Memcached哈希性能优化(八)——总结报告
Memcached哈希性能优化报告
一、 Memcached分析
这两个月一直在memcached优化和找工作之间忙着,一边复习一边优化改代码还真是个让人觉得难以忘记的夏天。做这个项目确实收获了很多,不管是对Linux的系统的认识,还是对memcached的认识都比以前更近一步,另外后面由于添加分块hash,替换LRU算法和更改hash算法对源代码进行修改,一不小心就把原来的代码的测试改跪了,用gdb调试的能力也有所提升了。感觉这个项目还是蛮有价值的。
还是得把memcached简单介绍一下,毕竟后面的东西要用一下的来着。
1. 内存管理
首先这个内存指的是slab的内存管理,这个是memcached的一个主要特点,他所有的item的内存空间均是从slab管理的内存分配器中分配的。这个内存管理大致是以下这么几个要点
- 和一般的内存管理差不过, memcached从操作系统获取到一大块内存后, 便把这大块内存划分为各种大小的chunk块, chunk块大小按照比例逐渐递增,这个可以由用户来指定完成。
- 每个slabclass含有多个slab,一个slab是一个大小为1M的内存块,这个slab块的会被按照chunk块的大小进行分割进行分配。
- 从 slab管理器分配item的时候, 首先计算item的大小, 找到大小刚好大于等于某个chunk块size所在的slabclass,然后进行分配。
- 分配的逻辑很简单,如果有空闲的或是回收回来item的话,则直接分配从这个chunk块,否则尝试申请新的slab的然后进行分配,再要没有就只能返回NULL让LRU去替换了。
这种分配方式的缺点其实是蛮多的,举下面2个例子:
- 存在内存碎片, 比如说, 将48字节的item存储到一个64字节的 chunk, 就有16字节的内存浪费。
- 另外,由于slab是唯一的,必须采用slab_lock保证分配的原子性,也就是说如果多线程分配的话,如果cache_lock间冲突假设没有的话,到这个slab去申请内存的话也只能是单一的申请,所以决定了插入的过程的最终瓶颈就是这里了,而这里对内存的管理如果把他也分块的话导致后续的逻辑比较难处理,所以这个其实没有处理。
2. hash和LRU
hash和LRU这个东西memcached采用了最简单的设计方式,hash的实现采用的chain的实现,LRU是基于链表的实现,解构的图大概是下面这个样子的(原谅我的盗图行为图片来自百度百科)。

这个模型很经典,不管是链式hash还是LRU的双向链表的实现,不过存在下面几个问题
- 链式hash的实现很经典,但是由于是链表保存,数据的局部性很不好,所以内存的访问效率就会有所下降。
- LRU的那个双向链表的实现,插入和读取都要调整item在LRU表中的位置,这2个操作明显需要上锁,其实读取本身不需要上锁的,但是要调整LRU的位置,所以没有办法在do_item_link和do_item_unlink中我们都能发现要上锁cache表。
- 如果采用开放寻址法使用的话,那么hash的查找效率可能就不高了,所以hash的效率还是极为关键的。
3. 线程模型
这个优化做的没关注这里,就这个我就列举以下建立流程。
- 初始化主线程event_base,和worker线程
- 建立worker线程的通知管道
- 注册worker线程管道的libevent事件
- 初始化每个worker的CQ队列
- 启动worker线程,主线程监听socket事件,worker线程监听socket的读写事件
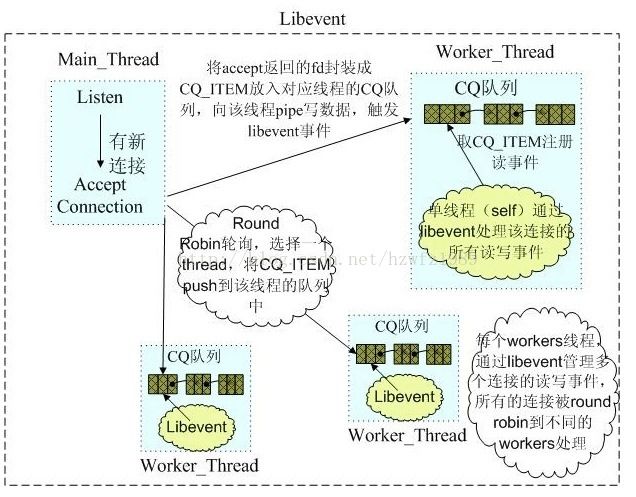
如果有链接建立或者是运行的过程见这张图(图片来自http://bachmozart.iteye.com/blog/344172),具体的代码分析就不列举了,今年这个blog都有的。
二、Memcached的优化内容
1. 分块hash优化
这个是这个样子的主要是为了能够多线程的读取和查找做优化使用,主要思路借鉴了下面这个文章的几个思路。"CPHASH: A Cache-Partitioned Hash Table",主要思路是下面两个
- 首先把hash表分块,每个分块由不同的线程进行处理,当然可以绑定到固定的核上去,这个有个memc3就是这个绑定的
- 每个hash块拥有有自己的LRU表和hash的表,分块由自己的LRU和hash表进行处理操作
这样读的效率肯定可以利用多核的优势,处理读的性能肯定可以上去,但是插入的效率是没有办法的,因为原因主要是出在了slab_lock这个上面,因为slab的分配显然不是可以并行的,因为slab的的分配由slab_lock进行处理,而这个由于上锁的原因,多个workerthread对应的只有一个slab分配器,那么可以肯定的说,插入的瓶颈没有办法通过多线程来解决,但是读可以采用多线程来提高读的效率的。所以这里分块hash主要是提升了读的性能。由于采用了分块hash的处理,那么使得有些item的逻辑就不是原来的那个了, 具体的代码可以看clockdev那个branch上的的代码,那个分支是采用了clock替换和mulit-hash是这么做的。
2. clock算法优化
目的其实很单纯,牺牲命中率和淘汰次数,提高get的读写性能,尤其是多核的情况下这个Clock置换算法大致描述如下
1类(A=0, M=0): 表示该页最近既未被访问,又未被更新,是最佳淘汰页。
2类(A=0, M=1):表示该页最近未被访问,但已被修改,并不是很好的淘汰页。
3类(A=1, M=0):最近已被访问,但未被修改,该页有可能再被访问。
4类(A=1, M=1): 最近已被访问且被修改,该页可能再被访问。其执行过程可分成以下三步:
(1) 从指针所指示的当前位置开始,扫描循环队列,寻找A=0且M=0的第一类页面, 将所遇到的第一个页面作为所选中的淘汰页。在第一次扫描期间不改变访问位A。
(2) 如果第一步失败,即查找一周后未遇到第一类页面,则开始第二轮扫描,寻找A=0且M=1的第二类页面,将所遇到的第一个这类页面作为淘汰页。在第二轮扫描期间,将所有扫描过的页面的访问位都置0。
(3) 如果第二步也失败,亦即未找到第二类页面,则将指针返回到开始的位置,并将所有的访问位复0。然后重复第一步,如果仍失败,必要时再重复第二步,此时就一定能找到被淘汰的页。
2类(A=0, M=1):表示该页最近未被访问,但已被修改,并不是很好的淘汰页。
3类(A=1, M=0):最近已被访问,但未被修改,该页有可能再被访问。
4类(A=1, M=1): 最近已被访问且被修改,该页可能再被访问。其执行过程可分成以下三步:
(1) 从指针所指示的当前位置开始,扫描循环队列,寻找A=0且M=0的第一类页面, 将所遇到的第一个页面作为所选中的淘汰页。在第一次扫描期间不改变访问位A。
(2) 如果第一步失败,即查找一周后未遇到第一类页面,则开始第二轮扫描,寻找A=0且M=1的第二类页面,将所遇到的第一个这类页面作为淘汰页。在第二轮扫描期间,将所有扫描过的页面的访问位都置0。
(3) 如果第二步也失败,亦即未找到第二类页面,则将指针返回到开始的位置,并将所有的访问位复0。然后重复第一步,如果仍失败,必要时再重复第二步,此时就一定能找到被淘汰的页。
具体的实现的话采用下面的策略实现
- 只采用了时间进行标记,在update和get的时候记录下最新时间,在替换的时候检验这个时间是不是超期,如果超期则进行替换,如果没有超期就不替换。
- 为了能够支持循环查找,讲LRU的链表改成了双向的循环链表,同时添加hand指针,指向需要替换的元素,如果超期就替换,如果不超期则进行下一次尝试,如果失败的话,则就将这个元素替换出去
- 更新的过程中,不将元素放置到head处,只更新访问时间,这样的话就不用断掉链表,这样不用进行item _unlink和item_link的过程
这么做的话,get的性能确实可以上去,但是检查的过程中确实会降低部分的命中虑。
3. hash算法优化
采用了Hopscotch_hashing算法,其思路见这个wikihttp://en.wikipedia.org/wiki/Hopscotch_hashing。
这是一种线性探测hash算法的变形,主要目的是为了提高查询速度。原始的线性探测算法在key较多的情况下探测次数过多,而这个算法的目的其实就是减少探测的次数。
他的步骤主要是这么三个步骤:
- 首先检测映射到的bucket,看它是不是被占用,如果未被占用那就直接使用
- 如果已被占用,那么采用线性探测法探测到位置pos
- 如果pos的位置离bucket的位置大于给定的阈值H,那就调整这个上面的位置,使得这个H-1的bucket上出现空槽,如果没有空槽,resize哈希表然后再次进行尝试。
这个在最新的master上有所采用,不过性能好像不是很好,主要是expand hashtable的过程变得代价很大,而且expand的时机的选择变得更加的不确定,而且expand的过程中必须得上锁,期间几乎不能处理其他的请求,如果不expand bucket的话,可以有比较不错的处理性能的情况,所以这个过程和memc3的cuckoo hashing比较类似,它确实也舍弃了expand hash这个后台处理线程,看来线性探测法在这个expand上确实很难做到最优。
4. tag查询优化
这个主要是借鉴这个文章的“MemC3: Compact and Concurrent MemCache with Dumber Caching and Smarter Hashing”,找到了github上的项目,不过貌似编译完了运行不了,插入key貌似会报错(>_<),不过思路蛮好的
- 首先,另外采用一个hash函数计算算出一个1字节大小tag,直接保存在 hashtable 的对应item里面。
- 然后查找的时候,先比较tag是不是一致,如果一致,再去比较 key。
这样避免没必要的指针取地址的操作,而且当key很大时,比较key的代价其实还是蛮高的,而很多时候tag比较首先就会不满足了,因而就没必要再去解析这个key对应的内容了,而且如果key存储在另外的内存块里面很可能造成cache不命中,性能就不好了。这个也是前面hash算法优化的一个问题, 尤其是碰撞的key又用链表链接在一起的时候,进而遍历历整个链表,最坏的情况下如果后续链表的节点都在不同的内存,性能那就更差了。
三、优化结果
主要是这么几个结论把,以前的blog上也写过部分的测试结果,现在统一描述以下。测试环境一台4核的pc,内存4G,2台24核工作站作为client使用进行测试。
client均采用48个线程进行读写工作
1. 测试pc单线程工作
这个测试的过程主要是测试上限,由于slab_lock的限制上限其实结果插入大约是每秒10万个操作,读取也在每秒11万操作
[OVERALL], RunTime(ms), 45906.0
[OVERALL], Throughput(ops/sec), 108917.52712063782
[INSERT], Operations, 4999968
[INSERT], AverageLatency(us), 428.84410700228483
[INSERT], MinLatency(us), 123
[INSERT], MaxLatency(us), 59953
[INSERT], 95thPercentileLatency(ms), 0
[INSERT], 99thPercentileLatency(ms), 1
[INSERT], Return=0, 4999968
2. 测试pc 8个线程工作
采用clock+mulitihash:
插入平均是每秒9万操作。
[OVERALL], RunTime(ms), 53169.0
[OVERALL], Throughput(ops/sec), 94039.15815606838[INSERT], Operations, 4999968
[INSERT], AverageLatency(us), 497.43873040787463
[INSERT], MinLatency(us), 120
[INSERT], MaxLatency(us), 156936
[INSERT], 95thPercentileLatency(ms), 0
[INSERT], 99thPercentileLatency(ms), 6
[INSERT], Return=0, 4999968
采用原始的memcached:
插入平均是每秒6万操作,
[OVERALL], RunTime(ms), 77420.0
[OVERALL], Throughput(ops/sec), 64582.381813484884
[INSERT], Operations, 4999968
[INSERT], AverageLatency(us), 722.7500804005145
[INSERT], MinLatency(us), 120
[INSERT], MaxLatency(us), 118476
[INSERT], 95thPercentileLatency(ms), 1
[INSERT], 99thPercentileLatency(ms), 12
采用2个client
采用clock + mulithash:
2个读取是每秒20万操作,基本是单个client的叠加
采用原始的memcached:
2个读取是每秒20万操作,基本是单个client的叠加
而单个client的测试基本读取都是每秒11万操作
这个是clock + multihash
[OVERALL], RunTime(ms), 167550.0
[OVERALL], Throughput(ops/sec), 119367.16204118174
[READ], Operations, 19959611
[READ], AverageLatency(us), 389.58720097300494
[READ], MinLatency(us), 94
[READ], MaxLatency(us), 58364
[READ], 95thPercentileLatency(ms), 0
[READ], 99thPercentileLatency(ms), 3
原始的能稍微差点,但是数量级差不多
[OVERALL], RunTime(ms), 168112.0
[OVERALL], Throughput(ops/sec), 118968.11649376607
[READ], Operations, 19960241
[READ], AverageLatency(us), 390.19616010648366
[READ], MinLatency(us), 97
[READ], MaxLatency(us), 166104
[READ], 95thPercentileLatency(ms), 0
[READ], 99thPercentileLatency(ms), 3
get的过程中中memcahed的所在pc的cpu的利用率均为能达到100%,但是client的cpu都已经是100%了,也就是说get的处理性能没有达到最高,但是在插入的过程中确实cpu的利用率在htop下看达到了100%,而且单个client的增加,处理的总数是会增加的,所以说get处理过程中2个client确实没有达到这个pc的处理的最高值,get的插入确实是没有办法检测出来,从htop的看到的cpu的利用率来说,clock+multihash能稍微高一点点,这个是测试的环境所限,确实无法测出2个实际的差距。但是在单机上有一个趋势就是采用multihash的办法在发端的线程提升的情况下,hash的效果下降不会太大,而原始的会跌落的比较明显。
四、总结
这次的memcached的开源夏令营也算是告一段路了,期间查询了不少资料,看了不少的paper和项目,从之前的bagLRU到后来的memC3,从开始研究乐观锁和多版本并发控制到后来去研究hash算法和lru算法之间的差异,从skiplist的算法优化到后来的结构的修改,中间试过不少办法,也走了一些弯路,但是发现探索的过程还是学到了许多的东西。不过中间的很多过程还是发现了自己很多不足的地方,希望能够能以此为基础,进一步提高自己的能力,另外,发现开源项目真的很不错,希望以后能继续研究和回馈开源项目。