Hadoop 两张表,三种 join 方式的实践
目录
-
- 前言
- 问题引入
- Reduce-side join
-
- 代码
- reduce输出文件
- mr log
-
- map 输出
- 想想有什么问题没有?
- Map-side join
-
- 场景设定为:比如一个大表 和 一个小表 join
-
- Java 程序
- mr log
- 输出
- Semi Join
-
- 场景设定为:大表 join 大表
-
- Motivation
- 处理思路
- 输入
- Java程序
- Log
前言
本文始终以order.txt 和 pd.txt两个文本数据展开,实践了map-side join, reduce-side join & semi join,并做了一些介绍和说明。
建议多google,网上很多文章写的很乱,排版也是乱七八糟,一套数据是可以三种jon都说到,并实践的,但就是不实践全。
// TODO
后续需要结合spark join 对比理解; 同时复习下SQL中的一些join操作底层是怎么实现的。
问题引入
这也是网上搜出来的大部分
- 订单表(orderId, proId, amount)
1001 01 1
1002 02 2
1003 03 3
1004 01 4
1005 02 5
1006 03 6
- 产品表(proId, proName)
01 小米
02 华为
03 格力
想要的join结果(即某个订单,属于哪个品牌的,有多少量) ,这个问题很合理,mysql写写也简单 ?
1001 小米 1
1002 华为 2
1003 格力 3
1004 小米 4
1005 华为 5
1006 格力 6
Reduce-side join
比较容易想到的就是,数据都放到内存中,有了proId的关联,join就是很简单的事情了
代码
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
import java.net.URI;
import java.util.ArrayList;
import java.util.List;
/**
* @Author mubi
* @Date 2020/5/4 12:50
*/
public class TableJoinMain {
static class TableMapper extends Mapper<LongWritable, Text, Text, Text> {
StringBuilder sb = new StringBuilder();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
FileSplit inputSplit = (FileSplit)context.getInputSplit();
String name = inputSplit.getPath().getName();
String[] split = value.toString().split(" ");
sb.setLength(0);
// pId 关联两个表,作为key
if(name.contains("order")) {
String pId = split[1];
sb.append("order#");
sb.append(" " + split[0]); // orderId
sb.append(" " + split[2]); // amount
context.write(new Text(pId), new Text(sb.toString()));
}else {
String pId = split[0];
sb.append("pd#");
sb.append(" " + split[1]); // pName
context.write(new Text(pId), new Text(sb.toString()));
}
}
}
static class TableReducer extends Reducer<Text, Text, Text, NullWritable> {
List<Order> orderList = new ArrayList<Order>();
List<Pro> proList = new ArrayList<Pro>();
@Override
protected void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
// proId
String pId = key.toString();
// 关联 proId 的 pro 和 order
for(Text text : values) {
String value = text.toString();
System.out.println("reduce record, key:" + key + " value:" + value);
//将集合中的元素添加到对应的list中
if(value.startsWith("order#")) {
String[] split = value.split(" ");
Order order = new Order(split[1], pId, Long.valueOf(split[2]));
orderList.add(order);
}else if(value.startsWith("pd#")){
String[] split = value.split(" ");
Pro pro = new Pro(pId, split[1]);
proList.add(pro);
}
}
// 做 join
int m = orderList.size();
int n = proList.size();
for(int i=0;i<m;i++) {
for(int j=0;j<n;j++) {
String joinBean =
orderList.get(i).getId() + " " +
proList.get(j).getpName() + " " +
orderList.get(i).getAmount();
// 输出
context.write(new Text(joinBean), NullWritable.get());
}
}
orderList.clear();
proList.clear();
}
}
public static void main(String[] args) throws Exception {
String hdfsUrl = "hdfs://localhost:9000";
String dst1 = hdfsUrl + "/input/order";
String dst2 = hdfsUrl + "/input/pd";
// hadoop fs -cat hdfs://localhost:9000/output/join/part-r-00000
//输出路径,必须是不存在的,空文件也不行。
String dstOut = hdfsUrl + "/output/join";
// 1 获取配置信息,或者job对象实例
Configuration configuration = new Configuration();
Job job = Job.getInstance(configuration);
// 如果输出目录已经存在,则先删除
FileSystem fileSystem = FileSystem.get(new URI(hdfsUrl), configuration);
Path outputPath = new Path("/output/join");
if(fileSystem.exists(outputPath)){
fileSystem.delete(outputPath,true);
}
// 2 指定本程序的jar包所在的本地路径
job.setJarByClass(TableJoinMain.class);
// 3 指定本业务job要使用的Mapper/Reducer业务类
job.setMapperClass(TableMapper.class);
job.setReducerClass(TableReducer.class);
// 4 指定Mapper输出数据的kv类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
// 5 指定最终输出的数据的kv类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(NullWritable.class);
// 6 指定job的输入原始文件所在目录
FileInputFormat.addInputPath(job, new Path(dst1));
FileInputFormat.addInputPath(job, new Path(dst2));
FileOutputFormat.setOutputPath(job, new Path(dstOut));
// 7 将job中配置的相关参数,以及job所用的java类所在的jar包, 提交给yarn去运行
boolean result = job.waitForCompletion(true);
System.exit(result ? 0 : 1);
}
}
- order对象
/**
* @Author mubi
* @Date 2020/5/4 12:54
*/
public class Order {
String id;
String pId;
Long amount;
public Order(String id, String pId, Long amount) {
this.id = id;
this.pId = pId;
this.amount = amount;
}
public String getId() {
return id;
}
public String getpId() {
return pId;
}
public Long getAmount() {
return amount;
}
}
- pro 对象
/**
* @Author mubi
* @Date 2020/5/4 12:55
*/
public class Pro {
String pId;
String pName;
public Pro(String pId, String pName) {
this.pId = pId;
this.pName = pName;
}
public String getpId() {
return pId;
}
public String getpName() {
return pName;
}
}
reduce输出文件
1004 小米 4
1001 小米 1
1005 华为 5
1002 华为 2
1006 格力 6
1003 格力 3
mr log
2020-05-04 22:55:07,759 INFO [org.apache.hadoop.mapreduce.Job] - Counters: 36
File System Counters
FILE: Number of bytes read=1610
FILE: Number of bytes written=1056991
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=240
HDFS: Number of bytes written=84
HDFS: Number of read operations=33
HDFS: Number of large read operations=0
HDFS: Number of write operations=8
HDFS: Number of bytes read erasure-coded=0
Map-Reduce Framework
Map input records=9
Map output records=9
Map output bytes=144
Map output materialized bytes=174
Input split bytes=193
Combine input records=0
Combine output records=0
Reduce input groups=3
Reduce shuffle bytes=174
Reduce input records=9
Reduce output records=6
Spilled Records=18
Shuffled Maps =2
Failed Shuffles=0
Merged Map outputs=2
GC time elapsed (ms)=64
Total committed heap usage (bytes)=1196949504
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=90
File Output Format Counters
Bytes Written=84
map 输出
如下,两个表的数据被打标了,然后reduce读取的时候在区分出来
01 order# 1001 1
02 order# 1002 2
03 order# 1003 3
01 order# 1004 4
02 order# 1005 5
03 order# 1006 6
01 pd# 小米
02 pd# 华为
03 pd# 格力
想想有什么问题没有?
显然结果毋庸置疑是正确的;但是可以看到reduce端要拉取两个表数据(不管最后是否是可以join的),且是做的笛卡尔积;要是两个表都很大,那么数据传输开销是很大的,内存使用应该也高
Map-side join
借鉴已知的一些 sql join 知识
场景设定为:比如一个大表 和 一个小表 join
显然能够想到的就是:小表数据直接内存中,然后遍历大表,去找小表的匹配,然后输出结果即可
Java 程序
- hadoop 2.7.2 使用的还是老的
context.getLocalCacheFiles();, 使用新的context.getCacheFiles();会报错
package join;
import org.apache.commons.lang3.StringUtils;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.BufferedReader;
import java.io.FileInputStream;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.URI;
import java.util.Map;
import java.util.concurrent.ConcurrentHashMap;
/**
* @Author mubi
* @Date 2020/5/4 12:50
*/
public class TableJoinMain2 extends Configured {
static class TableMapper extends Mapper<LongWritable, Text, Text, NullWritable> {
// map 之前,就把 pd.txt 的内容缓存起来
Map<String, String> mpPro2Name = new ConcurrentHashMap<String, String>();
@Override
protected void setup(Context context) throws IOException {
Path[] cacheFiles = context.getLocalCacheFiles();
String line;
for (Path cacheFile : cacheFiles) {
BufferedReader br = new BufferedReader(new InputStreamReader(
new FileInputStream(cacheFile.getName()),"UTF-8"));
while(StringUtils.isNotEmpty((line=br.readLine()))){
String[] arr = line.split(" ");
mpPro2Name.put(arr[0], arr[1]);
}
}
}
StringBuffer sb = new StringBuffer();
// map 操作 order.txt, 利用缓存内容做join 操作
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String[] split = value.toString().split(" ");
sb.setLength(0);
// pId 关联两个表,作为key
String pId = split[1];
if(mpPro2Name.containsKey(pId)) {
sb.append(split[0]); // orderId
sb.append(" " + mpPro2Name.get(pId));
sb.append(" " + split[2]); // amount
context.write(new Text(sb.toString()), NullWritable.get());
}
}
}
public static void main(String[] args) throws Exception {
String hdfsUrl = "hdfs://localhost:9000";
String dst1 = hdfsUrl + "/input/order";
String dst2 = hdfsUrl + "/input/pd";
// hadoop fs -cat hdfs://localhost:9000/output/join/part-r-00000
//输出路径,必须是不存在的,空文件也不行。
String dstOut = hdfsUrl + "/output/join";
// 1 获取配置信息,或者job对象实例
Configuration configuration = new Configuration();
Job job = Job.getInstance(configuration);
// 添加本地缓存文件
job.addCacheFile(new Path(dst2).toUri());
// job.addCacheFile(new Path("/Users/mubi/test_data/pd.txt").toUri());
// 如果输出目录已经存在,则先删除
FileSystem fileSystem = FileSystem.get(new URI(hdfsUrl), configuration);
Path outputPath = new Path("/output/join");
if(fileSystem.exists(outputPath)){
fileSystem.delete(outputPath,true);
}
// 2 指定本程序的jar包所在的本地路径
job.setJarByClass(TableJoinMain2.class);
// 3 指定本业务job要使用的Mapper/Reducer业务类
job.setMapperClass(TableMapper.class);
// job.setReducerClass();
// 4 指定Mapper输出数据的kv类型
// job.setMapOutputKeyClass(Text.class);
// job.setMapOutputValueClass(Text.class);
// 5 指定最终输出的数据的kv类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(NullWritable.class);
// 6 指定job的输入原始文件所在目录
FileInputFormat.addInputPath(job, new Path(dst1));
// FileInputFormat.addInputPath(job, new Path(dst2));
FileOutputFormat.setOutputPath(job, new Path(dstOut));
// 7 将job中配置的相关参数,以及job所用的java类所在的jar包, 提交给yarn去运行
boolean result = job.waitForCompletion(true);
System.exit(result ? 0 : 1);
}
}
mr log
2020-05-05 22:33:06,063 INFO [org.apache.hadoop.mapreduce.Job] - Counters: 36
File System Counters
FILE: Number of bytes read=550
FILE: Number of bytes written=705400
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=180
HDFS: Number of bytes written=84
HDFS: Number of read operations=35
HDFS: Number of large read operations=0
HDFS: Number of write operations=6
HDFS: Number of bytes read erasure-coded=0
Map-Reduce Framework
Map input records=6
Map output records=6
Map output bytes=84
Map output materialized bytes=102
Input split bytes=98
Combine input records=0
Combine output records=0
Reduce input groups=6
Reduce shuffle bytes=102
Reduce input records=6
Reduce output records=6
Spilled Records=12
Shuffled Maps =1
Failed Shuffles=0
Merged Map outputs=1
GC time elapsed (ms)=0
Total committed heap usage (bytes)=390070272
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=60
File Output Format Counters
Bytes Written=84
输出
1001 小米 1
1002 华为 2
1003 格力 3
1004 小米 4
1005 华为 5
1006 格力 6
Semi Join
场景设定为:大表 join 大表
上述的 Map-side join 方法似乎不太好了,内存不够;在sql join中,使用了排序,然后merge join, 仍然是分治思想
https://sites.google.com/site/hadoopcs561/home/paper-a-comparison-of-join-algorithms-for-log-processing-in-mapreduce/phase-1-semi-join
Motivation
Join a table R (customer table) and a table L (log table) on joining key CustID using MapReduce architecture.
Often, when R is large, many records in R may not be actually referenced by any records in table L. Consider Facebook as an example. Its user table has hundreds of millions of records. However, an hour worth of log data likely contains the activities of only a few million unique users and the majority of the users are not present in this log at all. For broadcast join, this means that a large portion of the records in R that are shipped across the network (via the DFS) and loaded in the hash table are not used by the join. We exploit semi-join to avoid sending the records in R over the network that will not join with L
大意: R join L,R比如是facebook的user表,L比如是一个log表(R是上亿的,但是一小时log记录表,可能只有上百万的不同用户而已)如果遍历R去join L显然很多数据是不会参与join的,可以将这些数据先过滤掉
处理思路
因为只有部分key会最后join,那么先把key存储起来(这比较小,直接内存存起来);
在进行 map 的时候 判断是否在 内存key中(空数据可以布隆过滤器),这样过滤掉数据
那么随后仍然可以采用 reduce-side 的方式处理了
输入
- order.txt
1001 01 1
1002 02 2
1003 03 3
1004 01 4
1005 02 5
1006 03 6
1007 04 7
1008 05 8
- pd.txt
01 小米
02 华为
03 格力
order.txt中有一些是不会与pd.txt join的
Java程序
package join;
import com.google.common.base.Strings;
import org.apache.commons.lang3.StringUtils;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.eclipse.jetty.util.ConcurrentHashSet;
import java.io.BufferedReader;
import java.io.FileInputStream;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.URI;
import java.util.ArrayList;
import java.util.List;
import java.util.Set;
/**
* @Author mubi
* @Date 2020/5/4 12:50
*/
public class TableJoinMain2 {
static class TableMapper extends Mapper<LongWritable, Text, Text, Text> {
StringBuilder sb = new StringBuilder();
Set<String> joinKeys = new ConcurrentHashSet<String>();
@Override
protected void setup(Context context) throws IOException {
Path[] cacheFiles = context.getLocalCacheFiles();
String line;
for (Path cacheFile : cacheFiles) {
BufferedReader br = new BufferedReader(new InputStreamReader(
new FileInputStream(cacheFile.getName()),"UTF-8"));
while(StringUtils.isNotEmpty((line=br.readLine()))){
String[] arr = line.split(" ");
String proId = arr[0];
joinKeys.add(proId);
}
}
}
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
FileSplit inputSplit = (FileSplit)context.getInputSplit();
String name = inputSplit.getPath().getName();
String[] split = value.toString().split(" ");
sb.setLength(0);
// pId 关联两个表,作为key
if(name.contains("order")) {
String pId = split[1];
// 过滤
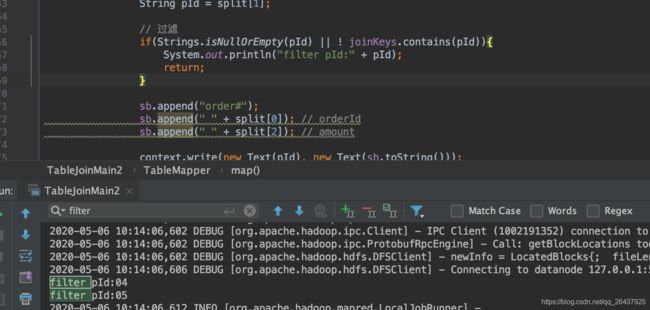
if(Strings.isNullOrEmpty(pId) || ! joinKeys.contains(pId)){
System.out.println("filter pId:" + pId);
return;
}
sb.append("order#");
sb.append(" " + split[0]); // orderId
sb.append(" " + split[2]); // amount
context.write(new Text(pId), new Text(sb.toString()));
}else {
String pId = split[0];
sb.append("pd#");
sb.append(" " + split[1]); // pName
context.write(new Text(pId), new Text(sb.toString()));
}
}
}
static class TableReducer extends Reducer<Text, Text, Text, NullWritable> {
List<Order> orderList = new ArrayList<Order>();
List<Pro> proList = new ArrayList<Pro>();
@Override
protected void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
// proId
String pId = key.toString();
// 关联 proId 的 pro 和 order
for(Text text : values) {
String value = text.toString();
System.out.println("reduce record, key:" + key + " value:" + value);
//将集合中的元素添加到对应的list中
if(value.startsWith("order#")) {
String[] split = value.split(" ");
Order order = new Order(split[1], pId, Long.valueOf(split[2]));
orderList.add(order);
}else if(value.startsWith("pd#")){
String[] split = value.split(" ");
Pro pro = new Pro(pId, split[1]);
proList.add(pro);
}
}
// 做 join
int m = orderList.size();
int n = proList.size();
for(int i=0;i<m;i++) {
for(int j=0;j<n;j++) {
String joinBean =
orderList.get(i).getId() + " " +
proList.get(j).getpName() + " " +
orderList.get(i).getAmount();
// 输出
context.write(new Text(joinBean), NullWritable.get());
}
}
orderList.clear();
proList.clear();
}
}
public static void main(String[] args) throws Exception {
String hdfsUrl = "hdfs://localhost:9000";
String dst1 = hdfsUrl + "/input/order";
String dst2 = hdfsUrl + "/input/pd";
// hadoop fs -cat hdfs://localhost:9000/output/join/part-r-00000
//输出路径,必须是不存在的,空文件也不行。
String dstOut = hdfsUrl + "/output/join";
// 1 获取配置信息,或者job对象实例
Configuration configuration = new Configuration();
Job job = Job.getInstance(configuration);
// 添加本地缓存文件 (相对的小表缓存)
job.addCacheFile(new Path(dst2).toUri());
// 如果输出目录已经存在,则先删除
FileSystem fileSystem = FileSystem.get(new URI(hdfsUrl), configuration);
Path outputPath = new Path("/output/join");
if(fileSystem.exists(outputPath)){
fileSystem.delete(outputPath,true);
}
// 2 指定本程序的jar包所在的本地路径
job.setJarByClass(TableJoinMain.class);
// 3 指定本业务job要使用的Mapper/Reducer业务类
job.setMapperClass(TableMapper.class);
job.setReducerClass(TableReducer.class);
// 4 指定Mapper输出数据的kv类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
// 5 指定最终输出的数据的kv类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(NullWritable.class);
// 6 指定job的输入原始文件所在目录
FileInputFormat.addInputPath(job, new Path(dst1));
FileInputFormat.addInputPath(job, new Path(dst2));
FileOutputFormat.setOutputPath(job, new Path(dstOut));
// 7 将job中配置的相关参数,以及job所用的java类所在的jar包, 提交给yarn去运行
boolean result = job.waitForCompletion(true);
System.exit(result ? 0 : 1);
}
}
Log
2020-05-06 10:14:08,435 INFO [org.apache.hadoop.mapreduce.Job] - Counters: 36
File System Counters
FILE: Number of bytes read=1610
FILE: Number of bytes written=1067770
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=390
HDFS: Number of bytes written=84
HDFS: Number of read operations=60
HDFS: Number of large read operations=0
HDFS: Number of write operations=8
HDFS: Number of bytes read erasure-coded=0
Map-Reduce Framework
Map input records=11
Map output records=9
Map output bytes=144
Map output materialized bytes=174
Input split bytes=193
Combine input records=0
Combine output records=0
Reduce input groups=3
Reduce shuffle bytes=174
Reduce input records=9
Reduce output records=6
Spilled Records=18
Shuffled Maps =2
Failed Shuffles=0
Merged Map outputs=2
GC time elapsed (ms)=0
Total committed heap usage (bytes)=786432000
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=110
File Output Format Counters
Bytes Written=84
可以看到Map input records=11 , Map output records=9 因为order的数据被过滤掉了一些; 加入直接采用reduce-side join,显然Map output records会等于11.