通过一条SQL分析SparkSQL执行流程(二)
目录
一、SparkSql执行步骤
二、SparkSql执行步骤详细描述
2.1) 用户构建SparkSession ,调用sql函数
2.2) 构建SessionState
2.2.1)解析器
2.2.2)Catalog
2.2.3)分析器
2.2.4)优化器
2.2.5)Planner
2.2.6)构造QueryExecution的函数
三、总结
一、SparkSql执行步骤
对于下面一段SQL
SELECT a.uid,b.name,SUM(clk_pv) AS clk_pv
FROM log a
JOIN user b ON a.uid = b.uid
WHERE a.fr = 'android'
GROUP BY a.uid,b.name
在上一部分,我们分析了SparkSQL的建议执行流程图。我们知道一条SQL在Spark执行要经历以下几步:
- 用户提交SQL文本
- 解析器将SQL文本解析成逻辑计划
- 分析器结合Catalog对逻辑计划做进一步分析,验证表是否存在,操作是否支持等
- 优化器对分析器分析的逻辑计划做进一步优化,如将过滤逻辑下推到子查询,查询改写,子查询共用等
- Planner再将优化后的逻辑计划根据预先设定的映射逻辑转换为物理执行计划
- 物理执行计划做RDD计算,最终向用户返回查询数据
那么详细的执行计划是什么样的呢?如下图:
 主要的执行步骤如下:
主要的执行步骤如下:
- 用户构建SparkSession,并调用Sql函数,传入Sql脚本
- 构建SparkSession时,Spark内部会构造SessionState,SessionState会构造解析器,分析器,Catalog,优化器,Planner还有逻辑计划转化为执行计划的方法
- SparkSession调用sessionState的解析器将sql文件解析为逻辑计划
- SparkSession调用DataSet 对象(注意不是DataSet类)的ofRow方法,返回DataFrame
- DataSet对象调用SparkSession的SessionState的executePlan方法(这是一个函数)返回一个QueryExecution
- 构造QueryExecution的过程是分析(Catalog)->优化->转化为逻辑计划的过程
- DataSet对象调用QueryExecution的assertAnalyzed()方法,判断是否已分析
- DataSet对象通过DataSet类创建一个DataSet实例。同时传入RowEncoder即Schema并返回一个DataFrame即DataSet[Row]类型。
然后就可以在DataFrame上做各种算子。
二、SparkSql执行步骤详细描述
上述的流程又具体可分为几个关键阶段:
2.1)用户构建SparkSession ,调用sql函数
import org.apache.spark.sql.SparkSession
val spark = SparkSession
.builder()
.appName("Spark SQL basic example")
.config("spark.some.config.option", "some-value")
.getOrCreate()
val sqlContext = "....."
val df = spark.sql(sqlContext)
SparkSession是SparkSQL的统一入口。SparkSession是通过Builder构造的。(则这是一种典型的设计模式:构造者模式,目的是将类的构造和类的表现解耦)。
class SparkSession private(
@transient val sparkContext: SparkContext,
@transient private val existingSharedState: Option[SharedState],
@transient private val parentSessionState: Option[SessionState],
@transient private[sql] val extensions: SparkSessionExtensions)
extends Serializable with Closeable with Logging {
// Sparksession 的实现
}
如上,SparkSession在构造时,会传入一个SessionState类型的对象。这个对象是SparkSession能完成所有功能的核心。
private[sql] class SessionState(
sharedState: SharedState,
val conf: SQLConf,
val experimentalMethods: ExperimentalMethods,
val functionRegistry: FunctionRegistry,
val udfRegistration: UDFRegistration,
val catalog: SessionCatalog,
val sqlParser: ParserInterface,
val analyzer: Analyzer,
val optimizer: Optimizer,
val planner: SparkPlanner,
val streamingQueryManager: StreamingQueryManager,
val listenerManager: ExecutionListenerManager,
val resourceLoader: SessionResourceLoader,
createQueryExecution: LogicalPlan => QueryExecution,
createClone: (SparkSession, SessionState) => SessionState) {
//SessionState 实现
}
从上面代码可以看出来,构造SessionState就构造一个catalog,解析器,分析器,优化器和Planner。同时还传入一个函数createQueryExecution,这个函数会将逻辑计划转化为查询计划。
总结
SparkSession在底层封装了SessionState的构建,并对用户透明,用户只需构建SparkSession即可完成相应操作。
问题:如何实现外部数据源?
观察SparkSession构建SessionState的源码:
// 如果父Session有SessionState 则复制一份,否则调用instantiateSessionState构建
lazy val sessionState: SessionState = {
parentSessionState
.map(_.clone(this))
.getOrElse {
val state = SparkSession.instantiateSessionState(
SparkSession.sessionStateClassName(sparkContext.conf),
self)
initialSessionOptions.foreach { case (k, v) => state.conf.setConfString(k, v) }
state
}
}
// 构建SessionState的方法,利用反射和ClassLoader创建SessionState实例
private def instantiateSessionState(
className: String,
sparkSession: SparkSession): SessionState = {
try {
// invoke `new [Hive]SessionStateBuilder(SparkSession, Option[SessionState])`
val clazz = Utils.classForName(className)
val ctor = clazz.getConstructors.head
ctor.newInstance(sparkSession, None).asInstanceOf[BaseSessionStateBuilder].build()
} catch {
case NonFatal(e) =>
throw new IllegalArgumentException(s"Error while instantiating '$className':", e)
}
}
private def sessionStateClassName(conf: SparkConf): String = {
conf.get(CATALOG_IMPLEMENTATION) match {
case "hive" => HIVE_SESSION_STATE_BUILDER_CLASS_NAME
case "in-memory" => classOf[SessionStateBuilder].getCanonicalName
}
}
从上面的代码可知:用户配置CATALOG_IMPLEMENTATION,也就是参数spark.sql.catalogImplementation 参数指明定制的的SessionState。当日这个SessionState有一个Builder,且是BaseSessionStateBuilder的子类。
另外,在Object:StaticSQLConf 中我们发现:
val CATALOG_IMPLEMENTATION = buildStaticConf("spark.sql.catalogImplementation")
.internal()
.stringConf
.checkValues(Set("hive", "in-memory"))
.createWithDefault("in-memory")
这段代码的含义是如果用户指明的spark.sql.catalogImplementation参数不是"hive", "in-memory"或者说未指明,则默认为:in-memory。也就是说默认情况,使用的是in-memory 模式。而in-memory 模式实际构造的是Spark内部的SessionStateBuilder 的实例。
class SessionStateBuilder(
session: SparkSession,
parentState: Option[SessionState] = None)
extends BaseSessionStateBuilder(session, parentState) {
override protected def newBuilder: NewBuilder = new SessionStateBuilder(_, _)
}
而SessionStateBuilder 只是BaseSessionStateBuilder 的简单实现。因此构造自己外部数据源,必须重写自己的SessionState,并继承BaseSessionStateBuilder。
2.2)构建SessionState
在 【2.1】中我们看到SparkSession实际上就做了一件事:构建SessionState,以及怎么构建SessionState?
为了构建SessionState,首先从用户配置参数spark.sql.catalogImplementation中读到catalog实现,然后通过模式匹配找到对应的类名,再通过反射方法创建一个BaseSessionStateBuilder类型的实例。(这又是一个构造者设计模式的应用)
所以,SessionState的构造,实际是BaseSessionStateBuilder 的构造。我们知道,SessionState肯定有解析器,catalog,分析器,优化器,Planner(没找到好的中文名字对应),还有一个将逻辑计划转化为QueryExecution的函数。
那么这些组件是如何构造的的呢?
2.2.1)解析器
protected lazy val sqlParser: ParserInterface = {
extensions.buildParser(session, new SparkSqlParser(conf))
}
解析器是通过extensions.buildParser 构造的,extensions 是什么?
protected def extensions: SparkSessionExtensions = session.extensions
extensions是一个SparkSession的一个变量,是SparkSessionExtensions类型,我们在SparkSession对象的Builder类中我们看到:
/**
* Inject extensions into the [[SparkSession]]. This allows a user to add Analyzer rules,
* Optimizer rules, Planning Strategies or a customized parser.
*
* @since 2.2.0
*/
def withExtensions(f: SparkSessionExtensions => Unit): Builder = {
f(extensions)
this
}
这是2.2以后运行用户注入自己的分析的一个扩展。在SparkSessionExtensions的buildParser
private[sql] def buildParser(
session: SparkSession,
initial: ParserInterface): ParserInterface = {
parserBuilders.foldLeft(initial) { (parser, builder) =>
builder(session, parser)
}
}
实际上就是将用户扩展和Spark自己的解析器做合并。
2.2.2)Catalog
protected lazy val catalog: SessionCatalog = {
val catalog = new SessionCatalog(
session.sharedState.externalCatalog,
session.sharedState.globalTempViewManager,
functionRegistry,
conf,
SessionState.newHadoopConf(session.sparkContext.hadoopConfiguration, conf),
sqlParser,
resourceLoader)
parentState.foreach(_.catalog.copyStateTo(catalog))
catalog
}
如果用户定义自己的数据源,就是要改这个地方,实现自己的CataLog.
2.2.3)分析器
protected def analyzer: Analyzer = new Analyzer(catalog, conf) {
override val extendedResolutionRules: Seq[Rule[LogicalPlan]] =
new FindDataSourceTable(session) +:
new ResolveSQLOnFile(session) +:
customResolutionRules
override val postHocResolutionRules: Seq[Rule[LogicalPlan]] =
PreprocessTableCreation(session) +:
PreprocessTableInsertion(conf) +:
DataSourceAnalysis(conf) +:
customPostHocResolutionRules
override val extendedCheckRules: Seq[LogicalPlan => Unit] =
PreWriteCheck +:
HiveOnlyCheck +:
customCheckRules
}
在构造分析器时,重写了三个方法:外部的解析规则,postHoc(??什么鬼)解析规则
和外部的Check规则。这对于DDL命令等不需要解析的文本解析的文本,定义的规则。当然,用户也可以通过重写这个类,或者通过配置加载一些规则进来
2.2.4)优化器
protected def optimizer: Optimizer = {
new SparkOptimizer(catalog, conf, experimentalMethods) {
override def extendedOperatorOptimizationRules: Seq[Rule[LogicalPlan]] =
super.extendedOperatorOptimizationRules ++ customOperatorOptimizationRules
}
}
extendedOperatorOptimizationRules 说明,优化器也可以加载外部规则
2.2.5)Planner
protected def planner: SparkPlanner = {
new SparkPlanner(session.sparkContext, conf, experimentalMethods) {
override def extraPlanningStrategies: Seq[Strategy] =
super.extraPlanningStrategies ++ customPlanningStrategies
}
}
extraPlanningStrategies 说明,Planner也可以加载外部规则
2.2.6)构造QueryExecution的函数
protected def createQueryExecution: LogicalPlan => QueryExecution = { plan =>
new QueryExecution(session, plan)
}
实际上就是创建了一个QueryExecution实例
三、总结
在BaseSessionStateBuilder构造各类组件时,都暴露了外部接口,每一个组件用户都可以去实现定制的规则或策略。
最后,经过上面的分析,我们得到SparkSpark的类的关系图: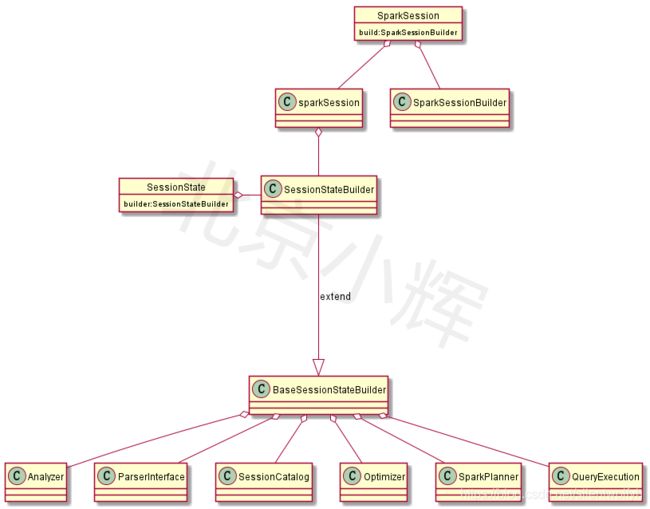 我们回到我们怎么使用SparkSQL
我们回到我们怎么使用SparkSQL
val spark = SparkSession
.builder()
.appName("Spark SQL basic example")
.config("spark.some.config.option", "some-value")
.getOrCreate()
val df = spark.sql(".............")
