一,Python介绍
1,python的出生与应用
python的创始人为吉多·范罗苏姆(Guido van Rossum)。1989年的圣诞节期间,吉多·范罗苏姆(中文名字:龟叔)为了在阿姆斯特丹打发时间,决心开发一个新的脚本解释程序,作为ABC语言的一种继承。
(龟叔:2005年加入谷歌至2012年,2013年加入Dropbox直到现在,依然掌握着Python发展的核心方向,被称为仁慈的独裁者)。

2017年7月的TIOBE排行榜,Python已经占据第四的位置, Python崇尚优美、清晰、简单,是一个优秀并广泛使用的语言。
Python可以应用于众多领域,如:数据分析、组件集成、网络服务、图像处理、数值计算和科学计算等众多领域。目前业内几乎所有大中型互联网企业都在使用Python,如:Youtube、Dropbox、BT、Quora(中国知乎)、豆瓣、知乎、Google、Yahoo!、Facebook、NASA、百度、腾讯、汽车之家、美团等。
目前Python主要应用领域:
- 云计算: 云计算最火的语言, 典型应用OpenStack
- WEB开发: 众多优秀的WEB框架,众多大型网站均为Python开发,Youtube, Dropbox, 豆瓣。。。, 典型WEB框架有Django
- 科学运算、人工智能: 典型库NumPy, SciPy, Matplotlib, Enthought librarys,pandas
- 系统运维: 运维人员必备语言
- 金融:量化交易,金融分析,在金融工程领域,Python不但在用,且用的最多,而且重要性逐年提高。原因:作为动态语言的Python,语言结构清晰简单,库丰富,成熟稳定,科学计算和统计分析都很牛逼,生产效率远远高于c,c++,java,尤其擅长策略回测
- 图形GUI: PyQT, WxPython,TkInter
Python在一些公司的应用:
-
- 谷歌:Google App Engine 、code.google.com 、Google earth 、谷歌爬虫、Google广告等项目都在大量使用Python开发
- CIA: 美国中情局网站就是用Python开发的
- NASA: 美国航天局(NASA)大量使用Python进行数据分析和运算
- YouTube:世界上最大的视频网站YouTube就是用Python开发的
- Dropbox:美国最大的在线云存储网站,全部用Python实现,每天网站处理10亿个文件的上传和下载
- Instagram:美国最大的图片分享社交网站,每天超过3千万张照片被分享,全部用python开发
- Facebook:大量的基础库均通过Python实现的
- Redhat: 世界上最流行的Linux发行版本中的yum包管理工具就是用python开发的
- 豆瓣: 公司几乎所有的业务均是通过Python开发的
- 知乎: 国内最大的问答社区,通过Python开发(国外Quora)
- 春雨医生:国内知名的在线医疗网站是用Python开发的
- 除上面之外,还有搜狐、金山、腾讯、盛大、网易、百度、阿里、淘宝 、土豆、新浪、果壳等公司都在使用Python完成各种各样的任务。
python发展史
1989年,为了打发圣诞节假期,Guido开始写Python语言的编译器。Python这个名字,来自Guido所挚爱的电视剧Monty Python’s Flying Circus。他希望这个新的叫做Python的语言,能符合他的理想:创造一种C和shell之间,功能全面,易学易用,可拓展的语言。
1991年,第一个Python编译器诞生。它是用C语言实现的,并能够调用C语言的库文件。从一出生,Python已经具有了:类,函数,异常处理,包含表和词典在内的核心数据类型,以及模块为基础的拓展系统。
python是什么编程语言
编程语言主要从以下几个角度为进行分类,编译型和解释型、静态语言和动态语言、强类型定义语言和弱类型定义语言,每个分类代表什么意思呢,我们一起来看一下。
2.1 编译型与解释型。
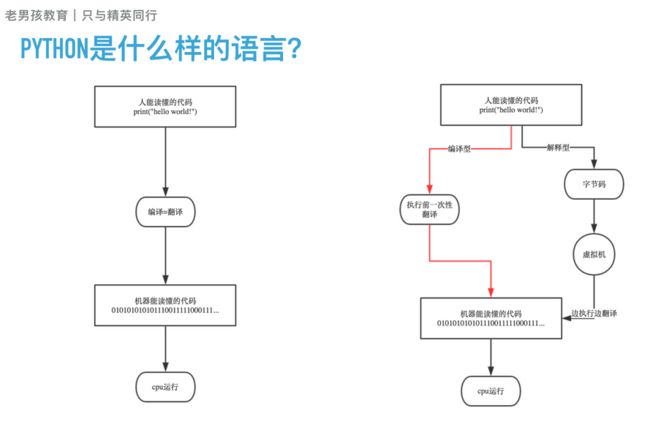
编译器是把源程序的每一条语句都编译成机器语言,并保存成二进制文件,这样运行时计算机可以直接以机器语言来运行此程序,速度很快;
而解释器则是只在执行程序时,才一条一条的解释成机器语言给计算机来执行,所以运行速度是不如编译后的程序运行的快的.
这是因为计算机不能直接认识并执行我们写的语句,它只能认识机器语言(是二进制的形式)
编译型
优点:编译器一般会有预编译的过程对代码进行优化。因为编译只做一次,运行时不需要编译,所以编译型语言的程序执行效率高。可以脱离语言环境独立运行。
缺点:编译之后如果需要修改就需要整个模块重新编译。编译的时候根据对应的运行环境生成机器码,不同的操作系统之间移植就会有问题,需要根据运行的操作系统环境编译不同的可执行文件。
解释型
优点:有良好的平台兼容性,在任何环境中都可以运行,前提是安装了解释器(虚拟机)。灵活,修改代码的时候直接修改就可以,可以快速部署,不用停机维护。
缺点:每次运行的时候都要解释一遍,性能上不如编译型语言。
2.2动态语言和静态语言
通常我们所说的动态语言、静态语言是指动态类型语言和静态类型语言。
(1)动态类型语言:动态类型语言是指在运行期间才去做数据类型检查的语言,也就是说,在用动态类型的语言编程时,永远也不用给任何变量指定数据类型,该语言会在你第一次赋值给变量时,在内部将数据类型记录下来。Python和Ruby就是一种典型的动态类型语言,其他的各种脚本语言如VBScript也多少属于动态类型语言。
(2)静态类型语言:静态类型语言与动态类型语言刚好相反,它的数据类型是在编译其间检查的,也就是说在写程序时要声明所有变量的数据类型,C/C++是静态类型语言的典型代表,其他的静态类型语言还有C#、JAVA等。
2.3强类型定义语言和弱类型定义语言
(1)强类型定义语言:强制数据类型定义的语言。也就是说,一旦一个变量被指定了某个数据类型,如果不经过强制转换,那么它就永远是这个数据类型了。举个例子:如果你定义了一个整型变量a,那么程序根本不可能将a当作字符串类型处理。强类型定义语言是类型安全的语言。
(2)弱类型定义语言:数据类型可以被忽略的语言。它与强类型定义语言相反, 一个变量可以赋不同数据类型的值。
强类型定义语言在速度上可能略逊色于弱类型定义语言,但是强类型定义语言带来的严谨性能够有效的避免许多错误。另外,“这门语言是不是动态语言”与“这门语言是否类型安全”之间是完全没有联系的!
例如:Python是动态语言,是强类型定义语言(类型安全的语言); VBScript是动态语言,是弱类型定义语言(类型不安全的语言); JAVA是静态语言,是强类型定义语言(类型安全的语言)。
通过上面这些介绍,我们可以得出,python是一门动态解释性的强类型定义语言
3,python的优缺点。
先看优点
- Python的定位是“优雅”、“明确”、“简单”,所以Python程序看上去总是简单易懂,初学者学Python,不但入门容易,而且将来深入下去,可以编写那些非常非常复杂的程序。
- 开发效率非常高,Python有非常强大的第三方库,基本上你想通过计算机实现任何功能,Python官方库里都有相应的模块进行支持,直接下载调用后,在基础库的基础上再进行开发,大大降低开发周期,避免重复造轮子。
- 高级语言————当你用Python语言编写程序的时候,你无需考虑诸如如何管理你的程序使用的内存一类的底层细节
- 可移植性————由于它的开源本质,Python已经被移植在许多平台上(经过改动使它能够工 作在不同平台上)。如果你小心地避免使用依赖于系统的特性,那么你的所有Python程序无需修改就几乎可以在市场上所有的系统平台上运行
- 可扩展性————如果你需要你的一段关键代码运行得更快或者希望某些算法不公开,你可以把你的部分程序用C或C++编写,然后在你的Python程序中使用它们。
- 可嵌入性————你可以把Python嵌入你的C/C++程序,从而向你的程序用户提供脚本功能
再看缺点:
速度慢,Python 的运行速度相比C语言确实慢很多,跟JAVA相比也要慢一些,因此这也是很多所谓的大牛不屑于使用Python的主要原因,但其实这里所指的运行速度慢在大多数情况下用户是无法直接感知到的,必须借助测试工具才能体现出来,比如你用C运一个程序花了0.01s,用Python是0.1s,这样C语言直接比Python快了10倍,算是非常夸张了,但是你是无法直接通过肉眼感知的,因为一个正常人所能感知的时间最小单位是0.15-0.4s左右,哈哈。其实在大多数情况下Python已经完全可以满足你对程序速度的要求,除非你要写对速度要求极高的搜索引擎等,这种情况下,当然还是建议你用C去实现的。
代码不能加密,因为PYTHON是解释性语言,它的源码都是以名文形式存放的,不过我不认为这算是一个缺点,如果你的项目要求源代码必须是加密的,那你一开始就不应该用Python来去实现。
线程不能利用多CPU问题,这是Python被人诟病最多的一个缺点,GIL即全局解释器锁(Global Interpreter Lock),是计算机程序设计语言解释器用于同步线程的工具,使得任何时刻仅有一个线程在执行,Python的线程是操作系统的原生线程。在Linux上为pthread,在Windows上为Win thread,完全由操作系统调度线程的执行。一个python解释器进程内有一条主线程,以及多条用户程序的执行线程。即使在多核CPU平台上,由于GIL的存在,所以禁止多线程的并行执行。关于这个问题的折衷解决方法,我们在以后线程和进程章节里再进行详细探讨。
当我们编写Python代码时,我们得到的是一个包含Python代码的以.py为扩展名的文本文件。要运行代码,就需要Python解释器去执行.py文件。
由于整个Python语言从规范到解释器都是开源的,所以理论上,只要水平够高,任何人都可以编写Python解释器来执行Python代码(当然难度很大)。事实上,确实存在多种Python解释器。
4,python的种类。
CPython
当我们从Python官方网站下载并安装好Python 3.6后,我们就直接获得了一个官方版本的解释器:CPython。这个解释器是用C语言开发的,所以叫CPython。在命令行下运行python就是启动CPython解释器。
CPython是使用最广的Python解释器。教程的所有代码也都在CPython下执行。
IPython
IPython是基于CPython之上的一个交互式解释器,也就是说,IPython只是在交互方式上有所增强,但是执行Python代码的功能和CPython是完全一样的。好比很多国产浏览器虽然外观不同,但内核其实都是调用了IE。
CPython用>>>作为提示符,而IPython用In [序号]:作为提示符。
PyPy
PyPy是另一个Python解释器,它的目标是执行速度。PyPy采用JIT技术,对Python代码进行动态编译(注意不是解释),所以可以显著提高Python代码的执行速度。
绝大部分Python代码都可以在PyPy下运行,但是PyPy和CPython有一些是不同的,这就导致相同的Python代码在两种解释器下执行可能会有不同的结果。如果你的代码要放到PyPy下执行,就需要了解PyPy和CPython的不同点。
Jython
Jython是运行在Java平台上的Python解释器,可以直接把Python代码编译成Java字节码执行。
IronPython
IronPython和Jython类似,只不过IronPython是运行在微软.Net平台上的Python解释器,可以直接把Python代码编译成.Net的字节码。
小结:
Python的解释器很多,但使用最广泛的还是CPython。如果要和Java或.Net平台交互,最好的办法不是用Jython或IronPython,而是通过网络调用来交互,确保各程序之间的独立性。
三,python基础初识。
1,运行python代码。
在d盘下创建一个t1.py文件内容是:
print('hello world')
打开windows命令行输入cmd,确定后 写入代码python d:t1.py
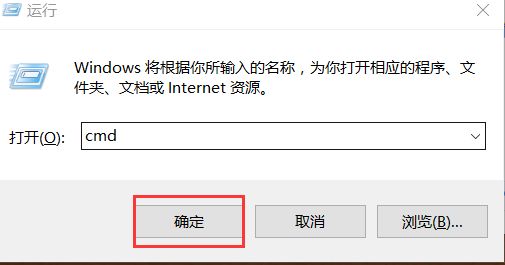

您已经运行了第一个python程序, 即:终端---->cmd-----> python 文件路径。 回车搞定~
2,解释器。
上一步中执行 python d:t1.py 时,明确的指出 t1.py 脚本由 python 解释器来执行。
如果想要类似于执行shell脚本一样执行python脚本,例: ./t1.py ,那么就需要在 hello.py 文件的头部指定解释器,如下:
|
1
2
3
|
#!/usr/bin/env python
print
"hello,world"
|
如此一来,执行: ./t1.py 即可。
ps:执行前需给予t1.py 执行权限,chmod 755 t1.py
3,内容编码。
python2解释器在加载 .py 文件中的代码时,会对内容进行编码(默认ascill),而python3对内容进行编码的默认为utf-8。
ASCII(American Standard Code for Information Interchange,美国标准信息交换代码)是基于拉丁字母的一套电脑编码系统,主要用于显示现代英语和其他西欧语言,其最多只能用 8 位来表示(一个字节),即:2**8 = 256,所以,ASCII码最多只能表示 256 个符号。
显然ASCII码无法将世界上的各种文字和符号全部表示,所以,就需要新出一种可以代表所有字符和符号的编码,即:Unicode
Unicode(统一码、万国码、单一码)是一种在计算机上使用的字符编码。Unicode 是为了解决传统的字符编码方案的局限而产生的,它为每种语言中的每个字符设定了统一并且唯一的二进制编码,规定虽有的字符和符号最少由 16 位来表示(2个字节),即:2 **16 = 65536,
注:此处说的的是最少2个字节,可能更多
UTF-8,是对Unicode编码的压缩和优化,他不再使用最少使用2个字节,而是将所有的字符和符号进行分类:ascii码中的内容用1个字节保存、欧洲的字符用2个字节保存,东亚的字符用3个字节保存...
所以,python解释器在加载 .py 文件中的代码时,会对内容进行编码(默认ascill),如果是如下代码的话:
报错:ascii码无法表示中文
|
1
2
3
|
#!/usr/bin/env python
print
"你好,世界"
|
改正:应该显示的告诉python解释器,用什么编码来执行源代码,即:
|
1
2
3
4
|
#!/usr/bin/env python
# -*- coding: utf-8 -*-
print
"你好,世界"
|
4,注释。
当行注释:# 被注释内容
多行注释:'''被注释内容''',或者"""被注释内容"""
5,变量
变量是什么? 变量:把程序运行的中间结果临时的存在内存里,以便后续的代码调用。
5.1、声明变量
|
1
2
3
4
|
#!/usr/bin/env python
# -*- coding: utf-8 -*-
name
=
"taibai"
|
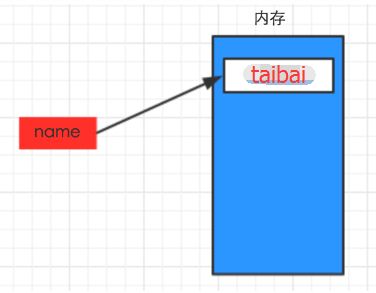
上述代码声明了一个变量,变量名为: name,变量name的值为:"taibai"
变量的作用:昵称,其代指内存里某个地址中保存的内容
5.2、变量定义的规则:
- 变量名只能是 字母、数字或下划线的任意组合
- 变量名的第一个字符不能是数字
- 以下关键字不能声明为变量名
['and', 'as', 'assert', 'break', 'class', 'continue', 'def', 'del', 'elif', 'else', 'except', 'exec', 'finally', 'for', 'from', 'global', 'if', 'import', 'in', 'is', 'lambda', 'not', 'or', 'pass', 'print', 'raise', 'return', 'try', 'while', 'with', 'yield'] - 变量的定义要具有可描述性。
5.3、推荐定义方式

#驼峰体 AgeOfOldboy = 56 NumberOfStudents = 80 #下划线 age_of_oldboy = 56 number_of_students = 80
你觉得哪种更清晰,哪种就是官方推荐的,我想你肯定会先第2种,第一种AgeOfOldboy咋一看以为是AngelaBaby
5.4、变量的赋值
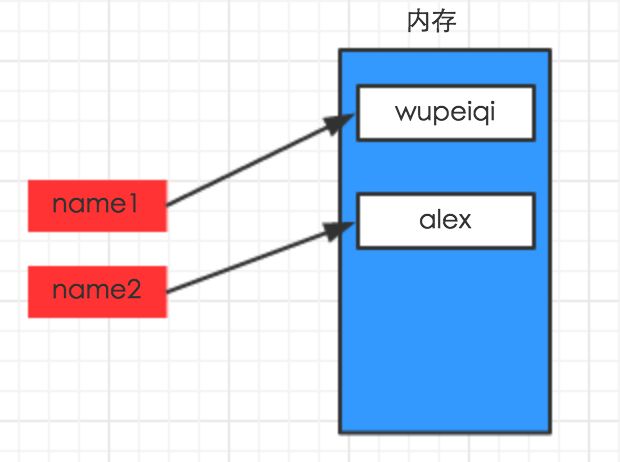
#!/usr/bin/env python # -*- coding: utf-8 -*- name1 = "wupeiqi" name2 = "alex"
#!/usr/bin/env python # -*- coding: utf-8 -*- name1 = "taibai" name2 = name1
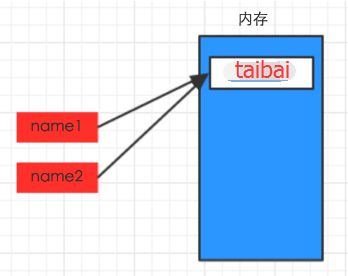
5.5、定义变量不好的方式举例
- 变量名为中文、拼音
- 变量名过长
- 变量名词不达意
6,常量
常量即指不变的量,如pai 3.141592653..., 或在程序运行过程中不会改变的量
举例,假如老男孩老师的年龄会变,那这就是个变量,但在一些情况下,他的年龄不会变了,那就是常量。在Python中没有一个专门的语法代表常量,程序员约定俗成用变量名全部大写代表常量
AGE_OF_OLDBOY = 56
在c语言中有专门的常量定义语法,
const int count = 60;一旦定义为常量,更改即会报错
7,程序交互
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# 将用户输入的内容赋值给 name 变量
name = input("请输入用户名:")
# 打印输入的内容
print(name)
执行脚本就会发现,程序会等待你输入姓名后再往下继续走。
可以让用户输入多个信息,如下
#!/usr/bin/env python # -*- coding: utf-8 -*-
name = input("What is your name?")
age = input("How old are you?")
hometown = input("Where is your hometown?")
print("Hello ",name , "your are ", age , "years old, you came from",hometown)
8,基础数据类型(初始)。
什么是数据类型?
我们人类可以很容易的分清数字与字符的区别,但是计算机并不能呀,计算机虽然很强大,但从某种角度上看又很傻,除非你明确的告诉它,1是数字,“汉”是文字,否则它是分不清1和‘汉’的区别的,因此,在每个编程语言里都会有一个叫数据类型的东东,其实就是对常用的各种数据类型进行了明确的划分,你想让计算机进行数值运算,你就传数字给它,你想让他处理文字,就传字符串类型给他。Python中常用的数据类型有多种,今天我们暂只讲3种, 数字、字符串、布尔类型
8.1、整数类型(int)。
int(整型)
在32位机器上,整数的位数为32位,取值范围为-2**31~2**31-1,即-2147483648~2147483647
在64位系统上,整数的位数为64位,取值范围为-2**63~2**63-1,即-9223372036854775808~9223372036854775807
long(长整型)
跟C语言不同,Python的长整数没有指定位宽,即:Python没有限制长整数数值的大小,但实际上由于机器内存有限,我们使用的长整数数值不可能无限大。
注意,自从Python2.2起,如果整数发生溢出,Python会自动将整数数据转换为长整数,所以如今在长整数数据后面不加字母L也不会导致严重后果了。
注意:在Python3里不再有long类型了,全都是int
>>> a= 2**64 >>> type(a) #type()是查看数据类型的方法>>> b = 2**60 >>> type(b)
除了int和long之外, 其实还有float浮点型, 复数型,但今天先不讲啦
8.2、字符串类型(str)。
在Python中,加了引号的字符都被认为是字符串!
>>> name = "Alex Li" #双引号 >>> age = "22" #只要加引号就是字符串 >>> age2 = 22 #int >>> >>> msg = '''My name is taibai, I am 22 years old!''' #我擦,3个引号也可以 >>> >>> hometown = 'ShanDong' #单引号也可以
那单引号、双引号、多引号有什么区别呢? 让我大声告诉你,单双引号木有任何区别,只有下面这种情况 你需要考虑单双的配合
msg = "My name is Alex , I'm 22 years old!"
多引号什么作用呢?作用就是多行字符串必须用多引号
msg = ''' 今天我想写首小诗, 歌颂我的同桌, 你看他那乌黑的短发, 好像一只炸毛鸡。 ''' print(msg)
字符串拼接
数字可以进行加减乘除等运算,字符串呢?让我大声告诉你,也能?what ?是的,但只能进行"相加"和"相乘"运算。
>>> name 'Alex Li' >>> age '22' >>> >>> name + age #相加其实就是简单拼接 'Alex Li22' >>> >>> name * 10 #相乘其实就是复制自己多少次,再拼接在一起 'Alex LiAlex LiAlex LiAlex LiAlex LiAlex LiAlex LiAlex LiAlex LiAlex Li'
注意,字符串的拼接只能是双方都是字符串,不能跟数字或其它类型拼接
>>> type(name),type(age2) (, ) >>> >>> name 'Alex Li' >>> age2 22 >>> name + age2 Traceback (most recent call last): File " ", line 1, in TypeError: cannot concatenate 'str' and 'int' objects #错误提示数字 和 字符 不能拼接
8.3、布尔值(True,False)。
布尔类型很简单,就两个值 ,一个True(真),一个False(假), 主要用记逻辑判断
但其实你们并不明白对么? let me explain, 我现在有2个值 , a=3, b=5 , 我说a>b你说成立么? 我们当然知道不成立,但问题是计算机怎么去描述这成不成立呢?或者说a< b是成立,计算机怎么描述这是成立呢?
没错,答案就是,用布尔类型
>>> a=3 >>> b=5 >>> >>> a > b #不成立就是False,即假 False >>> >>> a < b #成立就是True, 即真 True
9,格式化输出。
现有一练习需求,问用户的姓名、年龄、工作、爱好 ,然后打印成以下格式
------------ info of Alex Li -----------
Name : Alex Li
Age : 22
job : Teacher
Hobbie: girl
------------- end -----------------
你怎么实现呢?你会发现,用字符拼接的方式还难实现这种格式的输出,所以一起来学一下新姿势
只需要把要打印的格式先准备好, 由于里面的 一些信息是需要用户输入的,你没办法预设知道,因此可以先放置个占位符,再把字符串里的占位符与外部的变量做个映射关系就好啦
name = input("Name:")
age = input("Age:")
job = input("Job:")
hobbie = input("Hobbie:")
info = '''
------------ info of %s ----------- #这里的每个%s就是一个占位符,本行的代表 后面拓号里的 name
Name : %s #代表 name
Age : %s #代表 age
job : %s #代表 job
Hobbie: %s #代表 hobbie
------------- end -----------------
''' %(name,name,age,job,hobbie) # 这行的 % 号就是 把前面的字符串 与拓号 后面的 变量 关联起来
print(info)
%s就是代表字符串占位符,除此之外,还有%d,是数字占位符, 如果把上面的age后面的换成%d,就代表你必须只能输入数字啦
age : %d
我们运行一下,但是发现出错了。。。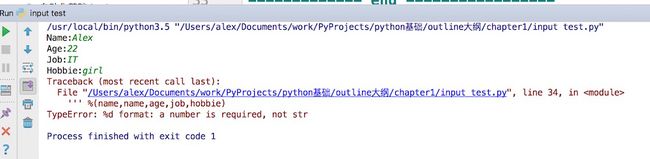
说%d需要一个数字,而不是str, what? 我们明明输入的是数字呀,22,22呀。
不用担心 ,不要相信你的眼睛我们调试一下,看看输入的到底是不是数字呢?怎么看呢?查看数据类型的方法是什么来着?type()
name = input("Name:")
age = input("Age:")
print(type(age)) 执行输出是
Name:Alex
Age:22
#怎么会是str
Job:IT
让我大声告诉你,input接收的所有输入默认都是字符串格式!
要想程序不出错,那怎么办呢?简单,你可以把str转成int
age = int( input("Age:") )
print(type(age))
肯定没问题了。相反,能不能把字符串转成数字呢?必然可以,str( yourStr )
问题:现在有这么行代码
msg = "我是%s,年龄%d,目前学习进度为80%"%('金鑫',18)
print(msg)
这样会报错的,因为在格式化输出里,你出现%默认为就是占位符的%,但是我想在上面一条语句中最后的80%就是表示80%而不是占位符,怎么办?
msg = "我是%s,年龄%d,目前学习进度为80%%"%('金鑫',18)
print(msg)
这样就可以了,第一个%是对第二个%的转译,告诉Python解释器这只是一个单纯的%,而不是占位符。
10,基本运算符。
运算符
计算机可以进行的运算有很多种,可不只加减乘除这么简单,运算按种类可分为算数运算、比较运算、逻辑运算、赋值运算、成员运算、身份运算、位运算,今天我们暂只学习算数运算、比较运算、逻辑运算、赋值运算、成员运算
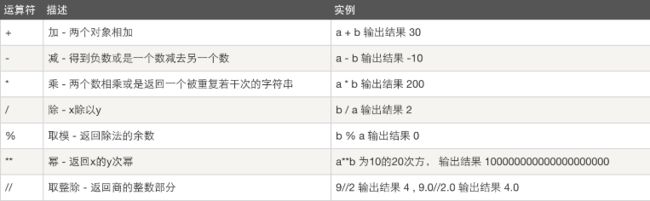
算数运算
以下假设变量:a=10,b=20
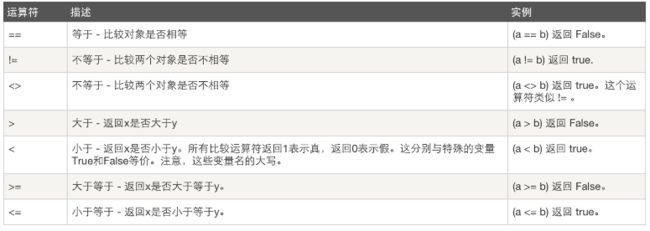
比较运算
以下假设变量:a=10,b=20
赋值运算
以下假设变量:a=10,b=20

逻辑运算

针对逻辑运算的进一步研究:
1,在没有()的情况下not 优先级高于 and,and优先级高于or,即优先级关系为( )>not>and>or,同一优先级从左往右计算。
例题:
判断下列逻辑语句的True,False。
1,3>4 or 4<3 and 1==1 2,1 < 2 and 3 < 4 or 1>2 3,2 > 1 and 3 < 4 or 4 > 5 and 2 < 1 4,1 > 2 and 3 < 4 or 4 > 5 and 2 > 1 or 9 < 8 5,1 > 1 and 3 < 4 or 4 > 5 and 2 > 1 and 9 > 8 or 7 < 6
6,not 2 > 1 and 3 < 4 or 4 > 5 and 2 > 1 and 9 > 8 or 7 < 6
2 , x or y , x为真,值就是x,x为假,值是y;
x and y, x为真,值是y,x为假,值是x。

例题:求出下列逻辑语句的值。
8 or 4 0 and 3 0 or 4 and 3 or 7 or 9 and 6
成员运算:
除了以上的一些运算符之外,Python还支持成员运算符,测试实例中包含了一系列的成员,包括字符串,列表或元组。

判断子元素是否在原字符串(字典,列表,集合)中:
例如:
#print('喜欢' in 'dkfljadklf喜欢hfjdkas')
#print('a' in 'bcvd')
#print('y' not in 'ofkjdslaf')
Python运算符优先级
以下表格列出了从最高到最低优先级的所有运算符:
| 运算符 | 描述 |
|---|---|
| ** | 指数 (最高优先级) |
| ~ + - | 按位翻转, 一元加号和减号 (最后两个的方法名为 +@ 和 -@) |
| * / % // | 乘,除,取模和取整除 |
| + - | 加法减法 |
| >> << | 右移,左移运算符 |
| & | 位 'AND' |
| ^ | | 位运算符 |
| <= < > >= | 比较运算符 |
| <> == != | 等于运算符 |
| = %= /= //= -= += *= **= | 赋值运算符 |
| is is not | 身份运算符 |
| in not in | 成员运算符 |
| not and or | 逻辑运算符 |
11,流程控制之--if。
假如把写程序比做走路,那我们到现在为止,一直走的都是直路,还没遇到过分叉口,想象现实中,你遇到了分叉口,然后你决定往哪拐必然是有所动机的。你要判断那条岔路是你真正要走的路,如果我们想让程序也能处理这样的判断怎么办? 很简单,只需要在程序里预设一些条件判断语句,满足哪个条件,就走哪条岔路。这个过程就叫流程控制。
if...else 语句
单分支
if 条件:
满足条件后要执行的代码
双分支
"""
if 条件:
满足条件执行代码
else:
if条件不满足就走这段
"""
AgeOfOldboy = 48
if AgeOfOldboy > 50 :
print("Too old, time to retire..")
else:
print("还能折腾几年!")
缩进
这里必须要插入这个缩进的知识点
你会发现,上面的if代码里,每个条件的下一行都缩进了4个空格,这是为什么呢?这就是Python的一大特色,强制缩进,目的是为了让程序知道,每段代码依赖哪个条件,如果不通过缩进来区分,程序怎么会知道,当你的条件成立后,去执行哪些代码呢?
在其它的语言里,大多通过{}来确定代码块,比如C,C++,Java,Javascript都是这样,看一个JavaScript代码的例子
var age = 56
if ( age < 50){
console.log("还能折腾")
console.log('可以执行多行代码')
}else{
console.log('太老了')
}
在有{}来区分代码块的情况下,缩进的作用就只剩下让代码变的整洁了。
Python是门超级简洁的语言,发明者定是觉得用{}太丑了,所以索性直接不用它,那怎么能区分代码块呢?答案就是强制缩进。
Python的缩进有以下几个原则:
- 顶级代码必须顶行写,即如果一行代码本身不依赖于任何条件,那它必须不能进行任何缩进
- 同一级别的代码,缩进必须一致
- 官方建议缩进用4个空格,当然你也可以用2个,如果你想被人笑话的话。
多分支
回到流程控制上来,if...else ...可以有多个分支条件
if 条件:
满足条件执行代码
elif 条件:
上面的条件不满足就走这个
elif 条件:
上面的条件不满足就走这个
elif 条件:
上面的条件不满足就走这个
else:
上面所有的条件不满足就走这段
写个猜年龄的游戏吧
age_of_oldboy = 48
guess = int(input(">>:"))
if guess > age_of_oldboy :
print("猜的太大了,往小里试试...")
elif guess < age_of_oldboy :
print("猜的太小了,往大里试试...")
else:
print("恭喜你,猜对了...")
上面的例子,根据你输入的值不同,会最多得到3种不同的结果
再来个匹配成绩的小程序吧,成绩有ABCDE5个等级,与分数的对应关系如下
A 90-100
B 80-89 C 60-79 D 40-59 E 0-39 要求用户输入0-100的数字后,你能正确打印他的对应成绩
score = int(input("输入分数:"))
if score > 100:
print("我擦,最高分才100...")
elif score >= 90:
print("A")
elif score >= 80:
print("B")
elif score >= 60:
print("C")
elif score >= 40:
print("D")
else:
print("太笨了...E")
这里有个问题,就是当我输入95的时候 ,它打印的结果是A,但是95 明明也大于第二个条件elif score >=80:呀, 为什么不打印B呢?这是因为代码是从上到下依次判断,只要满足一个,就不会再往下走啦,这一点一定要清楚呀!
12,流程控制之--while循环。
12.1,基本循环
while
条件:
# 循环体
# 如果条件为真,那么循环体则执行
# 如果条件为假,那么循环体不执行
|
12.2,循环中止语句
如果在循环的过程中,因为某些原因,你不想继续循环了,怎么把它中止掉呢?这就用到break 或 continue 语句
- break用于完全结束一个循环,跳出循环体执行循环后面的语句
- continue和break有点类似,区别在于continue只是终止本次循环,接着还执行后面的循环,break则完全终止循环
例子:break
count = 0
while count <= 100 : #只要count<=100就不断执行下面的代码
print("loop ", count)
if count == 5:
break
count +=1 #每执行一次,就把count+1,要不然就变成死循环啦,因为count一直是0
print("-----out of while loop ------")
输出
loop 0 loop 1 loop 2 loop 3 loop 4 loop 5 -----out of while loop ------
例子:continue
count = 0
while count <= 100 :
count += 1
if count > 5 and count < 95: #只要count在6-94之间,就不走下面的print语句,直接进入下一次loop
continue
print("loop ", count)
print("-----out of while loop ------")
输出
loop 1 loop 2 loop 3 loop 4 loop 5 loop 95 loop 96 loop 97 loop 98 loop 99 loop 100 loop 101 -----out of while loop ------
12.3,while ... else ..
与其它语言else 一般只与if 搭配不同,在Python 中还有个while ...else 语句
while 后面的else 作用是指,当while 循环正常执行完,中间没有被break 中止的话,就会执行else后面的语句
count = 0
while count <= 5 :
count += 1
print("Loop",count)
else:
print("循环正常执行完啦")
print("-----out of while loop ------")
输出
Loop 1 Loop 2 Loop 3 Loop 4 Loop 5 Loop 6 循环正常执行完啦 -----out of while loop ------
如果执行过程中被break啦,就不会执行else的语句啦
count = 0
while count <= 5 :
count += 1
if count == 3:break
print("Loop",count)
else:
print("循环正常执行完啦")
print("-----out of while loop ------")
输出
Loop 1 Loop 2 -----out of while loop ------
四,相关练习题。
1、使用while循环输入 1 2 3 4 5 6 8 9 10
2、求1-100的所有数的和
3、输出 1-100 内的所有奇数
4、输出 1-100 内的所有偶数
5、求1-2+3-4+5 ... 99的所有数的和
6、用户登陆(三次机会重试)
在太白老师评论有答案