- 简单了解 JVM
记得开心一点啊
jvm
目录♫什么是JVM♫JVM的运行流程♫JVM运行时数据区♪虚拟机栈♪本地方法栈♪堆♪程序计数器♪方法区/元数据区♫类加载的过程♫双亲委派模型♫垃圾回收机制♫什么是JVMJVM是JavaVirtualMachine的简称,意为Java虚拟机。虚拟机是指通过软件模拟的具有完整硬件功能的、运行在一个完全隔离的环境中的完整计算机系统(如:JVM、VMwave、VirtualBox)。JVM和其他两个虚拟机
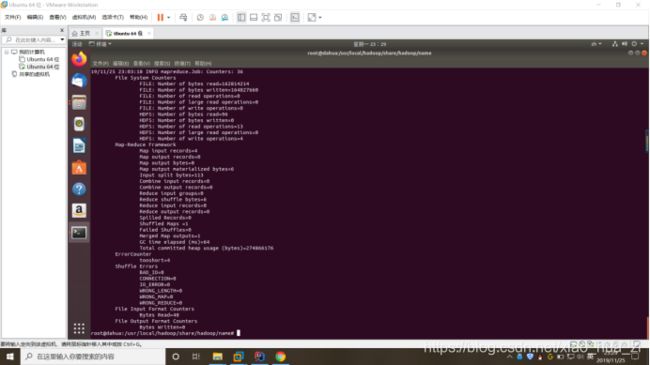
- 浅谈MapReduce
Android路上的人
Hadoop分布式计算mapreduce分布式框架hadoop
从今天开始,本人将会开始对另一项技术的学习,就是当下炙手可热的Hadoop分布式就算技术。目前国内外的诸多公司因为业务发展的需要,都纷纷用了此平台。国内的比如BAT啦,国外的在这方面走的更加的前面,就不一一列举了。但是Hadoop作为Apache的一个开源项目,在下面有非常多的子项目,比如HDFS,HBase,Hive,Pig,等等,要先彻底学习整个Hadoop,仅仅凭借一个的力量,是远远不够的。
- 程序计数器的作用
毕加涛
java
程序计数器的作用就是**用来记住下一条jvm指令的执行地址。**它的特点是**线程私有的**,也就是一人一个。然后cpu会给每个线程分配时间片,然后等待这个线程的时间片用完之后就会轮到下一个线程来执行。所以此时就需要计数器来记录线程运行的下一行指令的地址,等到下次轮到这个线程执行的时候来到上次执行的指令地址来继续执行指令。所以它的作用就是:为了保证程序的执行遵循自上而下有顺序的执行。
- Hadoop
傲雪凌霜,松柏长青
后端大数据hadoop大数据分布式
ApacheHadoop是一个开源的分布式计算框架,主要用于处理海量数据集。它具有高度的可扩展性、容错性和高效的分布式存储与计算能力。Hadoop核心由四个主要模块组成,分别是HDFS(分布式文件系统)、MapReduce(分布式计算框架)、YARN(资源管理)和HadoopCommon(公共工具和库)。1.HDFS(HadoopDistributedFileSystem)HDFS是Hadoop生
- Hadoop架构
henan程序媛
hadoop大数据分布式
一、案列分析1.1案例概述现在已经进入了大数据(BigData)时代,数以万计用户的互联网服务时时刻刻都在产生大量的交互,要处理的数据量实在是太大了,以传统的数据库技术等其他手段根本无法应对数据处理的实时性、有效性的需求。HDFS顺应时代出现,在解决大数据存储和计算方面有很多的优势。1.2案列前置知识点1.什么是大数据大数据是指无法在一定时间范围内用常规软件工具进行捕捉、管理和处理的大量数据集合,
- 分享一个基于python的电子书数据采集与可视化分析 hadoop电子书数据分析与推荐系统 spark大数据毕设项目(源码、调试、LW、开题、PPT)
计算机源码社
Python项目大数据大数据pythonhadoop计算机毕业设计选题计算机毕业设计源码数据分析spark毕设
作者:计算机源码社个人简介:本人八年开发经验,擅长Java、Python、PHP、.NET、Node.js、Android、微信小程序、爬虫、大数据、机器学习等,大家有这一块的问题可以一起交流!学习资料、程序开发、技术解答、文档报告如需要源码,可以扫取文章下方二维码联系咨询Java项目微信小程序项目Android项目Python项目PHP项目ASP.NET项目Node.js项目选题推荐项目实战|p
- 系统设计DDIA之Chapter 7 Transactions 之防止丢失更新
暴躁老哥在线刷题
SystemDesign数据库系统设计大数据系统架构DDIA
防止丢失更新涉及处理多个事务并发写入时发生的各种冲突类型。虽然“读已提交”和“快照隔离”等隔离级别管理与读取相关的冲突,但防止丢失更新需要额外的措施来处理写写冲突。丢失更新问题:当两个事务同时读取一个值,对其进行修改,然后将修改后的值写回时,会发生这种问题。一个修改可能会覆盖或“破坏”另一个修改,导致更新丢失。例子包括递增计数器、更新复杂文档,或多个用户同时编辑相同内容。防止丢失更新的解决方案:原
- STM32 的 RTC(实时时钟)详解
千千道
STM32stm32物联网单片机
目录一、引言二、RTC概述三、RTC的工作原理1.时钟源2.计数器3.闹钟功能4.备份寄存器四、RTC寄存器1.RTC_TR(TimeRegister,时间寄存器)2.RTC_DR(DateRegister,日期寄存器)3.RTC_SSR(SubsecondRegister,亚秒寄存器)4.RTC_PRER(PrescalerRegister,预分频器寄存器)5.RTC_CR(ControlReg
- hbase介绍
CrazyL-
云计算+大数据hbase
hbase是一个分布式的、多版本的、面向列的开源数据库hbase利用hadoophdfs作为其文件存储系统,提供高可靠性、高性能、列存储、可伸缩、实时读写、适用于非结构化数据存储的数据库系统hbase利用hadoopmapreduce来处理hbase、中的海量数据hbase利用zookeeper作为分布式系统服务特点:数据量大:一个表可以有上亿行,上百万列(列多时,插入变慢)面向列:面向列(族)的
- 大数据毕业设计hadoop+spark+hive知识图谱租房数据分析可视化大屏 租房推荐系统 58同城租房爬虫 房源推荐系统 房价预测系统 计算机毕业设计 机器学习 深度学习 人工智能
2401_84572577
程序员大数据hadoop人工智能
做了那么多年开发,自学了很多门编程语言,我很明白学习资源对于学一门新语言的重要性,这些年也收藏了不少的Python干货,对我来说这些东西确实已经用不到了,但对于准备自学Python的人来说,或许它就是一个宝藏,可以给你省去很多的时间和精力。别在网上瞎学了,我最近也做了一些资源的更新,只要你是我的粉丝,这期福利你都可拿走。我先来介绍一下这些东西怎么用,文末抱走。(1)Python所有方向的学习路线(
- 《android进阶之光》——多线程编程(上)
TAING要一直努力
读书笔记
今天了解了下多线程编程,知识点如下:进程与线程:进程是什么?线程是什么?进程可以看作是程序的实体,是线程的容器,是受操作系统管理的基本运行单元,例如exe文件就是一个进程。线程是进程运行的一些子任务,是操作系统调度的最小单元,各线程拥有自己的计数器,堆栈,局部变量等,也可以访问线程间共享的内存。线程的状态有哪些?新创建,可运行,等待,超时等待,阻塞,终止怎么创建一个线程?-三种方法第一种,MyTr
- Spark集群的三种模式
MelodyYN
#Sparksparkhadoopbigdata
文章目录1、Spark的由来1.1Hadoop的发展1.2MapReduce与Spark对比2、Spark内置模块3、Spark运行模式3.1Standalone模式部署配置历史服务器配置高可用运行模式3.2Yarn模式安装部署配置历史服务器运行模式4、WordCount案例1、Spark的由来定义:Hadoop主要解决,海量数据的存储和海量数据的分析计算。Spark是一种基于内存的快速、通用、可
- 月度总结 | 2022年03月 | 考研与就业的抉择 | 确定未来走大数据开发路线
「已注销」
个人总结hadoop
一、时间线梳理3月3日,寻找到同专业的就业伙伴3月5日,着手准备Java八股文,决定先走Java后端路线3月8月,申请到了校图书馆的考研专座,决定暂时放弃就业,先准备考研,买了数学和408的资料书3月9日-3月13日,因疫情原因,宿舍区暂封,这段时间在准备考研,发现内容特别多3月13日-3月19日,大部分时间在刷Hadoop、Zookeeper、Kafka的视频,同时在准备实习的项目3月20日,退
- HBase介绍
mingyu1016
数据库
概述HBase是一个分布式的、面向列的开源数据库,源于google的一篇论文《bigtable:一个结构化数据的分布式存储系统》。HBase是GoogleBigtable的开源实现,它利用HadoopHDFS作为其文件存储系统,利用HadoopMapReduce来处理HBase中的海量数据,利用Zookeeper作为协同服务。HBase的表结构HBase以表的形式存储数据。表有行和列组成。列划分为
- Java中的大数据处理框架对比分析
省赚客app开发者
java开发语言
Java中的大数据处理框架对比分析大家好,我是微赚淘客系统3.0的小编,是个冬天不穿秋裤,天冷也要风度的程序猿!今天,我们将深入探讨Java中常用的大数据处理框架,并对它们进行对比分析。大数据处理框架是现代数据驱动应用的核心,它们帮助企业处理和分析海量数据,以提取有价值的信息。本文将重点介绍ApacheHadoop、ApacheSpark、ApacheFlink和ApacheStorm这四种流行的
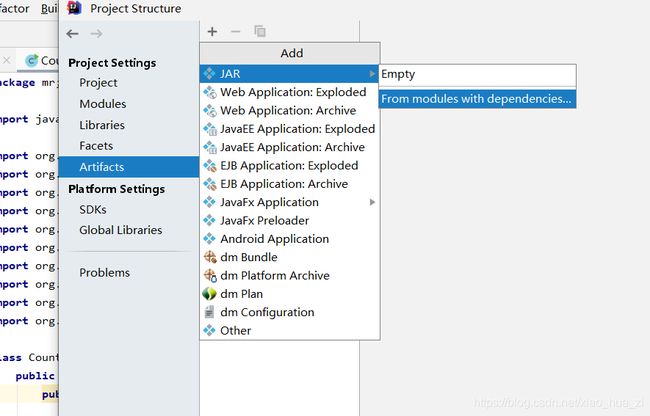
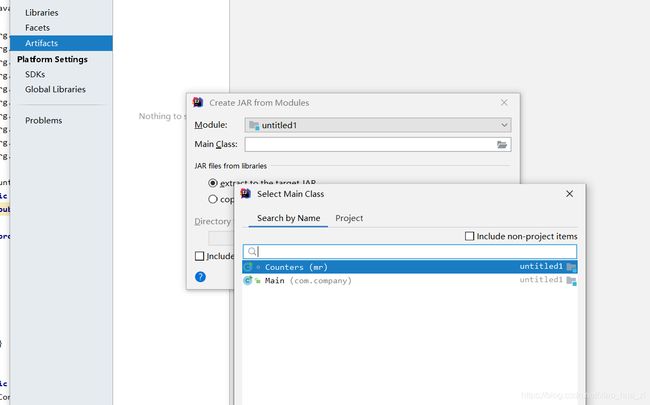
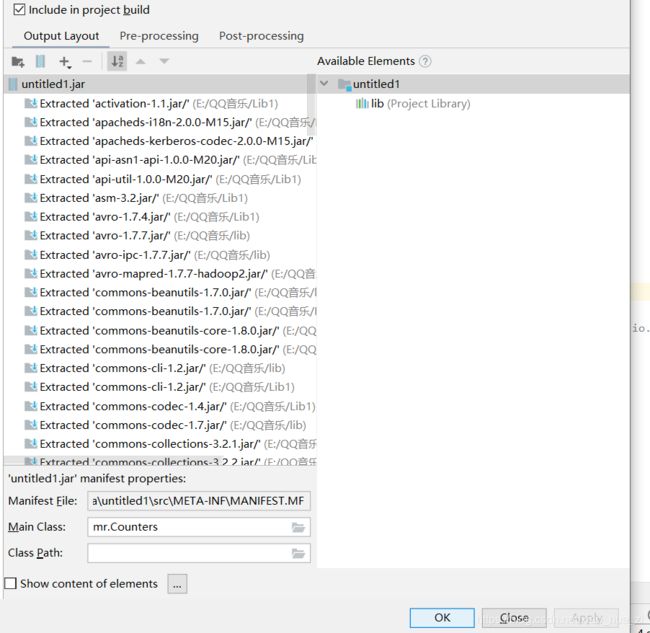
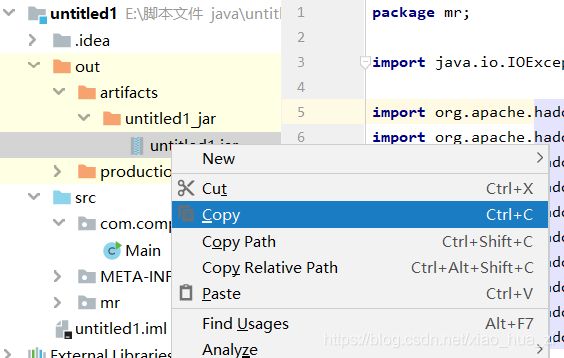
- Hadoop windows intelij 跑 MR WordCount
piziyang12138
一、软件环境我使用的软件版本如下:IntellijIdea2017.1Maven3.3.9Hadoop分布式环境二、创建maven工程打开Idea,file->new->Project,左侧面板选择maven工程。(如果只跑MapReduce创建java工程即可,不用勾选Creatfromarchetype,如果想创建web工程或者使用骨架可以勾选)image.png设置GroupId和Artif
- Hadoop学习第三课(HDFS架构--读、写流程)
小小程序员呀~
数据库hadoop架构bigdata
1.块概念举例1:一桶水1000ml,瓶子的规格100ml=>需要10个瓶子装完一桶水1010ml,瓶子的规格100ml=>需要11个瓶子装完一桶水1010ml,瓶子的规格200ml=>需要6个瓶子装完块的大小规格,只要是需要存储,哪怕一点点,也是要占用一个块的块大小的参数:dfs.blocksize官方默认的大小为128M官网:https://hadoop.apache.org/docs/r3.
- hadoop启动HDFS命令
m0_67401228
java搜索引擎linux后端
启动命令:/hadoop/sbin/start-dfs.sh停止命令:/hadoop/sbin/stop-dfs.sh
- 能力追上博士生,OpenAI发布最强o1系列模型
杰克尼
杂谈chatgpt
9月13日凌晨1点,OpenAI发布o1系列模型,包括o1-preview(下称o1预览版)和o1-mini。针对这一消息,该公司创始人SamAltman在X上表示:“nomorepatience,jimmy.(需要耐心等待的时刻结束了)”OpenAI表示:“该模型代表了人工智能能力的新水平。鉴于此,我们将计数器重置为1,并将该系列命名为o1。”这也意味着,o1就是此前坊间盛传即将发布的“草莓”模
- redux 的 toolkit使用教程和demo
天下一场夢
前端面试题Reactreact.jsjavascript前端
React的redux-toolkit是一个简化Redux开发的工具包,它提供了一系列的简化方法来处理常见的Redux模式。下面我将指导你如何使用redux-toolkit创建一个简单的计数器应用。第一步:安装依赖首先你需要确保你的项目中已经安装了react,react-dom,@reduxjs/toolkit,和react-redux。你可以通过以下命令来安装它们(如果你还没有创建项目的话,可以
- 【计算机毕设-大数据方向】基于Hadoop的电商交易数据分析可视化系统的设计与实现
程序员-石头山
大数据实战案例大数据hadoop毕业设计毕设
博主介绍:✌全平台粉丝5W+,高级大厂开发程序员,博客之星、掘金/知乎/华为云/阿里云等平台优质作者。【源码获取】关注并且私信我【联系方式】最下边感兴趣的可以先收藏起来,同学门有不懂的毕设选题,项目以及论文编写等相关问题都可以和学长沟通,希望帮助更多同学解决问题前言随着电子商务行业的迅猛发展,电商平台积累了海量的数据资源,这些数据不仅包括用户的基本信息、购物记录,还包括用户的浏览行为、评价反馈等多
- 分布式离线计算—Spark—基础介绍
测试开发abbey
人工智能—大数据
原文作者:饥渴的小苹果原文地址:【Spark】Spark基础教程目录Spark特点Spark相对于Hadoop的优势Spark生态系统Spark基本概念Spark结构设计Spark各种概念之间的关系Executor的优点Spark运行基本流程Spark运行架构的特点Spark的部署模式Spark三种部署方式Hadoop和Spark的统一部署摘要:Spark是基于内存计算的大数据并行计算框架Spar
- spark常用命令
我是浣熊的微笑
spark
查看报错日志:yarnlogsapplicationIDspark2-submit--masteryarn--classcom.hik.ReadHdfstest-1.0-SNAPSHOT.jar进入$SPARK_HOME目录,输入bin/spark-submit--help可以得到该命令的使用帮助。hadoop@wyy:/app/hadoop/spark100$bin/spark-submit--
- spark启动命令
学不会又听不懂
spark大数据分布式
hadoop启动:cd/root/toolssstart-dfs.sh,只需在hadoop01上启动stop-dfs.sh日志查看:cat/root/toolss/hadoop/logs/hadoop-root-datanode-hadoop03.outzookeeper启动:cd/root/toolss/zookeeperbin/zkServer.shstart,三台都要启动bin/zkServ
- 编程常用命令总结
Yellow0523
LinuxBigData大数据
编程命令大全1.软件环境变量的配置JavaScalaSparkHadoopHive2.大数据软件常用命令Spark基本命令Spark-SQL命令Hive命令HDFS命令YARN命令Zookeeper命令kafka命令Hibench命令MySQL命令3.Linux常用命令Git命令conda命令pip命令查看Linux系统的详细信息查看Linux系统架构(X86还是ARM,两种方法都可)端口号命令L
- 单片机程序架构-时间片轮询架构
Jerry---
嵌入式单片机
1定时器复用说明(1)首先定义任务数、任务定时初值(任务轮询时间=定时初值*定时器中断时间)、任务定时计数器;(2)在定时器中断服务函数中添加【复用函数】。#defineTASK_NUM3//这里定义的任务数为3,表示有三个任务会使用此定时器定时。uint16_tTaskCount[TASK_NUM];//这里为三个任务定义三个变量来存放定时值uint8_tTaskMark[TASK_NUM];/
- 【Azure Redis 缓存】Redis的指标显示CPU为70%,而Service Load却达到了100%。这两个指标意义的解释及如何缓解呢?
云中路灯
问题描述为什么Redis的指标显示CPU为70%,而ServiceLoad却达到了100%,如何来解释这两个指标,以及如何来缓解这样的情况呢?问题回答CPU指标:该值表示的是用于Redis的Azure缓存服务器的CPU使用率(以百分比表示)。此值映射到操作系统\Processor(_Total)%ProcessorTime性能计数器。ServerLoad指标:该指标表示Redis服务器忙于处理消息
- Hadoop常见面试题整理及解答
叶青舟
Linuxhdfs大数据hadooplinux
Hadoop常见面试题整理及解答一、基础知识篇:1.把数据仓库从传统关系型数据库转到hadoop有什么优势?答:(1)关系型数据库成本高,且存储空间有限。而Hadoop使用较为廉价的机器存储数据,且Hadoop可以将大量机器构建成一个集群,并在集群中使用HDFS文件系统统一管理数据,极大的提高了数据的存储及处理能力。(2)关系型数据库仅支持标准结构化数据格式,Hadoop不仅支持标准结构化数据格式
- JVM是什么?
.suki...
JVM1024程序员节
JVM是java虚拟机栈,用于运行java执行字节码文件的。是java实现跨平台的核心机制,因为它的目的是使用相同的字节码文件,在不同的操作系统运行的结果相同。一、java内存模型在JDK1.8之前,它是分为线程共享和线程私有的,在线程共享的部分分为堆区和方法区;在线程私有的部分分为jvm虚拟机栈、程序计数器、本地方法栈。在1.8之后,它是将方法区换为元空间。jvm虚拟机栈:是由一个个的栈帧组成,
- 【JVM】Java内存分配与回收:深入理解Java内存管理
逐星ing
Java#jvm八股文/面试题jvmjava开发语言
Java内存分配与回收:深入理解Java内存管理引言Java虚拟机(JVM)的内存管理是确保Java应用程序性能和稳定性的关键。理解Java的内存分配方式和回收过程对于开发者来说至关重要。基础知识JVM内存模型:JVM内存分为堆(Heap)、栈(Stack)、方法区(MethodArea)和程序计数器(ProgramCounter)。堆(Heap):存储对象实例和数组。栈(Stack):存储局部变
- jquery实现的jsonp掉java后台
知了ing
javajsonpjquery
什么是JSONP?
先说说JSONP是怎么产生的:
其实网上关于JSONP的讲解有很多,但却千篇一律,而且云里雾里,对于很多刚接触的人来讲理解起来有些困难,小可不才,试着用自己的方式来阐释一下这个问题,看看是否有帮助。
1、一个众所周知的问题,Ajax直接请求普通文件存在跨域无权限访问的问题,甭管你是静态页面、动态网页、web服务、WCF,只要是跨域请求,一律不准;
2、
- Struts2学习笔记
caoyong
struts2
SSH : Spring + Struts2 + Hibernate
三层架构(表示层,业务逻辑层,数据访问层) MVC模式 (Model View Controller)
分层原则:单向依赖,接口耦合
1、Struts2 = Struts + Webwork
2、搭建struts2开发环境
a>、到www.apac
- SpringMVC学习之后台往前台传值方法
满城风雨近重阳
springMVC
springMVC控制器往前台传值的方法有以下几种:
1.ModelAndView
通过往ModelAndView中存放viewName:目标地址和attribute参数来实现传参:
ModelAndView mv=new ModelAndView();
mv.setViewName="success
- WebService存在的必要性?
一炮送你回车库
webservice
做Java的经常在选择Webservice框架上徘徊很久,Axis Xfire Axis2 CXF ,他们只有一个功能,发布HTTP服务然后用XML做数据传输。
是的,他们就做了两个功能,发布一个http服务让客户端或者浏览器连接,接收xml参数并发送xml结果。
当在不同的平台间传输数据时,就需要一个都能解析的数据格式。
但是为什么要使用xml呢?不能使json或者其他通用数据
- js年份下拉框
3213213333332132
java web ee
<div id="divValue">test...</div>测试
//年份
<select id="year"></select>
<script type="text/javascript">
window.onload =
- 简单链式调用的实现技术
归来朝歌
方法调用链式反应编程思想
在编程中,我们可以经常遇到这样一种场景:一个实例不断调用它自身的方法,像一条链条一样进行调用
这样的调用你可能在Ajax中,在页面中添加标签:
$("<p>").append($("<span>").text(list[i].name)).appendTo("#result");
也可能在HQ
- JAVA调用.net 发布的webservice 接口
darkranger
webservice
/**
* @Title: callInvoke
* @Description: TODO(调用接口公共方法)
* @param @param url 地址
* @param @param method 方法
* @param @param pama 参数
* @param @return
* @param @throws BusinessException
- Javascript模糊查找 | 第一章 循环不能不重视。
aijuans
Way
最近受我的朋友委托用js+HTML做一个像手册一样的程序,里面要有可展开的大纲,模糊查找等功能。我这个人说实在的懒,本来是不愿意的,但想起了父亲以前教我要给朋友搞好关系,再加上这也可以巩固自己的js技术,于是就开始开发这个程序,没想到却出了点小问题,我做的查找只能绝对查找。具体的js代码如下:
function search(){
var arr=new Array("my
- 狼和羊,该怎么抉择
atongyeye
工作
狼和羊,该怎么抉择
在做一个链家的小项目,只有我和另外一个同事两个人负责,各负责一部分接口,我的接口写完,并全部测联调试通过。所以工作就剩下一下细枝末节的,工作就轻松很多。每天会帮另一个同事测试一些功能点,协助他完成一些业务型不强的工作。
今天早上到公司没多久,领导就在QQ上给我发信息,让我多协助同事测试,让我积极主动些,有点责任心等等,我听了这话,心里面立马凉半截,首先一个领导轻易说
- 读取android系统的联系人拨号
百合不是茶
androidsqlite数据库内容提供者系统服务的使用
联系人的姓名和号码是保存在不同的表中,不要一下子把号码查询来,我开始就是把姓名和电话同时查询出来的,导致系统非常的慢
关键代码:
1, 使用javabean操作存储读取到的数据
package com.example.bean;
/**
*
* @author Admini
- ORACLE自定义异常
bijian1013
数据库自定义异常
实例:
CREATE OR REPLACE PROCEDURE test_Exception
(
ParameterA IN varchar2,
ParameterB IN varchar2,
ErrorCode OUT varchar2 --返回值,错误编码
)
AS
/*以下是一些变量的定义*/
V1 NUMBER;
V2 nvarc
- 查看端号使用情况
征客丶
windows
一、查看端口
在windows命令行窗口下执行:
>netstat -aon|findstr "8080"
显示结果:
TCP 127.0.0.1:80 0.0.0.0:0 &
- 【Spark二十】运行Spark Streaming的NetworkWordCount实例
bit1129
wordcount
Spark Streaming简介
NetworkWordCount代码
/*
* Licensed to the Apache Software Foundation (ASF) under one or more
* contributor license agreements. See the NOTICE file distributed with
- Struts2 与 SpringMVC的比较
BlueSkator
struts2spring mvc
1. 机制:spring mvc的入口是servlet,而struts2是filter,这样就导致了二者的机制不同。 2. 性能:spring会稍微比struts快。spring mvc是基于方法的设计,而sturts是基于类,每次发一次请求都会实例一个action,每个action都会被注入属性,而spring基于方法,粒度更细,但要小心把握像在servlet控制数据一样。spring
- Hibernate在更新时,是可以不用session的update方法的(转帖)
BreakingBad
Hibernateupdate
地址:http://blog.csdn.net/plpblue/article/details/9304459
public void synDevNameWithItil()
{Session session = null;Transaction tr = null;try{session = HibernateUtil.getSession();tr = session.beginTran
- 读《研磨设计模式》-代码笔记-观察者模式
bylijinnan
java设计模式
声明: 本文只为方便我个人查阅和理解,详细的分析以及源代码请移步 原作者的博客http://chjavach.iteye.com/
import java.util.ArrayList;
import java.util.List;
import java.util.Observable;
import java.util.Observer;
/**
* “观
- 重置MySQL密码
chenhbc
mysql重置密码忘记密码
如果你也像我这么健忘,把MySQL的密码搞忘记了,经过下面几个步骤就可以重置了(以Windows为例,Linux/Unix类似):
1、关闭MySQL服务
2、打开CMD,进入MySQL安装目录的bin目录下,以跳过权限检查的方式启动MySQL
mysqld --skip-grant-tables
3、新开一个CMD窗口,进入MySQL
mysql -uroot
- 再谈系统论,控制论和信息论
comsci
设计模式生物能源企业应用领域模型
再谈系统论,控制论和信息论
偶然看
- oracle moving window size与 AWR retention period关系
daizj
oracle
转自: http://tomszrp.itpub.net/post/11835/494147
晚上在做11gR1的一个awrrpt报告时,顺便想调整一下AWR snapshot的保留时间,结果遇到了ORA-13541这样的错误.下面是这个问题的发生和解决过程.
SQL> select * from v$version;
BANNER
-------------------
- Python版B树
dieslrae
python
话说以前的树都用java写的,最近发现python有点生疏了,于是用python写了个B树实现,B树在索引领域用得还是蛮多了,如果没记错mysql的默认索引好像就是B树...
首先是数据实体对象,很简单,只存放key,value
class Entity(object):
'''数据实体'''
def __init__(self,key,value)
- C语言冒泡排序
dcj3sjt126com
算法
代码示例:
# include <stdio.h>
//冒泡排序
void sort(int * a, int len)
{
int i, j, t;
for (i=0; i<len-1; i++)
{
for (j=0; j<len-1-i; j++)
{
if (a[j] > a[j+1]) // >表示升序
- 自定义导航栏样式
dcj3sjt126com
自定义
-(void)setupAppAppearance
{
[[UILabel appearance] setFont:[UIFont fontWithName:@"FZLTHK—GBK1-0" size:20]];
[UIButton appearance].titleLabel.font =[UIFont fontWithName:@"FZLTH
- 11.性能优化-优化-JVM参数总结
frank1234
jvm参数性能优化
1.堆
-Xms --初始堆大小
-Xmx --最大堆大小
-Xmn --新生代大小
-Xss --线程栈大小
-XX:PermSize --永久代初始大小
-XX:MaxPermSize --永久代最大值
-XX:SurvivorRatio --新生代和suvivor比例,默认为8
-XX:TargetSurvivorRatio --survivor可使用
- nginx日志分割 for linux
HarborChung
nginxlinux脚本
nginx日志分割 for linux 默认情况下,nginx是不分割访问日志的,久而久之,网站的日志文件将会越来越大,占用空间不说,如果有问题要查看网站的日志的话,庞大的文件也将很难打开,于是便有了下面的脚本 使用方法,先将以下脚本保存为 cutlog.sh,放在/root 目录下,然后给予此脚本执行的权限
复制代码代码如下:
chmo
- Spring4新特性——泛型限定式依赖注入
jinnianshilongnian
springspring4泛型式依赖注入
Spring4新特性——泛型限定式依赖注入
Spring4新特性——核心容器的其他改进
Spring4新特性——Web开发的增强
Spring4新特性——集成Bean Validation 1.1(JSR-349)到SpringMVC
Spring4新特性——Groovy Bean定义DSL
Spring4新特性——更好的Java泛型操作API
Spring4新
- centOS安装GCC和G++
liuxihope
centosgcc
Centos支持yum安装,安装软件一般格式为yum install .......,注意安装时要先成为root用户。
按照这个思路,我想安装过程如下:
安装gcc:yum install gcc
安装g++: yum install g++
实际操作过程发现,只能有gcc安装成功,而g++安装失败,提示g++ command not found。上网查了一下,正确安装应该
- 第13章 Ajax进阶(上)
onestopweb
Ajax
index.html
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
<html xmlns="http://www.w3.org/
- How to determine BusinessObjects service pack and fix pack
blueoxygen
BO
http://bukhantsov.org/2011/08/how-to-determine-businessobjects-service-pack-and-fix-pack/
The table below is helpful. Reference
BOE XI 3.x
12.0.0.
y BOE XI 3.0 12.0.
x.
y BO
- Oracle里的自增字段设置
tomcat_oracle
oracle
大家都知道吧,这很坑,尤其是用惯了mysql里的自增字段设置,结果oracle里面没有的。oh,no 我用的是12c版本的,它有一个新特性,可以这样设置自增序列,在创建表是,把id设置为自增序列
create table t
(
id number generated by default as identity (start with 1 increment b
- Spring Security(01)——初体验
yang_winnie
springSecurity
Spring Security(01)——初体验
博客分类: spring Security
Spring Security入门安全认证
首先我们为Spring Security专门建立一个Spring的配置文件,该文件就专门用来作为Spring Security的配置



 这样就成功了。
这样就成功了。