lifelong learning 部分总结
注: 深度学习领域小白,文章如有问题,欢迎批评指正。
部分翻译论文(Continual lifelong learning with neural networks: A review)发表在 Neural Network,部分来自李宏毅lifelong learning,对于持续学习的研究在研究反向传播的时候就开始了,持续学习也是未来的研究热点。
lifelong learning, never ending learning, incremental learning(增量学习)
随着时间的推移,通过适应新知识,同时保留以前学到的经验,不断学习的能力被称为持续学习或终身学习。对于机器学习和神经网络模型来说,终身学习仍然是一个长期存在的挑战,因为从非平稳数据分布中不断获取增量可用信息通常会导致灾难性的遗忘或干扰。
几种方法:
- structural plasticity
- memory replay
- curriculum
- transfer learning
- intrinsic motivation
- multisensory integration
终身学习系统被定义为一种能够从连续的信息流中学习的自适应算法,随着时间的推移,这些信息逐渐可用,并且所要学习的任务数量(例如,分类任务中的成员类)不是预先定义的。关键的是,新信息的容纳应该在没有灾难性遗忘或干扰的情况下发生。
对于终身学习来说,需要解决的主要有三个方面的问题:
- 知识保留(Knowledge Retention): 如果只使用一个模型来不断的学习不同的任务,自然希望它在学习新的任务的时候,也不要忘记已经学习到的东西。同时也要避免为了单纯的保留之前已经学习到的东西而停止学习,这对于现有的神经网络就是第一个很大的挑战;
- 知识迁移(Knowledge Transfer):希望模型可以使用已经学习到的东西来帮助解决新的问题,达到触类旁通的效果。
- 模型扩展(Model Expansion):模型可以自己根据问题的复杂度进行扩展,变为更加复杂的模型。而目前使用神经网络时,用户都是根据自己的任务预定义好了模型的结构,因此解决这个问题十分的困难。
可以从三个关键方面来避免灾难性遗忘:
- 为新知识分配额外的神经资源
- 如果资源是固定的,则使用非重叠表示法
- 交织旧知识作为新知识的呈现

1. 正则化方法
通过对神经网络学习的参数加以约束来减轻灾难性遗忘。实际上,通过在损失函数中加惩罚项使模型参数受限地变动,阻碍在旧任务上重要参数的变化。

典型算法:EWC (Elastic Weight Consolidation, 2017, DeepMind)

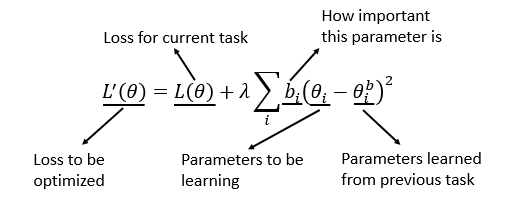
bi为参数重要性权重,为了最小化损失函数,显然重要性大的参数变化应尽量小,反之。
参考资料:
Elastic Weight Consolidation (EWC) http://www.citeulike.org/group/15400/article/14311063
Synaptic Intelligence (SI) https://arxiv.org/abs/1703.04200
Memory Aware Synapses (MAS) https://arxiv.org/abs/1711.09601 MAS相对于EWC的改进是无监督的。
缺点:
- 任务差异较大时不适用
- 忽略了参数之间的关联性
典型算法:PathNet (2017, DeepMind)
PathNet前身: Progressive Neural Network,即在新的任务上训练模型时,使用之前已经训练得到的所有模型的参数作为新模型的初始化参数,而不是使用参数的随机初始化。
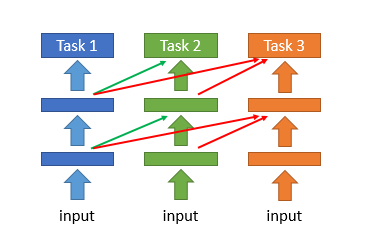
PathNet:

PathNet是由神经网络组成的网络,将训练后的第一个任务的路径所在的点的神经网络模块参数固定,然后初始化其它模块的参数,继续训练下一个任务。
缺点:
- 要求每个任务都有一个独立的输出层,这会阻止其以增量方式学习新的类
典型算法:GEM (Gradient Episodic Memory, NIPS2017) (正则化方法)
参考资料:
GEM: https://arxiv.org/abs/1706.08840
A-GEM: https://arxiv.org/abs/1812.00420
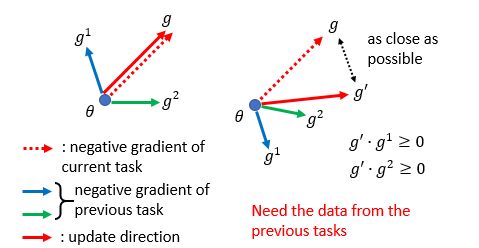
它的原理如下所示,红色虚线箭头g表示前面任务损失函数梯度下降最快方向,绿色箭头和蓝色箭头表示新任务损失函数梯度下降最快的方向。GEM所做的是希望之前任务梯度下降的方向靠近新任务梯度下降的方向,如红色实线箭头g′所示,同时又要求g和g′不要离得太远,表示希望模型不要忘记已经学到的东西。
总结:
正则化方法,提供了一种减轻灾难性遗忘的方法,然后大多数情况下要在新旧任务之间的性能做一个权衡。
2. 动态体系结构
当更新的任务有相当不同的分布时,它的训练就会开始失败。可以使用另一种技术来确保更新的数据可以通过增加网络的容量来表示,通过增加额外的神经元来做到这一点。
典型算法:DEN (2018, ICLR)

总结:
这种方法可以有效缓解灾难性的遗忘,但会导致体系结构的复杂性随着学习任务的数量而增加。
3. 互补学习系统与记忆重现
典型算法:iCaRL: Incremental Classifier and Representation Learning (https://arxiv.org/abs/1611.07725)
典型算法:GeppNet (2015)
担心模型在学习新任务的时候忘了旧任务,那么可以直接通过不断复习回顾的方式来解决。在模型学习新任务的同时混合原来任务的数据,让模型能够学习新任务的同时兼顾的考虑旧任务。不过,这样做有一个不太好的地方就是我们需要一直保存所有旧任务的数据,并且同一个数据会出现多次重复学习的情况。
一种直接利用“episodic memory”的方式是把旧任务样本添加到当前任务的样本中一起进行训练。但仍然需要解决,在少数样本上的过拟合问题。
问题:

4. 生成模型
典型算法:Learning without forgetting (LwF, https://arxiv.org/abs/1606.09282)(可以算作生成模型)

它可以是VAE、GAN等,既然无法存储所有的训练数据,那么就使用一个生成模型来学习已经训练过的数据的关键信息,当在解决下一个任务时,就用生成模型生成一些之前的数据来同时训练。这样既解决了数据存储的问题,又使用了前面所讲的同时在混合数据集上训练一个模型的想法。

参考文献:
Shin, H., Lee, J. K., Kim, J. & Kim, J. Continual learning with deep generative replay, NIPS 2017.
Kemker, R. & Kanan, C. Fearnet: Brain-inspired model for incremental learning, ICLR 2018.
5. 其它模型
Expert Gate: 原理是额外引入了一个Gate,在训练之前比较新任务和之前的哪个任务比较相似,然后使用相似任务上得到的模型的参数初始化新模型的参数。
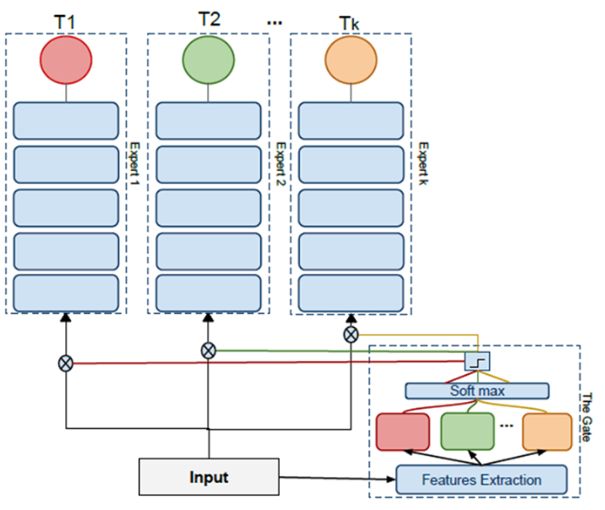
Net2Net: 利用知识迁移来解决大型网络的训练速度慢的问题,例如先训练一个小的网络,然后Net2Net,训练一个更大的网络,训练更大的网络时可以利用在小网络中已经训练好的权重,使得再训练大型的网络速度就变的非常快,利用小网络的权重的这个过程就是知识迁移的过程。
参考资料:
Net2Net: Accelerating Learning via Knowledge Transfer https://arxiv.org/abs/1511.05641
Expand the network only when the training accuracy of the current task is not good enough. https://arxiv.org/abs/1811.07017
另外部分参考博文:https://blog.csdn.net/Forlogen/article/details/90581326