第十三章:数据库支持
1:Python的数据库API
1)全局变量:
API级别是个字符串常量,可能是1.0或2.0
线程安全性等级(threadsafety)是个取值范围为0~3的整数。0表示线程完全不共享模块,而3表示模块是完全线程安全的。1表示线程本身可以共享模块,但不对连接共享。如果不使用多个线程,那完全不用担心这个变量
参数风格(paramstyle)表示在执行多次类似查询的时候,参数是如何被拼接到SQL查询中的。值'format'表示标准的字符串格式化,可在参数中进行拼接的地方插入%s。而值'pyformat'表示扩展的格式化代码,用于字典拼接中,比如%(foo)。除了Python风格之外,还有三种接合方式:'qmark'的意思是使用问号,而'numeric'表示使用:1或者:2格式的字段(数字表示参数的序号),而'named'表示:foobar这样的字段,其中foobar为参数名。
2)异常
3)连接和游标
为了使用基础数据库系统,首先必须连接到它。这个时候使用connect函数,按下表的参数顺序传递它们,参数类型都为字符串:
connect函数返回连接对象,这个对象表示目前和数据库的会话。连接对象支持的方法如下表:
cursor方法将引入另外一个主题:游标对象。通过游标执行SQL查询并检查结果。游标是比连接支持更多的方法,而且可能在程序中更好用: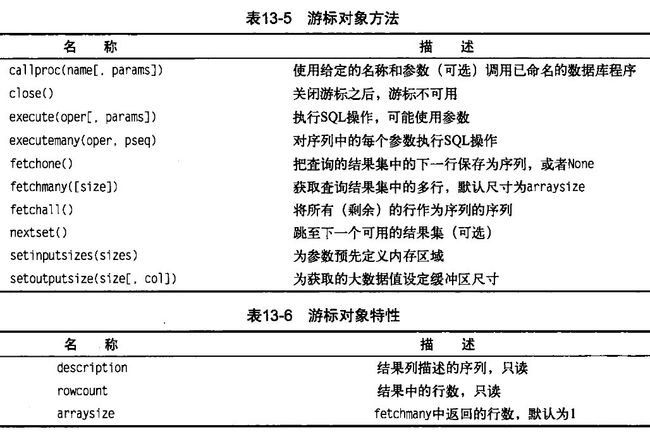
4)类型:数据库对插入到具有某种类型的列中的值有不同的要求,是为了能正确地与基础SQL数据库进行交互操作,DB API定义了用于特殊类型和值的构造函数及常量(单例模式)
2:SQLite和PySQLite
实例:

 View Code
View Code
import sqlite3 def convert(value): if value.startswith('~'): return value.strip('~') if not value: value = '0' return float(value) conn = sqlite3.connect('food.db') curs = conn.cursor() curs.execute(''' CREATE TABLE food ( id TEXT PRIMARY KEY, desc TEXT, water FLOAT, kcal FLOAT, protein FLOAT, fat FLOAT, ash FLOAT, carbs FLOAT, fiber FLOAT, sugar FLOAT ) ''') query = 'INSERT INTO food VALUES (?,?,?,?,?,?,?,?,?,?)' for line in open('ABBREV.txt'): fields = line.split('^') field_count = len(fields) vals = [convert(f) for f in fields[:field_count]] curs.execute(query, vals) conn.commit() conn.close()
查询:
View Code
import sqlite3,sys conn = sqlite3.connect('food.db') curs = conn.cursor() query = 'SELECT * FROM food WHERE %s ' % sys.argv[1] print(query) curs.execute(query) names = [f[0] for f in curs.description] for row in curs.fetchall(): for pair in zip(names,row): print('%s: %s' % pair) print()
小结
Python DB API:提供了简单、标准化的数据库接口,所以数据库的包装模块都应当遵循这个接口,以易于编写跨数据库的程序
连接:连接对象代表的是和SQL数据库的通信连接。使用cursor方法可以从它那获取独立的游标。通过连接对象可以提交或回滚事务
游标:用于执行查询和检查结果。
类型和特殊值:DB API标准指定了一组构造函数和特殊值的名字。构造函数处理日期和时间对象以及二进制数据对象。特殊值用来表示关系型数据库的类型,如STRING、NUMBER和DATATIME
SQLite:小型的嵌入式SQL数据库,它的python包装叫做PYSQLite。速度快,易于使用,不需要建立单独的服务器
第十四章:网络编程
1:几个网络设计模块
1)socket模块:在网络编程中的一个基本组件就是套接字(socket)。套接字主要是两个程序之间的“信息通道”。套接字包括两个:服务器套接字和客户机套接字。创建一个服务器套接字后,让它等待连接。这样它就在某个网络地址处(IP地址和一个端口号的组合)监听。
处理客户端套接字通常比处理服务端套接字容易,因为服务器必须准备随时处理客户端的连接,同时还要处理多个连接,而客户机只是简单地连接,完成事务,断开连接。
一个套接字就是一个socket模块中的socket类的实例。它的实例化需要3个参数:第1个参数是地址族(默认是socket.AF_INET);第2个参数是流(socket.SOCK_STREAM,默认值)或数据报(socket.SOCK_DGRAM)套接字;第3个参数是使用的协议(默认是0,使用默认值即可)。
服务端套接字使用bind方法后,再调用listen方法去监听这个给定的地址。客户端套接字使用connect方法连接到服务器在connect方法中使用的地址与bind方法中的地址相同(在服务端能实现很多功能,如socket.gethostname得到当前主机名)。这种情况下,一个地址就是一个格式为(host,port)的元组,其中host是主机名(比如www.github.com),port就是端口号。listen方法只有一个参数,即服务器未处理的连接的长度(即允许排队等待的连接数目,这些连接在停止接收之前等待接收)。
服务端套接字开始监听后,它就可以接受客户端的连接。这个步骤使用accept方法来完成。这个方法会阻塞(等待)直到客户端连接,然后该方法就返回一个格式为(client,address)的元组,client是一个客户端套接字,address是前面解释过的地址。服务器能处理客户端到它满意的程度,然后调用另一个accept方法开始等待下一个连接。这个过程通常都是在一个无限循环中实现的(这种形式的服务器端编程称为阻塞或是同步网络编程)
套接字有两个方法:send和recv(用于接收),用于传输数据。可以使用字符串参数调用send以发生数据,用一个所需的(最大)字节数做参数调用recv来接收数据。如果不能确定使用哪个数字比较好,那么1024是个很好的选择。
实例:简单的客户机/服务器(注意:Unix系统中需要要有系统管理员的权限才能使用1024以下的端口。这些低于1024的端口号被用于标准服务费。如80用于web服务)
Server:
View Code
import socket s = socket.socket() host = socket.gethostname() port = 1234 s.bind((host,port)) s.listen(5) while True: c, addr = s.accept() print('Got connection from ',addr) c.send('Thank you for connecting') c.close()
Client:
View Code
import socket s = socket.socket() host = socket.gethostname() port = 1234 s.connect((host,port)) print(s.recv(1024))
2)urllib和urllib2模块——它们能让通过网络访问文件。如果只使用简单的下载,urllib足够了。如果需要使用HTTP验证或者cookie或者要为自己的协议写扩展程序就选后者
(1)打开远程文件:可以像打开本地文件一样打开远程文件,不同之处是可以使用只读模式,使用的是来自urllib模块的urlopen,而不是open(或file):
>>> from urllib import request >>> webpage = request.urlopen('http://www.python.org')
注意:如果想要试验urllib但现在没有在线,可以用file开头的URL访问本地文件,如file:c:\text\somefile.txt(记得对\进行转义)
urlopen返回的类文件对象支持close、read、readline和readlines方法,也支持迭代。
假如要提前前面打开的Python页中的“about”链接的(相对)url,可以用正则表达式来实现:
>>> import re >>> text = webpage.read() >>> text_str = str(text) #read()返回的是字节 >>> m = re.search('About', text, re.IGNORECASE) >>> m.group(1) '/about/'
(2)获取远程文件:urlopen函数提供一个能从中读取数据的类文件对象。如果希望urllib为你下载文件并在本地文件中存储一个文件的副本,使用urlretrieve。urlretrieve返回一个元组(filename,headers)而不是类文件对象。filename是本地文件的名字(由urllib自动创建),headers包含一些远程文件的信息:
>>> import urllib.request >>> urllib.request.urlretrieve('http://www.python.org','D:\\python_webpage.html')
若没有指定文件名,文件会放在临时的位置,用open函数可以打开它,如果完成了对它的操作,就可以删除它。要清理临时文件,调用urlcleanup函数,无参数
urllib还提供了一些函数操作URL本身:
(1)quote(string [, safe]):它返回一个所有特殊字符(这些字符在URL中有特殊含义)都被对URL友好的字符代替的字符串(就像用%7E代替了~)。如果想在URL中使用一个包含特殊字符的字符串,这个函数很有用。safe字符串是不能这样写的,默认是'/'
(2)quote_plus(string [,safe]):功能和quote差不多,但用+代替空格
(3)unquote(string):和quote相反
(4)unquote_plus(string):和quote_plus相反
(5)urlencode(query [,doseq]):把映射(比如字典)或者包含两个元素的元组的序列(key,value)这种形式——转换成URL格式编码的字符串,这样的字符串可以在CGI查询中使用
3)其他模块
2:SocketServer 和它的朋友们
SocketServer模块是标准库中很多服务器框架的基础,这些服务器框架包括 BaseHTTPServer、SimpleHTTPServer、CGIHTTPServer、SimpleXMLRPCServer和DocXMLRPCServer
SocketServer包含了4个基本的类:针对TCP套接字流的TCPServer;针对UDP数据报套接字的UDPServer、以及针对性不强的UnixStreamServer和UnixDatagramServer。(可能不会用到后3个)
为了写一个使用SocketServer框架的服务器,大部分代码会在一个请求处理程序(request handler)中。每当服务器收到一个请求(来自客户端的连接)时,就会实例化一个请求处理程序,并且它的各种处理方法(handler methods)会再处理请求时被调用。具体调用哪个方法取决于特定的服务器和使用的处理程序类(handler class)。基本的BaseRequestHandler类把所有的操作都放到了处理器的一个叫做handle的方法中,这个方法会被服务器调用。然后这个方法就会访问属性self.request中的客户端套接字。如果使用的是流(如果使用的TCPServer,这就是有可能的),那么可以使用StreamRequestHandler类,创建两个其他新属性,self.rfile(用于读取)和self.wfile(用于写入)。然后就能使用这些类文件对象和客户机进行通信。
SocketServer框架中的其他类实现了对HTTP服务器的基本支持。其中包括运行CGI脚本,也包括对XML RPC的支持
下面的代码展示了之前小型服务器的SocketServer版本。注意,StreamRequestHandler在连接被处理完后悔负责关闭连接。要应注意使用''表示的是服务器正在其上运行的机器的主机名
View Code
#一个基于SocketServer的小型服务器 from socketserver import TCPServer,StreamRequestHandler class Handler(StreamRequestHandler): def handle(self): addr = self.request.getpeername() print('Got connection from ', addr) self.wfile.write('Thank you for connecting') server = TCPServer(('',1234), Handler) server.serve_forever()
3:多连接——目前讨论的解决方案都是同步的:即一次只能连接一个客户机并处理它的请求。如果每个请求只是花费很少的时间,比如,一个完整的聊天会话,那么同时能处理多个连接就很重要。
有3中主要的方法能实现这个目的:分叉(forking)、线程(threading)以及异步I/O(asynchronous I/O)。
比较:分叉占据资源,并且如果有太多的客户端时分叉不能很好的分叉(对于合理数量的客户端,分叉在现代的UNIX或Linux系统中是很高效的,如果是多CPU系统会更高效);线程处理能导致同步问题
什么是分叉和线程处理:分叉是一个UNIX术语:当分叉一个进程(一个运行的程序)时,基本上是复制了它,并且分叉后的两个进程都从当前的执行点继续运行,并且每个进程都有自己的内存副本(比如变量)。一个进程(原来的那个)成为父进程,另一个(复制的)成为子进程(可想象成平行宇宙)。分叉操作在时间线(timeline)上创建了一个分支,最后得到了两个独立存在的进程。通过fork函数的返回值可以判断哪个是原进程哪个是子进程。因此它们所执行的操作不同(如果相同,就没有意义了。两个进程会做同样的工作,会使电脑停顿)
在一个使用分叉的服务器中,每一个客户端机连接都利用分叉创造一个子进程。父进程继续监听新的连接,同时子进程处理客户端。当客户端的请求结束时,子进程就退出了。因为分叉的进程是并行运行的,客户端之间不必互相等待。
因为分叉有点耗费资源(每个分叉出来的进程都需要自己的内存),这就存在了另一个选择:线程。线程是轻量级的进程或子进程,所有的线程都存在于相同的(真正的)进程中,共享内存。资源消耗的下降伴随一个缺陷:因为线程共享内存,所有必须确保它们的变量不会冲突,或是在同一时间修改同一内容。这些问题可归结为同步问题。现代操作系统中(除了Windows,它不支持分叉)分叉实际是很快的。如果不想被同步问题困扰,分叉是一个很好的选择
能避免并行问题最好不过。后面会看到基于select函数的其他解决方法。避免线程和分叉的另外一个方法是转换到Stackless Python(http://stackless.com),一个为了能够在不同的上下文之间快速、方便切换而设计的Python版本。它支持一个叫微线程(microthreads)的类线程的并行形式,微线程比真线程的伸缩性要好。Stackless Python微线程已经被用于在星战前夜(EVE Online,http:///www.eve-online.com)来为成千上万的使用者服务
异步I/O:异步I/O在底层实现有点i难度。基本机制是select模块的select函数。还还有更高层次处理异步I/O的框架,包含在标准库中的这种类型的基本框架由:asyncore 和 asynchat 模块组成。Twisted是一个非常强大的异步网络编程框架
1)使用SocketServer进行分叉和线程处理(注意,Windows不支持分叉)
View Code
from socketserver import TCPServer,ForkingMixIn,StreamRequestHandler class Server(ForkingMixIn, TCPServer): pass class Handler(StreamRequestHandler): def handle(self): addr = self.request.getpeername() print('Got connection from', addr) self.wfile.write('Thank you for connecting') server = Server(('',1234), Handler) server.serve_forever()
View Code
from socketserver import TCPServer,ThreadingMixIn,StreamRequestHandler class Server(ThreadingMixIn, TCPServer):pass class Handler(StreamRequestHandler): def handle(self): addr = self.request.getpeername() print('Got connection from', addr) self.wfile.write('Thank you for connecting') server = Server(('',1234),Handler) server.serve_forever()
2)带有select和poll的异步I/O:当一个服务器与一个客户端通信时,来自客户端的数据可能是不连续的。如果使用分叉或线程处理,那就不是问题。当一个程序在等待数据,另一个并行的程序可以继续处理它们自己的客户端。另外的处理办法是只处理在给定时间内真正要进行通信的客户端。不需要一直监听——只要监听(或读取)一会儿,然后把它放到其他客户端的后面。
这是 asyncore/asynchat 框架和 Twisted框架采用的方法。这种功能的基础是select函数,如果poll函数可用,那也可以是它,这两个函数都来自select模块。其中poll的伸缩性更好,但它只能在UNIX系统中使用
select函数想要3个序列作为它的必选参数,此外还有一个可选的以秒为单位的超时时间作为第4个参数。这些序列是文件描述符整数(或是带有返回这样整数的fileno方法的对象)。这些就是我们等待的连接。3个序列用于输入、输出以及异常情况。如果没有给定超时时间,select会阻塞(也就是处于等待状态),直到其中一个文件描述符已经为行动做好了准备。如果给定了超时时间,select最多阻塞给定的超时时间。如果超时时间是0,那么就给出一个连续的poll(即不阻塞)。select的返回值是3个序列(也就是一个长度为3的元组),每个代表相应参数的一个活动子集
序列能包含文件对象(在windows中行不通)或套接字。下面代码展示了一个使用select的为很多连接服务的服务器(注意,服务器套接字本身被提供给select,这样select就能在准备接受一个新的连接时发出通知)。服务器是个简单的记录器(logger),它输出(在本地)来自客户机的所有数据。可以使用Telnet(或写一个简单的基于套接字的客户机来为它提供数据)连接它来进行测试。尝试用多个Telnet去连接来验证服务器能同时为多个客户端服务(服务器的日志会记录其中两个客户端的输入信息)
View Code
#使用了select的简单服务器 import socket,select s = socket.socket() host = socket.gethostname() port = 1234 s.bind((host, port)) s.listen(5) inputs = [s] while True: rs, ws, es = select.select(inputs, [], []) for r in rs: if r is s: c.addr = s.accept() print('Got connection from ', addr) inputs.append(c) else: try: data = r.recv(1024) disconnected = not data except socket.error: disconnected = True if disconnected: print(r.getpeername(), 'disconnected') inputs.remove(r) else: print(data)
poll方法使用起来比select简单,在调用poll时,会得到一个poll对象。然后就可以使用poll对象的register方法注册一个文件描述符(或是带有fileno方法的对象)。注册后可以使用unregister方法移除注册的对象。注册了一些对象(比如套接字)以后,就可以调用poll方法(带有一个可选的超时时间参数)并得到一个(fd,event)格式列表(可能是空的),其中fd是文件描述符,event则告诉你发生了什么。这是一个位掩码(bitemask),意思是它是一个整数,这个整数的每个位对应不同的事件。那些不同的事件是select模块的常量,为了验证是否设置了一个给定位(也就是说,一个给定的事件是否发生了),可使用按位与操作符(&):if event & select.POLLIN:...
下面代码是对select服务器的重写,用poll来代替select。注意添加了一个从文件描述符(ints)到套接字对象的映射(fdmap)
View Code
#使用poll的简单服务器 import socket, select s = socket.socket() host = socket.gethostname() port = 1234 s.bind((host, port)) fdmap = {s.fileno(): s} s.listen(5) p = select.poll() p.register(s) while True: events = p.poll() for fd, event in events: if fd in fdmap: c, addr = s.accept() print('Got connection from ', addr) p.register(c) fdmap[c.fileno()] = c elif event & select.POLLIN: data = fdmap[fd].recv(1024) if not data: #没有数据——关闭连接 print(fdmap[fd].getpeername(), 'disconnected') p.unregister(fd) del fdmap[fd] else: print(data)
4:Twisted框架:是一个事件驱动的Python网络框架,原来是为网络游戏开发的,现在被所有类型的网络软件使用。
1)下载并安装:http://twistedmatrix.com/
2)编写Twisted服务器:之前编写的基本套接字服务器都是显式的。其中一些有很清楚的事件循环,用来查找新的连接和新数据,而基于SocketServer的服务器有一个隐式的循环,在循环中服务器查找连接并为每个连接创建一个处理程序,但处理程序在要读数据时必须是显式的。Twisted(以及 asyncore/asynchat框架)使用一个事件甚至多个基于事件的方法。要编写基本的服务器,就要实现处理比如新客户端连接、新数据到达以及一个客户端断开连接等事件的事件处理程序。具体的类能通过基本类建立更精炼的事件,比如包装“数据到达”事件、收集数据直到新的一行,然后触发“一行数据到达”的事件。
事件处理程序在一个协议(protocol)中定义;在一个新的连接到达时,同样需要一个创建这种协议对象的工厂(factory),但如果只是想要创建一个通用的协议类的实例,那么就可以使用Twited自带的工厂。factory类在twisted.internet.protocol模块中。当编写自己的协议时,要使用和超类一样的模块中的protocol。得到一个连接后,事件处理程序connectionMade就会被调用;丢失一个连接后,connectionLost就会被调用。来自客户端的数据是通过处理程序dataReceived接收的。当然不能使用事件处理策略来把数据发回到客户端,如果要实现此功能,可以使用对象self.transport,这个对象有一个write方法,也有一个包含客户机地址(主机名和端口号)的client属性。
View Code
#使用Twisted的简单服务器 from twisted.internet import reactor from twisted.internet.protocol import Protocol,Factory class SimpleLogger(Protocol): def connectionMade(self): print('Got connection from ', self.transport.client) def connectionLost(self, reason): print(self.transport.client, 'disconnected') def dataReceived(self, data): print(data) factory = Factory() factory.protocol = SimpleLogger reactor.listenTCP(1234,factory) reactor.run()
很多情况下可能更喜欢每次得到一行数据。twisted.protocols.basic模块中包含一个有用的预定义协议是LineReceiver。它实现了dataReceived并且只要收到了一整行就调用事件处理程序lineReceived
使用了LineReceiver协议改进的记录服务器:
View Code
from twisted.internet import reactor from twisted.internet.protocol import Factory from twisted.protocols.basic import LineReceiver class SimpleLogger(LineReceiver): def connectionMade(self): print('Got connection from ', self.transport.client) def connectionLost(self, reason): print(self.transport.client, 'disconnected') def lineReceived(self, line): print(line) factory = Factory() factory.protocol = SimpleLogger reactor.listenTCP(1234,factory) reactor.run()
小结
套接字和socket模块:套接字程序(进程)之间进行通信的信息通道,可能会通过网络来通信。socket模块提供了对客户端和服务端套接字的低级访问功能。服务器端套接字会在指定的地址监听客服端的连接,而客户机是直接连接的
urllib和urllib2:urllib模块是一个简单的实现,而urllib2是可扩展的,而且很强大。两者都通过urlopen等简单的函数来工作
SocketServer框架:这是一个同步的网络服务器基类。位于标准库中。如果想同时处理多个连接,可以使用分叉和线程来处理混入类
select和poll:伸缩性和效率要比线程和分叉好得多
Twisted:异步的,伸缩性和效率方面表现很好