2020年文档相似性算法:初学者教程
作者|Masatoshi Nishimura 编译|VK 来源|Towards Data Science

如果你想知道2020年文档相似性任务的最佳算法,你来对了地方。
在33914篇《纽约时报》文章中,我测试了5种常见的文档相似性算法。从传统的统计方法到现代的深度学习方法。
每个实现少于50行代码。所有使用的模型都来自互联网。因此,你可以在没有数据科学知识的情况下,开箱即用,并且得到类似的结果。
在这篇文章中,你将学习如何实现每种算法以及如何选择最佳算法。内容如下:
最佳的定义
实验目标陈述
数据设置
比较标准
算法设置
选出赢家
对初学者的建议
你想深入自然语言处理和人工智能。你想用相关的建议来增加用户体验。你想升级旧的现有算法。那么你会喜欢这个文章的。
数据科学家主张绝对最好
你可能会搜索术语“最佳文档相似性算法”(best document similarity algorithms)。
然后你将从学术论文,博客,问答中得到搜索结果。一些侧重于特定算法的教程,而另一些则侧重于理论概述。
在学术论文中,一个标题说,这种算法的准确率达到了80%,而其他算法的准确率仅为75%。好啊。但是,这种差异是否足以让我们的眼睛注意到它呢?增加2%怎么样?实现这个算法有多容易?科学家倾向于在给定的测试集中追求最好,而忽略了实际意义。
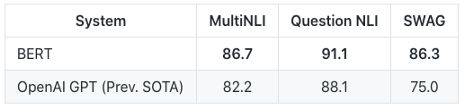
在相关的问题问答中,狂热的支持者占据了整个话题。有人说现在最好的算法是BERT。这个算法概念是如此具有革命性,它打败了一切。另一方面,愤世嫉俗者称一切都取决于工作。有些答案早在深度学习之前就有了。看看这个Stackoverflow(https://stackoverflow.com/questions/8897593/how-to-compute-the-similarity-between-two-text-documents)。2012年是投票最多的一年,很难判断它对我们到底意味着什么。
谷歌会很乐意投入数百万美元购买工程师的能力和最新的计算能力,仅仅是为了将他们的搜索能力提高1%。这对我们来说可能既不现实也没有意义。
性能增益和实现所需的技术专业知识之间有什么权衡?它需要多少内存?它以最少的预处理可以运行多快?
你想知道的是一种算法在实际意义上是如何优于另一种算法的。
这篇文章将为你提供一个指导方针,指导你在文档相似性问题应该实现哪种算法。
各种算法,通篇流行文章,预训练模型
本实验有4个目标:
通过在同一个数据集上运行多个算法,你将看到算法与另一个算法的公平性以及公平程度。
通过使用来自流行媒体的全文文章作为我们的数据集,你将发现实际应用程序的有效性。
通过访问文章url,你将能够比较结果质量的差异。
通过只使用公开可用的预训练模型,你将能够设置自己的文档相似性并得到类似的输出。
“预训练模型是你的朋友。-Cathal Horan”
数据设置-5篇基础文章
本实验选取了33914篇《纽约时报》的文章。从2018年到2020年6月。数据主要是从RSS中收集的,文章的平均长度是6500个字符。
从这些文章中选择5个作为相似性搜索的基础文章。每一个代表一个不同的类别。
在语义类别的基础上,我们还将度量书面格式。更多的描述在下面。
- Lifestyle, Human Interest:How My Worst Date Ever Became My Best(https://www.nytimes.com/2020/02/14/style/modern-love-worst-date-of-my-life-became-best.html)
- Science, Informational:A Deep-Sea Magma Monster Gets a Body Scan(https://www.nytimes.com/2019/12/03/science/axial-volcano-mapping.html)
- Business, News:Renault and Nissan Try a New Way After Years When Carlos Ghosn Ruled(https://www.nytimes.com/2019/11/29/business/renault-nissan-mitsubishi-alliance.html)
- Sports, News:Dominic Thiem Beats Rafael Nadal in Australian Open Quarterfinal(https://www.nytimes.com/2020/01/29/sports/tennis/thiem-nadal-australian-open.html)
- Politics, News:2020 Democrats Seek Voters in an Unusual Spot: Fox News(https://www.nytimes.com/2019/04/17/us/politics/fox-news-democrats-2020.html)
判断标准
我们将使用5个标准来判断相似性的性质。如果你只想查看结果,请跳过此部分。
标签的重叠
节
小节
文风
主题
标签是最接近人类判断内容相似性的工具。记者自己亲手写下标签。你可以在HTML标题中的news_keywords meta标记处检查它们。使用标签最好的部分是我们可以客观地测量两个内容有多少重叠。每个标签的大小从1到12不等。两篇文章的标签重叠越多,就越相似。
第二,我们看这个部分。这就是《纽约时报》在最高级别对文章进行分类的方式:科学、政治、体育等等。在网址的域名后面会进行显示,例如nytimes.com/…
第二部分是小节。例如,一个版块可以细分为world,或者world可以细分为Australia。并不是所有的文章都包含它,它不像以上那2个那么重要。
第四是文风。大多数文档比较分析只关注语义。但是,由于我们是在实际用例中比较推荐,所以我们也需要类似的写作风格。例如,你不想在学术期刊的“跑鞋和矫形术”之后,从商业角度阅读“十大跑鞋”。我们将根据杰斐逊县学校的写作指导原则对文章进行分组。该列表包括人类兴趣、个性、最佳(例如:产品评论)、新闻、操作方法、过去的事件和信息。
5个候选算法
这些是我们将要研究的算法。
- Jaccard
- TF-IDF
- Doc2vec
- USE
- BERT
每一个算法对33914篇文章运行,以找出得分最高的前3篇文章。对于每一篇基础文章,都会重复这个过程。
输入的是文章的全文内容。标题被忽略。
请注意,有些算法并不是为文档相似性而构建的。但是在互联网上有如此不同的意见,我们将亲眼看到结果。
我们将不关注概念理解,也不关注详细的代码审查。相反,其目的是展示问题的设置有多简单。如果你不明白以下算法的细节,不要担心,你可以阅读其他优秀博客进行理解
你可以在Github repo中找到整个代码库:https://github.com/massanishi/document_similarity_algorithms_experiments
如果你只想查看结果,请跳过此部分。
Jaccard
Jaccard 在一个多世纪前提出了这个公式。长期以来,这一概念一直是相似性任务的标准。
幸运的是,你会发现jaccard是最容易理解的算法。数学很简单,没有向量化。它可以让你从头开始编写代码。
而且,jaccard是少数不使用余弦相似性的算法之一。它标记单词并计算交集。
我们使用NLTK对文本进行预处理。
步骤:
小写所有文本
标识化
删除停用词
删除标点符号
词根化
计算两个文档中的交集/并集
import string
import nltk
nltk.download('stopwords')
nltk.download('wordnet')
nltk.download('punkt')
from nltk.corpus import stopwords
from nltk.tokenize import word_tokenize
from nltk.stem import WordNetLemmatizer
lemmatizer = WordNetLemmatizer()
base_document = "This is an example sentence for the document to be compared"
documents = ["This is the collection of documents to be compared against the base_document"]
def preprocess(text):
# 步骤:
# 1. 小写字母
# 2. 词根化
# 3. 删除停用词
# 4. 删除标点符号
# 5. 删除长度为1的字符
lowered = str.lower(text)
stop_words = set(stopwords.words('english'))
word_tokens = word_tokenize(lowered)
words = []
for w in word_tokens:
if w not in stop_words:
if w not in string.punctuation:
if len(w) > 1:
lemmatized = lemmatizer.lemmatize(w)
words.append(lemmatized)
return words
def calculate_jaccard(word_tokens1, word_tokens2):
# 结合这两个标识来找到并集。
both_tokens = word_tokens1 + word_tokens2
union = set(both_tokens)
# 计算交集
intersection = set()
for w in word_tokens1:
if w in word_tokens2:
intersection.add(w)
jaccard_score = len(intersection)/len(union)
return jaccard_score
def process_jaccard_similarity():
# 标记我们要比较的基本文档。
base_tokens = preprocess(base_document)
# 标记每一篇文档
all_tokens = []
for i, document in enumerate(documents):
tokens = preprocess(document)
all_tokens.append(tokens)
print("making word tokens at index:", i)
all_scores = []
for tokens in all_tokens:
score = calculate_jaccard(base_tokens, tokens)
all_scores.append(score)
highest_score = 0
highest_score_index = 0
for i, score in enumerate(all_scores):
if highest_score < score:
highest_score = score
highest_score_index = i
most_similar_document = documents[highest_score_index]
print("Most similar document by Jaccard with the score:", most_similar_document, highest_score)
process_jaccard_similarity()TF-IDF
这是自1972年以来出现的另一种成熟算法。经过几十年的测试,它是Elasticsearch的默认搜索实现。
Scikit learn提供了不错的TF-IDF的实现。TfidfVectorizer允许任何人尝试此操作。
利用scikit-learn的余弦相似度计算TF-IDF词向量的结果。我们将在其余的例子中使用这种余弦相似性。余弦相似性是许多机器学习任务中使用的一个非常重要的概念,可能值得你花时间熟悉一下。
多亏了scikit learn,这个算法产生了最短的代码行。
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics.pairwise import cosine_similarity
base_document = "This is an example sentence for the document to be compared"
documents = ["This is the collection of documents to be compared against the base_document"]
def process_tfidf_similarity():
vectorizer = TfidfVectorizer()
# 要生成统一的向量,首先需要将两个文档合并。
documents.insert(0, base_document)
embeddings = vectorizer.fit_transform(documents)
cosine_similarities = cosine_similarity(embeddings[0:1], embeddings[1:]).flatten()
highest_score = 0
highest_score_index = 0
for i, score in enumerate(cosine_similarities):
if highest_score < score:
highest_score = score
highest_score_index = i
most_similar_document = documents[highest_score_index]
print("Most similar document by TF-IDF with the score:", most_similar_document, highest_score)
process_tfidf_similarity()Doc2vec
Word2vec于2014年面世,这让当时的开发者们刮目相看。你可能听说过非常有名的一个例子:
国王 - 男性 = 女王
Word2vec非常擅长理解单个单词,将整个句子向量化需要很长时间。更不用说整个文件了。
相反,我们将使用Doc2vec,这是一种类似的嵌入算法,将段落而不是每个单词向量化。你可以看看这个博客的介绍:https://medium.com/wisio/a-gentle-introduction-to-doc2vec-db3e8c0cce5e
不幸的是,对于Doc2vec来说,没有官方预训练模型。我们将使用其他人的预训练模型。它是在英文维基百科上训练的(数字不详,但模型大小相当于1.5gb):https://github.com/jhlau/doc2vec
Doc2vec的官方文档指出,输入可以是任意长度。一旦标识化,我们输入整个文档到gensim库。
from gensim.models.doc2vec import Doc2Vec
from sklearn.metrics.pairwise import cosine_similarity
import string
import nltk
nltk.download('stopwords')
nltk.download('wordnet')
nltk.download('punkt')
from nltk.corpus import stopwords
from nltk.tokenize import word_tokenize
from nltk.stem import WordNetLemmatizer
lemmatizer = WordNetLemmatizer()
base_document = "This is an example sentence for the document to be compared"
documents = ["This is the collection of documents to be compared against the base_document"]
def preprocess(text):
# 步骤:
# 1. 小写字母
# 2. 词根化
# 3. 删除停用词
# 4. 删除标点符号
# 5. 删除长度为1的字符
lowered = str.lower(text)
stop_words = set(stopwords.words('english'))
word_tokens = word_tokenize(lowered)
words = []
for w in word_tokens:
if w not in stop_words:
if w not in string.punctuation:
if len(w) > 1:
lemmatized = lemmatizer.lemmatize(w)
words.append(lemmatized)
return words
def process_doc2vec_similarity():
# 这两种预先训练的模型都可以在jhlau的公开仓库中获得。
# URL: https://github.com/jhlau/doc2vec
# filename = './models/apnews_dbow/doc2vec.bin'
filename = './models/enwiki_dbow/doc2vec.bin'
model= Doc2Vec.load(filename)
tokens = preprocess(base_document)
# 只处理出现在doc2vec预训练过的向量中的单词。enwiki_ebow模型包含669549个词汇。
tokens = list(filter(lambda x: x in model.wv.vocab.keys(), tokens))
base_vector = model.infer_vector(tokens)
vectors = []
for i, document in enumerate(documents):
tokens = preprocess(document)
tokens = list(filter(lambda x: x in model.wv.vocab.keys(), tokens))
vector = model.infer_vector(tokens)
vectors.append(vector)
print("making vector at index:", i)
scores = cosine_similarity([base_vector], vectors).flatten()
highest_score = 0
highest_score_index = 0
for i, score in enumerate(scores):
if highest_score < score:
highest_score = score
highest_score_index = i
most_similar_document = documents[highest_score_index]
print("Most similar document by Doc2vec with the score:", most_similar_document, highest_score)
process_doc2vec_similarity()Universal Sentence Encoder (USE)
这是Google最近在2018年5月发布的一个流行算法。 实现细节:https://www.tensorflow.org/hub/tutorials/semantic_similarity_with_tf_hub_universal_encoder。
我们将使用谷歌最新的官方预训练模型:Universal Sentence Encoder 4(https://tfhub.dev/google/universal-sentence-encoder/4).
顾名思义,它是用句子来构建的。但官方文件并没有限制投入规模。没有什么能阻止我们将它用于文档比较任务。
整个文档按原样插入到Tensorflow中。没有进行标识化。
from sklearn.metrics.pairwise import cosine_similarity
import tensorflow as tf
import tensorflow_hub as hub
base_document = "This is an example sentence for the document to be compared"
documents = ["This is the collection of documents to be compared against the base_document"]
def process_use_similarity():
filename = "./models/universal-sentence-encoder_4"
model = hub.load(filename)
base_embeddings = model([base_document])
embeddings = model(documents)
scores = cosine_similarity(base_embeddings, embeddings).flatten()
highest_score = 0
highest_score_index = 0
for i, score in enumerate(scores):
if highest_score < score:
highest_score = score
highest_score_index = i
most_similar_document = documents[highest_score_index]
print("Most similar document by USE with the score:", most_similar_document, highest_score)
process_use_similarity()BERT
这可是个重量级选手。2018年11月谷歌开源BERT算法。第二年,谷歌搜索副总裁发表了一篇博文,称BERT是他们过去5年来最大的飞跃。
它是专门为理解你的搜索查询而构建的。当谈到理解一个句子的上下文时,BERT似乎比这里提到的所有其他技术都要出色。
最初的BERT任务并不打算处理大量的文本输入。对于嵌入多个句子,我们将使用UKPLab(来自德国大学)出版的句子转换器开源项目(https://github.com/UKPLab/sentence-transformers),其计算速度更快。它们还为我们提供了一个与原始模型相当的预训练模型(https://github.com/UKPLab/sentence-transformers#performance)
所以每个文档都被标记成句子。并对结果进行平均,以将文档表示为一个向量。
import numpy as np
from sklearn.metrics.pairwise import cosine_similarity
from nltk import sent_tokenize
from sentence_transformers import SentenceTransformer
base_document = "This is an example sentence for the document to be compared"
documents = ["This is the collection of documents to be compared against the base_document"]
def process_bert_similarity():
# 这将下载和加载UKPLab提供的预训练模型。
model = SentenceTransformer('bert-base-nli-mean-tokens')
# 虽然在句子转换器的官方文件中并没有明确的说明,但是原来的BERT是指一个更短的句子。我们将通过句子而不是整个文档来提供模型。
sentences = sent_tokenize(base_document)
base_embeddings_sentences = model.encode(sentences)
base_embeddings = np.mean(np.array(base_embeddings_sentences), axis=0)
vectors = []
for i, document in enumerate(documents):
sentences = sent_tokenize(document)
embeddings_sentences = model.encode(sentences)
embeddings = np.mean(np.array(embeddings_sentences), axis=0)
vectors.append(embeddings)
print("making vector at index:", i)
scores = cosine_similarity([base_embeddings], vectors).flatten()
highest_score = 0
highest_score_index = 0
for i, score in enumerate(scores):
if highest_score < score:
highest_score = score
highest_score_index = i
most_similar_document = documents[highest_score_index]
print("Most similar document by BERT with the score:", most_similar_document, highest_score)
process_bert_similarity()算法评估
让我们看看每种算法在我们的5篇不同类型的文章中的表现。我们根据得分最高的三篇文章进行比较。
在这篇博文中,我们将只介绍五种算法中性能最好的算法的结果。有关完整的结果以及个别文章链接,请参阅仓库中的算法目录:https://github.com/massanishi/document_similarity_algorithms_experiments
1. How My Worst Date Ever Became My Best
BERT胜利
这篇文章是一个人类感兴趣的故事,涉及一个50年代离婚妇女的浪漫约会。
这种写作风格没有像名人名字这样的特定名词。它对时间也不敏感。2010年的一个关于人类兴趣的故事在今天可能也同样重要。在比较中没有一个算法性能特别差。
BERT和USE的比赛千钧一发。USE把故事绕到了社会问题,BERT关注浪漫和约会。其他算法则转向了家庭和孩子的话题,可能是因为看到了“ex husband 前夫”这个词。
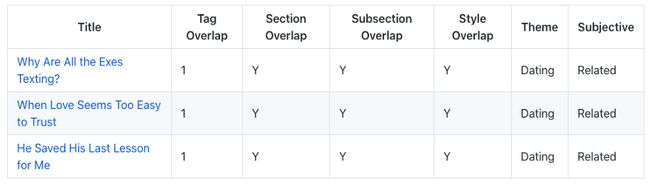
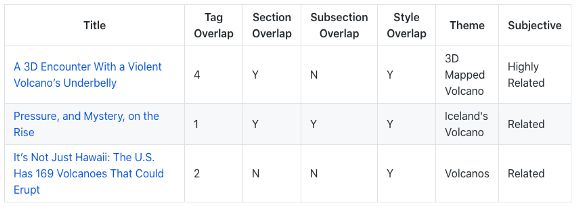
2. A Deep-Sea Magma Monster Gets a Body Scan
TF-IDF获胜。
这篇科学文章是关于海洋中活火山的三维扫描。
3D扫描、火山和海洋是罕见的术语。所有算法都很好地实现了公平。
TF-IDF正确地选择了那些只谈论地球海洋内火山的人。USE与它相比也是一个强大的竞争者,它的重点是火星上的火山而不是海洋。另一些算法则选择了有关俄罗斯军用潜艇的文章,这些文章与科学无关,与主题无关。
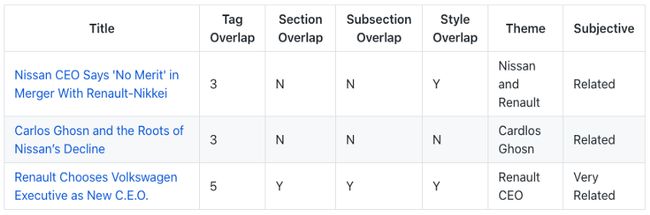
3. Renault and Nissan Try a New Way After Years When Carlos Ghosn Ruled
TF-IDF获胜。
文章谈到了前首席执行官卡洛斯·戈恩越狱后雷诺和日产的遭遇。
理想的匹配将讨论这3个实体。与前两篇相比,本文更具有事件驱动性和时间敏感性。相关新闻应与此日期或之后发生(从2019年11月开始)。
TF-IDF正确地选择了关注日产CEO的文章。其他人则选择了一些谈论通用汽车行业新闻的文章,比如菲亚特克莱斯勒(Fiat Chrysler)和标致(Peugeot)的结盟。
值得一提的是,Doc2vec和USE生成了完全相同的结果。
4. Dominic Thiem Beats Rafael Nadal in Australian Open Quarterfinal
Jaccard、TF-IDF和USE结果相似。
这篇文章是关于网球选手多米尼克·蒂姆在2020年澳大利亚网球公开赛(网球比赛)上的文章。
新闻是事件驱动的,对个人来说非常具体。所以理想的匹配是多米尼克和澳大利亚公开赛。
不幸的是,这个结果由于缺乏足够的数据而受到影响。他们都谈论网球。但有些比赛是在谈论2018年法国网球公开赛的多米尼克。或者,在澳大利亚网球公开赛上对费德勒的看法。
结果是三种算法的结果。这说明了关键的重要性:我们需要尽最大努力收集、多样化和扩展数据池,以获得最佳的相似性匹配结果。
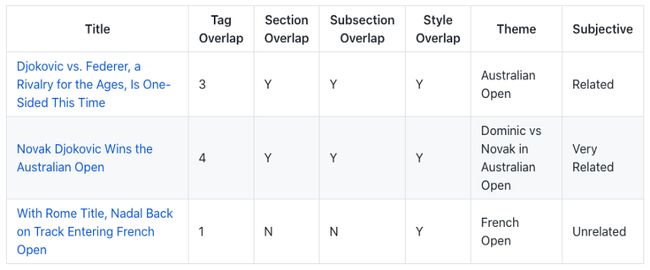
5. 2020 Democrats Seek Voters in an Unusual Spot: Fox News
USE胜利。
这篇文章是关于民主党人的,特别关注伯尼·桑德斯在福克斯新闻(Fox News)上为2020年大选出镜。
每一个话题都有自己的大问题。关于民主党候选人和选举的文章很多。因为这个故事的主旨是新颖的,所以我们优先讨论民主党候选人和福克斯的关系。
旁注:在实践中,你要小心对待政治上的建议。把自由和保守的新闻混合在一起很容易让读者不安。既然我们是单独和《纽约时报》打交道,那就不必担心了。
USE找到了一些关于伯尼·桑德斯和福克斯、微软全国广播公司等电视频道的文章。其他人则选择了一些讨论2020年大选中其他民主党候选人的文章。
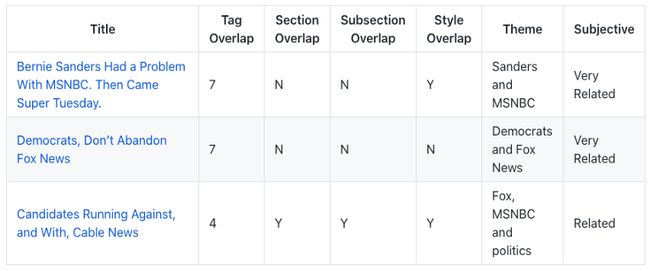
速度之王
在结束赢家之前,我们需要谈谈运行时间。每种算法在速度方面表现得非常不同。
结果是,TF-IDF的实施比任何其他方法都快得多。要在单个CPU上从头到尾计算33914个文档(标识化、向量化和比较),需要:
TF-IDF:1.5分钟。
Jaccard:13分钟。
Doc2vec:43分钟。
USE:62分钟。
BERT:50多小时(每个句子都被向量化了)。
TF-IDF只花了一分半钟。这是USE的2.5%。当然,你可以合并多种效率增强。但潜在收益需要讨论。这将使我们有另一个理由认真审视相关的利弊权衡。
以下是5篇文章中的每一篇的赢家算法。
- BERT
- TF-IDF
- TF-IDF
- Jaccard, TF-IDF和USE
- USE
从结果可以看出,对于新闻报道中的文档相似性,TF-IDF是最佳候选。如果你使用它的最小定制,这一点尤其正确。考虑到TF-IDF是发明的第二古老的算法,这也令人惊讶。相反,你可能会失望的是,现代先进的人工智能深度学习在这项任务中没有任何意义。
当然,每种深度学习技术都可以通过训练自己的模型和更好地预处理数据来改进。但所有这些都伴随着开发成本。你想好好想想,相对于TF-IDF方法,这种努力会带来额外多大的好处。
最后,可以说我们应该完全忘记Jaccard和Doc2vec的文档相似性。与今天的替代品相比,它们没有带来任何好处。
新手推荐
假设你决定从头开始在应用程序中实现相似性算法,下面是我的建议。
1.先实施TF-IDF
最快的文档相似性匹配是TF-IDF,尽管有深度学习的各种宣传,例如深度学习给你一个高质量的结果。但是TFIDF最棒的是,它是闪电般的快。
正如我们所看到的,将其升级到深度学习方法可能会或不会给你带来更好的性能。在计算权衡时,必须事先考虑很多问题。
2.积累更好的数据
Andrew Ng给出了一个类似的建议。你不能指望你的车没有油就跑。油必须是好的。
文档相似性依赖于数据的多样性,也依赖于特定的算法。你应该尽你最大的努力找到唯一的数据来增强你的相似性结果。
3.升级到深度学习
仅当你对TF-IDF的结果不满意时,才迁移到USE或BERT以升级模型。你需要考虑计算时间。你可能会预处理词嵌入,因此你可以在运行时更快地处理相似性匹配。谷歌为此写了一篇教程:https://cloud.google.com/solutions/machine-learning/building-real-time-embeddings-similarity-matching-system
4.调整深度学习算法
你可以慢慢升级你的模型。训练你自己的模型,将预训练好的知识融入特定的领域,等等。今天也有许多不同的深度学习模式。你可以一个一个的来看看哪一个最适合你的具体要求。
文档相似性是许多NLP任务之一
你可以使用各种算法实现文档的相似性:一些是传统的统计方法,另一些是尖端的深度学习方法。我们已经在纽约时报的文章中看到了它们之间的比较。
使用TF-IDF,你可以在本地笔记本电脑上轻松启动自己的文档相似性。不需要昂贵的GPU。不需要大内存。你仍然可以得到高质量的数据。
诚然,如果你想做情绪分析或分类等其他任务,深入学习应该适合你的工作。但是,当研究人员试图突破深度学习效率和成绩界限时,我们要意识到生活在炒作的圈子里是不健康的。它给新来的人带来巨大的焦虑和不安全感。
坚持经验主义可以让我们看到现实。
希望这个博客鼓励你开始自己的NLP项目。
参考阅读
- An article covering TF-IDF and Cosine similarity with examples: “Overview of Text Similarity Metrics in Python“:https://towardsdatascience.com/overview-of-text-similarity-metrics-3397c4601f50
- An academic paper discussing how cosine similarity is used in various NLP machine learning tasks: “Cosine Similarity”:https://www.sciencedirect.com/topics/computer-science/cosine-similarity
- Discussion of sentence similarity in different algorithms: “Text Similarities : Estimate the degree of similarity between two texts”:https://medium.com/@adriensieg/text-similarities-da019229c894
- An examination of various deep learning models in text analysis: “When Not to Choose the Best NLP Model”:https://blog.floydhub.com/when-the-best-nlp-model-is-not-the-best-choice/
- Conceptual dive into BERT model: “A review of BERT based models”:https://towardsdatascience.com/a-review-of-bert-based-models-4ffdc0f15d58
- A literature review on document embeddings: “Document Embedding Techniques”:https://towardsdatascience.com/document-embedding-techniques-fed3e7a6a25d
原文链接:https://towardsdatascience.com/the-best-document-similarity-algorithm-in-2020-a-beginners-guide-a01b9ef8cf05
欢迎关注磐创AI博客站: http://panchuang.net/
sklearn机器学习中文官方文档: http://sklearn123.com/
欢迎关注磐创博客资源汇总站: http://docs.panchuang.net/