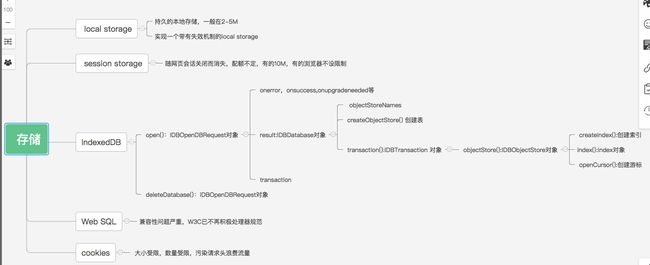
HTML5存储
localStorage和sessionStorage

使用方法如下
在chrome浏览器中
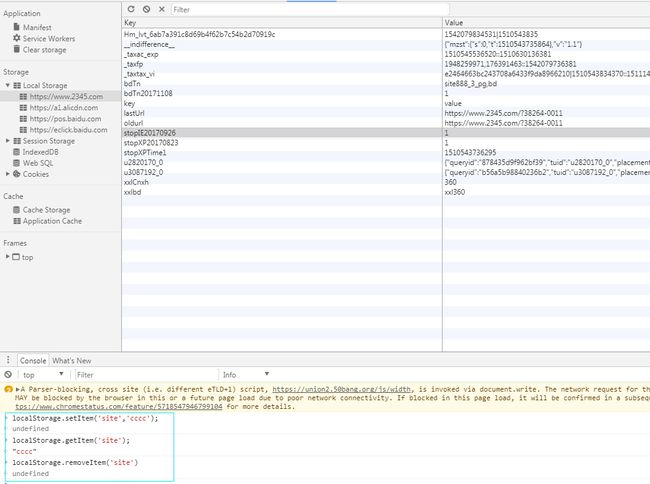

使用方法如下:
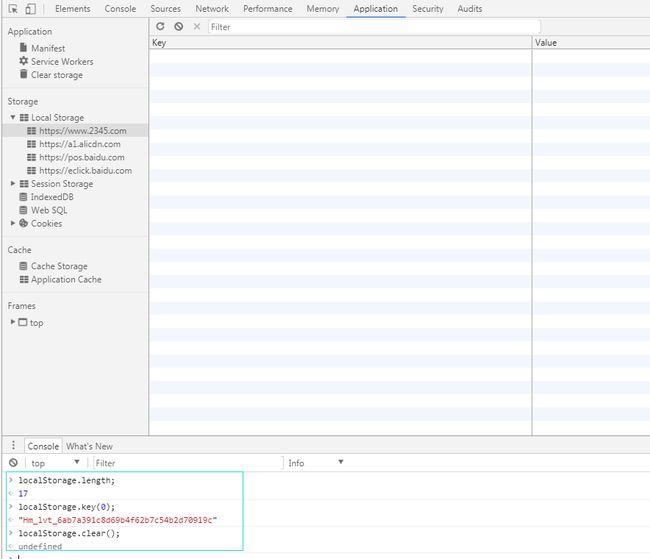
总结
### localStorage和sessionStorage cookie的作用是与服务器进行交互,作为HTTP规范的一部分而存在,将其用于存储存在以下缺点 - cookie大小受限(仅有4kb左右) - 单个域名下数量限制(50个左右) - 污染请求头浪费流量(每次发送新的请求时都会被发送到服务器) 而Web Storage仅仅是为了在本地“存储”数据而生,相对cookie更加适合用于本地存储 #### 相同的使用方法和属性 - setItem(key,value)方法设置存储内容 - getItem(key)方法获取存储内容 - removeItem(key)方法删除存储内容 - clear()方法清除所有内容 - key()方法获取存储的key,传入索引值,不存在时返回null - length属性获取存储内容个数 #### 不同的存储时效 - localStorage 持久的本地存储,除非主动删除数据,否则永远不过期 - sessionStorage 会在网页会话结束后失效(标签页关闭) #### 不同的存储容量 - localStorage 一般在2-5Mb - sessionStorage 存储容量不定,部分浏览器不设限制
使用storage注意点:
1.存储容量超出限制
sessionStorage和localStorage的存储空间虽然较大,但是存储容量仍有限制,叫做配额。
存储值时应该使用try catch来捕获异常
try{
localStorage.setItem(key,data);
//重复调用这个函数
//save();
}catch(e){
console.log(e.name);
}
```
- 抛出QoutaExceededError异常
2.存储类型的限制
仅能存储字符串
注意类型转换,将存储内容转化为string
```
localStorage.setItem("gaogao",{age:20})
//存储为gaogao [object object]
所以要将对象转换为字符串之后再存储
localStorage.setItem("gaogao",JSON.stringify({age:20}))
//存储为 gaogao {"age":20}
然后再将JSON字符串转换为对象进行使用
```
3.sessionStorage失效机制
刷新页面不会失效
相同url不同标签页不能共享sessionStorage
先设置 然后location.reload()方法刷新

在刷新的页面中获取sessionStorage
![]()

代码如下
html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Titletitle>
head>
<body>
<script>
(function () {
var ls = window.localStorage;
function oops() {
return console.warn('your browser is not supported localStorage API')
}
function getItem(key) {
var data = ls.getItem(key);
data = JSON.parse(data) || {}; //空对象
if (data.time === 0){
return data.value;//为0当做一个持续的数据
}else if(Date.now() > data.time) {//超出了设置的过期时间
ls.removeItem(key);
return '';
}else {
return typeof data.value !== 'undefined' ? data.value : ''; //空对象返回空字符串
}
}
function setItem(key,value,time) {//time设置过期的时间
if(typeof key === 'undefined'){return}//如果没输入的key 暂停调用这个函数 typeof返回字符串所以后面的undefined加引号
var data = {
time : time ? Date.now() + time : 0 , //如果有time设置 返回毫秒数 没有就当做长期保存
value : value
};
//接受字符串
data = JSON.stringify(data);
//捕获 如果超出定额 则清空再设置
try {
ls.setItem(key,data);
}catch (e){
ls.clear();
ls.setItem(key,data);
}
}
function removeItem(key) {
ls.removeItem(key);
}
function clear() {
ls.clear();
}
window.cacheStorage = {
getItem : ls ? getItem : oops,
setItem : ls ? setItem : oops,
removeItem : ls ? removeItem : oops,
Clear : ls ? clear : clear
}
})()
script>
body>
html>
实际效果



执行如下 创建一个数据库
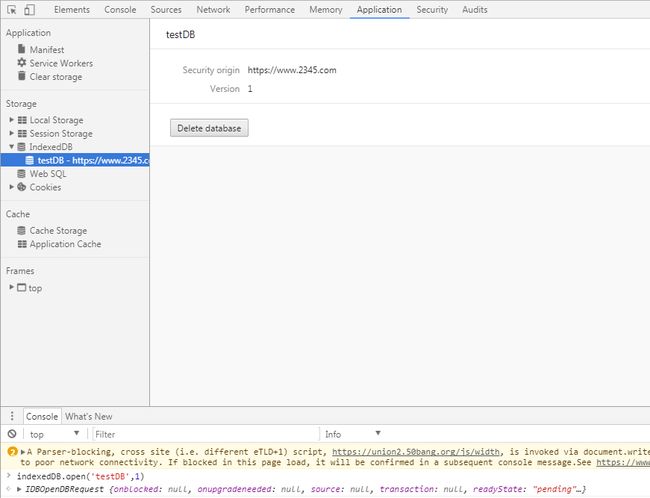
删除
![]()
注意都要刷新才有效果
### 如何创建数据库和表
Web Storage使用简单字符串键值对在本地存储数据,方便灵活,但是对于大量结构化数据存储力不从心,IndexedDB是为了能够在客户端存储大量的结构化数据,并且使用索引高效检索的API。
#### indexedDB数据库特点
- indexedDB数据库是一种事物型数据库
- 是NoSQL数据库,不能使用SQL语句进行数据的增删查改
- 使用js对象存储数据,保证了数据的结构完整性
#### 创建数据库
- indexedDB.open(name[,version])创建或者打开一个数据库,返回一个IDBOpenDBRequest对象
- indexedDB.deleteDatabase(name)删除数据库,返回一个IDBOpenDBRequest对象,但其中已经没有了result
#### IDBOpenDBRequest对象
当创建数据库或者打开数据库之后,我们会得到一个IDBOpenDBRequest对象,而我们希望得到的DB对象在其result属性中,即IDBDatabase对象。而在IDBOpenDBRequest中还定义了几个接口,即
- onerror: 请求失败的回调函数句柄
- onsuccess:请求成功的回调函数句柄
- onupgradeneeded:请求数据库版本变化句柄
- result属性:保存IDBDatabase对象
我们通过使用这些句柄来定义不同状态下的事件处理语句
```
// 简化indexedDB
var db = window.indexedDB || window.mozIndexedDB || window.webkitIndexedDB || window.msIndexedDB;
var version = 1;
var request = db.open("test",version);
//后执行
request.onsuccess = function (e) {
console.log("版本打开成功")
}
request.onerror = function (e) {
console.log("版本发生错误")
}
//先执行
request.onupgradeneeded = function (e) {
console.log("版本发生变化")
}
```
当按照如下方式进行测试,打印结果如下
```
刷新页面:版本发生变化,版本打开成功
再次刷新:版本打开成功
设置version = 2刷新:版本发生变化,版本打开成功
再次刷新:版本打开成功
设置version = 1刷新:版本发生错误
```
由此可见,当我们传入的版本号和数据库当前版本号不一致的时候onupgradeneeded就会被调用,而且当试图打开比当前数据库版本低的version,调用的就是onerror了。所以我们需要利用这些事件句柄的回调函数来获取result。
```
//打开成功时,将result中的IDBDatabase对象赋给db
request.onsuccess = function (e) {
db = e.target.result;
}
//出错时打印出错信息
request.onerror = function (e) {
console.log(e.currentTarget.errormessage)
}
//版本发生变化时
```
#### 创建表(ObjectStore)
objectStore是一个灵活的数据结构,可以存放多种类型数据,里面存储的每条数据和一个键相关联。
- 使用indexedDB.createObjectStore(name,keypath)创建ObjectStore
#### 设置主键的两种方法
- 设置自增主键{autoIncrement:true}
- 取数据中字段做为主键{keyPath:字段名}

关于这个“表”是做什么用的?
IndexedDB 是一种浏览器端文档数据库,可以被网页脚本程序创建和操作。它允许储存大量数据,并且提供查询接口,且可以建立索引。就数据库类型而言,IndexedDB不属于关系型数据库(不支持SQL查询语句),更接近NoSQL数据库。关系型数据库(如SQL Server,MySQL,Oracle等)的数据存储在表中;文档数据库(如MongoDB,CouchDB,Redis)将数据集作为个体对象来存储。 通过使用IndexedDB,开发者可以通过惯于在服务器端数据库几乎相同的方式进行创建、读取、更新和删除大量数据记录的操作。
最直接的说法,就是未来在浏览器上存储数据或者是对数据进行操作。
var db = window.indexedDB || window.mozIndexedDB || window.msIndexedDB || window.webkitIndexedDB ; var request , result , version = 5, dbName = 'testDB', osName = 'os1'; function creatDB() { request = db.open(dbName, version); request.onsuccess = function () { db = request.result; console.log('open success');//后打印 } request.onerror = function (e) { console.log(e.currentTarget.errormessage); } request.onupgradeneeded = function () { db = request.result; console.log('upgradeneeded'); //先打印 if(!db.objectStoreNames.contains(osName)){ db.createObjectStore(osName , {autoIcrement : true}); } } }
表的增删查改

过渡?




关于索引的使用



关于游标的使用




离线存储


配置manifest
CACHE MANIFEST #VERSON 1.0 CACHE: script.js //离线也可以打开这里的文件了 style.css NETWORK: * FALLBACK:
### 离线存储Application cache #### Application cache的功能 - 可永久存储资源,当资源发生改变要通过配置文件修改资源 - 被存储资源可供离线使用 - 可通过配制文件修改存储策略 #### manifest 文件配置 ``` CACHE MANIFEST #VERSION 1.0 CACHE: test.js test.jpg FALLBACK: NETWORK: *//星号表示所有的资源都可以 ``` - 文件起始标记CACHE MANIFEST - 缓存标记CACHE - 网络请求标记 NETWORK - 资源失效回退标记FALLBACK - 使用#进行注释 #### appcache 示例 - 运行一个web服务 - manifest文件的MINE Type为text/cache-manifest #### 糟糕之处 - 文件总是来自缓存,即使在线环境(更新时必须要修改manifest) - 更新只在manifest文件自身更新之后 - 别忘记给所有缓存文件加上HTTP缓存控制 - 未被缓存的资源必须在network中指明 - 无法分辨响应式资源,造成流量浪费 - 无法重定向至其他域名 ### service worker #### 功能 - 离线缓存 - 消息推送 - 后台消息传递 - 网络代理,转发请求,伪造响应 #### 如何实现离线存储 - 安装service worker - 监听install事件,并存储文件 - 监听fetch事件,返回被存储的文件
application cache 缺点 1,文件总是来自缓存,即使在线环境 2,更新只是在manifest文件自身更新之后 3,不要忘记给所有缓存文件加上HTTP缓存控制 4、未被缓存的资源必须在NETWORK指明,否则图片不会加载未被缓存的资源(通常用 * 号指明全部资源) 5、无法分辨响应式资源(如果全部缓存它会全部加载响应式资源)
#### service worker离线存储功能的优势 - 可以更细致的控制存储资源 - 拥有强大的更新机制 #### service worker 现状 - 规范处于草案状态 - 使用需要成本:https协议 - 兼容性不佳
总结