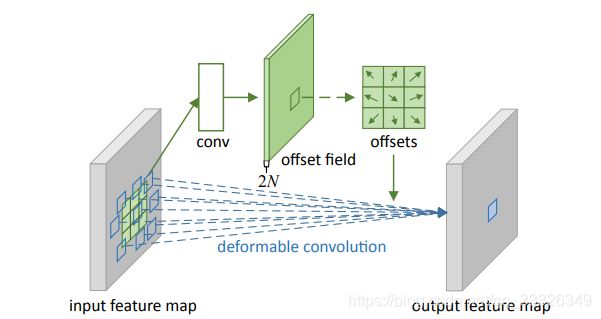
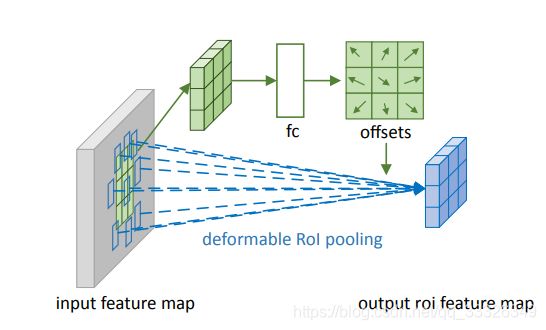
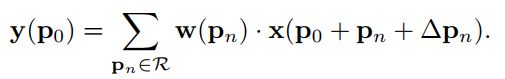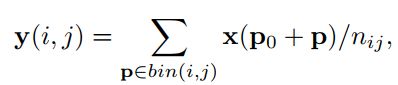- JSON 与 AJAX
Auscy
jsonajax前端
一、JSON(JavaScriptObjectNotation)1.数据类型与语法细节支持的数据类型:基本类型:字符串(需用双引号)、数字、布尔值(true/false)、null。复杂类型:数组([])、对象({})。严格语法规范:键名必须用双引号包裹(如"name":"张三")。数组元素用逗号分隔,最后一个元素后不能有多余逗号。数字不能以0开头(如012会被解析为12),不支持八进制/十六进制
- Python之七彩花朵代码实现
PlutoZuo
Pythonpython开发语言
Python之七彩花朵代码实现文章目录Python之七彩花朵代码实现下面是一个简单的使用Python的七彩花朵。这个示例只是一个简单的版本,没有很多高级功能,但它可以作为一个起点,你可以在此基础上添加更多功能。importturtleastuimportrandomasraimportmathtu.setup(1.0,1.0)t=tu.Pen()t.ht()colors=['red','skybl
- 【前端】jQuery数组合并去重方法总结
在jQuery中合并多个数组并去重,推荐使用原生JavaScript的Set对象(高效简单)或$.unique()(仅适用于DOM元素,不适用于普通数组)。以下是完整解决方案:方法1:使用ES6Set(推荐)//定义多个数组constarr1=[1,2,3];constarr2=[2,3,4];constarr3=[3,4,5];//合并数组并用Set去重constmergedArray=[...
- 如何解决 NPM proxy, 当我们在终端nodejs应用程序时出现代理相关报错
Thisisaproblemrelatedtonetworkconnectivity.npmERR!networkInmostcasesyouarebehindaproxyorhavebadnetworksettings.在使用npminstall下载包的时候总是报以下错误:在控制台或VisualStudioCode终端中运行以下命令:npmconfigrmproxynpmconfigrmhttp
- npm proxy setting
kjndppl
[Node.jsJavaScriptnpmhttpsproxypassword
清理npmconfigdeletehttp-proxynpmconfigdeletehttps-proxy具体设置步骤如下:1.执行npmconfig后,将看到下一行提示信息npmconfigls-ltoshowalldefaults.2.执行npmconfigls-l后,在一大长串的settign中找出userconfig项(大概位于倒数第4项)[b]userconfig[/b]="C:\\Us
- 传统检测响应慢?陌讯多模态引擎提速90+FPS实战
2501_92473147
算法计算机视觉目标检测
开篇痛点:实时目标检测在安防监控中的核心挑战在安防监控领域,实时目标检测是保障公共安全的关键技术。然而,传统算法如YOLOv5或开源框架MMDetection常面临两大痛点:误报率高(复杂光照或遮挡场景下检测不稳定)和响应延迟(高分辨率视频流处理FPS低于30)。实测数据显示,城市交通监控系统误报率达15%,导致安保资源浪费;客户反馈表明,延迟超100ms时,目标跟踪可能失效。这些问题源于算法泛化
- 实时预览功能问题
GISer_Jinger
项目javascript开发语言ecmascript
你遇到的问题是:“B端修改配置后无法实时出现在previewiframe中,而必须点击刷新才能生效”。主要原因与以下几方面有关:❗为什么需要手动刷新:iFrame与主页面之间缺少实时通信机制:原本仅靠刷新重新加载iframe,而没有通过postMessage等方式同步状态;Valtio的proxy状态不能跨文件热刷新持久保存:当你修改包含proxy定义的文件,热重载会导致object被替换,监听丢
- [Vue warn]: onUnmounted is called when there is no active component instance to be associated with
扬帆起航&d
vue.jsjavascript前端ecmascript前端框架
[Vuewarn]:onUnmountediscalledwhenthereisnoactivecomponentinstancetobeassociatedwith.LifecycleinjectionAPIscanonlybeusedduringexecutionofsetup().Ifyouareusingasyncsetup(),makesuretoregisterlifecyclehoo
- 深度学习模型表征提取全解析
ZhangJiQun&MXP
教学2024大模型以及算力2021AIpython深度学习人工智能pythonembedding语言模型
模型内部进行表征提取的方法在自然语言处理(NLP)中,“表征(Representation)”指将文本(词、短语、句子、文档等)转化为计算机可理解的数值形式(如向量、矩阵),核心目标是捕捉语言的语义、语法、上下文依赖等信息。自然语言表征技术可按“静态/动态”“有无上下文”“是否融入知识”等维度划分一、传统静态表征(无上下文,词级为主)这类方法为每个词分配固定向量,不考虑其在具体语境中的含义(无法解
- h5-video标签全屏显示记录
ZhDan91
前端开发混合app
video{width:100%;height:100%;object-fit:fill;}
- flutter redux状态管理
liao277218962
Flutterflutterstateredux
Flutter状态管理系列文章目录Flutter状态管理(setState、InheritedWidget、Provider、Riverpod、BLoC/Cubit、GetX、MobX、Redux)setState()使用详解:原理及注意事项InheritedWidget组件使用及原理Flutter中Provider的使用、注意事项与原理解析(含代码实战)GetX用法详细解析以及注意事项Flutt
- QML与C++相互调用函数并获得返回值
cpp_learners
QMLc++QMLqt
这篇博客主要讲解在qml端如何直接调用c++的函数并获得返回值,在c++端如何直接调用qml的函数并获得返回值;主要以map或者jsonobject、list或者jsonarray为主!其他单个类型,常见的类型,例如QString、int等,就不演示了;一通百通。目录1准备工作1.1C++端1.2QML端2qml端直接调用c++端函数3c++端直接调用qml端函数3.1调用qml的qmlFuncO
- Android 15.0 根据app包名授予app监听系统通知权限
安卓兼职framework应用工程师
android15.0Rom定制化系列讲解androidromframework监听系统通知权限
1.概述在15.0的系统rom产品定制化开发中,在一些产品rom定制化开发中,系统内置的第三方app需要开启系统通知权限,然后可以在app中,监听系统所有通知,来做个通知中心的功能,所以需要授权获取系统通知的权限,然后来顺利的监听系统通知。来做系统通知的功能,接下来来实现这个功能2.根据app包名授予app监听系统通知权限的核心类packages/apps/Settings/src/com/and
- iOS 多个线程对数组操作(遍历,插入,删除),实现一个线程安全的NSMutabeArray
//联系人:石虎QQ:1224614774昵称:嗡嘛呢叭咪哄一、概念1.含义:@synchronized(self){}//这个其实就是一个加锁。如果self其他线程访问,则会阻塞。这样做一般是用来对单2.重写构造方法@interfaceSHSafetyArray:NSObject{@privateNSMutableArray*_mutableArray;//声明数组}//遍历加锁-(void)m
- C++STL-set
s15335
C++STLc++开发语言
一.基础概念set也是一种容器,像vector,string这样,但它是树形容器。在物理结构上是二叉搜索树,逻辑上还是线性结构。set容器内元素不可重复,multiset内容器元素可以重复;这两个容器,插入的元素都是有序排列。二.基础用法1.set对象创建1.默认构造函数sets1;2.初始化列表sets2_1={9,8,7,6,5};//56789sets2_2({9,8,7,7,6,5});/
- 低温冷启动 & 高温热启动
hahaha6016
fpga开发
低温冷启动1.在低温下,晶体管的阈值电压可能升高,导致时序路径变慢,从而可能引起建立时间(setuptime)违规。另外,也可能出现保持时间(holdtime)违规,因为低温下信号传播速度可能变快(但通常低温下延迟增加,所以建立时间问题更常见)。2.droppinglogiccore意味着在低温下某个逻辑核心(可能是一个特定的模块或IP核)无法正常启动或工作,导致功能失效3.cellname,这通
- 【Qualcomm】高通SNPE框架简介、下载与使用
Jackilina_Stone
人工智能QualcommSNPE
目录一高通SNPE框架1SNPE简介2QNN与SNPE3Capabilities4工作流程二SNPE的安装与使用1下载2Setup3SNPE的使用概述一高通SNPE框架1SNPE简介SNPE(SnapdragonNeuralProcessingEngine),是高通公司推出的面向移动端和物联网设备的深度学习推理框架。SNPE提供了一套完整的深度学习推理框架,能够支持多种深度学习模型,包括Pytor
- 目标检测(object detection)
加油吧zkf
目标检测目标检测人工智能计算机视觉
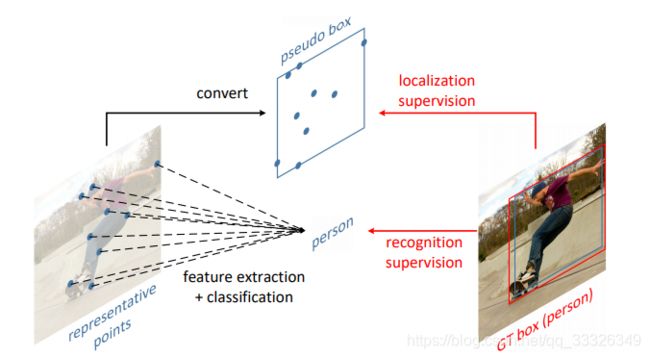
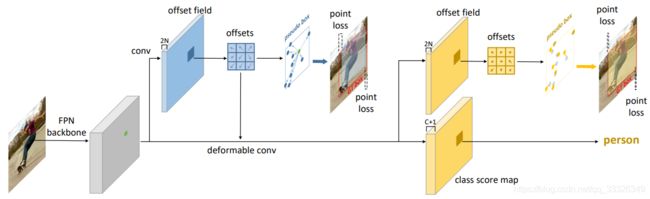
目标检测作为计算机视觉的核心技术,在自动驾驶、安防监控、医疗影像等领域发挥着不可替代的作用。本文将系统讲解目标检测的概念、原理、主流模型、常见数据集及应用场景,帮助读者构建对这一技术的完整认知。一、目标检测的核心概念目标检测(ObjectDetection)是指在图像或视频中自动定位并识别出所有感兴趣的目标的技术。它需要解决两个核心问题:分类(Classification):确定图像中每个目标的类
- 技术演进中的开发沉思-32 MFC系列:生命周期
chilavert318
熬之滴水穿石windowsc++
今天,我们继续MFC以一种更亲近的方式,梳理这个框架的脉络,看看一个MFC程序从诞生到运行的完整故事。一、MFC类层次结构昨天已经梳理过MFC的类层次了,今天梳理其生命周期,还是要提一下。因为它确实很重要,如果把MFC比作一个庞大的家族,那类层次结构就是它的族谱。最顶层的CObject就像家族的老祖宗,所有成员都流淌着它的血液——封装了最基础的功能,比如对象的创建与销毁、序列化等。往下分,就像家族
- php中调用对象的方法可以使用array($object, ‘methodName‘)?
IT 老王
phpandroid开发语言
是的,在PHP中,array($object,'methodName')是一种标准的回调语法,用于表示“调用某个对象的特定方法”。这种语法可以被许多函数(如call_user_func()、call_user_func_array()、usort()等)识别并执行。语法原理在PHP中,可调用对象(callable)有多种形式,其中之一是[对象实例,方法名]数组:第一个元素:对象实例(必须是已实例化
- LLM 大模型学习必知必会系列(十三):基于SWIFT的VLLM推理加速与部署实战
汀、人工智能
LLM技术汇总人工智能自然语言处理LLMAgentvLLMAI大模型大模型部署
LLM大模型学习必知必会系列(十三):基于SWIFT的VLLM推理加速与部署实战1.环境准备GPU设备:A10,3090,V100,A100均可.#设置pip全局镜像(加速下载)pipconfigsetglobal.index-urlhttps://mirrors.aliyun.com/pypi/simple/#安装ms-swiftpipinstall'ms-swift[llm]'-U#vllm与
- CMD,PowerShell、Linux/MAC设置环境变量
sky丶Mamba
零基础转大模型应用开发linuxmacos运维
以下是CMD(Windows)、PowerShell(Windows)、Linux/Mac在临时/永久环境变量操作上的对比表格:环境变量操作对照表(CMDvsPowerShellvsLinux/Mac)操作CMD(Windows)PowerShell(Windows)Linux/Mac(Bash/Zsh)设置临时变量setVAR=value$env:VAR="value"exportVAR=val
- JavaScript知识归纳——面试题
Dream_Lee_1997
JavaScriptjs面试题
JavaScript面试题总结JavaScript知识点1、JavaScript中settimeout与setinteval两个函数的区别?2、编写JavaScript脚本生成1-6之间的整数?3、在JavaScript脚本中,isNaN的作用是什么?4、JavaScript中获取某个元素有哪几种方式?5、Ajax的优缺点都有什么?6、简述一下Ajax的工作原理。7、JavaScript中的数据类
- 什么是ORM?它如何简化后端开发?
破碎的天堂鸟
学习教程数据库
什么是ORM?ORM(对象关系映射,Object-RelationalMapping)是一种编程技术,用于解决面向对象编程语言与关系型数据库之间的数据转换问题。其核心是将数据库中的表结构映射为程序中的类和对象,使开发者能够以操作对象的方式操作数据库,而非直接编写SQL语句。具体而言:映射机制:数据库表→编程语言中的类(如User类对应users表)表字段→类的属性(如username字段对应Use
- 5G RAN接入场景的IMS语音业务开通全流程
码农老gou
5G5G网络
1.UE注册请求声明语音能力UE→AMF:发送RegistrationRequestNAS消息,关键参数:-UE'susagesetting="VoiceCentric"//终端以语音业务为核心-RequestedNSSAI:包含IMS切片标识(S-NSSAI)技术意义:通知网络优先保障语音业务资源(如QoS、移动性管理)。触发AMF按语音终端策略处理注册流程。规范依据:TS24.501§5.5.
- QT5使用cmakelists引入Qt5Xlsx库并使用
1、首先需要已经有了Qt5Xlsx的头文件和库,并拷贝到程序exe路径下(以xxx.exe/3rdparty/qtxlsx路径为例,Qt5Xlsx版本为0.3.0);2、cmakelist中:#设置QtXlsx路径set(QTXLSX_ROOT_DIR${CMAKE_CURRENT_SOURCE_DIR}/3rdparty/qtxlsx)set(QTXLSX_INCLUDE_DIR${QTXLSX
- 【解决Qt报warning: ‘setAxisX‘ is deprecated遇到的问题】
解决Qt报warning:‘setAxisX‘isdeprecated遇到的问题背景:移植老代码时,报如题警告。老代码:m_input_chart->setAxisY(axisY,input_series);然后修改为:m_input_chart->addAxis(axisY,Qt::AlignLeft);input_series->attachAxis(axisY);运行之后没有警告了,但是坐标
- SpringAOP中的JointPoint和ProceedingJoinPoint使用详解(附带详细示例)
如何在5年薪百万
springboot
概念JointPointJointPoint是程序运行过程中可识别的点,这个点可以用来作为AOP切入点。JointPoint对象则包含了和切入相关的很多信息。比如切入点的对象,方法,属性等。我们可以通过反射的方式获取这些点的状态和信息,用于追踪tracing和记录logging应用信息。Pointcutpointcut是一种程序结构和规则,它用于选取joinpoint并收集这些point的上下文信
- 【电脑】主板的基础知识
Mike_Wuzy
电脑
主板(Motherboard)是计算机的核心组件之一,它将所有其他硬件部件连接在一起并协调它们的工作。以下是关于主板的详细知识:1.架构组成一个典型的主板通常由以下几个主要部分构成:芯片组(Chipset):分为南桥和北桥两个部分。北桥(Northbridge):负责处理高速数据传输,如连接内存控制器、显示接口等。现代CPU集成了北桥的功能,因此许多主板上已经不再有独立的北桥芯片。南桥(South
- 如何发现Redis中的bigkey?
代码中の快捷键
redis数据库缓存
如何发现Redis中的bigkey?我主要用这几个方法:redis-cli--bigkeys(最常用,最省事):直接在命令行敲这个命令:redis-cli-h你的redis地址-p端口--bigkeys作用:它会自动扫描整个数据库。结果:告诉你每种数据类型(String,Hash,List,Set,ZSet)里最大的那个key是什么,有多大(比如String多大,List有多少元素)。优点:简单、
- java解析APK
3213213333332132
javaapklinux解析APK
解析apk有两种方法
1、结合安卓提供apktool工具,用java执行cmd解析命令获取apk信息
2、利用相关jar包里的集成方法解析apk
这里只给出第二种方法,因为第一种方法在linux服务器下会出现不在控制范围之内的结果。
public class ApkUtil
{
/**
* 日志对象
*/
private static Logger
- nginx自定义ip访问N种方法
ronin47
nginx 禁止ip访问
因业务需要,禁止一部分内网访问接口, 由于前端架了F5,直接用deny或allow是不行的,这是因为直接获取的前端F5的地址。
所以开始思考有哪些主案可以实现这样的需求,目前可实施的是三种:
一:把ip段放在redis里,写一段lua
二:利用geo传递变量,写一段
- mysql timestamp类型字段的CURRENT_TIMESTAMP与ON UPDATE CURRENT_TIMESTAMP属性
dcj3sjt126com
mysql
timestamp有两个属性,分别是CURRENT_TIMESTAMP 和ON UPDATE CURRENT_TIMESTAMP两种,使用情况分别如下:
1.
CURRENT_TIMESTAMP
当要向数据库执行insert操作时,如果有个timestamp字段属性设为
CURRENT_TIMESTAMP,则无论这
- struts2+spring+hibernate分页显示
171815164
Hibernate
分页显示一直是web开发中一大烦琐的难题,传统的网页设计只在一个JSP或者ASP页面中书写所有关于数据库操作的代码,那样做分页可能简单一点,但当把网站分层开发后,分页就比较困难了,下面是我做Spring+Hibernate+Struts2项目时设计的分页代码,与大家分享交流。
1、DAO层接口的设计,在MemberDao接口中定义了如下两个方法:
public in
- 构建自己的Wrapper应用
g21121
rap
我们已经了解Wrapper的目录结构,下面可是正式利用Wrapper来包装我们自己的应用,这里假设Wrapper的安装目录为:/usr/local/wrapper。
首先,创建项目应用
&nb
- [简单]工作记录_多线程相关
53873039oycg
多线程
最近遇到多线程的问题,原来使用异步请求多个接口(n*3次请求) 方案一 使用多线程一次返回数据,最开始是使用5个线程,一个线程顺序请求3个接口,超时终止返回 缺点 测试发现必须3个接
- 调试jdk中的源码,查看jdk局部变量
程序员是怎么炼成的
jdk 源码
转自:http://www.douban.com/note/211369821/
学习jdk源码时使用--
学习java最好的办法就是看jdk源代码,面对浩瀚的jdk(光源码就有40M多,比一个大型网站的源码都多)从何入手呢,要是能单步调试跟进到jdk源码里并且能查看其中的局部变量最好了。
可惜的是sun提供的jdk并不能查看运行中的局部变量
- Oracle RAC Failover 详解
aijuans
oracle
Oracle RAC 同时具备HA(High Availiablity) 和LB(LoadBalance). 而其高可用性的基础就是Failover(故障转移). 它指集群中任何一个节点的故障都不会影响用户的使用,连接到故障节点的用户会被自动转移到健康节点,从用户感受而言, 是感觉不到这种切换。
Oracle 10g RAC 的Failover 可以分为3种:
1. Client-Si
- form表单提交数据编码方式及tomcat的接受编码方式
antonyup_2006
JavaScripttomcat浏览器互联网servlet
原帖地址:http://www.iteye.com/topic/266705
form有2中方法把数据提交给服务器,get和post,分别说下吧。
(一)get提交
1.首先说下客户端(浏览器)的form表单用get方法是如何将数据编码后提交给服务器端的吧。
对于get方法来说,都是把数据串联在请求的url后面作为参数,如:http://localhost:
- JS初学者必知的基础
百合不是茶
js函数js入门基础
JavaScript是网页的交互语言,实现网页的各种效果,
JavaScript 是世界上最流行的脚本语言。
JavaScript 是属于 web 的语言,它适用于 PC、笔记本电脑、平板电脑和移动电话。
JavaScript 被设计为向 HTML 页面增加交互性。
许多 HTML 开发者都不是程序员,但是 JavaScript 却拥有非常简单的语法。几乎每个人都有能力将小的
- iBatis的分页分析与详解
bijian1013
javaibatis
分页是操作数据库型系统常遇到的问题。分页实现方法很多,但效率的差异就很大了。iBatis是通过什么方式来实现这个分页的了。查看它的实现部分,发现返回的PaginatedList实际上是个接口,实现这个接口的是PaginatedDataList类的对象,查看PaginatedDataList类发现,每次翻页的时候最
- 精通Oracle10编程SQL(15)使用对象类型
bijian1013
oracle数据库plsql
/*
*使用对象类型
*/
--建立和使用简单对象类型
--对象类型包括对象类型规范和对象类型体两部分。
--建立和使用不包含任何方法的对象类型
CREATE OR REPLACE TYPE person_typ1 as OBJECT(
name varchar2(10),gender varchar2(4),birthdate date
);
drop type p
- 【Linux命令二】文本处理命令awk
bit1129
linux命令
awk是Linux用来进行文本处理的命令,在日常工作中,广泛应用于日志分析。awk是一门解释型编程语言,包含变量,数组,循环控制结构,条件控制结构等。它的语法采用类C语言的语法。
awk命令用来做什么?
1.awk适用于具有一定结构的文本行,对其中的列进行提取信息
2.awk可以把当前正在处理的文本行提交给Linux的其它命令处理,然后把直接结构返回给awk
3.awk实际工
- JAVA(ssh2框架)+Flex实现权限控制方案分析
白糖_
java
目前项目使用的是Struts2+Hibernate+Spring的架构模式,目前已经有一套针对SSH2的权限系统,运行良好。但是项目有了新需求:在目前系统的基础上使用Flex逐步取代JSP,在取代JSP过程中可能存在Flex与JSP并存的情况,所以权限系统需要进行修改。
【SSH2权限系统的实现机制】
权限控制分为页面和后台两块:不同类型用户的帐号分配的访问权限是不同的,用户使
- angular.forEach
boyitech
AngularJSAngularJS APIangular.forEach
angular.forEach 描述: 循环对obj对象的每个元素调用iterator, obj对象可以是一个Object或一个Array. Iterator函数调用方法: iterator(value, key, obj), 其中obj是被迭代对象,key是obj的property key或者是数组的index,value就是相应的值啦. (此函数不能够迭代继承的属性.)
- java-谷歌面试题-给定一个排序数组,如何构造一个二叉排序树
bylijinnan
二叉排序树
import java.util.LinkedList;
public class CreateBSTfromSortedArray {
/**
* 题目:给定一个排序数组,如何构造一个二叉排序树
* 递归
*/
public static void main(String[] args) {
int[] data = { 1, 2, 3, 4,
- action执行2次
Chen.H
JavaScriptjspXHTMLcssWebwork
xwork 写道 <action name="userTypeAction"
class="com.ekangcount.website.system.view.action.UserTypeAction">
<result name="ssss" type="dispatcher">
- [时空与能量]逆转时空需要消耗大量能源
comsci
能源
无论如何,人类始终都想摆脱时间和空间的限制....但是受到质量与能量关系的限制,我们人类在目前和今后很长一段时间内,都无法获得大量廉价的能源来进行时空跨越.....
在进行时空穿梭的实验中,消耗超大规模的能源是必然
- oracle的正则表达式(regular expression)详细介绍
daizj
oracle正则表达式
正则表达式是很多编程语言中都有的。可惜oracle8i、oracle9i中一直迟迟不肯加入,好在oracle10g中终于增加了期盼已久的正则表达式功能。你可以在oracle10g中使用正则表达式肆意地匹配你想匹配的任何字符串了。
正则表达式中常用到的元数据(metacharacter)如下:
^ 匹配字符串的开头位置。
$ 匹配支付传的结尾位置。
*
- 报表工具与报表性能的关系
datamachine
报表工具birt报表性能润乾报表
在选择报表工具时,性能一直是用户关心的指标,但是,报表工具的性能和整个报表系统的性能有多大关系呢?
要回答这个问题,首先要分析一下报表的处理过程包含哪些环节,哪些环节容易出现性能瓶颈,如何优化这些环节。
一、报表处理的一般过程分析
1、用户选择报表输入参数后,报表引擎会根据报表模板和输入参数来解析报表,并将数据计算和读取请求以SQL的方式发送给数据库。
2、
- 初一上学期难记忆单词背诵第一课
dcj3sjt126com
wordenglish
what 什么
your 你
name 名字
my 我的
am 是
one 一
two 二
three 三
four 四
five 五
class 班级,课
six 六
seven 七
eight 八
nince 九
ten 十
zero 零
how 怎样
old 老的
eleven 十一
twelve 十二
thirteen
- 我学过和准备学的各种技术
dcj3sjt126com
技术
语言VB https://msdn.microsoft.com/zh-cn/library/2x7h1hfk.aspxJava http://docs.oracle.com/javase/8/C# https://msdn.microsoft.com/library/vstudioPHP http://php.net/manual/en/Html
- struts2中token防止重复提交表单
蕃薯耀
重复提交表单struts2中token
struts2中token防止重复提交表单
>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>
蕃薯耀 2015年7月12日 11:52:32 星期日
ht
- 线性查找二维数组
hao3100590
二维数组
1.算法描述
有序(行有序,列有序,且每行从左至右递增,列从上至下递增)二维数组查找,要求复杂度O(n)
2.使用到的相关知识:
结构体定义和使用,二维数组传递(http://blog.csdn.net/yzhhmhm/article/details/2045816)
3.使用数组名传递
这个的不便之处很明显,一旦确定就是不能设置列值
//使
- spring security 3中推荐使用BCrypt算法加密密码
jackyrong
Spring Security
spring security 3中推荐使用BCrypt算法加密密码了,以前使用的是md5,
Md5PasswordEncoder 和 ShaPasswordEncoder,现在不推荐了,推荐用bcrpt
Bcrpt中的salt可以是随机的,比如:
int i = 0;
while (i < 10) {
String password = "1234
- 学习编程并不难,做到以下几点即可!
lampcy
javahtml编程语言
不论你是想自己设计游戏,还是开发iPhone或安卓手机上的应用,还是仅仅为了娱乐,学习编程语言都是一条必经之路。编程语言种类繁多,用途各 异,然而一旦掌握其中之一,其他的也就迎刃而解。作为初学者,你可能要先从Java或HTML开始学,一旦掌握了一门编程语言,你就发挥无穷的想象,开发 各种神奇的软件啦。
1、确定目标
学习编程语言既充满乐趣,又充满挑战。有些花费多年时间学习一门编程语言的大学生到
- 架构师之mysql----------------用group+inner join,left join ,right join 查重复数据(替代in)
nannan408
right join
1.前言。
如题。
2.代码
(1)单表查重复数据,根据a分组
SELECT m.a,m.b, INNER JOIN (select a,b,COUNT(*) AS rank FROM test.`A` A GROUP BY a HAVING rank>1 )k ON m.a=k.a
(2)多表查询 ,
使用改为le
- jQuery选择器小结 VS 节点查找(附css的一些东西)
Everyday都不同
jquerycssname选择器追加元素查找节点
最近做前端页面,频繁用到一些jQuery的选择器,所以特意来总结一下:
测试页面:
<html>
<head>
<script src="jquery-1.7.2.min.js"></script>
<script>
/*$(function() {
$(documen
- 关于EXT
tntxia
ext
ExtJS是一个很不错的Ajax框架,可以用来开发带有华丽外观的富客户端应用,使得我们的b/s应用更加具有活力及生命力。ExtJS是一个用 javascript编写,与后台技术无关的前端ajax框架。因此,可以把ExtJS用在.Net、Java、Php等各种开发语言开发的应用中。
ExtJs最开始基于YUI技术,由开发人员Jack
- 一个MIT计算机博士对数学的思考
xjnine
Math
在过去的一年中,我一直在数学的海洋中游荡,research进展不多,对于数学世界的阅历算是有了一些长进。为什么要深入数学的世界?作为计算机的学生,我没有任何企图要成为一个数学家。我学习数学的目的,是要想爬上巨人的肩膀,希望站在更高的高度,能把我自己研究的东西看得更深广一些。说起来,我在刚来这个学校的时候,并没有预料到我将会有一个深入数学的旅程。我的导师最初希望我去做的题目,是对appe