Zookeeper介绍和特点
一.什么是ZooKeeper
Zookeeper的由来
Zookeeper最早起源于雅虎研究院的一个研究小组。在当时,研究人员发现,在雅虎内部很多大型系统基本都需要依赖一个类似的系统来进行分布式协调,但是这些系统往往都存在分布式单点问题。所以,雅虎的开发人员就试图开发一个通用的无单点问题的分布式协调框架,以便让开发人员将精力集中在处理业务逻辑上。
关于“ZooKeeper”这个项目的名字,其实也有一段趣闻。在立项初期,考虑到之前内部很多项目都是使用动物的名字来命名的(例如著名的Pig项目),雅虎的工程师希望给这个项目也取一个动物的名字。时任研究院的首席科学家RaghuRamakrishnan开玩笑地说:“在这样下去,我们这儿就变成动物园了!”此话一出,大家纷纷表示就叫动物园管理员吧一一一因为各个以动物命名的分布式组件放在一起,雅虎的整个分布式系统看上去就像一个大型的动物园了,而Zookeeper正好要用来进行分布式环境的协调一一于是,Zookeeper的名字也就由此诞生了。
顾名思义 zookeeper 就是动物园管理员,他是用来管 hadoop(大象)、Hive(蜜蜂)、pig(小
猪)的管理员, Apache Hbase 和 Apache Solr 的分布式集群都用到了 zookeeper;Zookeeper:
是一个分布式的、开源的程序协调服务,是 hadoop 项目下的一个子项目。他提供的主要功
能包括:配置管理、名字服务、分布式锁、集群管理。
1.1Zookeeper概览
顾名思义 zookeeper 就是动物园管理员,他是用来管 hadoop(大象)、Hive(蜜蜂)、pig(小
猪)的管理员, Apache Hbase 和 Apache Solr 的分布式集群都用到了 zookeeper;Zookeeper:
是一个分布式的、开源的程序协调服务,是 hadoop 项目下的一个子项目。他提供的主要功
能包括:配置管理、名字服务、分布式锁、集群管理。
ZooKeeper 是一个典型的分布式数据一致性解决方案,分布式应用程序可以基于 ZooKeeper 实现诸如数据发布/订阅、负载均衡、命名服务、分布式协调/通知、集群管理、Master 选举、分布式锁和分布式队列等功能。
Zookeeper 一个最常用的使用场景就是用于担任服务生产者和服务消费者的注册中心(提供发布订阅服务)。 服务生产者将自己提供的服务注册到Zookeeper中心,服务的消费者在进行服务调用的时候先到Zookeeper中查找服务,获取到服务生产者的详细信息之后,再去调用服务生产者的内容与数据。如下图所示,在 Dubbo架构中 Zookeeper 就担任了注册中心这一角色。

1.2 ZooKeeper的作用
1.1配置管理
在我们的应用中除了代码外,还有一些就是各种配置。比如数据库连接等。一般我们都
是使用配置文件的方式,在代码中引入这些配置文件。当我们只有一种配置,只有一台服务
器,并且不经常修改的时候,使用配置文件是一个很好的做法,但是如果我们配置非常多,
有很多服务器都需要这个配置,这时使用配置文件就不是个好主意了。这个时候往往需要寻
找一种集中管理配置的方法,我们在这个集中的地方修改了配置,所有对这个配置感兴趣的
都可以获得变更。Zookeeper 就是这种服务,它使用 Zab 这种一致性协议来提供一致性。现
在有很多开源项目使用 Zookeeper 来维护配置,比如在 HBase 中,客户端就是连接一个
Zookeeper,获得必要的 HBase 集群的配置信息,然后才可以进一步操作。还有在开源的消
息队列 Kafka 中,也使用 Zookeeper 来维护 broker 的信息。在 Alibaba 开源的 SOA 框架 Dubbo
中也广泛的使用 Zookeeper 管理一些配置来实现服务治理。
1.2名字服务
名字服务这个就很好理解了。比如为了通过网络访问一个系统,我们得知道对方的 IP
地址,但是 IP 地址对人非常不友好,这个时候我们就需要使用域名来访问。但是计算机是
不能是域名的。怎么办呢?如果我们每台机器里都备有一份域名到 IP 地址的映射,这个倒
是能解决一部分问题,但是如果域名对应的 IP 发生变化了又该怎么办呢?于是我们有了
DNS 这个东西。我们只需要访问一个大家熟知的(known)的点,它就会告诉你这个域名对应
的 IP 是什么。在我们的应用中也会存在很多这类问题,特别是在我们的服务特别多的时候,
如果我们在本地保存服务的地址的时候将非常不方便,但是如果我们只需要访问一个大家都
熟知的访问点,这里提供统一的入口,那么维护起来将方便得多了。
1.3分布式锁
其实在第一篇文章中已经介绍了 Zookeeper 是一个分布式协调服务。这样我们就可以利
用 Zookeeper 来协调多个分布式进程之间的活动。比如在一个分布式环境中,为了提高可靠
性,我们的集群的每台服务器上都部署着同样的服务。但是,一件事情如果集群中的每个服
务器都进行的话,那相互之间就要协调,编程起来将非常复杂。而如果我们只让一个服务进
行操作,那又存在单点。通常还有一种做法就是使用分布式锁,在某个时刻只让一个服务去
干活,当这台服务出问题的时候锁释放,立即 fail over 到另外的服务。这在很多分布式系统
中都是这么做,这种设计有一个更好听的名字叫 Leader Election(leader 选举)。比如 HBase
的 Master 就是采用这种机制。但要注意的是分布式锁跟同一个进程的锁还是有区别的,所
以使用的时候要比同一个进程里的锁更谨慎的使用。
1.4集群管理
在分布式的集群中,经常会由于各种原因,比如硬件故障,软件故障,网络问题,有些
节点会进进出出。有新的节点加入进来,也有老的节点退出集群。这个时候,集群中其他机
器需要感知到这种变化,然后根据这种变化做出对应的决策。比如我们是一个分布式存储系
统,有一个中央控制节点负责存储的分配,当有新的存储进来的时候我们要根据现在集群目
前的状态来分配存储节点。这个时候我们就需要动态感知到集群目前的状态。还有,比如一
个分布式的 SOA 架构中,服务是一个集群提供的,当消费者访问某个服务时,就需要采用
某种机制发现现在有哪些节点可以提供该服务(这也称之为服务发现,比如 Alibaba 开源的
SOA 框架 Dubbo 就采用了 Zookeeper 作为服务发现的底层机制)。还有开源的 Kafka 队列就
采用了 Zookeeper 作为 Cosnumer 的上下线管理。
二.ZooKeeper的一些重要概念
2.1 重要概念总结
1. ZooKeeper 本身就是一个分布式程序(只要半数以上节点存活,ZooKeeper 就能正常服务)。
2…为了保证高可用,最好是以集群形态来部署 ZooKeeper,这样只要集群中大部分机器是可用的(能够容忍一定的机器故障),那么 ZooKeeper 本身仍然是可用的。
3. ZooKeeper 将数据保存在内存中,这也就保证了 高吞吐量和低延迟(但是内存限制了能够存储的容量不太大,此限制也是保持znode中存储的数据量较小的进一步原因)。
4. ZooKeeper 是高性能的。 在“读”多于“写”的应用程序中尤其地高性能,因为“写”会导致所有的服务器间同步状态。(“读”多于“写”是协调服务的典型场景。)
5. ZooKeeper有临时节点的概念。 当创建临时节点的客户端会话一直保持活动,瞬时节点就一直存在。而当会话终结时,瞬时节点被删除。持久节点是指一旦这个ZNode被创建了,除非主动进行ZNode的移除操作,否则这个ZNode将一直保存在Zookeeper上。
6. ZooKeeper 底层其实只提供了两个功能:①管理(存储、读取)用户程序提交的数据;②为用户程序提供数据节点监听服务。
2.2会话
Session 指的是 ZooKeeper 服务器与客户端会话。在 ZooKeeper 中,一个客户端连接是指客户端和服务器之间的一个 TCP 长连接。客户端启动的时候,首先会与服务器建立一个 TCP 连接,从第一次连接建立开始,客户端会话的生命周期也开始了。通过这个连接,客户端能够通过心跳检测与服务器保持有效的会话,也能够向Zookeeper服务器发送请求并接受响应,同时还能够通过该连接接收来自服务器的Watch事件通知。 Session的sessionTimeout值用来设置一个客户端会话的超时时间。当由于服务器压力太大、网络故障或是客户端主动断开连接等各种原因导致客户端连接断开时,只要在sessionTimeout规定的时间内能够重新连接上集群中任意一台服务器,那么之前创建的会话仍然有效。
在为客户端创建会话之前,服务端首先会为每个客户端都分配一个sessionID。由于 sessionID 是 Zookeeper 会话的一个重要标识,许多与会话相关的运行机制都是基于这个 sessionID 的,因此,无论是哪台服务器为客户端分配的 sessionID,都务必保证全局唯一。
2.3Znode
在 Zookeeper 中,znode 是一个跟 Unix 文件系统路径相似的节点,可以往这个节点存储
或获取数据。
Zookeeper 底层是一套数据结构。这个存储结构是一个树形结构,其上的每一个节点,
我们称之为“znode”
zookeeper 中的数据是按照“树”结构进行存储的。而且 znode 节点还分为 4 中不同的类
型。
每一个 znode 默认能够存储 1MB 的数据(对于记录状态性质的数据来说,够了)
可以使用 zkCli 命令,登录到 zookeeper 上,并通过 ls、create、delete、get、set 等命令
操作这些 znode 节点.
2.4Znode节点类型
(1)PERSISTENT 持久化节点: 所谓持久节点,是指在节点创建后,就一直存在,直到
有删除操作来主动清除这个节点。否则不会因为创建该节点的客户端会话失效而消失。
**(2)PERSISTENT_SEQUENTIAL 持久顺序节点:**这类节点的基本特性和上面的节点类
型是一致的。额外的特性是,在 ZK 中,每个父节点会为他的第一级子节点维护一份时序,
会记录每个子节点创建的先后顺序。基于这个特性,在创建子节点的时候,可以设置这个属
性,那么在创建节点过程中,ZK 会自动为给定节点名加上一个数字后缀,作为新的节点名。
这个数字后缀的范围是整型的最大值。在创建节点的时候只需要传入节点 “/test_”,这样
之后,zookeeper 自动会给”test_”后面补充数字。
**(3)EPHEMERAL 临时节点:**和持久节点不同的是,临时节点的生命周期和客户端会
话绑定。也就是说,如果客户端会话失效,那么这个节点就会自动被清除掉。注意,这里提
到的是会话失效,而非连接断开。另外,在临时节点下面不能创建子节点。
这里还要注意一件事,就是当你客户端会话失效后,所产生的节点也不是一下子就消失
了,也要过一段时间,大概是 10 秒以内,可以试一下,本机操作生成节点,在服务器端用
命令来查看当前的节点数目,你会发现客户端已经 stop,但是产生的节点还在。
**(4) EPHEMERAL_SEQUENTIAL 临时自动编号节点:**此节点是属于临时节点,不过带
有顺序,客户端会话结束节点就消失。
2.4 Watcher
Watcher,就是事件监听器,Zookeeper允许用户注册一些watcher,并且在一些事件特定触发时,ZooKeeper会将通知发给客户端。
2.5 ACL
Zookeeper采用ACL(AccessControlLists)策略来进行权限控制,类似于 UNIX 文件系统的权限控制。Zookeeper 定义了如下5种权限。
1. create:创建子节点的权限
2. read:获取节点数据和子节点列表的权限
3. write:更新节点的权限
4. delete:删除节点的权限
5. admin:设置节点ACL的权限
三.ZooKeeper的特点
- 顺序一致性: 从同一客户端发起的事务请求,最终将会严格地按照顺序被应用到 ZooKeeper 中去。
- 原子性: 所有事务请求的处理结果在整个集群中所有机器上的应用情况是一致的,也就是说,要么整个集群中所有的机器都成功应用了某一个事务,要么都没有应用。
- **单一系统映像 **: 无论客户端连到哪一个 ZooKeeper 服务器上,其看到的服务端数据模型都是一致的。
4.可靠性: 一旦一次更改请求被应用,更改的结果就会被持久化,直到被下一次更改覆盖。
四.ZooKeeper的设计特点
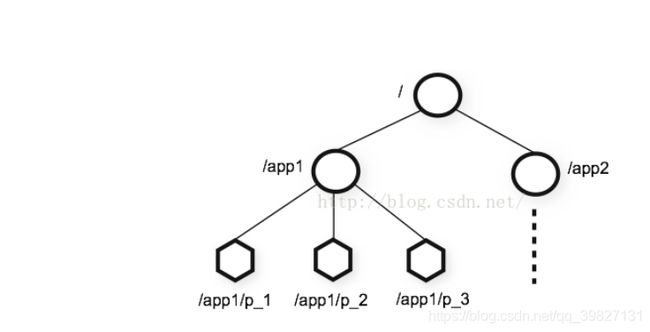
4.1 ZooKeeper的数据模型
数据模型: ZooKeeper 采用的类似文件系统的形式保存数据,文件系统中的每一个节点
(Znode)都由一个路径唯一标识。在整个数据存储的路径中 / 表示根节点,其他的 Znode
节点,都是相对于根节点。Znode 可以拥有子节点。
4.2可搭建集群
ZooKeeper官方架构图:
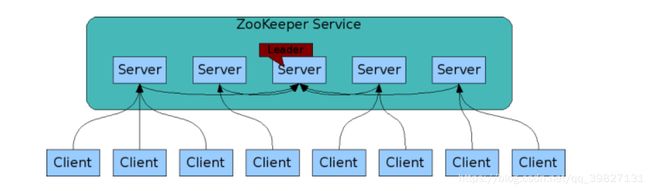
五. ZooKeeper集群角色介绍
在 ZooKeeper 中没有选择传统的 Master/Slave 概念,而是引入了**Leader、Follower 和 Observer **三种角色。如下图所示:

ZooKeeper 集群中的所有机器通过一个 Leader 选举过程来选定一台称为 “Leader” 的机器,Leader 既可以为客户端提供写服务又能提供读服务。除了 Leader 外,Follower 和 Observer 都只能提供读服务。Follower 和 Observer 唯一的区别在于 Observer 机器不参与 Leader 的选举过程,也不参与写操作的“过半写成功”策略,因此 Observer 机器可以在不影响写性能的情况下提升集群的读性能。

六.ZooKeeper ,ZAB 协议,Paxos算法
6.1ZAB 协议&Paxos算法
ZooKeeper 并没有完全采用 Paxos算法 ,而是使用 ZAB 协议作为其保证数据一致性的核心算法。另外,在ZooKeeper的官方文档中也指出,ZAB协议并不像 Paxos 算法那样,是一种通用的分布式一致性算法,它是一种特别为Zookeeper设计的崩溃可恢复的原子消息广播算法。
6.2 ZAB 协议介绍
ZAB(ZooKeeper Atomic Broadcast 原子广播) 协议是为分布式协调服务 ZooKeeper 专门设计的一种支持崩溃恢复的原子广播协议。 在 ZooKeeper 中,主要依赖 ZAB 协议来实现分布式数据一致性,基于该协议,ZooKeeper 实现了一种主备模式的系统架构来保持集群中各个副本之间的数据一致性。
- http://codemacro.com/2014/10/15/explain-poxos/图解Paxos协议
- https://dbaplus.cn/news-141-1875-1.htmlZAB协议分析
参考
1.https://snailclimb.gitee.io/javaguide/