机器学习笔记:如何用xLearn实现FFM算法

在推荐系统和计算广告业务中,点击率CTR(click-through rate)和转化率CVR(conversion rate)是衡量流量转化的两个关键指标。准确的估计CTR、CVR对于提高流量的价值,增加广告及电商收入有重要的指导作用。FM近年来表现突出,分别在由Criteo和Avazu举办的CTR预测竞赛中夺得冠军。因子分解机(Factorization Machine, FM)是由Steffen Rendle提出的一种基于矩阵分解的机器学习算法,其主要用于解决数据稀疏的业务场景(如推荐业务),特征组合的问题。
1
FM原理
任何从事点击率预测问题或者推荐系统相关工作的人都会遇到类似的情况。由于数据量巨大,利用有限的计算资源对这些数据集进行预测是很有挑战性的。
一般地,categories特征经过one-hot编码以后,样本数据会变得很稀疏,假设有10万个item,如果对item的这个特征进行one-hot编码,这个维度的数据稀疏性就是十万分之一,同时编码后样本空间有一个categories会变成10万维,特征空间急剧增长。由于很多特征对预测并不重要,在数据稀疏的场景下,因子分解有助于从原始数据中提取到重要的潜式或隐式的特征。
多项式模型是包含特征组合的最直观的模型。根据矩阵论的知识,对任意实矩阵W,存在矩阵V,使得W=V*V^t。因此二阶FM(2-way FM)公式为:
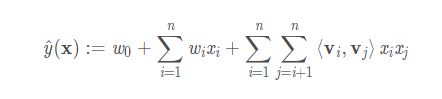
其中,各个参数的size为:
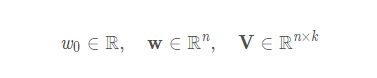
内积定义如下:
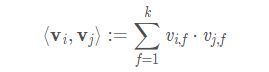
其中k表示的是决定分解机维度的超参。n表示的是模型参数的维度。2-way的FM捕捉了所有的单独的特征以及变量之间的特征。从公式来看,模型前半部分就是普通的LR线性组合,后半部分的交叉项即特征的组合。单从模型表达能力上来看,FM的表达能力是强于LR的,至少不会比LR弱,当交叉项参数全为0时退化为普通的LR模型。
FM与SVM相似,是具有多项式核的predictor,同时与SVM相比具有以下优势:
FM支持在稀疏数据上进行参数估计,而SVM会效果很差,因为训出的SVM模型会面临较高的bias
FM拥有线性的复杂度, 可以通过原始数据来优化,而SVM则依赖于support vectors(支持向量)确定超平面
FM是一种可以与任何实值特征向量一起使用的通用预测器。与此相反,其他最先进的因子分解模型仅适用于非常有限的输入数据
2
FFM原理
FFM模型中引入了类别的概念,即field。举例来说,在FM原理讲解中,“男性”与“篮球”、“男性”与“年龄”所起潜在作用是默认一样的,但实际上不一定。FM算法无法捕捉这个差异,因为它不区分更广泛类别field的概念,而会使用相同参数的点积来计算。
设样本一共有n个特征, f个field,那么FFM的二次项有nf个隐向量。而在FM模型中,每一维特征的隐向量只有一个。FM可以看作FFM的特例,是把所有特征都归属到一个field时的FFM模型。

在训练FFM的过程中,有许多小细节值得特别关注:
样本归一化。FFM默认是进行样本数据的归一化,此参数设置为假,很容易造成数据inf溢出,进而引起梯度计算的nan错误。因此,样本层面的数据是推荐进行归一化的。
特征归一化。CTR/CVR模型采用了多种类型的源特征,包括数值型和categorical类型等。但是,categorical类编码后的特征取值只有0或1,较大的数值型特征会造成样本归一化后categorical类生成特征的值非常小,没有区分性。
省略零值特征,零值特征对模型完全没有贡献。包含零值特征的一次项和组合项均为零,对于训练模型参数或者目标值预估是没有作用的。因此,可以省去零值特征,提高FFM模型训练和预测的速度,这也是稀疏样本采用FFM的显著优势。
3
xLearn实现
实现FM & FFM的最流行的python库有:LibFM、LibFFM、xlearn和tffm。
xLearn是一款高性能,易于使用且可扩展的机器学习软件包,包括FM和FFM模型,可用于大规模解决机器学习问题。xlearn的官方地址:https://github.com/aksnzhy/xlearn ,它支持丰富的python接口,支持多种优化算法与超参调优。xLearn可以直接处理csv以及libsvm格式的数据来实现FM算法,但对FFM算法而言,我们必须将数据转换为libffm格式。
训练数据格式的样式为:
格式转换的关键代码为:
def convert_to_ffm(df,type,numerics,categories,features):
currentcode = len(numerics)
catdict = {}
catcodes = {}
# Flagging categorical and numerical fields
for x in numerics:
catdict[x] = 0
for x in categories:
catdict[x] = 1
nrows = df.shape[0]
ncolumns = len(features)
with open(str(type) + "_ffm.txt", "w") as text_file:
# Looping over rows to convert each row to libffm format
for n, r in enumerate(range(nrows)):
datastring = ""
datarow = df.iloc[r].to_dict()
datastring += str(int(datarow['Loan_Status'])) # Set Target Variable here
# For numerical fields, we are creating a dummy field here
for i, x in enumerate(catdict.keys()):
if(catdict[x]==0):
datastring = datastring + " "+str(i)+":"+ str(i)+":"+ str(datarow[x])
else:
# For a new field appearing in a training example
if(x not in catcodes):
catcodes[x] = {}
currentcode +=1
catcodes[x][datarow[x]] = currentcode #encoding the feature
# For already encoded fields
elif(datarow[x] not in catcodes[x]):
currentcode +=1
catcodes[x][datarow[x]] = currentcode #encoding the feature
code = catcodes[x][datarow[x]]
datastring = datastring + " "+str(i)+":"+ str(int(code))+":1"
datastring += '\n'
text_file.write(datastring)
使用CRITEO_CTR比赛的简略数据,构建简单的FFM模型,https://github.com/aksnzhy/xlearn/tree/master/demo/classification/criteo_ctr,
import xlearn as xl
# Training task
ffm_model = xl.create_ffm() # Use field-aware factorization machine (ffm)
ffm_model.setTrain("./small_train.txt") # Set the path of training data
# parameter:
# 0. task: binary classification
# 1. learning rate : 0.2
# 2. regular lambda : 0.002
param = {'task':'binary', 'lr':0.2, 'lambda':0.002}
# Train model
ffm_model.fit(param, "./model.out")
我们发现,xLearn 训练过后在当前文件夹下产生了一个叫 model.out 的新文件。这个文件用来存储训练后的模型,我们可以用这个模型在未来进行预测:
ffm_model.setTest("./small_test.txt")
ffm_model.predict("./model.out", "./output.txt")
在 xLearn 中,用户可以将分数通过 setSigmoid() API 转换到(0-1)之间:
ffm_model.setSigmoid()
ffm_model.setTest("./small_test.txt")
ffm_model.predict("./model.out", "./output.txt")
参考链接:
FM论文:
https://www.csie.ntu.edu.tw/~b97053/paper/Rendle2010FM.pdf
FFM论文:
https://www.csie.ntu.edu.tw/~cjlin/papers/ffm.pdf
FM在特征组合中的应
用:
https://www.cnblogs.com/zhangchaoyang/articles/7897085.html
推荐系统FM & FFM算法解读与实践:
https://blog.csdn.net/baymax_007/article/details/83931698
各位小伙伴如有兴趣交流,欢迎关注公众号留言勾搭
代码猴



在看点这里
