Redis有序集合
文章目录
-
- 一、有序集合介绍
- 二、常用命令介绍
- 三、有序集合数据结构
-
- 为什么有序集合需要同时使用跳跃表和字典来实现?
- 采用哪种编码由什么决定?
- 压缩列表
-
- 压缩列表节点的构成
- 跳跃表
一、有序集合介绍
有序集合,顾名思义,元素有序且唯一的集合,满足有序性、唯一性、确定性,sorted set、zset都是指的有序集合。
二、常用命令介绍
有序集合共有25个相关命令,这里只介绍常用的命令,其他的可以去官方文档查看。
添加元素
ZADD key [NX|XX] [CH] [INCR]score member [score member …]
key:有序集合的键;
NX:不存在才添加该元素,类似HashMap的putIfAbsent;
XX:存在时才添加元素,也就是覆盖;
CH:返回值将会是元素产生改变的数量,不加这个选项只改变分数是不会计数的;
INCR:在原分数的基础上加上新的分数,而不是覆盖;
score:元素的分数,分数越小,排名越靠前,排名从0开始,分数相同的情况下再按照字典序进行排序;
member:元素成员
元素加分
ZINCRBY key increment member
increment:待加分数
等同于ZADD key INCRY score member
查询元素个数
ZCARD key
统计分数范围内的元素个数
ZCOUNT key min max
min:最小分数
max:最大分数
使用示例:
分数在负无穷到正无穷范围内的元素个数,也就是所有元素个数,效果同ZCARD
ZCOUNT myzset -inf +inf
统计分数大于1小于等于3的元素个数
ZCOUNT myzset (1 3
按排名范围查找
ZRANGE key start stop [WITHSCORES]
start:开始索引
stop:结束索引
WITHSCORES:同时查询出分数
使用示例:
ZRANGE myset 0 -1 WITHSCORES
按分数范围查找
ZRANGEBYSCORE key min max [WITHSCORES] [LIMIT offset count]
LIMIT offset count类似mysql的用法,不再赘述
按排名倒序范围查询
ZREVRANGE key start stop [WITHSCORES]
按分数倒序范围查询
ZREVRANGEBYSCORE key max min [WITHSCORES] [LIMIT offset count]
查询元素分数
ZSCORE key member
查询元素排名
ZRANK key member
排名从0开始
查询元素倒序排名
ZREVRANK key member
删除元素
ZREM key member [member …]
按排名范围删除元素
ZREMRANGEBYRANK key start stop
按分数范围删除元素
ZREMRANGEBYSCORE key min max
lex相关的命令是分数相同时按字典序进行相关操作的命令,使用较少,这里不做介绍,有兴趣的自己查看官方文档:https://redis.io/commands
三、有序集合数据结构
Redis的五种数据结构在Redis的实现中都表示为一个Redis对象,对象包含了类型、编码、具体的数据等信息,有序集合的编码可以是zipList或skipList,ziplist编码的压缩列表对象使用压缩列表作为底层实现,每个集合元素使用两个紧挨在一起的压缩列表节点来保存,第一个节点保存元素的成员(member),而第二个元素则保存元素的分值(score)。
压缩列表内的集合元素按分值从小到大进行排序,分值较小的元素被放置在靠近表头的方向,而分值较大的元素则被放置在靠近表尾的方向。


skiplist编码的有序集合对象使用zset结构作为底层实现,一个zset结构同时包含一个字典和一个跳跃表:
typedef struct zset {
zskiplist *zsl;
dict *dict;
} zset;
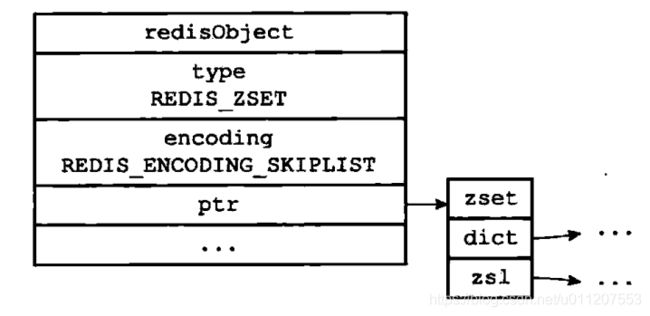
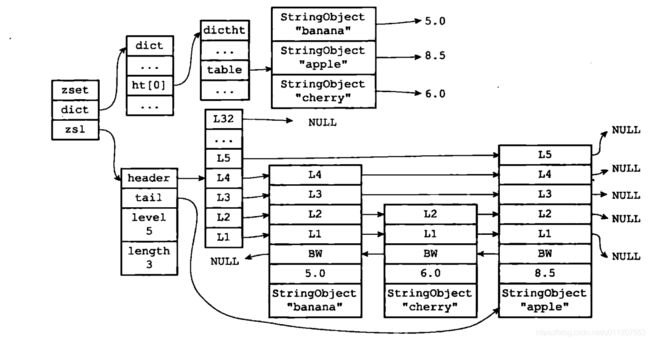
为什么有序集合需要同时使用跳跃表和字典来实现?
在理论上,有序集合可以单独使用字典或者跳跃表的其中一种数据结构来实现,但无论单独使用字典还是跳跃表,在性能上对比起同时使用字典和跳跃表都会有所降低。
举个例子,如果我们只使用字典来实现有序集合,那么虽然以O(1)复杂度查找成员的分值这一特性会被保留,但是,因为字典以无序的方式来保存集合元素,所以每次在执行范围型操作一一一比如ZRANK、ZRANG等命令时,程序都需要对字典保存的所有元素进行排序,完成这种排序需要至少O(NlogN)时间复杂度,以及额外的O(N)内存空间(因为要创建一个数组来保存排序后的元素)。
另一方面,如果我们只使用跳跃表来实现有序集合,那么跳跃表执行范围型操作的所有优点都会被保留,但因为没有了字典,所以根据成员查找分值这一操作的复杂度将从O(1)上升为O(logN)。因为以上原因,为了让有序集合的查找和范围型操作都尽可能快地执行,Redis选择了同时使用字典和跳跃表两种数据结构来实现有序集合。
采用哪种编码由什么决定?
当有序集合对象可以同时满足以下两个条件时,对象使用ziplist编码:
- 有序集合保存的元素数量小于128个;
- 有序集合保存的所有元素成员的长度都小于64字节;
不能满足以上两个条件的有序集合对象将使用skiplist编码。
以上两个条件的上限值可以通过zset-max-ziplist-entries(默认128)和zset-max-ziplist-value(默认64)来调整,当编码从ziplist转换成skiplist后,即便删除元素满足了上述条件,编码也不会从skiplist重新转换成ziplist。
压缩列表
压缩列表(zset)是列表键和哈希键的底层实现之一。当一个列表键只包含少量列表项,并且每个列表项要么就是小整数值,要么就是长度比较短的字符串,那么Redis就会使用压缩列表来做列表键的底层实现。
压缩列表的构成
压缩列表是Redis为了节约内存而开发的,是由一系列特殊编码的连续内存块组成的顺序型(sequential)数据结构。一个压缩列表可以包含任意多个节点(entry),每个节点可以保存一个字节数组或者一个整数值。

压缩列表各个组成部分的说明
| 属性 | 类型 | 长度 | 用途 |
|---|---|---|---|
| zlbytes | uint32_t | 4字节 | 记录整个压缩列表占用的内存字节数:在对压缩列表进行内存重分配,或者计算zlend的位置时使用 |
| zltail | uint32_t | 4字节 | 记录压缩列表表尾节点距离压缩列表的起始地址有多少字节:通过这个偏移量,程序无须遍历整个压缩列表就可以确定表尾节点的地址 |
| zllen | uint16_t | 2字节 | 记录了压缩列表包含的节点数量:当这个属性的值小于UINT16_MAX(65535)时,这个属性的值就是压缩列表包含节点的数量;当这个值等于UINT16_MAX时,节点的真实数量需要遍历整个压缩列表才能计算得出 |
| entryX | 列表节点 | 不定 | 压缩列表包含的各个节点,节点的长度由节点保存的内容决定 |
| zlend | uint8_t | 1字节 | 特殊值0xFF(十进制255),用于标记压缩列表的末端 |
压缩列表节点的构成
每个压缩列表节点可以保存一个字节数组或者一个整数值,其中,字节数组可以是以下三种长度的其中一种:
- 长度小于等于63(26一1)字节的字节数组;
- 长度小于等于16383(2]4一1)字节的字节数组;
- 长度小于等于4294967295(232一1)字节的字节数组;
而整数值则可以是以下六种长度的其中一种:
- 4位长,介于0至12之间的无符号整数
- 1字节长的有符号整数;
- 3字节长的有符号整数;
- uint16_t类型整数;
- uint32_t类型整数;
- uint64_t类型整数。

previous_entry_length
节点的属性以字节为单位,记录了压缩列表中前一个节点的长度。
previousentry_length属性的长度可以是1字节或者5字节:
- 如果前一节点的长度小于254字节,那么previous_entry_length属性的长度为1字节:前一节点的长度就保存在这一个字节里面。
- 如果前一节点的长度大于等于254字节,那么previous_entry_length属性的长度为5字节:其中属性的第一字节会被设置为0xFE(十进制值254),而之后的四个字节则用于保存前一节点的长度。
encoding
节点的encoding属性记录了节点的content属性所保存数据的类型以及长度:
- 一字节、两字节或者五字节长,值的最高位为00、01或者10的是字节数组编码:这种编码表示节点的content属性保存着字节数组,数组的长度由编码除去最高两位之后的其他位记录;
- 一字节长,值的最高位以11开头的是整数编码:这种编码表示节点的content属性保存着整数值,整数值的类型和长度由编码除去最高两位之后的其他位记录。
content
每个压缩列表节点可以保存一个字节数组或者一个整数值,其中,字节数组可以是以下三种长度的其中一种:
- 长度小于等于63(26一1)字节的字节数组;
- 长度小于等于16383(2]4一1)字节的字节数组;
- 长度小于等于4294967295(232一1)字节的字节数组;
而整数值则可以是以下六种长度的其中一种:
- 4位长,介于0至12之间的无符号整数
- 1字节长的有符号整数;
- 3字节长的有符号整数;

压缩列表操作API
| 函数 | 作用 | 算法复杂度 |
|---|---|---|
| ziplistNew | 创建一个新的压缩列表 | O(1) |
| ziplistPush | 创建一个包含给定值的新节点,并将这个新节点添加到压缩列表的表头或者表尾 | 平均O(N),最坏O(N^2) |
| ziplistlnsert | 将包含给定值的新节点插人到给定节点 | 平均O(N),最坏O(N^2) |
| ziplistlndex | 返回压缩列表给定索引上的节点 | O(N) |
| ziplistFind | 在压缩列表中查找并返回包含了给定值的节点 | 因为节点的值可能是一个字节数组,所以检查节点值和给定值是否相同的复杂度为O(N),而查找整个列表的复杂度则为O(N^2) |
| ziplistNext | 返回给定节点的下一个节点 | O(1) |
| ziplistPrev | 返回给定节点的前一个节点 | O(1) |
| ziplistGet | 获取给定节点所保存的值 | O(1) |
| ZiplistDelete | 从压缩列表中删除给定的节点 | 平均O(N),最坏O(N^2) |
| ziplistDeleteRange | 删除压缩列表在给定索引上的连续多个节点 | 平均O(N),最坏O(N^2) |
| ziplistBlobLen | 返回压缩列表目前占用的内存字节数 | O(1) |
| ziplistLen | 返回压缩列表目前包含的节点数量 | 节点数量小于65535时为O(1),大于65535时为O(N^2) |
跳跃表
跳跃表(skiplist)是一种有序数据结构,它通过在每个节点中维持多个指向其他节点的指针,从而达到快速访问节点的目的。
跳跃表支持平均O(logN)、最坏O(N)复杂度的节点查找,还可以通过顺序性操作来批处理节点。
在大部分情况下,跳跃表的效率可以和平衡树相媲美,并且因为跳跃表的实现比平衡树要来得更为简单,所以有不少程序都使用跳跃表来代替平衡树。
Redis使用跳跃表作为有序集合键的底层实现之一,如果一个有序集合包含的元素数量比较多,又或者有序集合中元素的成员(member)是比较长的字符串时,Redis就会使用跳跃表来作为有序集合键的底层实现。
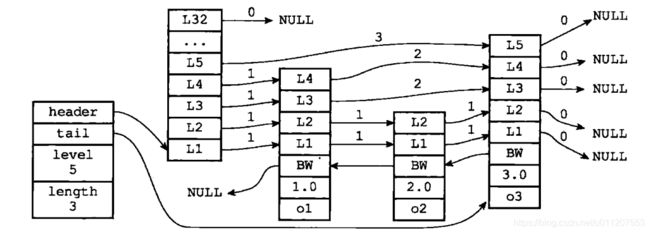
跳跃表操作API
| 函数 | 作用 | 时间复杂度 |
|---|---|---|
| zslCreate | 创建一个新的跳跃表 | O(1) |
| zslFree | 释放给定跳跃表,以及表中包含的所有节点 | O(N),N为表的长度 |
| zsIInsert | 将包含给定成员和分值的新节点添加到跳跃表中 | 平均O(logN),最坏O(N),N为跳跃表长度 |
| zsIDeIete | 删除跳跃表中包含给定成员和分值的节点 | 平均O(logN),最坏O(N),N为跳跃表长度 |
| zslGetRank | 返回包含给定成员和分值的节点在跳跃表中的排位 | 平均O(logN),最坏O(N),N为跳跃表长度 |
| zsIGetEIementByRank | 返回表在给定排位上的节点 | 平均O(logN),最坏O(N),N为跳跃表长度 |
| zslIsInRange | 给定一个分值范围,有至少一个节点的分值在该范围内,返回1,否则返回0 | 通过跳跃表的表头节点和表尾节点,这个检测可以用O(1)复杂度完成 |
| zsIFirstInRange | 给定一个分值范围,返回跳跃表中第一个符合这个范围的节点 | 平均O(logN),最坏O(N),N为跳跃表长度 |
| zs1LastInRange | 给定一个分值范围,返回跳跃表中最后一个符合这个范围的节点 | 平均O(logN),最坏O(N),N为跳跃表长度 |
| zs1De1eteRangeByScore | 给定一个分值范围,删除跳跃表中所有在这个范围之内的节点 | O(N),N为被删除节点数量 |
| zs1De1eteRangeByRank | 给定一个排位范围,删除跳跃表中所有在这个范围之内的节点 | O(N),N为被删除节点数量 |