Dubbo源码解析(十八)Dubbo 序列化、反序列化
文章目录
- Dubbo 序列化、反序列化
-
- 序列化--编解码技术
-
- 介绍
- 目的
- 实际序列技术
-
- Java序列化
- hessian2
- fst
- json
- kyro
- protobuf
- avro
- Dubbo 序列化的实现
-
- 源码结构
- dubbo-serialization-api
- Hession2实现
-
- Hessian2ObjectInput
- Hessian2ObjectOutput
- dubbo-serialization-protobuf-json 实现
-
- GenericProtobufObjectInput
- GenericProtobufObjectOutput
- 性能对比
- 总结
Dubbo 序列化、反序列化
我们都知道在本地调用的时候,是本地JAVA虚拟机读取内存中的对象实例,作为参数,执行方法的调用,所以参数是在本地内存中的。但是在跨进程,甚至跨网络的服务调用中,在分布式系统中,都是通过网络进行交互的。作为二进制流传输到被调用的服务器中。而在我们的对象转换为二进制流称之为序列化,相应的二进制流转换为对象的话就称之为反序列化。
序列化–编解码技术
介绍
In computer science, in the context of data storage, serialization (or serialisation) is the process of translating data structures or object state into a format that can be stored (for example, in a file or memory buffer) or transmitted (for example, across a networkconnection link) and reconstructed later (possibly in a different computer environment).[1] When the resulting series of bits is reread according to the serialization format, it can be used to create a semantically identical clone of the original object.
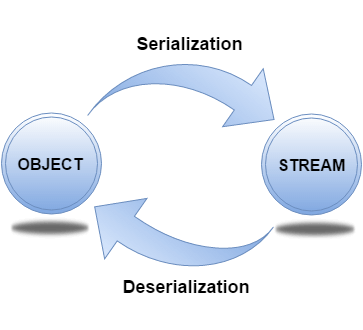
如上图 对象转换为二进制流称之为序列化,相应的二进制流转换为对象的话就称之为反序列化。
目的
-
对象传输
在网络中的两台主机,因为我们不在同一个主机内,当发生交互的时候,没有办法直接将
java对象内存地址暴露出去,只能通过网络进行传输,那么这个时候我们就会需要把这个对象转化为二进制流(TCP/IP限制)的穿过去,并且在接收方需要接收到二进制流并转化为对象。 -
对象持久化
上一个例子我们说的是进行网络间调用的时候,大家都知道内存在断电的情况下会丢失所有数据,我们如果不把对象持久化的话,那么当重启应用,所有的对象都恢复不回来,所以无论是分布式缓存还是数据库都会把数据持久化到磁盘里。这里当然我们如果需要对当前应用的对象进行恢复的话,也要进行持久化。
-
深克隆
我们知道在java中,对象之间的依赖特别复杂,如果想深克隆一个对象的话,势必要把对象所依赖的对象都备一个份,我们就可以通过序列化来保存对象,然后反序列化可以得到多个深克隆的副本。
实际序列技术
Java序列化
java 序列化从jdk1.1就已经提供,他不知道添加额外的类,只需要实现java.io.Serailizable接口并生成一个序列化ID就可以了。java序列化相对于的序列化框架更简单,无需引入任何依赖,但是无法跨语言、并且序列化后的字节码流太大、性能较低,不然也不会有这么多其它的序列化框架。
hessian2
Hessian是一个轻量级的remoting onhttp工具,使用简单的方法提供了RMI的功能。 相比WebService,Hessian更简单、快捷。采用的是二进制RPC协议,因为采用的是二进制协议,所以它很适合于发送二进制数据。
fst
FST fast-serialization 是重新实现的 Java 快速对象序列化的开发包。序列化速度更快(2-10倍)、体积更小,而且兼容 JDK 原生的序列化。要求 JDK 1.7 支持。
json
JSON(JavaScript Object Notation, JS 对象简谱) 是一种轻量级的数据交换格式。它基于 ECMAScript (欧洲计算机协会制定的js规范)的一个子集,采用完全独立于编程语言的文本格式来存储和表示数据。简洁和清晰的层次结构使得 JSON 成为理想的数据交换语言。 易于人阅读和编写,同时也易于机器解析和生成,并有效地提升网络传输效率。
fastjson jackson gson
kyro
Kryo是一个快速高效的Java序列化框架,旨在提供快速、高效和易用的API。无论文件、数据库或网络数据Kryo都可以随时完成序列化。Kryo还可以执行自动深拷贝(克隆)、浅拷贝(克隆)。这是对象到对象的直接拷贝,非对象->字节->对象的拷贝。
protobuf
ProtoBuf 全称 Google Protocol Buffer ,它由Google 开源而来。它将数据结构以.proto文件进行描述,通过代码生成工具可以以生成对应的数据结构的pojo对象和Protobuf相关的方法和属性。
- 结构化数据存储格式(XML、JSON) 等
- 高效的编解码性能
- 语言无关、平台无关、扩展性好
- 官方支持Java/C++/python/go/dart/c# 多种语言
avro
Apache Avro™ is a data serialization system.由Hadoop创始人Doug Cutting创建的一种语言无关的数据序列化和RPC框架,用于解决Hadoop中Writable序列化机制的缺点:缺少跨语言特性,与Java绑的太紧,数据格式很难被JVM外的语言进行处理。
那在已经有真么多序列化框架的情况下,为什么还有搞一套框架呢?
Doug Cutting撰文解释道:Hadoop现存的RPC系统遇到一些问题,如性能瓶颈(当前采用IPC系统,它使用Java自带的DataOutputStream和DataInputStream);需要服务器端和客户端必须运行相同版本的Hadoop;只能使用Java开发等。但现存的这些序列化系统自身也有毛病,以Protocol Buffers为例,它需要用户先定义数据结构,然后根据这个数据结构生成代码,再组装数据。如果需要操作多个数据源的数据集,那么需要定义多套数据结构并重复执行多次上面的流程,这样就不能对任意数据集做统一处理。其次,对于Hadoop中Hive和Pig这样的脚本系统来说,使用代码生成是不合理的。并且Protocol Buffers在序列化时考虑到数据定义与数据可能不完全匹配,在数据中添加注解,这会让数据变得庞大并拖慢处理速度。其它序列化系统有如Protocol Buffers类似的问题。所以为了Hadoop的前途考虑,Doug Cutting主导开发一套全新的序列化系统,这就是Avro,于09年加入Hadoop项目族中。
作者:Albert陈凯
链接:https://www.jianshu.com/p/a5c0cbfbf608
来源:简书
简书著作权归作者所有,任何形式的转载都请联系作者获得授权并注明出处。
avro 提供了以下功能
- Rich data structures.
- A compact, fast, binary data format.
- A container file, to store persistent data.
- Remote procedure call (RPC).
- Simple integration with dynamic languages. Code generation is not required to read or write data files nor to use or implement RPC protocols. Code generation as an optional optimization, only worth implementing for statically typed languages.
Dubbo 序列化的实现
源码结构
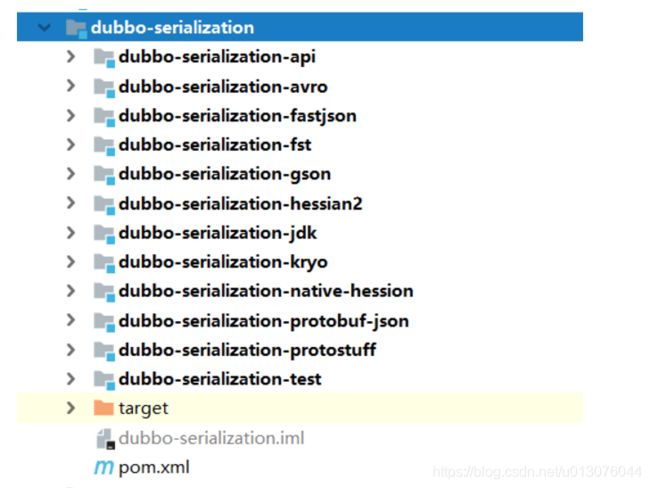
可以看到dubbo的序列化实现方式多种多样,基本上把上面列举到的序列化技术都实现了。这也源自于社区的发展和贡献啊。
dubbo-serialization-api
dubbo 规定了一下的api约束与规范,需要自定义的只需要实现对应的Input/Output接口即可。
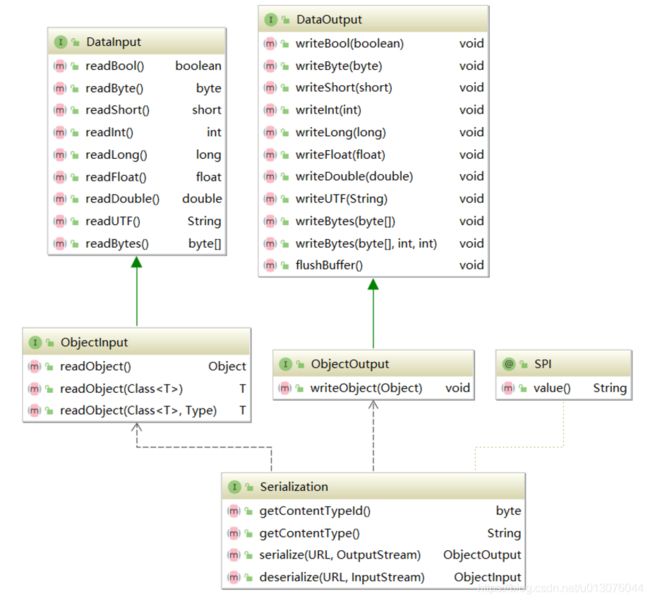
- DataInput 基本数据类型的反序列化
- ObjectInput 对象类型的反序列化
- DataOutput 基本数据类型的序列化
- ObjectOutput 对象类型的序列化
- Serialization 序列化策略接口,指定序列化程序。默认 hession2
Hession2实现
Hessian2ObjectInput
public class Hessian2ObjectInput implements ObjectInput {
private final Hessian2Input mH2i;
public Hessian2ObjectInput(InputStream is) {
mH2i = new Hessian2Input(is);
mH2i.setSerializerFactory(Hessian2SerializerFactory.SERIALIZER_FACTORY);
}
@Override
public boolean readBool() throws IOException {
return mH2i.readBoolean();
}
// ... 省略其它read实现
}
Hessian2ObjectOutput
public class Hessian2ObjectOutput implements ObjectOutput {
private final Hessian2Output mH2o;
public Hessian2ObjectOutput(OutputStream os) {
mH2o = new Hessian2Output(os);
mH2o.setSerializerFactory(Hessian2SerializerFactory.SERIALIZER_FACTORY);
}
@Override
public void writeBool(boolean v) throws IOException {
mH2o.writeBoolean(v);
}
// ... 省略其它write实现
}
可以看到在实现方式上,是通过委托HessionInput和HessionOutput来实现的。
dubbo-serialization-protobuf-json 实现
GenericProtobufObjectInput
public class GenericProtobufObjectInput implements ObjectInput {
private final BufferedReader reader;
public GenericProtobufObjectInput(InputStream in) {
this.reader = new BufferedReader(new InputStreamReader(in));
}
@Override
public boolean readBool() throws IOException {
return read(boolean.class);
}
// ... 省略其它read实现
private String readLine() throws IOException {
String line = reader.readLine();
if (line == null || line.trim().length() == 0) {
throw new EOFException();
}
return line;
}
private <T> T read(Class<T> cls) throws IOException {
if (!ProtobufUtils.isSupported(cls)) {
throw new IllegalArgumentException("This serialization only support google protobuf entity, the class is :" + cls.getName());
}
String json = readLine();
return ProtobufUtils.deserialize(json, cls);
}
}
GenericProtobufObjectOutput
public class GenericProtobufObjectOutput implements ObjectOutput {
private final PrintWriter writer;
public GenericProtobufObjectOutput(OutputStream out) {
this.writer = new PrintWriter(new OutputStreamWriter(out));
}
@Override
public void writeBool(boolean v) throws IOException {
writeObject(v);
}
@Override
public void writeObject(Object obj) throws IOException {
if (obj == null) {
throw new IllegalArgumentException("This serialization only support google protobuf object, the object is : null");
}
if (!ProtobufUtils.isSupported(obj.getClass())) {
throw new IllegalArgumentException("This serialization only support google protobuf object, the object class is: " + obj.getClass().getName());
}
writer.write(ProtobufUtils.serialize(obj));
writer.println();
writer.flush();
}
@Override
public void flushBuffer() {
writer.flush();
}
}
可以看到在实现方式上,是通过委托BufferedReader和PrintWriter来实现的。
性能对比
http://dangdangdotcom.github.io/dubbox/serialization.html
总结
- 序列化技术和反序列化技术可应用于网络传输、持久化等场景
- 在dubbo中,只需要实现
ObjectInput和ObjectOutput,并且创建一个Serialization的实现, 即可个性化定制实现Dubbo序列化