spark-hdfs-自定义OutputFormat
spark-hdfs-自定义OutputFormat
- 一、SRC
- 二、usage
-
- 1. 继承FileOutputFormat
一、SRC
主要就是2个实现类TextOutputFormat和SequenceOutputFormat
spark的rdd的saveAsTextFile()方法底层默认调的其实也是TextOutputFormat,这有2个问题:
1是无法指定文件名(这个其实不是问题,因为逻辑上只需要指定目录名即可,分布式的情况下一个文件肯定要分成多个部分,给每个部分指定名称无意义)
2是无法满足一些个性化需求
所以需要自定义
OutputFormat的作用就是把内存中一个个的kv变成文件
需要注意的是,OutputFormat是要在各个分区执行的,所以保存的文件名要区分开来,否则会报文件已存在的错。所以生成完再合并还是免不了的。
二、usage
1. 继承FileOutputFormat,这里的T1和T2是kv的泛型
2. 重写getRecordWriter方法,返回RecordWriter,RecordWriter类里的write方法用来设置如何写kv

{1} RecordWriter继承 RecordWriter,重写write和close方法。write的作用就是接一对kv,写到文件。
write方法的入参是kv,现在已经拿到kv了,可输出流怎么获取呢?这里的输出流需要自己添加方法创建,因为本来就是要自定义。此时需要做2件事:
- 是创建FSDataOutputStream流,在流里可以设置输出路径,可以精确到文件
- 是获取配置信息,除非输出流写绝对路径,否则还是要获取父目录。
- 这一步需要自己手动在getRecordWrite方法中把job对象传给RecordWriter对象

- 这一步需要自己手动在getRecordWrite方法中把job对象传给RecordWriter对象
- key默认是偏移量,一般用不到,历史遗留问题,vaue默认不带回车,要自己加
三、example
上面仅仅是基本的例子,实际使用时有很多坑。现在记录一个实际例子:
1. 需求+源码分析:把df保存为gz格式并且编码要改为GBK
{1} rdd的df.rdd.saveAsTextFile("",classOf[GzipCodec])默认用的是TextOutputFormat,不能设置编码格式。TextOutputFormat的源码中:
- 编码格式是写死的

- write方法加了synchronized,不会并发写。而且只要kv有1个为null或NullWritable,就不会加分隔符,也不会写空值。

- write方法底层调用了writeObject(Object o)方法,里面比较奇怪的是如果是Text类型,会使用系统默认的编码格式,如果是别的类型,toString()后使用utf-8

- OutputFormat的文件名是怎么生成的?
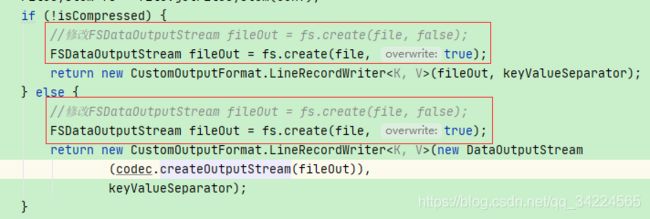
https://blog.csdn.net/qq_34224565/article/details/106305247 - 根据上步第4步,将文件名修改为没有taskId的,这样相同表和相同日期时,生成的文件会重名,所以需要把输出流改为overweight
2. 一开始尝试用自定义的OutputFormat继承TextOutputFormat,但发现此处的继承无法实现,子类调用父类的getRecordWriter方法,调用的始终是父类的静态内部类。又因为网上的blog都是直接继承的FileOutputFormat,于是就选了这个方案。
{1} traps
[1] hadoop的java API同时提供了2套API(原因未知),自然而然,新的肯定是好一些,于是选了新的。
注意的是:
(1) 2套API的类名完全一致,一定要注意区分包名。新的是org.apache.hadoop.mapreduce.lib.output,老的是org.apache.hadoop.mapred。使用老的方法saveAsHadoopFile时,对应的参数也全都是老包中的,否则会报编译错,此处巨坑!!!
包括TextOutputFormat和FileOutputFormat,新旧2套类名一样,包名不同。新的FileOutputFormat是抽象类已经实现了FileOutputFormat接口的所有方法,而旧的继承FileOutputFormat后还要继续实现FileOutputFormat的方法
![]()
(2) spark的rdd对应的方法名不同,使用新API的只有1个2个重载的saveAsNewAPIHadoopFile和1个saveAsNewAPIHadoopDataset方法。因为相比旧的saveAsHadoopFile系列的方法,关于压缩的配置放到了hadoopConfiguration的配置中,只需要在方法中指定OutputFormat类。
[2] rdd的泛型要和saveAs方法中的一致,且都要为MR中的类型,比如String要转Text
![]()
(1) String转Text,直接用new Text(String str)即可。
(2) 如果想设空,直接写null或者用NullWritable.get(),源码中NullWritable的构造器是私有的,但new NullWritable() 却不报编译错,不知为啥。
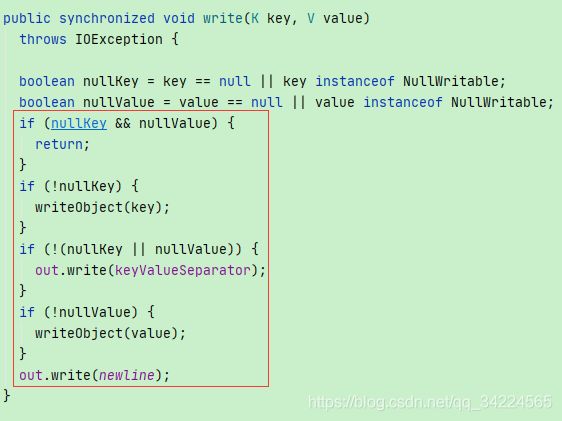
源码中,kv有一方为null或NullWritable就不输出分隔符,只输出不为空的。
FileOutputFormat中如果判断key或v为null或者为NullWritable类型,就不会输出k v和分隔符。所以pairRDD完全可以把k或者v设为null或NullWritable来实现用单valueRDD调双valueRDD的方法。推荐设为NullWritable
[3] java中,如果一个类声明时没设置范围,那么获取其class对象时不能设泛型,否则会报关于type的错
如下2处,声明和引用时要一致。
![]()
![]()
{2} 编写CustomOutputFormat
一开始想的是继承FileOutputFormat,但发现FileOutputFormat中的非抽象方法过多,比如设置压缩,要挨个设置4个参数
发现最简单的方法就是把TextOutputFormat类中的代码直接复制到到自定义的CustomOutputFormat类,然后把TextOutputFormat中写死的编码格式和写入Text类型时没设置编码的坑补上就能完美实现功能。
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.compress.CompressionCodec;
import org.apache.hadoop.io.compress.GzipCodec;
import org.apache.hadoop.mapreduce.RecordWriter;
import org.apache.hadoop.mapreduce.TaskAttemptContext;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.ReflectionUtils;
import java.io.DataOutputStream;
import java.io.IOException;
import java.io.UnsupportedEncodingException;
public class CustomOutputFormat<K, V> extends FileOutputFormat<K, V> {
public static String SEPERATOR = "mapreduce.output.textoutputformat.separator";
protected static class LineRecordWriter<K, V>
extends RecordWriter<K, V> {
// private static final String utf8 = "UTF-8";//此处修改
private static final String encod = "GBK";
private static final byte[] newline;
static {
try {
newline = "\n".getBytes(encod);
} catch (UnsupportedEncodingException uee) {
throw new IllegalArgumentException("can't find " + encod + " encoding");
}
}
protected DataOutputStream out;
private final byte[] keyValueSeparator;
public LineRecordWriter(DataOutputStream out, String keyValueSeparator) {
this.out = out;
try {
this.keyValueSeparator = keyValueSeparator.getBytes(encod);
} catch (UnsupportedEncodingException uee) {
throw new IllegalArgumentException("can't find " + encod + " encoding");
}
}
public LineRecordWriter(DataOutputStream out) {
this(out, "\t");
}
/**
* Write the object to the byte stream, handling Text as a special
* case.
*
* @param o the object to print
* @throws IOException if the write throws, we pass it on
*/
private void writeObject(Object o) throws IOException {
//此处修改
// if (o instanceof Text) {
// Text to = (Text) o;
// out.write(to.getBytes(), 0, to.getLength());
// } else {
out.write(o.toString().getBytes(encod));
}
public synchronized void write(K key, V value)
throws IOException {
boolean nullKey = key == null || key instanceof NullWritable;
boolean nullValue = value == null || value instanceof NullWritable;
if (nullKey && nullValue) {
return;
}
if (!nullKey) {
writeObject(key);
}
if (!(nullKey || nullValue)) {
out.write(keyValueSeparator);
}
if (!nullValue) {
writeObject(value);
}
out.write(newline);
}
public synchronized void close(TaskAttemptContext context) throws IOException {
out.close();
}
}
public RecordWriter<K, V>
getRecordWriter(TaskAttemptContext job
) throws IOException, InterruptedException {
Configuration conf = job.getConfiguration();
boolean isCompressed = getCompressOutput(job);
String keyValueSeparator = conf.get(SEPERATOR, "\t");
CompressionCodec codec = null;
String extension = "";
if (isCompressed) {
Class<? extends CompressionCodec> codecClass =
getOutputCompressorClass(job, GzipCodec.class);
codec = (CompressionCodec) ReflectionUtils.newInstance(codecClass, conf);
extension = codec.getDefaultExtension();
}
Path file = getDefaultWorkFile(job, extension);
FileSystem fs = file.getFileSystem(conf);
if (!isCompressed) {
FSDataOutputStream fileOut = fs.create(file, false);
return new CustomOutputFormat.LineRecordWriter<K, V>(fileOut, keyValueSeparator);
} else {
FSDataOutputStream fileOut = fs.create(file, false);
return new CustomOutputFormat.LineRecordWriter<K, V>(new DataOutputStream
(codec.createOutputStream(fileOut)),
keyValueSeparator);
}
}
}