Spark 分区(Partition)的认识、理解和应用
转载地址:https://blog.csdn.net/zhangzeyuan56/article/details/80935034
一、什么是分区以及为什么要分区?
Spark RDD 是一种分布式的数据集,由于数据量很大,因此要它被切分并存储在各个结点的分区当中。从而当我们对RDD进行操作时,实际上是对每个分区中的数据并行操作。

图一:数据如何被分区并存储到各个结点

图二:RDD、Partition以及task的关系
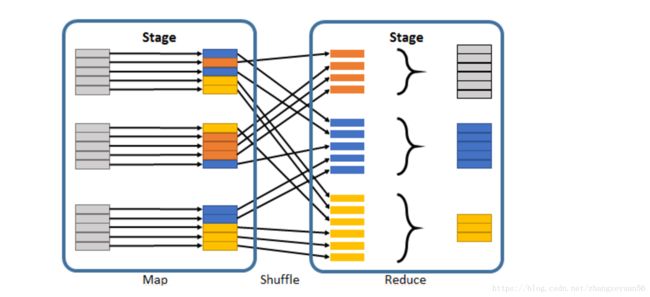
图三:分区数在shuffle操作会变化
二、分区的3种方式
1、HashPartitioner
scala> val counts = sc.parallelize(List((1,'a'),(1,'aa'),(2,'b'),(2,'bb'),(3,'c')), 3)
.partitionBy(new HashPartitioner(3))
HashPartitioner确定分区的方式:partition = key.hashCode () % numPartitions
2、RangePartitioner
scala> val counts = sc.parallelize(List((1,'a'),(1,'aa'),(2,'b'),(2,'bb'),(3,'c')), 3)
.partitionBy(new RangePartitioner(3,counts))
RangePartitioner会对key值进行排序,然后将key值被划分成3份key值集合。
3、CustomPartitioner
CustomPartitioner可以根据自己具体的应用需求,自定义分区。
class CustomPartitioner(numParts: Int) extends Partitioner {
override def numPartitions: Int = numParts
override def getPartition(key: Any): Int =
{
if(key==1)){
0
} else if (key==2){
1} else{
2 }
}
}
scala> val counts = sc.parallelize(List((1,'a'),(1,'aa'),(2,'b'),(2,'bb'),(3,'c')), 3).partitionBy(new CustomPartitioner(3))
三、理解从HDFS读入文件默认是怎样分区的
Spark从HDFS读入文件的分区数默认等于HDFS文件的块数(blocks),HDFS中的block是分布式存储的最小单元。如果我们上传一个30GB的非压缩的文件到HDFS,HDFS默认的块容量大小128MB,因此该文件在HDFS上会被分为235块(30GB/128MB);Spark读取SparkContext.textFile()读取该文件,默认分区数等于块数即235。
四、如何设置合理的分区数
1、分区数越多越好吗?
不是的,分区数太多意味着任务数太多,每次调度任务也是很耗时的,所以分区数太多会导致总体耗时增多。
2、分区数太少会有什么影响?
分区数太少的话,会导致一些结点没有分配到任务;另一方面,分区数少则每个分区要处理的数据量就会增大,从而对每个结点的内存要求就会提高;还有分区数不合理,会导致数据倾斜问题。
3、合理的分区数是多少?如何设置?
总核数=executor-cores * num-executor
一般合理的分区数设置为总核数的2~3倍