小白学习三维检测和三维语义理解(3D-understanding)持续更新中。。
Uderstanding
- Understanding
-
- 三维 understanding
-
- 一、Learning only from point cloud
-
- (1)PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation(cvpr-2017)
-
- 简介:
- 贡献:
- 算法(贡献点)核心思路:
- 算法(贡献)具体实现流程:
- 实验对比&效果:
- 缺点:
- (2)PointNet++: Deep Hierarchical Feature Learning on Point Sets in a Metric Space(NIPS-2017)
-
- 简介:
- 贡献:
- 算法(贡献点)核心思路:
- 算法(贡献)具体实现流程:
- 实验对比&效果:
- 缺点:
- (3)2020综述 Deep Learning for 3D Point Clouds: A Survey
-
- 简介:
- 贡献:
- 3D Shape Classification:
- 3D Object detection and tracking:
-
- 一、3D Object Detection
- **(4)Other Methods**
- **2.Single Shot Methods**
- **二、3D Object Tracking**
- **三、3D scene flow estimation**
- Summary
- 3D Point Cloud Segmentation:
-
- **2) Instance Segmentation**
- 2D-3D joint learning
-
- 3D-SIS: 3D Semantic Instance Segmentation of RGB-D Scans(CVPR-2019)
-
- 简介:
- 贡献:
- 算法(贡献点)核心思路:
- 算法(贡献)具体实现流程:
- 实验对比&效果:
- 缺点:
Understanding
三维 understanding
一、Learning only from point cloud
(1)PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation(cvpr-2017)
homepage.paper. 作者中文讲解视频. code.
简介:
之前在三维检测上的工作:
(1)将不规则的点云数据转换为规则的体素数据,然后在体素数据上进行CNN,大量的耗费计算资源。
(2)人工在三维数据中进行特征的提取和计算。(依赖人工的水平,鲁棒性低)
(3)将三维数据投影在二维的空间平面中,然后利用二维的空间检测方法来完成检测,(会损失部分重要的三维信息)
本文开创性的提出了一种只应用最原始的三维点云数据进行深度学习的方法(神经网络),实现了三维检测的end-to-end的检测,更多的挖掘数据中的信息。
本文可以粗略的完成对三维物体的检测、分类和分割。
贡献:
• We design a novel deep net architecture suitable for consuming unordered point sets in 3D;
• We show how such a net can be trained to perform 3D shape classification, shape part segmentation and scene semantic parsing tasks;
• We provide thorough empirical and theoretical analysis on the stability and efficiency of our method;
• We illustrate the 3D features computed by the selected neurons in the net and develop intuitive explanations for its performance.
• 对点的丢失具有较高的鲁棒性
算法(贡献点)核心思路:
1.特征提取:将三维的点映射到更高维的空间(MLP),然后再通过对称性的操作(max pooling)(因为是高维空间所以避免了信息的丢失,同时完成了置换不变性),然后再通过一个函数γ(MLP)来得到output scores。
2.该网络对于视角的变换不变性的解决:(基于数据本身的变换函数模块)
将输入的n3的点,经过T-Net网络,生产变换参数,再由变换函数得到另一组变换后的n3的点云,最终解决不同视角的问题。?
整体相当于优化点,优化点的特征,便于后面的网络进行处理。
算法(贡献)具体实现流程:

1.输入n3的点,经过变换网络生产新的,优化过的n3的点。
2.通过mlp将每个点,映射到更高维的空间,得到相关的特征向量。
3.再通过变换网络,对相关特征进行更归一化的特征,便于后续的网络学习。
4.继续做MLP,将64维的特征映射到更高维的1024维的特征。
5.再通过max-pooling进行对称性操作,得到全局特征。
6.再通过级联的全连接网络得到,output scores,进行K哥class的分类。
7.分割问题:相当于对每个点的分类,将局部特征和全局特征进行全局学习(或者说单个特征再全局特征中的检索,看自己属于哪个class),分别得到每个点的局部类别,进而将同属于同一类别的点提取出,便实现了分割。
8.再通过MLP,生成n*m(m个类别)
实验对比&效果:

本文虽然是最早的对3D点云进行处理的深度学习网络,但是结果已经和当时较为成熟的在体素上进行RCNN的网络相当。
缺点:
对局部特征学习不够
(2)PointNet++: Deep Hierarchical Feature Learning on Point Sets in a Metric Space(NIPS-2017)
homepage.paper. 作者中文讲解视频. code.
简介:
Pointnet++是作者自己对Pointnet的升级版, 该网络设计了多级点云特征提取的方案,解决了Pointnet对局部特征提取不足的缺点, 使得该网络的学习效果更好;同时该网络在同一级上结合了不同尺度上的学习特征,使得了该网络具有较强的鲁棒性(更好的解决了点丢失时对分类结果的影响)。
贡献:
1.实现对在全局中对局部点云信息进行单独处理,再经过对多个不同的局部点云的提取,再形式上实现了类似于CNN的形式,使得该网络更好的识别物体和分割物体。
2.能够实现hierarchical feature learning(多级点云特征学习)、解决translation invariant 和permutation invariant。(解决了平移不变性和置换不变性)
3.可以在同一级上金和不同尺度上的学习特征,使得该网络在面对点的数据部分丢失时由更好的鲁棒性。
算法(贡献点)核心思路:
对每个局部小区域中的点进行pointnet,然后再扩大区域再进行pointnet,实现多级点云特征的学习,使得学习效果更好。
算法(贡献)具体实现流程:


通过在不同尺度,不同范围内进行不断的PointNet++,使得对点云数据的学习在形式上更像传统的CNN一样,使得检测学习的精度更好,效果更好。
实验对比&效果:
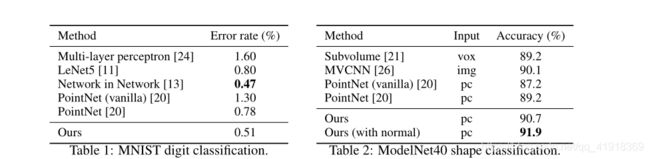
缺点:
这是初代的对点云原始数据上进行深度学习的方法,学习的效果还需要大幅提升。
(3)2020综述 Deep Learning for 3D Point Clouds: A Survey
homepage.paper. 作者持续更新
DOI: 10.1109/TPAMI.2020.3005434
简介:

本文是汇总了现有用深度学习来处理点云数据的所有方法。其中包含三大类别:
(1)3D Shape Classification
(2)3D Object Detection and Tracking
(3)3D Ponit Cloud Segementation
贡献:
- To the best of our knowledge, this is the first survey paper to comprehensively cover deep learning methods for several important point cloud under- standing tasks, including 3D shape classification, 3D object detection and tracking, and 3D point cloud segmentation.
- As opposed to existing reviews [19], [20], we specifically focus on deep learning methods for 3D point clouds rather than all types of 3D data.
- This paper covers the most recent and advanced progresses of deep learning on point clouds. Therefore, it provides the readers with the state-of-the-art methods.
- Comprehensive comparisons of existing methods on several publicly available datasets are provided (e.g., in Tables 2, 3, 4, 5), with brief summaries and insightful discussions being presented.
3D Shape Classification:
现有一共三种方法:

- Multi-view based methods project an unstructured point cloud into 2D images,先将3D点云投影到多个二维视图中,然后在二维的图像中进行学习。
- volumetric-based methods convert a point cloud into a 3D volumetric representation.然后再三维空间中进行三维的CNN。
- Point-based Networks directly work on raw point clouds。
(1) Pointwise MLP Methods
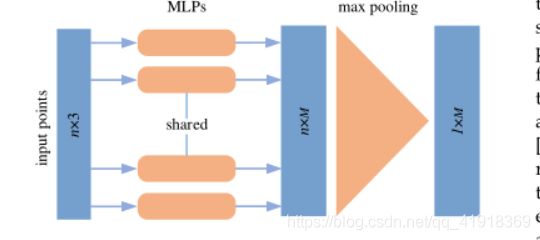
(2)Convolution-based Methods

(3)Graph-based Methods
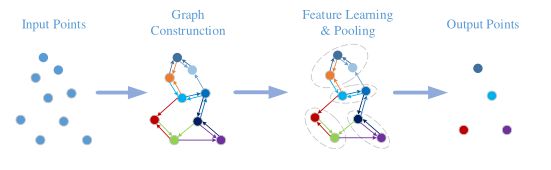
(4) Hierarchical Data Structure-based Methods
(5)Other Methods
Summary:
- Pointwise MLP networks are usually served as the basic building block for other types of networks to learn pointwise features.(逐点MLP通常是其他网路的基础)
- As a standard deep learning architecture, convolution-based networks can achieve superior
performance on irregular 3D point clouds. More attention should be paid to both discrete and continuous convolution networks for irregular data.(基于卷积的网络) - Due to its inherent strong capability to handle irregular data, graph-based networks have attracted increasingly more attention in recent years. However, it is still challenging to extend graph-based networks in the spectral domain to various graph structures. (图神经网络)
3D Object detection and tracking:
一、3D Object Detection
3D object detection methods can be divided into two categories: region proposal based and single shot methods. (3维检测也是分为两大类,基于 region proposal 和single shot的方法)
Several milestone methods are presented

1.Region Proposal-based Methods
These methods first propose several possible regions (also called proposals) containing objects, and then extract region wise features to determine the category label of each proposal. (先根据特征向量生成proposals,然后再在每个region中根据其特征向量对其设别其类别。)
According to their object proposal generation approach, these methods can further be divided into three categories: multi-view based, segmentation based and frustum-based methods.(根据proposal的生成方式不同,我们又将其分为基于视图的方法、基于分割的方法和基于视锥的方法)

(1)Multi-view based Methods
该方法根据不同的视图(例如:LiDAR front view, Bird’s Eye View (BEV), and image等)来生成proposal,该方法的计算成本通常比较高。
该方法的最经典算法是2017年清华的MV3D,该方法首先在BEV视图中进行高精度的2DCNN,生成相应的ROI,然后将该ROI投影到其他视图中,再结合不同视图中的proposla生成3D bounding box,虽然该方法的精度非常高了,但是其运算速度特别的慢,该领域内接下来的工作便是从两个方向改进该方法(多是提高检测速度。)
First, several methods have been proposed to efficiently fuse the information of different modalities.Second, different methods have been investigated to extract robust representations of the input data.
典型算法及文章:
(1)MV3D(Multi-view 3D object detection network for autonomous driving,)、
(2)Joint 3D proposal generation and object detection from view aggregation、
(3)Deep continuous fusion for multi-sensor 3D object detection、
Multi-task multi-sensor fusion for 3D object detection、
(4)PIXOR: Real-time 3D object detection from point clouds、
(5)Fast and furious: Real time end-to-end 3D detection, tracking and motion forecasting with a single convolutional net、
(6)RT3D: Real-time 3D vehicle detection in lidar point cloud for autonomous driving、
(2)Segmentation-based Methods
These methods first leverage existing semantic segmentation techniques to remove most background points, and then generate a large amount of high quality proposals on foreground points to save computation,(先筛选前景点和背景点,然后删除背景点,在前景点中生成proposal)
these methods achieve higher object recall rates and are more suitable for complicated scenes with highly occluded and crowded objects。
典型网络:
(1)PonitRCNN。 Specifically, they directly segmented 3D point clouds to obtain foreground points and then fused semantic features and local spatial
features to produce high-quality 3D boxes.
(2)PonitRGCN在pointRCNN中的RPN之后,利用GCN(图卷积神经网络)来进行三维物体检测.
(3)STD: Sparse-to-dense 3D object detector for point cloud中用一种球形anchor来关联每个点,然后使用每个点的语义评分来删除多余的锚点,使得该网络有更高的召回率。
(3)Frustum-based Methods
These methods first leverage existing 2D object detectors to generate 2D candidate regions of objects and then extract a 3D frustum proposal for each 2D candidate region (现在2维图像中进行检测,然后根据二维图像检测的proposal和相机的外参,生成三维的proposal)(该方法依赖二维的检测精度,并且不能很好的解决物体遮挡问题)
经典网络:
- F-PointNet是该方法的开创性工作。(It generates a frustum proposal for each 2D region and applies PointNet (or PointNet++ ) to learn point cloud features of each 3D frustum for amodal 3D box estimation.)
- Point-SENet:which were further used to adaptively highlight useful features and suppress informative-less features. (能够自适应的突出有用的特征,并抑制信息量少的特征)
- PointSIFT:强化了捕获点云的方向信息,从而获得了强大的形状缩放鲁棒性,检测性能上有了进一步提高。
- PointFusion:
- RoarNet:
- Frustum convNet:
- Patch refinement - localized 3D object detection:
(4)Other Methods
- 3D IoU loss
integrated the IoU of two 3D rotated bounding boxes into several state-of-the-art detectors to achieve consistent performance improvement - Fast Point R-CNN :
proposed a two-stage network architecture to use both point cloud and voxel representations,(用更快的速度同时检测精度达到了PointRCNN,) - PV-RCNN :
kitti检测汽车榜第一, - VoteNet:
2.Single Shot Methods
These methods directly predict class probabilities and regress 3D bounding boxes of objects using a single-stage network. They do not need region proposal generation and post-processing. As a result, they can run at a high speed.(运行速度快)
According to the type of input data, single shot methods can be divided into three categories: BEV-based, discretization based and point-based methods.
(1)BEV-based Methods.
These methods mainly take BEV representation as their input.
(2)Discretization-based Methods.
These methods convert a point cloud into a regular discrete representation, and then apply CNN to predict both categories and 3D boxes of objects.
(3)Point-based Methods:
These methods directly take raw point clouds as their inputs.

二、3D Object Tracking
Given the locations of an object in the first frame, the task of object tracking is to estimate its state in subsequent frames . Since 3D object tracking can use the rich geometric information in point clouds, it is expected to overcome several drawbacks faced by image-based tracking, including occlusion, illumination and scale variation.
(同过检测到第一帧的状态来预测物体接下来的状态,由于三维空间有丰富的几何信息,可能解决二维物体跟踪的一些缺陷)
三、3D scene flow estimation
所谓场景流,就是光流的三维版本,表述了图像/点云中每个点在前后两帧的变化情况。目前对场景流的研究还局限在实验室阶段,由于缺乏实际数据(打标成本太高)以及客观的评价指标,离工程应用还有不小的距离。此外,巨大的计算量也是一个瓶颈。
二维的光流估计是视频理解的主要方式之一,
光流:具体是指,视频图像的一帧中的代表同一对象(物体)像素点移动到下一帧的移动量,使用二维向量表示。光流是一种描述像素随时间在图像之间运动的方法。
二维中,深度学习光流估计算法将以FlowNet/FlowNet2.0为例介绍。
三维场流估计有一些介绍文章 https://zhuanlan.zhihu.com/p/85663856
现阶段可以参考的文章:
(1)FlowNet3D
(2)FlowNet3D++
(3)HPLFlowNet
(4)PointRNN
(5)MeteorNet
(6)Just go with the flow
Summary
(1)基于proposal的方法现阶段更常用,且效果更好。
(2)3D object detector有两个缺点:对远处的物体识别能力较差, 和并没有充分的运用图像中的纹理信息。
(3)多任务联合学习是未来发展的一个方向。
(4) 3D object tracking and scene flow estimation are emerging research topics
3D Point Cloud Segmentation:
According to the segmentation granularity, 3D point cloud segmentation methods can be classified into three categories: semantic segmentation (scene level), instance segmentation (object level) and part segmentation (part level).
1) 3D Semantic Segmentation
语义分割是将同一类物体分割出来。
there are four paradigms for semantic segmentation: projection-based, discretization-based, point-based, and hybrid methods.(四种:基于投影,基于离散化,基于点的和混合式)
基于投影和离散化的方法的第一步都是将不规则的点云数据转化为规则的表达方式,而基于点的方法则是直接在原始的点云上进行处理的。
- Projection-based Methods
These methods usually project a 3D point cloud into 2D images, including multi-view and spherical images.
(1) Multi-view Representation
该方法一般在原始的三维点云的基础上,选择几个虚拟的照相机摄影点,然后将三维点云分别投影到多个二维平面中,然后在二维平面中进行学习,然后再融合不同视图的重投影分数,得到每个点的最终语义标签。
Overall, the performance of multi-view segmen- tation methods is sensitive to viewpoint selection and occlusions. Besides, these methods have not fully exploited the underlying geometric and structural information, as the projection step inevitably introduces information loss.
(2)Spherical Representation
暂未读懂。 - Discretization-based Methods
These methods usually convert a point cloud into a dense/sparse discrete representation, such as volumetric and sparse permutohedral lattices.
(1)Dense Discretization Representation
Early methods usually voxelized the point clouds as dense grids and then leverage the standard 3D convolutions. 后来融入了全卷积等方法,使得效果明显提高。
该方法由于将点云转化为体素后,可以使用标准的三维卷积,所以检测精度上较为理想,但体素化的步骤,从原理上必然带来了部分几何信息的丢失。通常,搞分辨率会带来巨大的计算量和使用巨大的存储空间,而较小的分辨率,又会导致部分细节的丢失。
(2)Sparse Discretization Representation
稀疏离散化表示,暂未看懂,大致意思式再上述体素的表示基础上进行稀疏化,从而缩减了计算量和存储空间。 - Hybrid Methods
将二维图像和三维数据进行联合学习。 - Point-based Methods
Point-based networks directly work on irregular point clouds. However, point clouds are orderless and unstructured, making it infeasible to directly apply standard CNNs. To this end, the pioneering work PointNet is proposed to learn per-point features using shared MLPs and global features using symmetrical pooling functions. Based on PointNet, a series of point-based networks have been proposed recently . Overall, these methods can be roughly divided into pointwise MLP methods, point convolution methods, RNN- based methods, and graph-based methods.
(1)Pointwise MLP Methods
再PointNet中首先提出的应用MLP来提取信息, 再次基础上扩展的方法。
(2)Point Convolution Methods.
这些方法倾向于为点云提出有效的卷积运算。
(3)RNN-based Methods
为了从点云中捕获固有的上下文特征,应用递归神经网络(RNN)
(4)Graph-based Methods
应用图神经网络结构
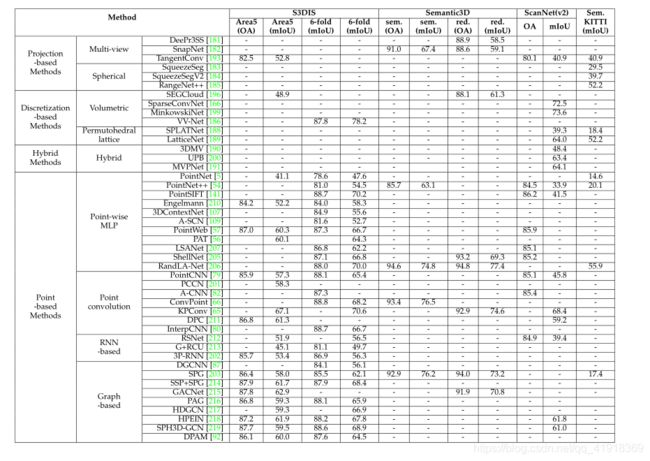
2) Instance Segmentation
在将物体的类别分出来的基础上,还要具体的知道他式输入人A还是人B或是人C

(1)Proposal-based Methods
These methods convert the instance segmentation problem into two sub-tasks: 3D object detection and instance mask prediction.
(2)Proposal-free Methods
they usually consider instance segmentation as a subsequent clustering step after semantic segmentation.
开创性工作:SGPN
2D-3D joint learning
3D-SIS: 3D Semantic Instance Segmentation of RGB-D Scans(CVPR-2019)
homepage.paper. 视频.
简介:
This paper introduces a new neural network structure (3D-SIS). The network proposes 2D-3D joint learning for the first time. It also learns from geometry and RGB to improve the effect of instance segmentation; at the same time, the network is fully convolutional end-to-end Network, so it can run efficiently in a large three-dimensional environment.
input:(1)3D scan geometry features(2)2D RGB input features
output:(1)3D object bounding boxes (2)class labels(3)instance masks
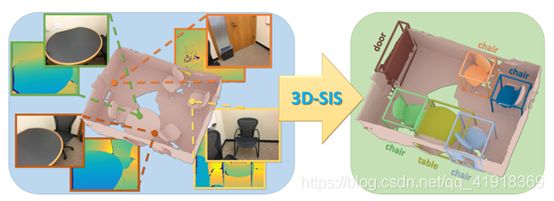
贡献:
This paper introduce 3D-SIS, a new approach for 3D semantic instance segmentation of RGB-D scans, which is trained in an end-to-end fashion to detect object instances and jointly learn features from RGB and geometry data.
算法(贡献点)核心思路:
The core idea of the method is to jointly learn features from RGB and geometry data using multi-view RGB-D input recorded with commodity RGB-D sensors, thus enabling accurate instance predictions.
算法(贡献)具体实现流程:
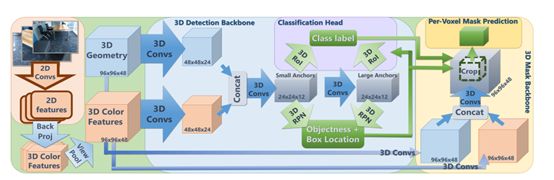
一、网络输入数据预处理:
(1)通过bundle fusion获得该空间的几何信息(用体素来表示,TSDF)
(2)将尽可能覆盖该环境内的所有2为图像取出,并通过二维卷积获得其二维特征,再将其反射投影到该室内环境的三维体素中,每个体素中带有的颜色特征。
二、通过3D Detection Backbone 进行三维物体检测
(1)分别对3D Geomentry 和3D Color Features 进行三维卷积,然后再将其三维卷积得到的特征进行融合。
(2)对(1)中的融合结果通过anchor进行3DRPN生成三维物体的Box Location
(3)结合(2)中具体的三维物体的box和box中具体的三维特征,进行3DROI分别得到每个3D box中每个3维物体的类别,实现检测分类功能。
三、通过3D Mask Backbone 给检测出来的每个三维物体打上mask。
实验对比&效果:


缺点:
(1)输入复杂,有三维和二维两种形式
(2)大量使用三维卷积,训练时间和检测时间长,不一定能够完成实时任务
(3)网络结构不够紧凑,分别对两种输入进行了两种3D CNN,部分结构理论上可能可以共享。