CDH5.16.1安装Spark2.x,简称CDS安装(图解官网安装)
CDH的官网都写的很详细,我们要学会看官网的步骤去安装,是最权威的
文章目录
- 一 找到Spark在哪里
- 二 安装CDS
-
- 2.1 安装Service Descriptor
-
- 步骤a
- 步骤b
- 步骤c
- 步骤d
- 2.2 添加包裹仓库(parcel repository)
- 2.3 CMS配置Parcel URL
- 2.4 下载,分发,激活
- 2.5 添加Spark2 服务
- 三 运行example
一 找到Spark在哪里
官网的文档地址:https://docs.cloudera.com/documentation/

点击上面的Apache Spark2

如下图,第一点是安装Spark的一些版本要求,我们点进去看下

如下图,是安装spark之前的一些版本要求,自己去看下对应关系

二 安装CDS
2.1 安装Service Descriptor
步骤a

先要安装service descriptor,我们点击连接进去看看
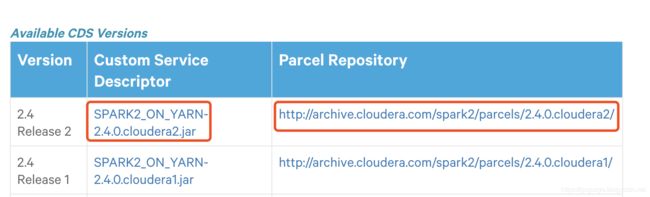
先下载service descriptor
wget http://archive.cloudera.com/spark2/csd/SPARK2_ON_YARN-2.4.0.cloudera2.jar
然后顺便把包裹Parcel也下载了,点击右边的连接
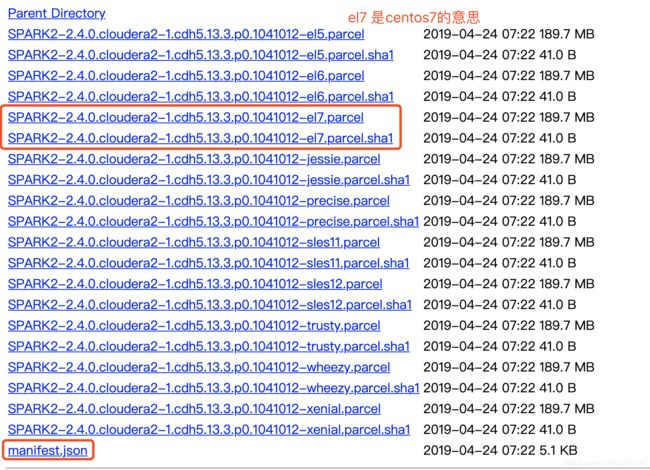
下载命令
wget http://archive.cloudera.com/spark2/parcels/2.4.0.cloudera2/SPARK2-2.4.0.cloudera2-1.cdh5.13.3.p0.1041012-el7.parcel
wget http://archive.cloudera.com/spark2/parcels/2.4.0.cloudera2/SPARK2-2.4.0.cloudera2-1.cdh5.13.3.p0.1041012-el7.parcel.sha1
wget http://archive.cloudera.com/spark2/parcels/2.4.0.cloudera2/manifest.json
下载之后的文件

步骤b
然后我们接着安装service descriptor,刚刚步骤a我们已经下载好了

从上图可以看出,步骤b是让我们登陆到Cloudera Manager Server主机,然后把下载好的service descriptor拷贝到location configured,我们点进去看看位置在哪里
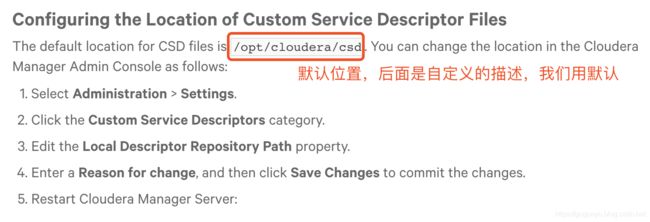
创建目录
mkdir /opt/cloudera/csd
移动service descriptor文件
mv SPARK2_ON_YARN-2.4.0.cloudera2.jar /opt/cloudera/csd
步骤c

步骤c,是设置service descriptor文件的拥有者和权限644
chown -R cloudera-scm:cloudera-scm /opt/cloudera/csd/SPARK2_ON_YARN-2.4.0.cloudera2.jar
chmod -R 644 /opt/cloudera/csd/SPARK2_ON_YARN-2.4.0.cloudera2.jar
步骤d
重启Cloudera Manager Server
sudo systemctl restart cloudera-scm-server
2.2 添加包裹仓库(parcel repository)
第二点,我们已经做了,下面我们看第三点

上面描述,在CM管理员控制界面,添加远程仓库URL,我们看下面的Note注意:如果我们的CMS不能互联网访问,可以把parcel文件放到一个新的仓库,也就是我们自己内部搭建一个仓库地址,然后内网安装(因为有的企业只能内网集群),我们点击new parcel repository
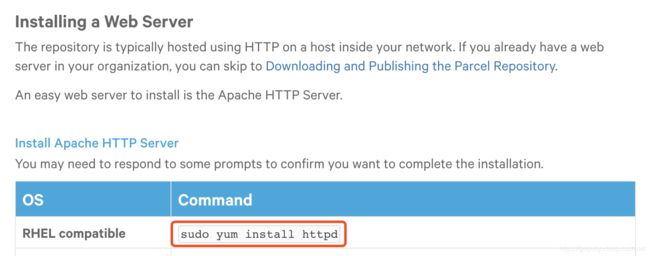
下面我们就跟着官网一起配置自己的http服务
先安装httpd
sudo yum install -y httpd
下面这一步是要我们下载parcel和manifest.json,这个下载,我们刚刚在前面已经下载了

下图,让我们把.parcel文件和manifest.json文件移动到我们刚刚安装的httpd server目录
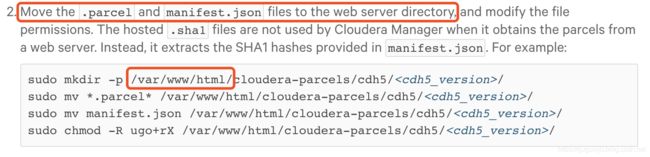
然后我们执行下面的命令:
sudo mkdir /var/www/html/spark2_parcel
sudo mv *.parcel* /var/www/html/spark2_parcel
sudo mv manifest.json /var/www/html/spark2_parcel
sudo chmod -R ugo+rX /var/www/html/spark2_parcel
然后下面让我们放下我们的httpd服务,看能不能访问到parcel

从下图可以看出,我们自己的parcel repository搭建好了

2.3 CMS配置Parcel URL
继续看官网的操作说明

进入cloudera manager界面 点击Parcels

点击Configuration

然后我们继续看看官网说怎么配置
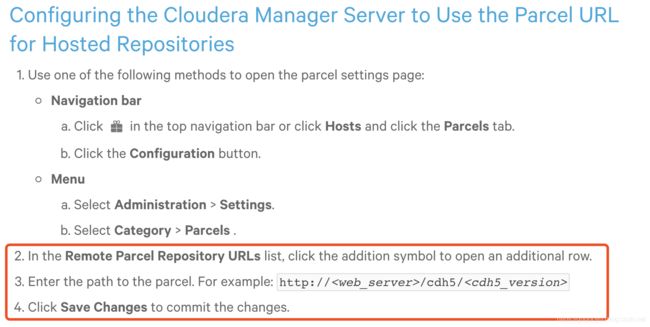
意思是让我们输入我们自己的httpd搭建好的包裹文件路径,然后保证Changes
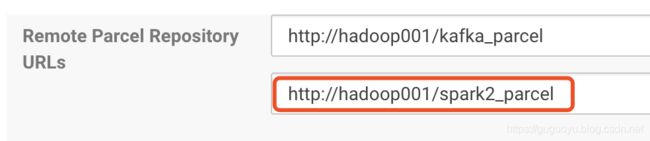
到这里可以看到Spark,本地URL已经设置好了

2.4 下载,分发,激活
回到安装文档的官网地址
https://docs.cloudera.com/documentation/spark2/latest/topics/spark2_installing.html

点击Download

点击Distribute

点击Active

到这里激活ok了

2.5 添加Spark2 服务
点击Add Service
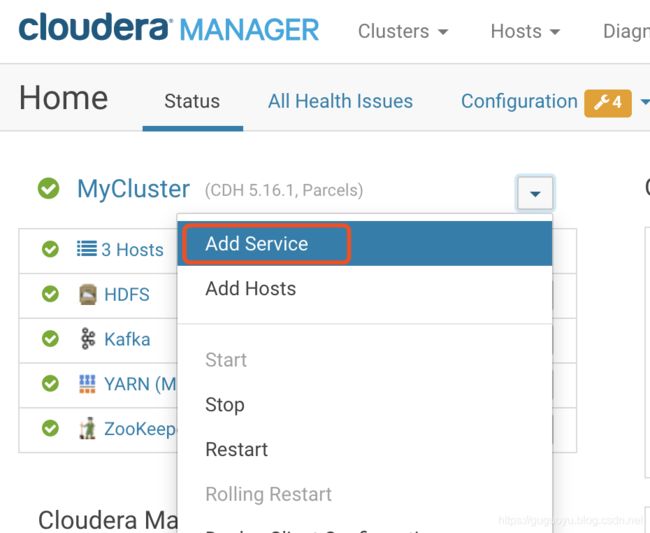
spark2出现了
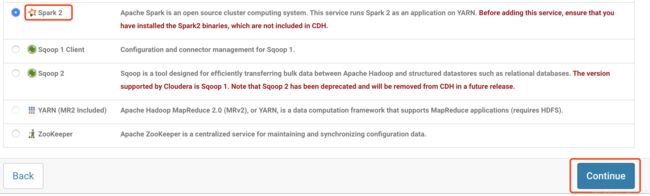
选择History Server节点

选择hadoop003,因为其他机器进程慢多了,选择hadoop003的意思,以后spark提交,到hadoop003提交即可

然后一直下一步即可
最后重启下yarn即可,因为yarn不仅要支持mapreduce,还要支持spark on yarn
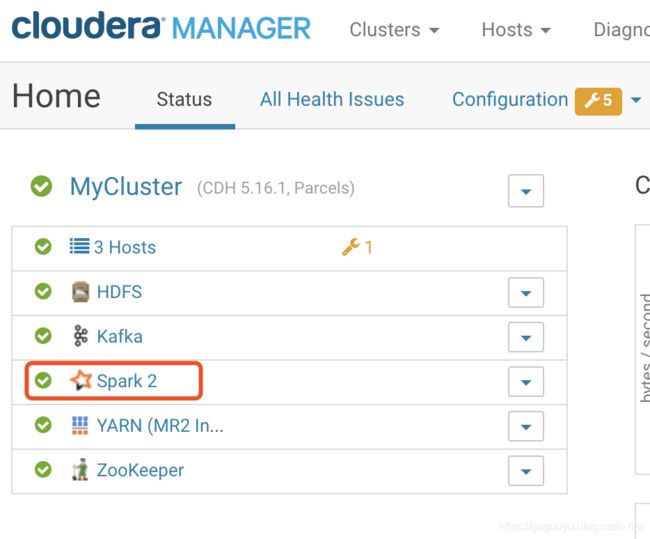
到这里安装结束
三 运行example
cloudera公司Spark的文档:https://docs.cloudera.com/documentation/spark2/latest.html

点进去看看,spark2的命令为spark2-submit

用CRT连接hadoop003机器,因为我们刚刚在hadoop003安装spark2的
spark2-submit \
--master yarn \
--executor-memory 1G \
--executor-cores 1 \
--num-executors 1 \
--class org.apache.spark.examples.SparkPi \
/opt/cloudera/parcels/SPARK2/lib/spark2/examples/jars/spark-examples_2.11-2.4.0.cloudera2.jar
执行的时候出现如下的错误(遇到错误的时候,不要害怕,看日志):
Exception in thread “main” java.lang.IllegalArgumentException: Required executor memory (1024), overhead (384 MB), and PySpark memory (0 MB) is above the max threshold (1208 MB) of this cluster! Please check the values of ‘yarn.scheduler.maximum-allocation-mb’ and/or ‘yarn.nodemanager.resource.memory-mb’
从上面错误可以看出,是内存不够,而且上面已经给我们提示,这2哥参数需要检查一下
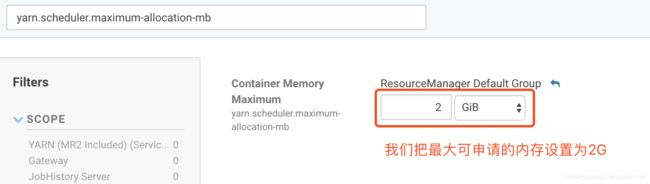
再设置下Container内存,因为executor是跑在Container里的

然后重启yarn

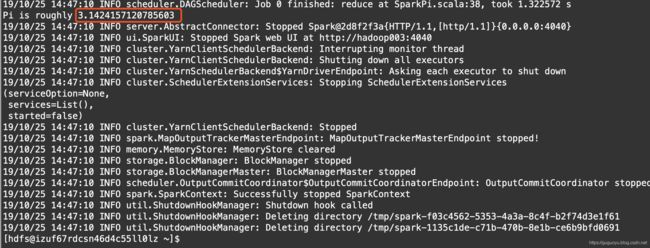
重启之后,我们再执行
spark2-submit \
--master yarn \
--executor-memory 1G \
--executor-cores 1 \
--num-executors 1 \
--class org.apache.spark.examples.SparkPi \
/opt/cloudera/parcels/SPARK2/lib/spark2/examples/jars/spark-examples_2.11-2.4.0.cloudera2.jar
发现又出现如下错误:
![]()
org.apache.hadoop.security.AccessControlException: Permission denied: user=root, access=WRITE, inode="/user":hdfs:supergroup:drwxr-xr-x
上面错误的意思是:权限拒绝,我们使用的用户root,期望进行写的操作
但是节点只允许hdfs用户,进行写,那么我们切换到hdfs去执行名
su - hdfs
执行结果如下,说明我们的spark2可以正常使用