神经网络基础
Deep learning就是深层神经网络
神经网络的结构如下,
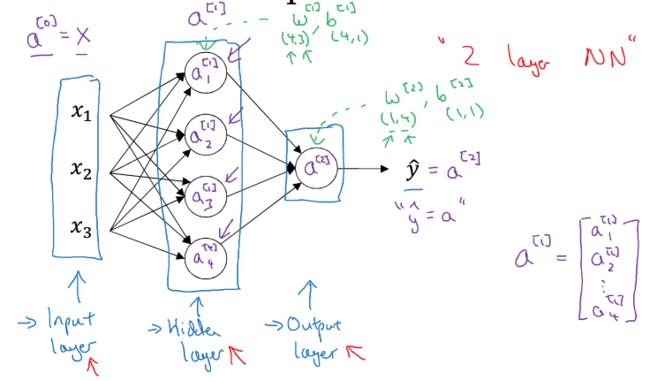
这是两层神经网络,输入层一般不算在内,分别是hidden layer和output layer
hidden layer中的一个神经元的结构如下,
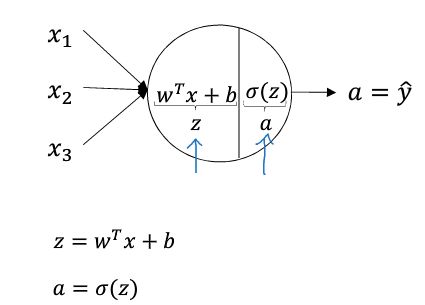
可以看出这里的神经元结构等同于一个逻辑回归单元,神经元都是由线性部分和非线性部分组成
非线性部分,又称为激活函数,这里用的是sigmod,也可以用其他,比如relu或tanh
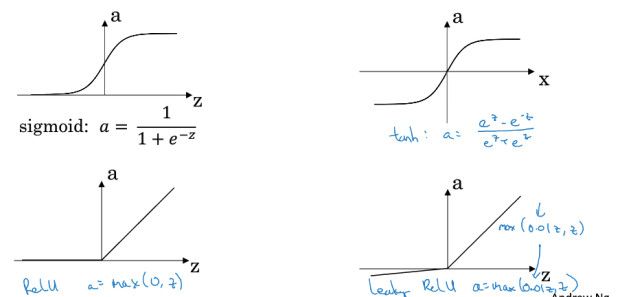
为什么要用激活函数?
因为既然要用神经网络去拟合任意function,光用线性拟合是不行的,因为再多层的线性函数叠加完了,还是线性函数,永远拟合不了非线性函数
所以激活函数就赋予了神经网络,非线性的能力
各种激活函数,参考,
聊一聊深度学习的activation function,https://zhuanlan.zhihu.com/p/25110450
这种简单的神经网络,称为前馈神经网络,直接理解,计算时是从输入层,逐层前馈计算的
而每层的参数w,b就是训练学习的对象
而训练学习参数的过程,会用到反向传播算法
训练首先要确定优化目标,loss(error) function,然后就是让各个参数沿着梯度方向下降,以达到最优点
这里注意,cost function,意思是 average of the loss function of entire training set,概念不要混

在神经网络中求导,用的就是反向传播算法,就是链式求导,比如,要算dw,先算da,再算dz,最后链式求导到dw
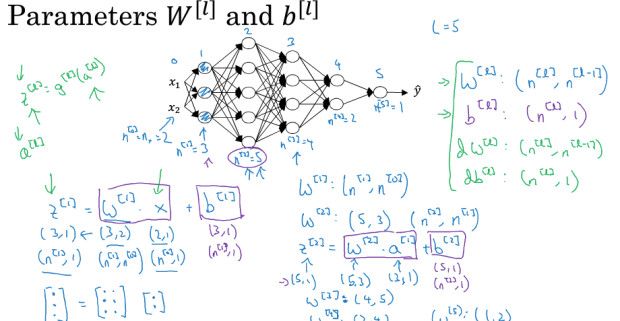
这里需要注意的是每层参数w,b的shape,如下图,
为什么需要深层网络?
直观上看, 深层网络,可以逐步提取从简单到复杂的各层的features
深层网络在每层的节点数,要大大小于浅层网络
ok,现在深度神经网络的结构讲完了
实际中,怎么去debug和调优一个网络?
先需要明确一些概念,
训练集,开发集,测试集
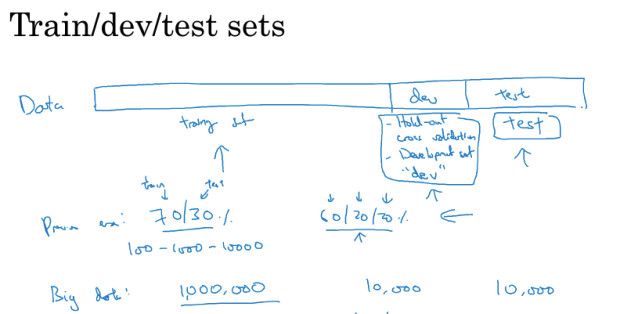
先要把数据集分开,一部分用于训练,一部分用于验证,这里有可以分dev和test,也可不分
Bias and Variance
优化的效果,可以用bias和variance来衡量,并找出模型的问题点
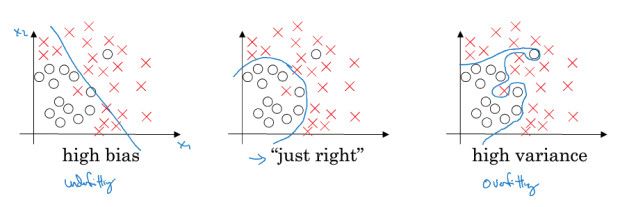
上面这个图,比较容易理解,
high bias,对训练集拟合不够好,模型太简单
high variance,模型过于复杂,过拟合训练集
所以在评价一个模型时,要同时给出,train set error和dev set error

train set error高就是high bias
dev set error高就是high variance
注意这里的假设是基于human准确率的,如果human判断也只能到15% error,那么train set error达到15%,也不能说是high bias
对于high bias,相对容易解决些,比如调整网络结构,用更复杂的网络,或增加训练时间和迭代次数
但是对于high variance,怎么解决,相对困难些,比如增加训练集,这个往往代价较高
正则化
解决high variance主要的方法,是正则化技术,Regularization
参考下图,正则化其实就是在cost function里面,加上罚项,或范数

这里又可以分为L2,L1,范数
我们优化的目的是让cost function达到最小,那么对于罚项而言,最小就是为0,
所以加上罚项的效果,就是会让某些w参数趋向0,即让w矩阵更加稀疏,而超参数,lambda决定罚项对整个优化的影响程度
L1,L2的不同在于,L1会让某些w参数直接等于0,而不是趋于0
这样做的理论依据是,奥卡姆剃刀(Occam's razor)原理,尽量选择更为简单的模型
这里的L2范数,用的比较多,又称为Frobenius norm(弗罗贝尼乌斯范数),也称为权值衰减weight decay
因为对于L2范数,梯度下降时,权值w会乘上一个小于1的系数,所以称为权值衰减
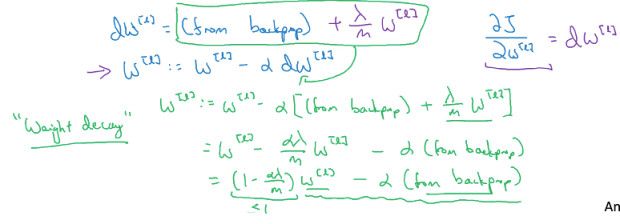
Regularization为何可以解决high variance的问题?
high variance的问题是因为模型过于复杂,而over fit训练集导致的
而正则化的结果,是某些w参数趋向于0,这等同于网络中的某些节点接近于失效,即简化了模型的复杂度
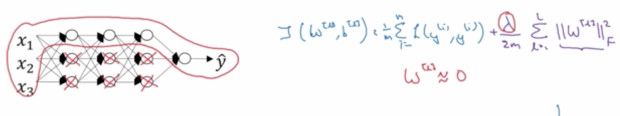
从另一个角度理解,
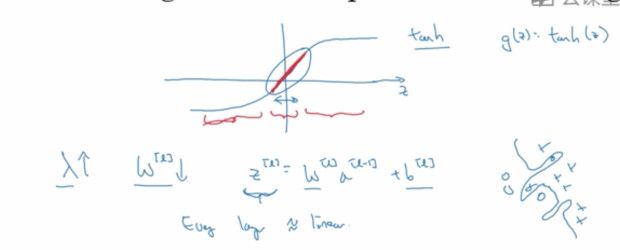
当w很小的时候,对于激活函数的z,也会是个较小的值,对于tanh或sigmod这样的激活函数,在这个区间会更加接近线性关系
所以很多w趋于0的时候,会让整个网络更趋向线性,所以会降低过拟合的程度
Dropout Regularization
dropout的思路比较简单,在训练时,每次迭代都随机的disable掉一些节点,以防止过耦合
dropout的效果,取决于keep-prob这个超参数,比如keep-prob=0.8,80%的概念会保留这个节点
如下图,我们可以对不同的layer设置不同的keep-prob,以解决某些layer的过拟合问题

具体的实现,如下介绍inverted dropout

比如对于第三层的输出a3,如果第三层有5个节点,我们需要决定哪些节点dropout,那么该节点的输出为0
这里直接用random和keep-prob比较,来判断是否需要dropout
关键点是,最终a3需要除以keep-prob值,把dropout掉的输出值补回来,所以称为inverted dropout
这样做的目的是,保证虽然在dropout时,不改变a3的期望,因为dropout只有在train的时候,在test的时候并不会去dropout
drop之所以可以起效果的原因还是比较直观的,因为他训练时减少了节点数,降低了模型的复杂度
从另一个方面看,由于train的时候,任意的节点都可能被dropout,所以模型会趋向避免过于依赖某个节点的输出,这样会让w产生L2,平方范数类似的效果
Early stopping
思路就是在做优化时,同时考虑train error 和 dev error
在dev error没有明显变差前,停止优化
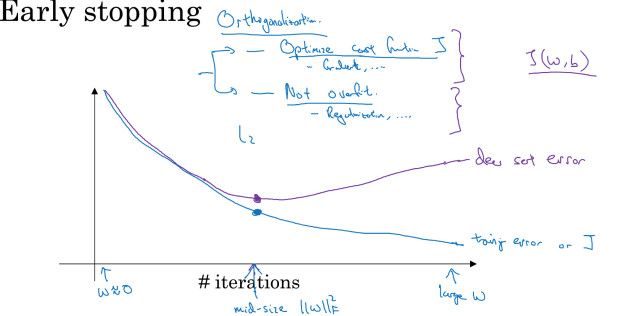
Early stopping的问题在于,无法正交的解决bias和variance的问题,做优化的时候需要同时考虑train error和dev error,所以增加优化时的复杂度
但是好处就是,不需要像L2一样尝试那么多的超参数lambda,只需要一次梯度下降的过程
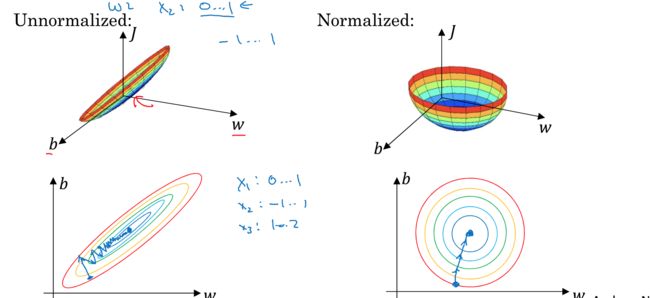
Normalizing inputs
在实际数据中,各个特征会有很大的差异,比如有些的取值范围0~1,有些1~10000,这样对于优化函数非常不友好
所以为了更快更高效的进行train,需要对input做normalize操作
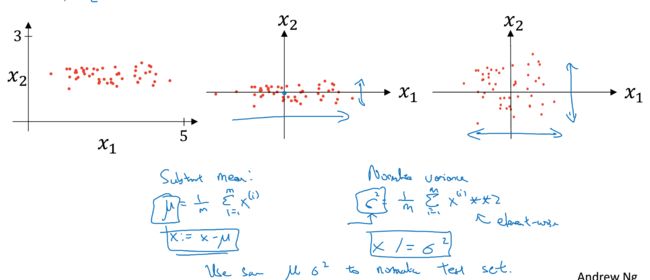
如图,很清晰,通过normalization,每个维度的数据都会达到,均值0,方差1
这里需要注意的是,如果对train数据进行normaliztion,那么需要用相同的参数对测试集进行normalization
下图更形象的表示,为何input normalization会对优化算法更为友好
梯度消失和爆炸
为了更直观的解释消失和爆炸的问题,这里NG用激活函数作为例子,
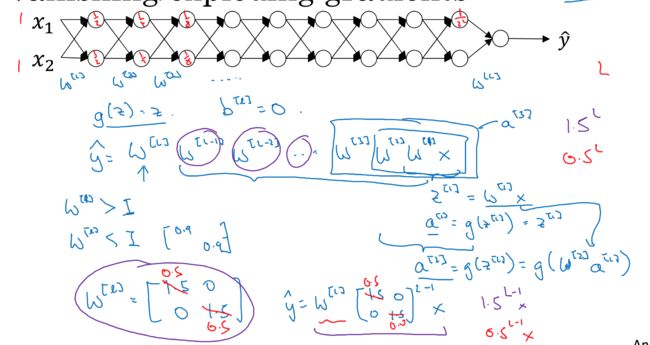
这里如果激活函数直接是,g(z)=z,且b=0,那么对于deep网络,第l层的输出,如上图,就是这样一个W的连乘形式
这里很容易看出,如果w是个比1大的数据,经过L层指数级增长后,会是个很大的值,那如果w比1小,结果就是会趋向于0
这里虽然是用激活函数来描述,其实对于梯度也是一样的,因为求梯度的时候是链式求导
梯度消失问题一直是阻碍deep learning的网络层数的因素,
如果我们更好的选择随机初始化参数,可以有效的缓解这个问题,
Xavier initialization,思路就是让输入和输出的方差一致,所以让var(w) = 1/n
为什么是1/n,NG没有说的太清楚,可以参考这里的推导,
CNN数值——xavier,https://zhuanlan.zhihu.com/p/22028079
对于,relu,使用He initialization,即var(w)=2/n,具体参考,聊一聊深度学习的weight initialization,https://zhuanlan.zhihu.com/p/25110150
说的比较清楚,
至于为何var(w) = 1/n
则w = np.random.random(shape) * np.sqrt(1/n),再想想
梯度的数值近似
如下图,我们可以用这种双边逼近的方式来近似梯度

这有什么用? 那我们可以用forward propagation,来检查我们的backward propagation是否实现的对
对于特定参数W,针对X,Y,可以通过backward propagation计算DW
参数W是由,w1,w2,w3,......,若干参数组成,现在可以用forward(w2+e),forward(w2-e),来计算出dw2的近似值,从而和dw2去比较,来看看backward是否算的对
优化算法
参考这篇知乎文章对优化算法的总结,
Adam那么棒,为什么还对SGD念念不忘,https://zhuanlan.zhihu.com/p/32230623
bath,mini-bath,stochastic
差别就是每次梯度下降过程是用整个train set,还是只用一个数据样本,还是用一个子集
显然,用到数据越多,梯度下降的稳定性越好,但性能会约差,所以是个balance,一般都会取中,用一个不大不小的mini-batch
指数加权平均
因为后续说的算法大都基于指数加权平均的想法,所以先介绍一下
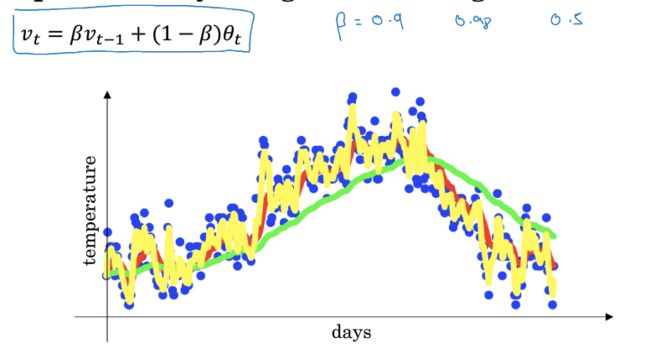
指数加权平均的公式如下,
其中B作为参数,如果越大,会导致曲线越稳定,但是对变化反应会约慢
可以认为,指数加权平均约等于1/(1-b)个时刻值的平均
下图中,红色线代表参数为0.9(10个值平均),绿色线表示参数为0.98(50个值平均),黄色表示参数为0.5(2个值)
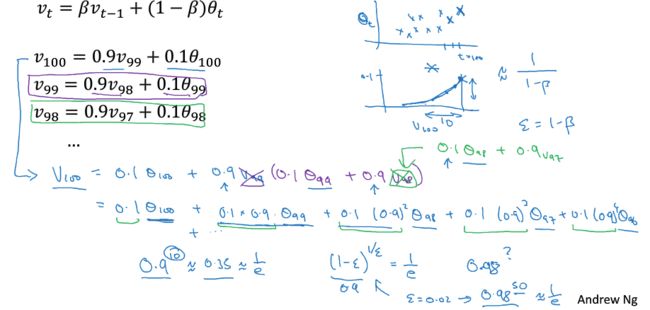
只所以叫指数加权,是因为当前值,对平均值的影响会呈现指数级别的衰减,如下图
加权指数平均好处是,计算时只需存一个值,比较简单,而不需要保留之前所有的值
然后它在开始时,有个bias的问题(这个问题也可以忽略掉,因为只要挨过冷启动就好)
因为如果初始值v0=0,刚开始的值会比较小
方法就是,将Vt除上1-Bt,这样在t比较小的时候,会对Vt有个明显的放大,以弥补初始值为0的问题
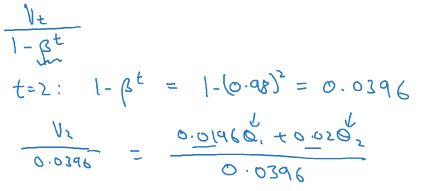
Momentum梯度下降
如下图,普通梯度下降的问题是,会有比较明显的oscillation,这样降低学习效率,而且无法使用比较大的学习率,如图中蓝色的线
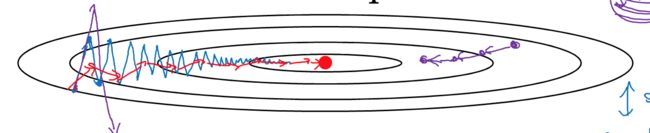
我们希望降低oscillation,这里可以用指数加权平均
因为是平均,所以在竖轴上的来回波动会平均掉,剩下就是在横轴上的更快速的梯度下降
另一种理解动量momentum的方式,一个正在滚动的球,具有惯性,你只能不断的施加外力去修正滚动的方向,而不能大幅突然转向
最终公式如下,

对梯度进行指数加权平均,最终用加权平均值来更新参数
这里增加一个超参数,Beta
RMSprop (Root Mean Square)
和momentum类似,也是为了消除oscillation
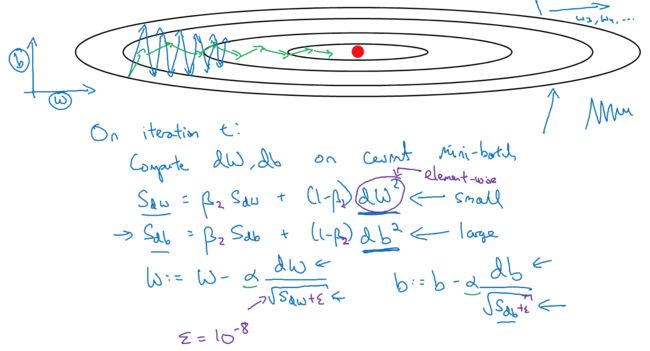
先算出梯度平方的指数加权平均,mean square
然后在更新参数的时候,dw会除上mean square的root
这样之所以有用,因为往往产生oscillation的维度的梯度都会比较大,如果不是那么普通优化算法也可以快速收敛
产生的效果就是,压缩产生oscillation维度的梯度更新幅度,放大有效维度的梯度更新幅度
这里又产生两个超参数,Beta2,以和momentum区别
epsilon,用于防止分母为0
Adam (Adaptive Moment Estimation)
Adam是非常通用和高效的算法,
思路就是把momentum,rmsprop结合起来

先用指数加权平均,算出Vdw和Sdw
然后去bias,消除冷启动

更新参数时,将momentum带入rmsprop的公式,

这个算法有较多的超参数,
alpha,beta1,beta2, epsilon
学习率alpha仍然是比较重要的,需要tune的参数
Learning Rate Decay
这也是一种加快学习和收敛速度的方法,
思路,开始的时候采用较大的学习率,这样可以快速逼近,但快接近收敛的时候,需要用较小的学习率,否则会来回波动
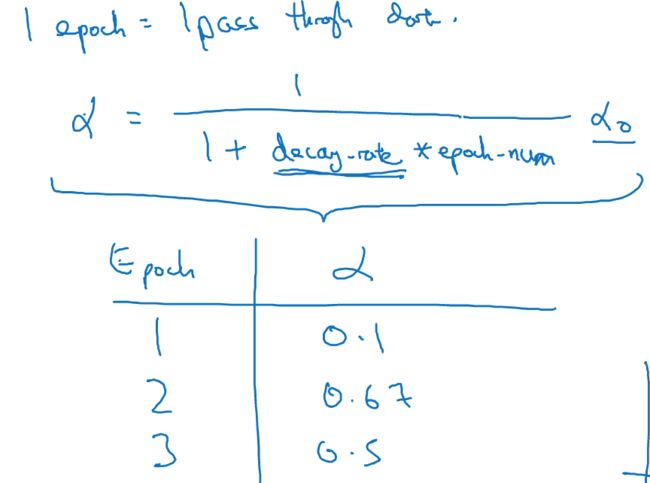
用这种方式,随着epoch的增大,学习率alpha会慢慢减小
Local Optima
在高维空间中,其实local optima的问题是不存在的,
因为在高维空间中碰到的都是saddle point,而不是local optima,因为几万维在一个点同时都是凹或凸的概念很小,一般都是部分凹,部分凸

对于saddle point的问题是plateau,稳定阶段,因为这里梯度接近0,收敛会非常的慢,需要花费很长时间
这时优秀的优化算法,如adam,可以帮助你快速走出plateau
Hyperparameters
常见的超参数如图,

红色的,学习率,往往是最重要的
黄色的,Beta(momentum),隐层的节点数,mini-batch大小,可以放在第二优先级进行调优
紫色的,网络层数,学习率的decay,第三优先级
而搜索最优超参数的策略,
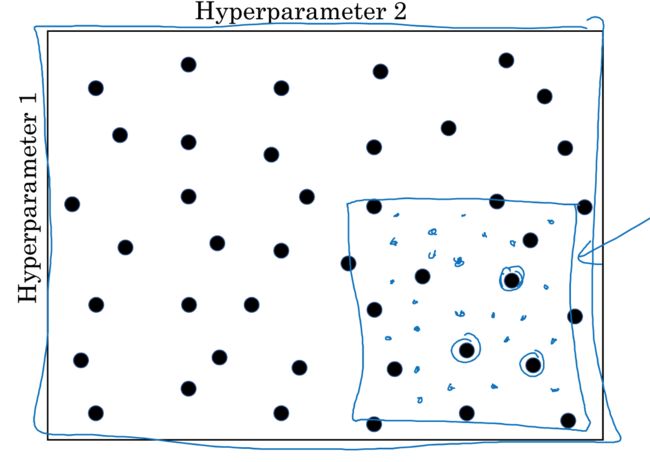
现在整个空间,随机选取,找到较优的参数,然后缩小搜索空间,继续更细粒度的搜索
在随机选取hyperparameter时,还需要考虑scale的问题
比如,如果是选择layer或节点数,那么用linear scale都是没问题的
但是如果是学习率alpha,取值范围0.0001到1

如果用linear scale,那么90%的值都会选在0.1到1之间,这样就不合适
所以要用log scale,让0.0001,0.001,0.01,0.1,1之间可以均匀的取值
对于momentum的参数Beta也有同样的问题,取值0.9到0.999
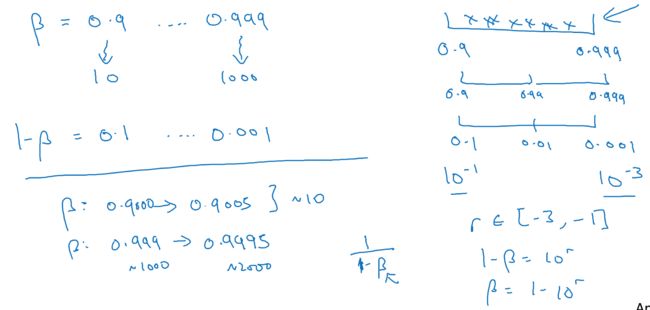
这里的技巧是,对1-beta采用log scale
这样做的理由,因为Beta在越靠近1的时候约敏感
B=0.9的时候,大概可以影响10个t的平均值,所以0.9005,也差不多是10个t,没啥影响
B=0.999的时候,大概可以影响1000个t,当如果变成0.9995,就会影响到2000个t,这个变化是很显著的
Batch Normalization
这篇知乎文章可以参考,
详解深度学习中的Normalization,不只是BN,https://zhuanlan.zhihu.com/p/33173246
前面已经提到,为了加快优化的速度,会对inputs做normalization
那自然的想法,是不是对每层的输入都做normalization,也会对加快优化速度
具体做法,直接用paper中的公式,

只所以叫batch normalization,因为每次normalization是针对一个mini-batch的,针对一个mini-batch中所有的X求出mean和variance,算出Xnorm
对于Xnorm,是mean=0,variance=1的分布
注意,最后还有一步,scale and shift,奇怪刚normalization完,怎么又shift回去了?
原因,
首先,这里的shift的参数r和beta是要通过学习优化的,所以这里赋予模型更大的自由度,你可以shift回原先的分布,也可以用任意的分布
再者,由于normalization在调用激活函数前,如果所有的输出都是mean=0,variance=1,对于像sigmod,tanh这样的函数,这个区域都是近似线性的区域,会限制模型的能力
那么将BN用于DL中,如下图
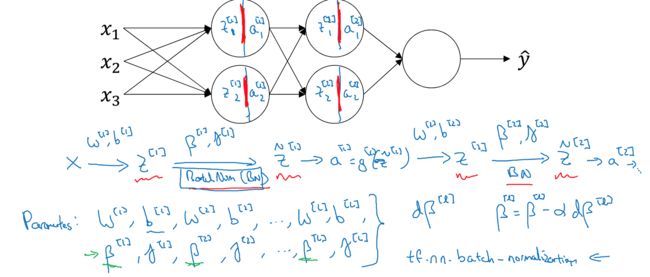
进行BN是在激活函数前,这样每层参数除了W,B,又多了beta,r
这里因为会对z做normalization,所以B无论啥值,最终都是会被消去的,所以这里的参数,可以把B去掉
为什么BN会有效?这个其实比较复杂
首先理解,Internal Covariate Shift,啥意思
NG给了个例子,你用全是黑猫的训练集训练模型,而测试集里面是各种颜色的猫,效果一定不会太好
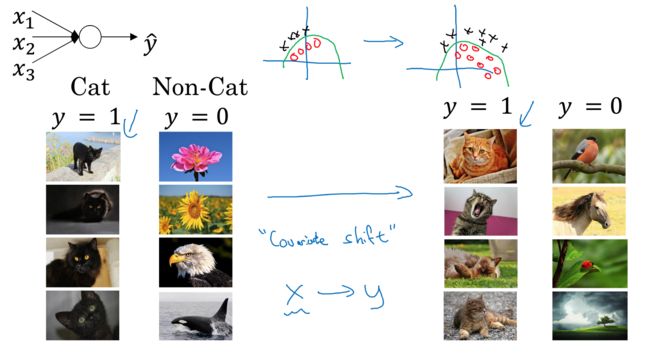
而黑猫到彩色猫的这种数据变化,就叫Covariate Shift
用知乎上的定义,
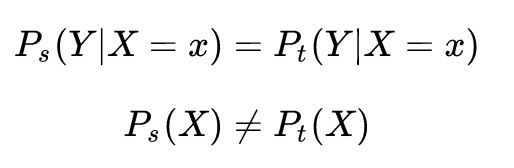
意思是,他们虽然都是符合一种分布,但是他们本身出现的概率不同
比如,我这次从上层得到的input都是黑猫的,我根据黑猫做了参数调优,然后下次过来的input又变成彩色猫,那可能参数要发生很大的改变
结果就是导致,
深度神经网络涉及到很多层的叠加,而每一层的参数更新会导致上层的输入数据分布发生变化,通过层层叠加,高层的输入分布变化会非常剧烈,这就使得高层需要不断去重新适应底层的参数更新
那BN的作用,就是限制每层输入的分布变化,让每层可以相对独立的对参数进行优化,而不会太过于受到上层输入的影响
虽然输入不一定是mean=0,variance=1那么规范,但毕竟通过beta和r是会被限定在某一分布内
BN除了可以使得参数训练更快速和稳定,
还能有效解决梯度消失问题,因为BN会将input调整到0附近,这样对于sigmod或tanh就不那么容易梯度消失
还附带一些regularization的效果
最后需要注意的是,
在test阶段,
没有mini-batch,如何得到normalization时需要的mean和variance
答案是用train时,所以mini-batch得到的mean和variance的平均值

DL Strategy
orthogonalization,正交化
说白了,一次只独立优化一个指标,让目标和方法更明确
一个knob,同时调整音量和亮度,是不是很confuse,同样同时调整bias和variance也是一样很confuse
如下图,在不同阶段的问题,我们用独立的方法去解决和优化

single number evaluation metrics
比如你评估一个算法好坏,用prision和recall,两个指标不好比较,所以用F1-score
satisficing and optimizing metrics
如果一个算法,需要同时考虑很多指标,很难合成单一指标
那就从里面挑出一个主要的优化指标,用于优化
其他的都设成满足指标
比如将accuracy设为优化指标,运行时间等设成满足指标
Train/dev/test distributions
dev set和optimizing metrics的设定非常重要,因为这是目标
如果metrics或dev set,无法表示和代表未来实际使用的场景中的数据,要及时修正
并且dev set和test set需要同分布,最好是在同样的数据集中采样,否则在dev set上验证和优化的模型会不适用于test set
train,dev,test的比例如下,
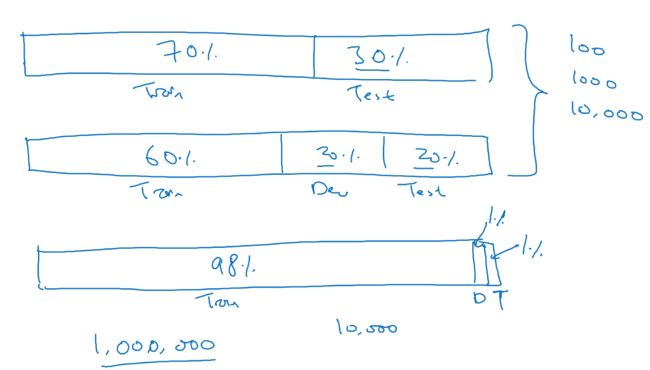
由于对于DL,数据集往往很多,所以只需要挑10000个左右的dev和test set即可
对于很多应用,甚至可以只用dev set,并没有test set
human-level performance
Bayes optimal error是理论可以达到的最小误差
而在很多场景下,human-level performance会比较接近 bayes error

而算法的优化,在低于human-level的时候会比较有效率,而一旦超过human level,进展会很慢
原因是,超过human-level后,一般比较接近bayes error,所以上升空间不大
并且一旦超过human level,很难通过人类标注,或人类分析数据来提升模型
在知道和理解human level后,才好判断如何优化算法,
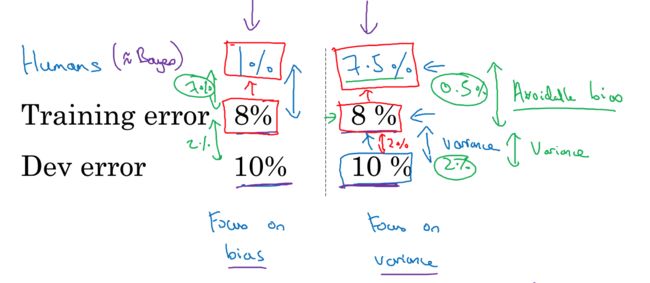
如图,虽然数据一样,但算法优化的思路是不同的
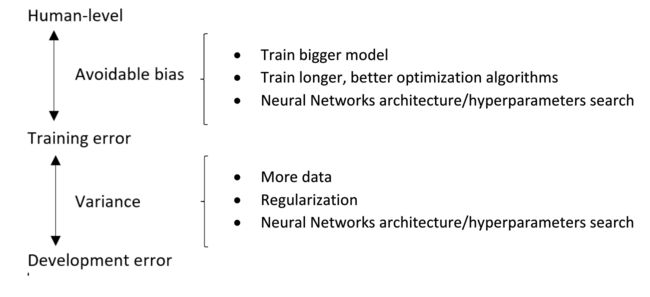
training error和human level之间差值,称为可避免误差,avoidable bias
dev error和training error之间差值,称为variance
在avoidable bias和variance之间进行比较,来判断优化哪一个
incorrectly labeled data
对于trainset中,少量的错误的label,无需关心
DL algorithm are quiet robust to random errors in the training set
而对于dev和testset中的错误,因为dev和test往往较小,所以需要修正掉
training and tesing on different distributions
前面说了,dev和test set表示优化目标,所以一定要同分布,且可以代表真实数据的分布
但是train set的分布可以不一样,原因是往往我们能找到的真实数据集比较小,如图,
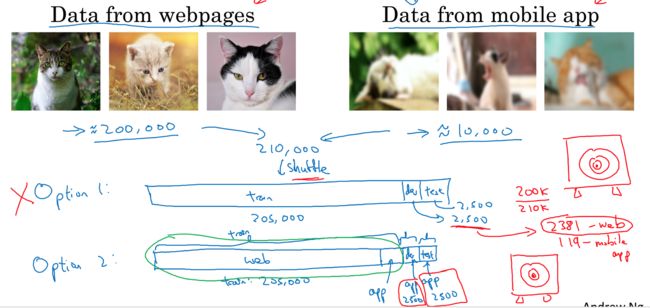
我们只有比较少的来自mobile app的猫图(10000),但是有大量的来自webpages的猫图(200000)
那么如何构造数据集?
可以把200000+10000图片放一起,sample出5000作为dev和test set,但这样做的最大问题是,dev和testset的分布不能代表真实数据,所以我们优化的目标可能是错的
所以正确的方法是,从mobile app的猫图中,sample 5000张用作dev和test set,因为我们一定要保证优化的目标是正确的
但是如果training set和dev set来自不同的分布,那么我们之前的bias,variance分析方法有些问题
因为用基于training set训练好的模型去测试不同分布的dev set,如果效果不好,你很难判断是由于variance过拟合,还是由于模型没有见过dev set的数据导致

所以,这里新加一种数据集,training-dev,和training数据同分布,这样用training-dev就可以判断模型是否存在variance问题
如果dev和training-dev之间的error差很多,说明存在data mismatch问题,而不是variance问题
如果发生dev和test的error比training-dev小,这看似很不合理,说明dev和test set中的数据更为简单,比training set容易判断
那么对于data mismatch问题,如何解决?没有太系统的方法
NG的建议是,人工去分析training和devset的区别,并尽量找个更多的训练数据让training set更加逼近dev set
人工合成训练数据也是一个方法,比如合成猫的图片,在语音中加入噪音
但人工合成的问题在于,我们用的case只是所有可能性空间中的一小部分,所以容易造成过拟合
迁移学习,transfer learning
这是一个很常用的技能,使用transfer learning的场景是,

用迁移学习,往往是由于在目标场景下,缺乏足够的数据,或者为了节省模型训练时间
做法就是,把输出层换掉,用新的训练集去单独训练最后一层的参数
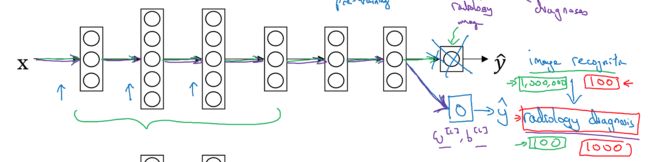
如果新的训练集比较多,也可以多加几层,或者多训练几层
这样做的理由是,
对于深层网络,就是一个从低级特征到高级特征不断抽象的过程
对于图像和语音,越低层的特征越容易被重用,所以把高层的layer换掉或重新训练,也会有很好的效果
multi-task learning
往往用于图像识别场景,

比如对于一张图片,我们希望同时识别,行人,车,信号灯等

注意这个和softmax不一样,softmax是单任务多元分类
在何种场景下,用多任务学习
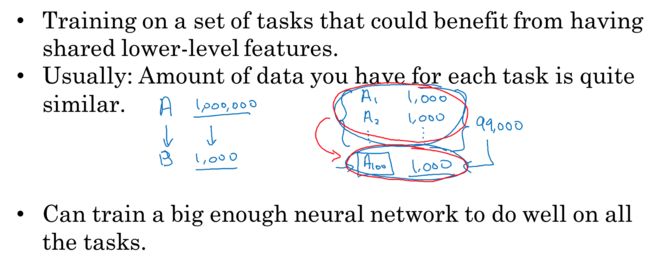
每个任务可以share低层特征,这样放在一起可以互相帮助
每个任务的训练集都不多,这样合一块,可以解决训练集过少的问题
我们可以训练一个足够大的网络来处理多任务
End to end deep learning
这是对传统机器学习或是传统it的一种挑战,传统it很多领域都是要依赖领域专家构造或编写系统和规则来完成工作
而DL有机会打破这一现象,你只需要给出海量的训练数据,深层网络会自己去抽象和学习这些领域知识,而不需要领域专家去精心构造的规则和系统
比如对于语音识别,以前需要若干步骤,精心的调试才能达到较好的效果
而如今,直接用一个深度网络,就可以省略中间这些步骤
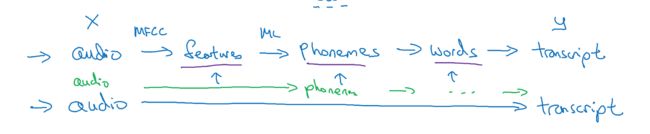
但是当前end to end deep learning的问题是,我们可能没有那么多的训练数据
所以在实际中,我们还是会把一个问题分解成若干个有大量训练数据的子问题
比如,门禁系统,会分成两个步骤,一是找到脸,二是比较脸
