《ProxylessNAS: Direct Neural Architecture Search on Target Task and Hardware》论文阅读笔记
ProxylessNAS
这篇文章出自著名的MIT Song Han组。正如其名proxyless–没有proxy,也就是想要构建某个数据集在某硬件上的网络就直接在此数据集上进行搜索,并将在对应硬件上的延时作为优化目标,而不是像之前的工作先在CIFAR-10上搜索然后再迁移到ImageNet等大数据集上,这篇文章发表在了ICLR 2019。原文可见ProxylessNAS: Direct Neural Architecture Search on Target Task and Hardware。
摘要
神经网络体系结构搜索(NAS)通过自动设计有效的神经网络体系结构而产生巨大的影响。然而,传统的NAS算法的计算需求令人望而却步(如 1 0 4 10^{4} 104个GPU时),这使得直接搜索大规模任务(如ImageNet)上的架构变得困难。可微分NAS可以通过网络架构的连续表示来降低GPU工作时间的开销,但是却存在GPU内存消耗高的问题(与候选集大小成线性增长)。因此,他们需要利用代理(proxy)任务,例如在较小的数据集上进行训练,或者只使用几个块进行学习,或者只训练几个epoch。这些在代理任务上优化的架构不能保证在目标任务上是最优的。本文提出的ProxylessNAS可以直接学习用于大规模目标任务和目标硬件平台的体系架构。本文解决了可微NAS的高内存消耗问题,并将计算成本(GPU小时数和GPU内存)降低到与常规训练相同的水平,同时仍然允许大量候选集。在CIFAR-10和ImageNet上的实验证明了该方法的直接性和专业性。在CIFAR-10上,本文的模型仅用5.7M的参数就达到了2.08%的测试误差,比之前SOTA的AmoebaNet-B架构还要好,而使用的参数却少了6倍。在ImageNet上,本文的模型比MobileNetV2的top-1准确率高3.1%,同时在测量GPU延迟的情况下,速度快1.2倍。本文还将ProxylessNAS应用于专业化具有直接硬件指标(例如,延迟)的硬件的神经架构,并为高效CNN架构的设计提供见解。
1. 引言
神经网络结构搜索(NAS)在实现图像识别和语言建模等多种深度学习任务的神经网络结构设计自动化方面取得了很大的成功。尽管取得了令人瞩目的结果,但是传统的NAS算法计算量非常大,需要在一次实验中针对目标任务训练数千个模型。因此,直接将NAS应用于大规模任务(如ImageNet)在计算上是昂贵的或不可能的,这使得它很难产生实际的行业影响。作为一个折衷方案,NASNet那篇文章建议在代理任务上搜索构建块,例如训练更少的epoch,从较小的数据集(例如CIFAR-10)开始,或者使用较少的块进行学习。然后,将性能最好的块堆叠起来并迁移到大规模目标任务上。这种模式在随后的NAS算法中被广泛采用。
但是,不能保证在代理任务上优化的这些块在目标任务上是最优的,尤其是在考虑诸如延迟等硬件指标时。更重要的是,为了实现可迁移性,这类方法只搜索少量的架构模式,然后重复地堆叠相同的模式,这限制了块的多样性,从而损害了性能。
这项工作提出了一个简单有效的解决方案,称为ProxylessNAS,它直接学习目标任务和硬件上的体系结构,而不是使用代理(图1)。此外还移除了以前NAS工作中重复块的限制,并允许学习和指定所有块。为了达到这一目的,通过以下方法将架构搜索的计算成本降低到与常规训练相同的水平。

在GPU耗时方面,将NAS定义为路径级的修剪过程。具体来说就是直接训练一个包含所有候选路径的超参数网络(图2)。在训练过程中显式地引入体系结构参数来学习哪些路径是冗余的,而这些冗余路径在训练结束时被剪枝以得到一个紧凑的优化体系架构。这样,在架构搜索过程中只需要训练一个没有任何元控制器(或超网络)的网络。
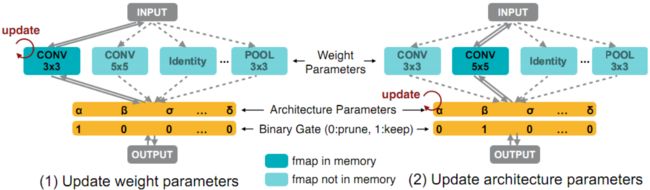
然而,天真地将所有候选路径都包含在内会导致GPU内存爆炸,因为内存消耗随着选择的数量线性增长。因此,在GPU内存方面,对架构参数进行二值化(1或0),并在运行时强制只有一条路径处于活跃状态,从而将所需的内存减少到训练紧凑模型的相同级别。文章提出了一种基于梯度的方法来训练这些基于BinaryConnect的二值化参数。此外,为了处理不可微的硬件目标(以延迟为例),以在目标硬件上学习专门的网络体系结构,作者将网络延迟建模为一个连续函数,并将其作为正则化损失进行优化。此外还提出了一种基于REINFORCE的算法,作为处理硬件指标的替代策略。
在CIFAR-10和ImageNet上的实验中,由于其直观性和专业性,本文的方法可以获得很强的实验结果。本文贡献总结如下:
- ProxylessNAS是第一种NAS算法,它在不使用任何代理的情况下直接学习大规模数据集(如ImageNet)上的体系结构,同时仍然允许一个大型候选集并移除重复块的限制。有效地扩大了搜索空间,取得了较好的性能。
- 为NAS提供了新的路径级修剪的观点,显示了NAS与模型压缩之间的紧密联系。 通过使用路径级别的二值化可以节省一个数量级的内存消耗。
- 本文提出了一种新颖的基于梯度的方法(延迟正则化损失)来处理硬件目标(例如延迟)。 给定不同的硬件平台:CPU / GPU /移动设备,ProxylessNAS支持硬件感知的神经网络专门化,这正是针对目标硬件进行了优化。
- 大量的实验表明ProxylessNAS具有直接性和专业性的优势。 在不同硬件平台(GPU,CPU和移动电话)的延迟限制下,它在CIFAR-10和ImageNet上实现了SOTA的精度性能。 此外还分析了针对不同硬件平台的高效CNN模型的见解,并提出在不同的硬件体系结构上需要专门的神经网络体系结构才能进行高效推理。
2. 相关工作
- 神经网络架构搜索NAS
- 强化学习,进化算法
- 提高NAS的效率:
- 超网络
- 权重共享
- 与这项工作更密切的是:
- One-Shot、DARTS:将NAS建模为包含所有候选路径的超参数化网络的单个训练过程,但存在着巨大的GPU内存消耗问题,因此仍然需要利用代理任务。而这项工作则通过路径二值化来解决这个问题。
- 网络剪枝
3. 方法
这一节首先描述了具有所有候选路径的超参数化网络的构造,然后介绍了如何利用二值化结构参数将训练超参数化网络的内存消耗降低到与常规训练相同的水平。提出了一种基于梯度的二值化结构参数训练算法。最后,我们提出了两种处理不可微目标(如延迟)的技术,用于在目标硬件上专门化神经网络。
3.1 超参数化网络的构建
将神经网络表示为 N ( e , ⋯ , e n ) \mathcal{N}(e,\cdots,e_{n}) N(e,⋯,en),其中 e i e_{i} ei表示有向无环图(DAG)中的某条边。令 O = { o i } \mathcal{O}=\{o_{i}\} O={ oi}为N个候选基本操作的集合(例如卷积,池化,identity,zero等)。为了构建包含搜索空间中任何架构的超参数化网络,这里不将每条边设置为一个有限的基本操作,而是将每条边设置为一个具有N条并行路径的混合操作(图2),表示为 m O m_{\mathcal{O}} mO。因此,超参数化网络可以表示为 N ( e = m O 1 , ⋯ , e n = m O n ) \mathcal{N}(e=m_{\mathcal{O}}^{1},\cdots,e_{n}=m_{\mathcal{O}}^{n}) N(e=mO1,⋯,en=mOn)。
给定输入x,混合操作 m O m_{\mathcal{O}} mO的输出基于其N条路径的输出来定义。在One-Shot里 m O ( x ) m_{\mathcal{O}}(x) mO(x)是 { o i ( x ) } \{o_{i}(x)\} { oi(x)}的和,而在DARTS里则是 { o i } \{o_{i}\} { oi}的加权和,其中通过将softmax应用于N个实值架构参数 { α i } \{\alpha_{i}\} { αi}来计算权重:
m O O n e − S h o t ( x ) = ∑ i = 1 N o i ( x ) , m O D A R T S ( x ) = ∑ i = 1 N p i o i ( x ) = ∑ i = 1 N e x p ( α i ) ∑ j e x p ( α j ) o i ( x ) (1) m_{\mathcal{O}}^{\mathrm{One-Shot}}(x)=\sum_{i=1}^{N}o_{i}(x),\qquad m_{\mathcal{O}}^{\mathrm{DARTS}}(x)=\sum_{i=1}^{N}p_{i}o_{i}(x)=\sum_{i=1}^{N}\frac{\mathrm{exp}(\alpha_{i})}{\sum_{j}\mathrm{exp}(\alpha_{j})}o_{i}(x)\tag{1} mOOne−Shot(x)=i=1∑Noi(x),mODARTS(x)=i=1∑Npioi(x)=i=1∑N∑jexp(αj)exp(αi)oi(x)(1)
如式(1)所示,计算所有N条路径的输出特征图并将其存储在内存中,而训练紧凑模型只涉及一条路径。因此,与训练紧凑模型相比,One-Shot和DARTS大约需要N倍的GPU内存和GPU时间。在大规模数据集上,具有较大设计空间的情况下很容易超过硬件的内存限制。这篇文章是基于路径二值化的思想来解决这个内存问题的。
3.2 学习二值化路径
这里为了减少内存占用,在训练超参数化网络时只保留一条路径(不是像之前某些工作二值化权重,这里是二值化整条路径)。具体的做法是引入N个实值架构参数 { α i } \{\alpha_{i}\} { αi},然后将实值路径权重转换为二值化门:
g = b i n a r i z e ( p 1 , ⋯ , p N ) = { [ 1 , 0 , ⋯ , 0 ] w i t h p r o b a b i l i t y p 1 , ⋯ [ 0 , 0 , ⋯ , 1 ] w i t h p r o b a b i l i t y p N . (2) g=\mathrm{binarize}(p_{1},\cdots,p_{N})=\begin{cases} [1,0,\cdots,0]&\mathrm{with\,\,probability}\,\,p_{1},\\ &\cdots \\ [0,0,\cdots,1]&\mathrm{with\,\,probability}\,\,p_{N}.\\ \end{cases}\tag{2} g=binarize(p1,⋯,pN)=⎩⎪⎨⎪⎧[1,0,⋯,0][0,0,⋯,1]withprobabilityp1,⋯withprobabilitypN.(2)
基于二值化门 g g g,混合运算的输出如下:
m O B i n a r y ( x ) = ∑ i = 1 N g i o i ( x ) = { o 1 ( x ) w i t h p r o b a b i l i t y p 1 , ⋯ o N ( x ) w i t h p r o b a b i l i t y p N . (3) m_{\mathcal{O}}^{\mathrm{Binary}}(x)=\sum_{i=1}^{N}g_{i}o_{i}(x)=\begin{cases} o_{1}(x)&\mathrm{with\,\,probability}\,\,p_{1},\\ &\cdots \\ o_{N}(x)&\mathrm{with\,\,probability}\,\,p_{N}.\\ \end{cases}\tag{3} mOBinary(x)=i=1∑Ngioi(x)=⎩⎪⎨⎪⎧o1(x)oN(x)withprobabilityp1,⋯withprobabilitypN.(3)
如式(3)和图2所示,通过使用二值化门而不是实值路径权重,在运行时只有一条激活路径在内存中处于活跃状态,因此训练超参数化网络的内存需求减少到训练紧凑模型的相同级别。这不仅仅是一个数量级的内存节省。
3.2.1 训练二值化架构参数
图2说明了在超参数化网络中权重参数和二值化架构参数的训练过程。在训练权值参数时,首先冻结架构参数,并根据公式(2)对每批输入数据随机采样二值化门。然后在训练集上通过标准梯度下降更新活跃路径的权重参数(图2左)。当训练架构参数时,权重参数被冻结,然后重置二进制门并在验证集上更新架构参数(图2右)。这两个更新步骤以交替方式执行。 一旦完成了架构参数的训练,便可以通过修剪冗余路径来获得紧凑的架构。 在这项工作中简单地选择权重最高的路径。
与权重参数不同,架构参数不直接包含在计算图中,因此无法使用标准梯度下降来更新。 这里引入一种基于梯度的方法来学习体系架构参数。
在BinaryConnect中,使用相对于其相应二值化门的梯度来更新实值权重。这里类似地,关于架构参数的梯度可以使用 ∂ L / ∂ g i \partial L/\partial g_{i} ∂L/∂gi代替 ∂ L / ∂ p i \partial L/\partial p_{i} ∂L/∂pi来近似地估计:
∂ L ∂ α i = ∑ j = 1 N ∂ L ∂ p j ∂ p j ∂ α i ≈ ∑ j = 1 N ∂ L ∂ g j ∂ p j ∂ α i = ∑ j = 1 N ∂ L ∂ g j ∂ ( e x p ( α j ) ∑ k e x p ( α k ) ) ∂ α i = ∑ j = 1 N ∂ L ∂ g j p j ( δ i j − p i ) (4) \frac{\partial L}{\partial \alpha_{i}}=\sum_{j=1}^{N}\frac{\partial L}{\partial p_{j}}\frac{\partial p_{j}}{\partial \alpha_{i}}\approx\sum_{j=1}^{N}\frac{\partial L}{\partial g_{j}}\frac{\partial p_{j}}{\partial \alpha_{i}}=\sum_{j=1}^{N}\frac{\partial L}{\partial g_{j}}\frac{\partial\left(\frac{\mathrm{exp}(\alpha_{j})}{\sum_{k}\mathrm{exp}(\alpha_{k})}\right)}{\partial \alpha_{i}}=\sum_{j=1}^{N}\frac{\partial L}{\partial g_{j}}p_{j}(\delta_{ij}-p_{i})\tag{4} ∂αi∂L=j=1∑N∂pj∂L∂αi∂pj≈j=1∑N∂gj∂L∂αi∂pj=j=1∑N∂gj∂L∂αi∂(∑kexp(αk)exp(αj))=j=1∑N∂gj∂Lpj(δij−pi)(4)
由于计算图中包含二值化门g,如式(3)所示, ∂ L / ∂ g j \partial L/\partial g_{j} ∂L/∂gj可通过反向传播计算。然而,计算 ∂ L / ∂ g j \partial L/\partial g_{j} ∂L/∂gj需要计算和存储 o j ( x ) o_{j}(x) oj(x)。因此,与训练紧凑模型相比,直接使用式(4)更新体系结构参数还需要大约N倍的GPU内存。
为了解决这个问题,考虑将从N个候选中选择一条路径的任务分解为多个二进制选择任务。这里的直觉是,直觉是,如果一条路径是特定位置的最佳选择,那么与其他任何一条路径相比,它应该都是更好的选择。
按照这个想法,在体系架构参数的更新步骤中,首先根据多项式分布 ( p 1 , ⋯ , p N ) (p_{1},\cdots,p_{N}) (p1,⋯,pN)采样两条路径,并掩盖所有其他路径,就好像它们不存在一样。因此,候选数目从N暂时减少到2,同时相应地重置路径权重 { p i } \{p_{i}\} { pi}和二值化门 { g i } \{g_{i}\} { gi}。然后,使用通过式(4)计算的梯度更新这两个采样路径的架构参数。最后,由于路径权重是通过将softmax应用于架构参数来计算的,所以需要通过乘以一个比率来重新调整这两个更新了的架构参数的值,以保持未采样路径的路径权重不变。因此,在每个更新步骤中,一个采样路径被增强(路径权重增加),另一个采样路径被衰减(路径权重减少),而所有其他路径保持不变。这样,不管N的值是多少,在架构参数的每个更新步骤中只涉及两条路径,从而将内存需求降低到训练一个紧凑模型的相同级别。
3.3 处理不可微的硬件指标
除了精度之外,在为硬件设计高效神经网络体系结构时,延迟(不是FLOPs)也是另一个非常重要的目标。 但与可以使用损失函数的梯度进行优化的精度不同,延迟是不可微分的。本文提出了两种算法来处理不可微的目标。
3.3.1 使延迟可微
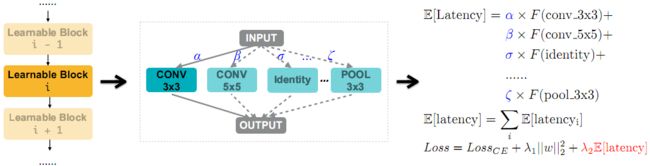
为了使延迟可微,这里的做法是将网络的延迟建模为神经网络维度的一个连续函数。考虑具有候选集合 { o j } \{o_{j}\} { oj}的混合操作,每个 o j o_{j} oj与代表选择 o j o_{j} oj的概率的路径权重 p j p_{j} pj相关联。因此,混合操作(即可学习块)的预期延迟为:
E [ l a t e n c y i ] = ∑ j p j i × F ( o j i ) (5) \mathbb{E}[\mathrm{latency}_{i}]=\sum_{j}p_{j}^{i}\times F(o_{j}^{i})\tag{5} E[latencyi]=j∑pji×F(oji)(5)
其中 E [ l a t e n c y i ] \mathbb{E}[\mathrm{latency}_{i}] E[latencyi]是第i个可学习块的预期延迟, F ( ⋅ ) F(\cdot) F(⋅)表示延迟预测模型, F ( o j i ) F(o_{j}^{i}) F(oji)是 o j i o_{j}^{i} oji的预测延迟。因此, E [ l a t e n c y i ] \mathbb{E}[\mathrm{latency}_{i}] E[latencyi]相对于架构参数的梯度可以表示为: ∂ E [ l a t e n c y i ] / ∂ p j i = F ( o j i ) \partial\mathbb{E}[\mathrm{latency}_{i}]/\partial p_{j}^{i}=F(o_{j}^{i}) ∂E[latencyi]/∂pji=F(oji)。
对于具有一系列混合操作的整个网络(图3左),由于这些操作是在推理期间按顺序执行的,因此可以用这些混合操作的预期延迟之和来表示网络的预期延迟:
E [ l a t e n c y ] = ∑ i E [ l a t e n c y i ] (6) \mathbb{E}[\mathrm{latency}]=\sum_{i}\mathbb{E}[\mathrm{latency}_{i}]\tag{6} E[latency]=i∑E[latencyi](6)
然后通过乘以比例因子 λ 2 ( > 0 ) \lambda_{2}(>0) λ2(>0)来将网络的预期延迟包含到正常的损失函数中去,该比例因子控制精度和延迟之间的折衷。最终损失函数如下所示(如右图3所示)
L o s s = L o s s C E + λ 1 ∥ w ∥ 2 2 + λ 2 E [ l a t e n c y ] Loss=Loss_{CE}+\lambda_{1}\lVert w\rVert_{2}^{2}+\lambda_{2}\mathbb{E}[\mathrm{latency}] Loss=LossCE+λ1∥w∥22+λ2E[latency]
其中 L o s s C E Loss_{CE} LossCE表示交叉熵损失, λ 1 ∥ w ∥ 2 2 \lambda_{1}\lVert w\rVert_{2}^{2} λ1∥w∥22表示权重衰减项。
3.3.2 基于强化的方法
作为BinaryConnect的替代方法,还可以利用REINFORCE来训练二值化的权重。考虑一个具有二值化参数 α \alpha α的网络,更新二值化参数的目的是找到使某个奖励 R ( ⋅ ) R(\cdot) R(⋅)最大化的最佳二值化门g。为了便于说明,假设网络只有一个混合操作。因此,根据REINFORCE,对二值化参数进行以下更新:
J ( α ) = E g ∼ α [ R ( N g ) ] = ∑ i p i R ( N ( e = o i ) ) , ∇ J ( α ) = ∑ i R ( N ( e = o i ) ) ∇ α p i = ∑ i R ( N ( e = o i ) ) p i ∇ α log ( p i ) = E g ∼ α [ R ( N g ) ∇ α log ( p ( g ) ) ] ≈ 1 M ∑ i = 1 M R ( N g i ) ∇ α log ( p ( g i ) ) (8) \begin{aligned} J(\alpha)&=\mathbb{E}_{g\sim\alpha}[R(\mathcal{N}_{g})]=\sum_{i}p_{i}R(\mathcal{N}(e=o_{i})),\\ \nabla J(\alpha)&=\sum_{i}R(\mathcal{N}(e=o_{i}))\nabla_{\alpha}p_{i}=\sum_{i}R(\mathcal{N}(e=o_{i}))p_{i}\nabla_{\alpha}\log(p_{i})\\ &=\mathbb{E}_{g\sim\alpha}[R(\mathcal{N}_{g})\nabla_{\alpha}\log(p(g))]\approx\frac{1}{M}\sum_{i=1}^{M}R(\mathcal{N}_{g^{i}})\nabla_{\alpha}\log(p(g^{i})) \end{aligned}\tag{8} J(α)∇J(α)=Eg∼α[R(Ng)]=i∑piR(N(e=oi)),=i∑R(N(e=oi))∇αpi=i∑R(N(e=oi))pi∇αlog(pi)=Eg∼α[R(Ng)∇αlog(p(g))]≈M1i=1∑MR(Ngi)∇αlog(p(gi))(8)
其中 g i g^{i} gi表示第i个采样的二值化门, p ( g i ) p(g^{i}) p(gi)表示根据式(2)采样 g i g^{i} gi的概率, N g i \mathcal{N}_{g^{i}} Ngi是根据二值化门 g i g^{i} gi得到的紧凑网络。由于式(8)不要求 R ( N g ) R(\mathcal{N}_{g}) R(Ng)相对于g是可微的,因此它可以处理不可微的目标。
4. 实验及结果
与之前的NAS工作不同的是这里直接搜索目标任务(CIFAR-10或ImageNet)和目标硬件(GPU,CPU和手机)上的体系结构,这也是题目里proxy less的来源。
4.1 CIFAR-10上的实验
架构空间
对于CIFAR-10实验,使用的是以PyramidNet为骨干的树状架构空间。使用两个超参数来控制网络在这个架构空间中的深度和宽度,即B和F,它们分别表示每个阶段的块数(总共3个阶段)和最终块的输出通道数。
训练细节
Proxyless-G (梯度方法) and Proxyless-R (REINFORCE方法) ,具体训练细节可参见原文。
结果
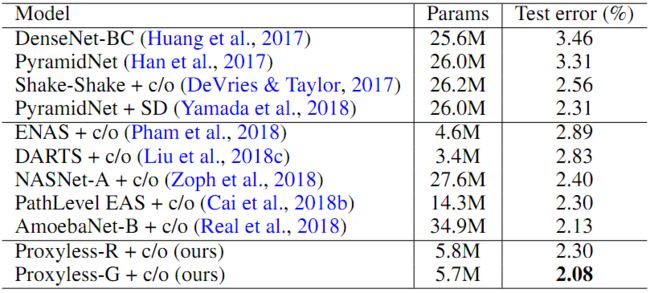
表1总结了本文提出的方法和CIFAR-10上的其他SOTA体系架构的测试错误率结果,其中“ c / o”表示使用Cutout。与这些SOTA的体系结构相比,本文提出的方法不仅可以获得更低的测试错误率,而且可以获得更好的参数效率。具体来说,Proxyless-G的测试错误率为2.08%,略好于AmoebaNet-B(CIFAR-10上先前的最佳架构)。值得注意的是,AmoebaNet-B使用34.9M参数,而Proxyless-G仅使用5.7M参数,少了6倍。此外,与同样探索树状架构空间的PathLevel EAS相比,Proxyless-G和Proxyless-R在参数减少一半的情况下获得了相似或更低的测试错误率结果。ProxylessNAS强大的经验结果表明了直接探索大型架构空间而不是重复堆叠同一个块的好处。
4.1 ImageNet上的实验
这里专注于学习高效的CNN架构,这种架构不仅在特定硬件平台上具有高精度,而且具有低延迟。因此,这是一个多目标NAS任务,其中一个目标是不可微的(即延迟)。这里的优化目标用的是 A C C ( m ) × [ L A T ( m ) / T ] w ACC(m)\times[LAT(m)/T]^{w} ACC(m)×[LAT(m)/T]w(跟MnasNet的一模一样哈哈),其中 T T T是目标延迟, w w w是控制精度和延迟之间权衡的超参数。
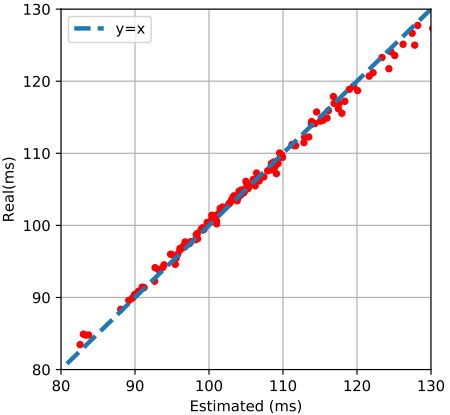
另外,在手机上,架构搜索时使用了延迟预测模型。如图5所示,可以看到到在测试集上预测的延迟和实际测量的延迟之间存在很强的相关性,这表明延迟预测模型可以用来替换昂贵的移动设施,而引入的误差很少。
架构空间
这里是直接使用MobileNetV2作为backbone来构建架构空间。但这里不是简单地重复相同的移动反向瓶颈卷积(MBConv,也就是MobileNetV2的基本构建块),而是可以对MBConv有所改变,让NAS去搜索不同的核大小(这里是3,5,7)和不同的扩展比(这里是3和6)。为了实现宽度和深度之间的直接traed-off,这里创建了一个更深的超参数化网络,并通过将zero运算添加到其混合运算的候选集来允许跳过带有残差连接的块。这样,在有限的延迟预算下,网络可以通过跳过更多的块和使用更大的MBConv层来选择变得更浅和更宽,或者通过保留更多的块和使用更小的MBConv层来选择变得更深和更窄。
训练细节
具体看原文。
ImageNet分类结果
首先应用ProxylessNAS来学习手机上的CNN模型。汇总结果见表2。与MobileNetV2相比,ProxylessNAS模型将top-1准确性提高了2.6%,同时在手机上保持了类似的延迟。 此外,通过使用乘数来重新调整网络的宽度,如图4所示,在所有延迟设置下,ProxylessNAS模型在性能上始终优于MobileNetV2。具体来说,要达到同样的top-1精度水平(约74.6%),MobileNetV2有143ms的延迟,而ProxylessNAS模型只需要78ms(快1.83倍)。与MnasNet相比,ProxylessNAS模型可以使top-1准确性提高0.6%,而移动延迟则要低一些。 更重要的是,ProxylessNAS的资源效率更高:GPU时间比MnasNet少200倍。

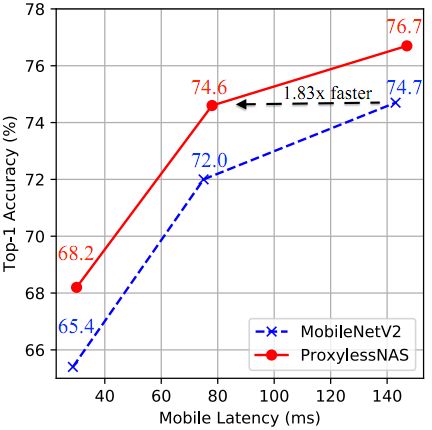
另外可以看到,Proxyless-G模型在ImageNet上只能达到71.8%的top-1精度,比具有延迟正则化损失的Proxyless-G给出的结果低2.4%。 因此在学习高效神经网络时,以延迟为直接目标至关重要。
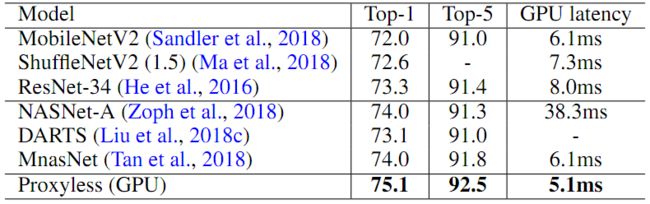
除了手机,也应用ProxylessNAS在GPU和CPU上学习专门的CNN模型。表3报告了GPU上的结果,可以发现与人工设计和自动搜索的体系结构相比,ProxylesNAS仍然可以获得优异的性能。表4显示了在三个不同平台上搜索模型的汇总结果。可以看到为GPU优化的模型在CPU和手机上运行速度并不快,反之亦然。因此,学习针对不同硬件架构的专用神经网络对于在不同硬件上实现最佳效率至关重要。

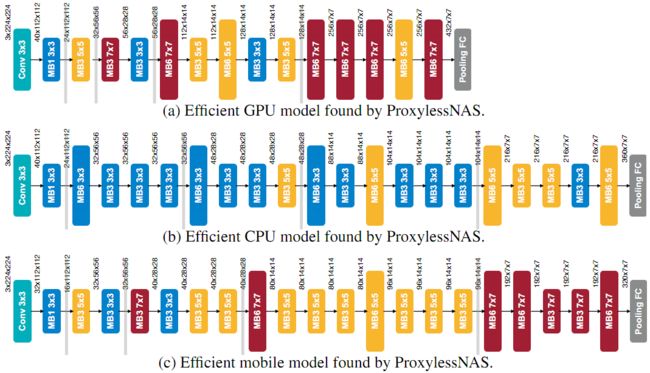
不同硬件的专用模型
图6展示了在三个硬件平台上搜索的CNN模型的详细架构。可以注意到,当针对不同的平台时,体系结构显示出不同的偏好:(i)GPU模型更浅更宽,特别是在特征图具有更高分辨率的早期阶段;(ii)GPU模型更喜欢大的MBConv操作(例如 7 × 7 7\times7 7×7 MBConv6),而CPU模型则更喜欢使用较小的MBConv操作。这是因为GPU具有比CPU高得多的并行度,因此它可以更好地利用大的MBConv操作。另一个有趣的发现是,在所有平台上搜索到的模型都在每个阶段的第一个块(对特征图进行下采样)中,首选较大的MBConv操作(这一点在MixNet中也有实验的证明,确实在下采样层用较大的卷积核是有好处的,大家在设计网络的时候可以考虑下采样层用一些 5 × 5 5\times5 5×5乃至 7 × 7 7\times7 7×7这样的大卷积核)。 这可能是因为较大的MBConv操作有利于网络在下采样时保留更多信息。 值得注意的是,此类模式无法在以前的NAS方法中捕获,因为它们迫使这些块共享相同的结构。
5. 总结
这篇文章介绍了ProxylessNAS,它可以直接在目标任务和目标硬件上学习神经网络结构,而无需任何代理。还使用路径二值化将NAS的搜索成本(GPU时间和GPU内存)降低到与正常训练相同的水平。通过直接搜索,在CIFAR-10和ImageNet上获得了很好的实证结果。通过将测量到的硬件延迟直接纳入优化目标,允许针对不同平台的专门化网络体系结构。
个人看法
本文的ProxylessNAS其实就是看到了之前的DARTS以及One-Shot虽然搜索速度降了下来,但是还是需要很多GPU内存,于是乎通过路径二值化的操作,不再像DARTS里面对不同操作求一个加权和,而是直接只保留两个操作,从而大大将内存需求从 O ( N ) O(N) O(N)降到了 O ( 1 ) O(1) O(1),因而也就可以在大数据集上直接搜索网络,而不用担心爆内存了。不过搜索时间需要200个GPU时,还是比DARTS慢了很多,怪不得在比较搜索时间的时候不放DARTS的结果呢2333。