AI正在往哪里去?这有一份来自腾讯AI Lab的2018答卷
雷刚 发自 凹非寺
量子位 报道 | 公众号 QbitAI
腾讯AI Lab,如何回答2018?
最近,这个巨头内部以AI为核心的实验室,对全年重点工作和进展进行了回顾。
或许从这些进展中,不仅能窥见腾讯对前沿AI方向的探索,还能感受到AI行业正在面临的最新挑战。
于是我们转载腾讯AI Lab 2018年度回顾全文,希望对你能有启发。
行业应用
AI+公益
我们在 2018 年完成了一些很有意义的项目,如“图片语音即时描述”技术,让机器充分理解图像内容后,将其“翻译”成语句,让视障者使用QQ空间时,能听到对图片的描述,实时了解朋友动态。
通过提供这一系列信息无障碍技术,腾讯今年获得了联合国教科文组织颁发的“数字技术增强残疾人权能奖”。
AI+医疗
第二个例子是显微镜的进化,我们在这种古老而重要的医疗器械中加入了AI与AR技术,让机器自动识别、检测、定量计算和生成报告,并将检测结果实时显示到医生所看目镜中,在不打断医生阅片的同时及时提醒,提高医生的诊断效率和准确度。
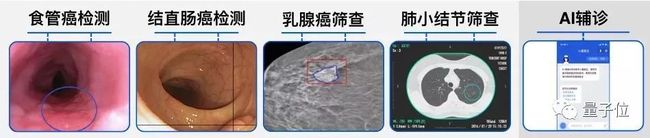
今年我们还会继续通过“腾讯觅影”产品深入探索AI+医疗的应用,目前图像处理技术已用在食管癌、肺癌、糖尿病性视网膜病变等疾病的早期筛查上,语言和语音处理技术也用于智能导诊和辅诊上。
△腾讯智能显微镜
AI+农业
我们还在“AI+农业”迈出了一小步——一个很会“种”黄瓜的AI。
在荷兰举办的国际AI温室种植大赛里,我们利用传感器和摄像头自动收集温室气候、作物发育情况等环境和作物数据,再用深度学习模型计算、判断和决策,驱动温室的设备元件,远程控制黄瓜生产,最后获总比分第二、AI策略第一的成绩,还开心收获了3496公斤黄瓜。

AI+视频
在腾讯视频中,我们提供了超分辨率和视频分类的技术。此外,我们还探索了对视频内容的深度理解、编辑与生成。
比如,让机器深度分析一个视频,识别其中人物、物体、场景,并分析它们的关系,并在时间顺序识别视频中不同的动作和事件,产生能表达出视频丰富语义信息的语句。
而在视频生成上,我们研究的视频运动信息迁移技术,在给到几张人物A的静止图片后,能让A模仿人物B的舞蹈动作,从静止到“动”起来。
前沿技术难题
下一代的智能交互:3D虚拟人
我们通过多个部门的共同研究,合作推进了“多模态人机交互”这一前沿课题。
我们将计算机视觉、自然语言处理、语音技术有机结合在一起,辅以一定的情绪认知、分析决策能力,赋予虚拟人看、听、想、说的多模态输入和输出能力,以实现更自然、逼真、风格鲜明、千人千面的人机交互体验。我们已经实现了整套技术方案的打通,并有望探索新的产品形式。
游戏AI → AGI
游戏是 AI 研究的传统实验场,从2016年研发围棋AI“绝艺”起,我们不断利用这块实验沃土,探索迈向通用人工智能的道路。2018 年,我们收获颇丰,而此类探索还将继续下去。
我们与王者荣耀及王者荣耀职业联赛共同探索的前沿研究项目——策略协作型AI“绝悟”——首次亮相KPL决赛,与人类战队(超过99%玩家)进行5V5水平测试并取得胜利。
我们使用了监督学习方法,模拟人类决策方法的算法模型兼具了大局观与微操能力,并在此基础上研发多个有针对性的强化学习训练模型,有效提升了AI团队协作能力。
此外,我们的深度强化学习智能体还在《星际争霸 II》战胜了Level-10内置 AI,还与清华大学合作拿下了FPS射击类游戏AI竞赛VizDoom赛事历史上首个中国区冠军。
机器人:打通虚拟和现实
我们还成立了企业级机器人实验室“腾讯Robotics X”,构建AI+机器人双基础部门,打造虚拟世界到真实世界的载体与连接器。
比如,我们从0到1实现了机械手从虚拟到现实的迁移,通过搭建满足各种物理属性的高逼真模拟器,支持多种强化学习算法,并能和机械臂和灵巧手的实体硬件接口兼容,通过新提出的DHER算法训练抓取、搭积木、端茶倒水等虚拟任务。
我们还将其成功迁移到了现实世界中。
另外,在新建成的腾讯深圳总部展厅里,我们还完成了“绝艺”围棋机器人、桌上冰球和与浙江大学合作的机械狗等展示项目,体现了机器人的本体、控制、感知、决策方面的能力。
开源开放
除了发表论文公开研究成果,我们也通过代码和数据开源将腾讯积累的技术能力(尤其是 AI 能力)共享给整个行业,并希望以此促进行业生态的共同发展和繁荣。
2018 年 10 月,我们开源了业内最大规模的多标签图像数据集Tencent ML-Images,其中包含了 1800 万图像和11000种常见物体类别。
此外我们还提供了从图像下载和图像预处理,到基于ML-Images的预训练和基于ImageNet的迁移学习,再到基于训练所得模型的图像特征提取整个流程的代码和模型。
截至目前已在 GitHub 获 2000 星和 2000+ 次下载。
我们还在 10 月份开源了一个大规模、高质量的中文词向量数据集,其中包含 800 多万中文词汇,在覆盖率、新鲜度及准确性上都优于之前的数据集。
11 月,我们开源了一个自动化深度学习模型压缩与加速框架 PocketFlow,其中整合了多种模型压缩与加速算法,并能利用强化学习自动搜索合适的压缩参数。我们希望该框架能降低模型压缩的技术门槛,赋能移动端 AI 应用开发。
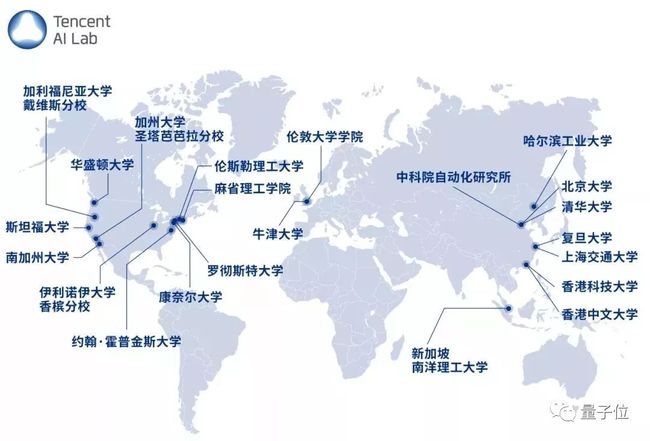
在高校合作方面,我们与麻省理工、牛津、斯坦福、港科大、清华和哈工大等全球知名高校的教授联合研究,并通过专项研究计划、访问学者计划、青年学者基金、联合实验室等多种方式,共探学术前沿领域,并迅速将研究应用到腾讯云、腾讯开放平台等多个业务中。
4大方向基础研究
我们基础研究方向主要为四个:机器学习、计算机视觉、语音处理和自然语言处理。
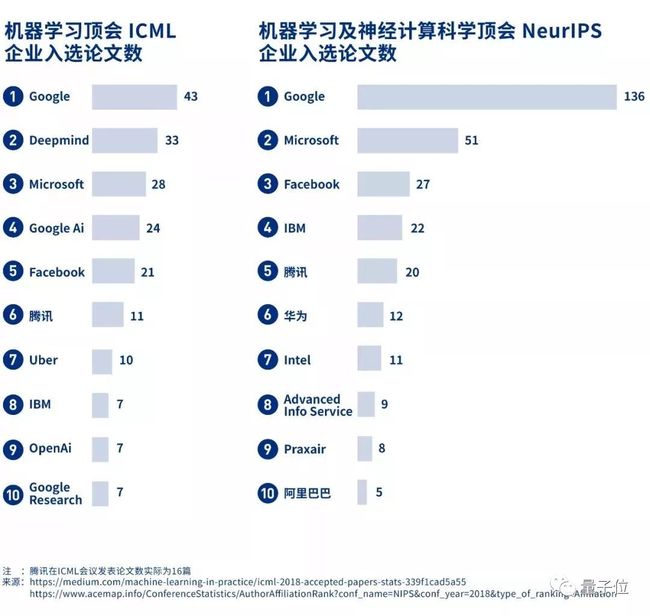
2018 年,我们有超过150 篇学术论文发表在各大顶级学术会议上,如NeurIPS、ICML、CVPR、ECCV、ACL、EMNLP、InterSpeech 和 ICASSP 等,位居国内企业前列。
未来,我们将继续关注前沿领域的研究课题,推进跨学科、多模态、交叉研究课题探索,以开放、合作和共赢的态度,不断探索研究的边界。
机器学习
学习能力,是区分智能机器和普通自动化机器的核心技能之一,也是迈向通用人工智能(AGI)的必备技能。
我们的研究涵盖了强化学习、迁移学习、模仿学习、优化算法、弱监督和半监督学习、对抗学习和多任务学习等。
我们探索了自动化机器学习(AutoML)的可能性,这是当前机器学习领域的前沿探索方向之一。
比如,我们提出了一种基于数据分布迁移的超参优化算法[1]。该方法利用分布相似度来迁移不同数据对应的超参优化结果,从而能对新数据的超参优化起到热启动的效果。
我们还进一步研发了FastBO算法,并发现其在医疗和游戏等多个场景上有比人工调参更好的效果。
针对多任务问题,我们提出了一种学习框架 L2MT[2] ,能自动发掘一个最优的多任务学习模型;我们还提出了一种用学习迁移实现迁移学习的方法 L2T[3],能显著降低迁移学习的计算成本和所需的领域知识。

我们也为强化学习提出了一些改进方法,比如提出一种描述如何从环境和任务来组成强化学习策略的元规则部件神经网络,实现了自适应于不同环境、不同任务的合成策略[4]。
我们还尝试用演示来提升强化学习的探索效果(POfD)[5]及使用联网智能体的完全去中心化多智能体强化学习[6]。
在计算机安全和社会安全上,我们研发的自动特征学习、群分类和图特征增强方面的算法,能成功识别和对抗黑产用户、涉黑群体和恶意用户(标记覆盖率超90%),还能精准识别有信贷风险的用户,帮助防控金融风险。
计算机视觉
计算机视觉技术有非常广泛的应用前景,是智能医疗、自动驾驶、增强现实、移动机器人等重要应用的不可或缺的一部分。
我们不断寻找赋予机器更强大视觉能力的方法,以实时、稳健和准确地理解世界。
2018 年,我们的探索包括结合相机与其它传感器数据实现 3D 实时定位[1]、结合传统时空建模方法(MRF)与深度学习方法(CNN)来跟踪和分割视频中的物体[2],及一些在视频描述生成任务上的新方法[3]。
我们还定义了一种名为视频重定位(Video re-localization)[4]的新任务,可在某段长视频中查找与指定视频语义相关片段。我们也为视频中的运动表征提出了一种端到端的神经网络TVNet[5]。
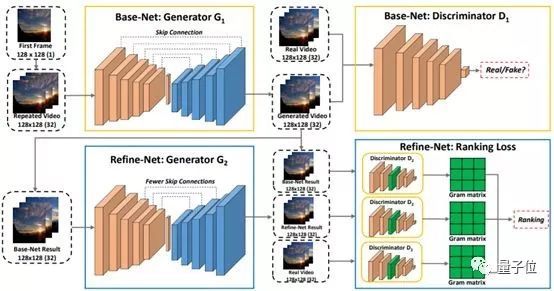
除了帮助机器理解世界,我们也在探索视频生成方面的技术,比如我们提出了一种自动生成延时摄影视频的解决方案[6],可以通过预测后续的图像帧来呈现可能发生的动态变化。我们也探索了多阶段动态生成对抗网络(MD-GAN)[7]在这一任务上的应用。
语音处理
我们的语音解决方案已经在腾讯的听听音箱、极光电视盒子和叮当音箱等产品中得到应用。
2018 年,我们又提出了一些新的方法和改进,在语音增强、语音分离、语音识别、语音合成等技术方向都取得了一定进展。
语音唤醒上,我们针对误唤醒、噪声环境中唤醒、快语速唤醒和儿童唤醒等问题,提出了一种新的语音唤醒模型[1],能显著提升关键词检测质量,在有噪声环境下表现突出,还能显著降低前端和关键词检测模块的功耗需求。
我们还提出了一种基于 Inception-ResNet 的声纹识别系统框架[2],可学习更加鲁棒且更具有区分性的嵌入特征。
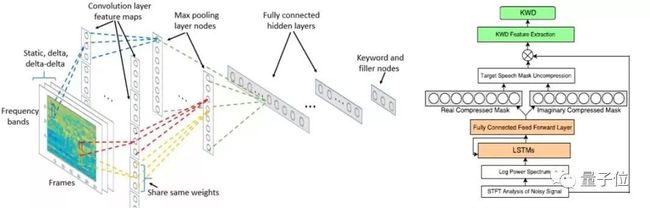
语音识别上,我们的解决方案是结合了说话人特征的个性化识别模型,能为每位用户提取并保存个性化声学信息特征。随用户数据积累,个性化特征自动更新,用户识别准确率能显著提升。
另外,我们还创新地提出了多类单元集合融合建模方案,这是一种实现了不同程度单元共享、参数共享、多任务的中英混合建模方案。这种方案能在基本不影响汉语识别准确度的情况下提升英语的识别水平。我们仍在噪声环境、多说话人场景[3]、“鸡尾酒会问题”[4]、多语言混杂等方面继续探索。
语音合成是确保机器与人类自然沟通的重要技术。腾讯在语音合成方面有深厚的技术积累,开发了可实现端到端合成和重音语调合成的新技术。腾讯AI Lab 2018 年在语调韵律变化[5]、说话风格迁移[6]等任务上取得了一些新进展。
自然语言处理
腾讯 AI Lab 在自然语言处理方面有广泛而又有针对性的研究,涉及文本理解、文本生成、人机对话、机器翻译等多个方向。
我们训练的模型在多个阅读理解类数据集上位居前列,如CMU大学的RACE、ARC (Easy/Challenge)及OpenBookQA等。
在神经网络机器翻译方面,我们通过改进当前主流翻译模型中的多层多头自注意力机制[1]和提出基于忠实度的训练框架[2],改善其核心的译文忠实度低的问题。
我们还针对口语翻译中代词缺省的问题提出了一种联合学习方法[3],以及探索如何将外部的翻译记忆融入神经网络翻译模型[4]。
我们还发布了一款AI辅助翻译产品TranSmart[5],向人工翻译致敬。它采用业内领先的人机交互式机器翻译和辅助翻译输入法技术,配合亿级双语平行数据,为用户提供实时智能翻译辅助,帮助用户更好更快地完成翻译任务。作为笔译工具的未来形态,目前这个产品已经进入了很多高校翻译课堂。
我们研究了文本和对话生成,提了出一种基于强化学习框架的回复生成模型[6],对于同一个输入能够自动生成多个不同的回复;一种跨语言神经网络置信跟踪框架XL-NBT[7]在实现跨语种对话系统方面有重要的实际应用潜力(比如多语种自动客服)。
此外,我们还为自动回复的多样性对条件变分自编码机进行了改进[8]。
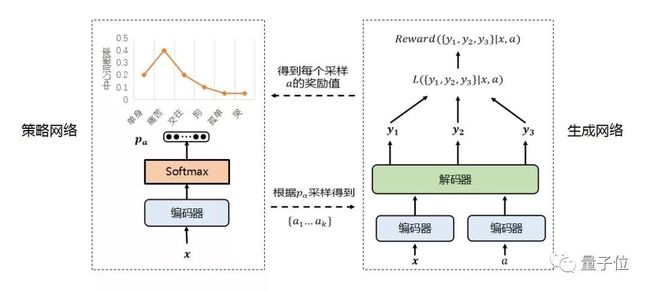
值得一提的是我们将中国古典文化与现代技术的结合方面的探索。我们在 2018 年春节期间推出了腾讯 AI 春联,可根据用户提供的两个汉字生成一副春联。
我们还探索了创造机器诗人的问题,提出一种基于对抗条件变分自编码器的诗歌生成方法(CVAE-D)[9],在主旨一致性和用词的新颖性上取得了不错的进展。
腾讯AI Lab现状
近三年时间里,腾讯AI Lab相继成立了深圳及美国西雅图实验室,目前团队有70多名顶尖AI科学家及300多位经验丰富的工程师,专注四大研究方向。
产业落地上,AI Lab将与新成立的“腾讯Robotics X”机器人实验室担当前沿技术双基础部门,深耕产业,拥抱消费及产业互联网,做好技术标配。

论文传送门:
机器学习
[1] 基于数据分布迁移的超参优化算法
https://arxiv.org/pdf/1810.06305.pdf
[2] 学习框架L2MT
https://arxiv.org/abs/1805.07541
[3] 用学习迁移实现迁移学习的方法 L2T
https://ai.tencent.com/ailab/media/publications/icml/148_Transfer_Learning_via_Learning_to_Transfer.pdf
[4] 自适应于不同环境、不同任务的合成策略
https://papers.nips.cc/paper/7393-synthesize-policies-for-transfer-and-adaptation-across-tasks-and-environments
[5] POfD
https://ai.tencent.com/ailab/media/publications/icml/152_Policy_Optimization_with_Demonstrations.pdf
[6] 完全去中心化多智能体强化学习
https://arxiv.org/abs/1802.08757
计算机视觉
[1] 3D 实时定位
https://arxiv.org/abs/1810.05456
[2] 跟踪和分割视频中的物体
https://arxiv.org/abs/1803.09453
[3] 视频描述生成任务新方法
https://arxiv.org/abs/1803.11438
[4] 视频重定位
https://arxiv.org/abs/1808.01575
[5] TVNet
https://arxiv.org/abs/1804.00413
[6] 自动生成延时摄影视频
https://arxiv.org/abs/1709.07592
[7] 多阶段动态生成对抗网络(MD-GAN)
https://arxiv.org/abs/1709.07592
语音处理
[1] 语音唤醒模型
https://www.isca-speech.org/archive/Interspeech_2018/pdfs/1668.pdf
[2] 基于 Inception-ResNet 的声纹识别系统框架
https://www.isca-speech.org/archive/Interspeech_2018/pdfs/1769.pdf
[3] 多说话人场景
https://ai.tencent.com/ailab/media/publications/MonauralMulti-TalkerSpeechRecognitionwithAttentionMechanismand_GatedConvolutionalNetworks._pdf.pdf
[4] 鸡尾酒会问题
https://link.springer.com/article/10.1631/FITEE.1700814
[5] 语调韵律变化
https://ai.tencent.com/ailab/media/publications/icassp/FEATURE_BASED_ADAPTATION_FOR_SPEAKING_STYLE_SYNTHESIS.pdf
[6] 说话风格迁移
https://www.isca-speech.org/archive/Interspeech_2018/pdfs/1991.pdf
自然语言处理
[1] 多层多头自注意力机制的改进
https://arxiv.org/abs/1810.10181
[2] 基于忠实度的训练框架
https://arxiv.org/abs/1811.08541
[3] 联合学习方法
https://arxiv.org/abs/1810.06195
[4] 翻译记忆融入
https://ai.tencent.com/ailab/nlp/papers/aaai2019_graph_translation.pdf
[5] AI辅助翻译产品TranSmart
http://transmart.qq.com/
[6] 基于强化学习框架的回复生成模型
https://ai.tencent.com/ailab/nlp/publications.html
[7] 跨语言神经网络置信跟踪框架 XL-NBT
https://arxiv.org/pdf/1808.06244.pdf
[8] 对条件变分自编码机的改进
http://aclweb.org/anthology/D18-1354
[9] 基于对抗条件变分自编码器的诗歌生成方法(CVAE-D)
http://aclweb.org/anthology/D18-1423
— 完 —
加入社群
为给AI从业者提供更好的交流平台,量子位现开放「AI+行业」社群,将会不定期邀请AI大咖、知名企业家、技术大牛进群分享,福利多多,欢迎小伙伴入群交流。
面向人群:AI相关从业者,技术、产品等人员,根据所在行业可选择相应行业社群;
入群方式:请在量子位公众号(QbitAI)对话界面回复关键字“行业群”,获取入群方式。
Ps.为保证社群价值,小助手会对申请入群的朋友进行审核,请大家理解!
诚挚招聘
量子位正在招募编辑/记者,工作地点在北京中关村。期待有才气、有热情的同学加入我们!相关细节,请在量子位公众号(QbitAI)对话界面,回复“招聘”两个字。

量子位 QbitAI · 头条号签约作者
վ'ᴗ' ի 追踪AI技术和产品新动态
喜欢就点「好看」吧 !