Linux slub分配器
目录
1. Slub重要数据结构说明 2
2. SLUB分配器框架建立过程 3
3. 通用缓存 4
4. 创建slub缓存 6
4.1 slub结构框架 6
4.2 slub缓存创建流程 6
4.3创建kmem_cache_nodes 8
4.4 计算slab order 9
5. Kmalloc 11
5.1 kmalloc分配流程: 11
5.2 分配slab 12
6. Kfree 14
6.1将object放到c->page中 14
6.3将slab放到s->cpu_slab 16
6.4将s->cpu_slab->partial释放到s->node->partial中 17
Slub重要数据结构说明
| struct kmem_cache |
|
| struct kmem_cache_cpu __percpu *cpu_slab |
为每个cpu缓存部分objects |
| unsigned long flags |
控制Slab创建的标志比如SLAB_RED_ZONE |
| unsigned long min_partial |
kmem_cache_node中保存的slab阀值 |
| int size |
Object大小包含调试和对齐相关数据 |
| int object_size |
Object本身大小 |
| int offset |
Free point offset通常情况为0,即object自身开始位置存放 Free point |
| int cpu_partial |
cpu_slab中缓存的objects数 |
| struct kmem_cache_order_objects oo |
高16位用于保存slab order,低16位保存一个slab中的objects数量 |
| gfp_t allocflags |
从伙伴系统分配slab的所用的分配标志 |
| int inuse |
包含对齐的object大小 |
| int align |
对齐大小 |
| const char *name |
缓存名 |
| struct list_head list |
用于将缓存链接到全局链表 slab_caches中 |
| int red_left_pad |
左边危险区大小 |
| unsigned int *random_seq |
Slab内部freelist的随机数数组 |
| struct kmem_cache_node *node[MAX_NUMNODES] |
管理缓存中的slab |
| struct kmem_cache_cpu |
|
| void **freelist |
指向第一个空闲的kobject |
| struct page *page |
Slab是一个联合页,这里指向这个联合页的首页 |
| struct page *partial |
缓存备用的slab |
| struct kmem_cache_node |
|
| unsigned long nr_partial |
缓存中slab的数量 |
| struct list_head partial |
Slab链表 |
slab是缓存中的一组object,是缓存一次从伙伴系统分配内存的大小,slab就是一个s->oo阶的联合页
| struct page |
|
| void *freelist |
Slab内部空闲object链表 |
| struct { unsigned inuse:16; unsigned objects:15; unsigned frozen:1; }; |
struct { unsigned inuse:16; //已经使用的object unsigned objects:15;//slab中的object数 unsigned frozen:1;//为1表明slab位于s->cpu_slab中;为0表明slab位于s->node中或者没有空闲object的slab }; |
| struct page *next |
Slab单向链表 |
| unsigned long compound_head |
指向联合页首页 |
| unsigned int compound_order |
联合页页阶这里即是slab的order |
| struct kmem_cache *slab_cache; |
指向page所属的slab |
SLUB分配器框架建立过程
slub缓存有三个管理结构:struct kmem_cache用于管理整个slub缓存;cpu_slab是一个percpu变量,缓存部分object用于每个cpu上的内存分配,避免竞争提高效率;node用于管理备用的slab,每个内存节点由一个这样的管理结构。
struct kmem_cache {
struct kmem_cache_cpu __percpu *cpu_slab;
......
struct kmem_cache_node *node[MAX_NUMNODES];
};据上面的描述可知要创建一个slub缓存需要分配kmem_cache,cpu_slab,node这三个结构,但是在开机阶段小块内存分配机制(slub)还没有建立,不能进行动态分配,所以我们使用临时的局部定义结构体先构建一个用于分配kmem_cache和kmem_cache_node的两个slub缓存。cpu_slab是一个percpu变量这个时候percpu机制已经可用了所以可以通过__alloc_percpu直接分配。
全局变量slab_state用于记录slub框架建立的状态:
enum slab_state {
DOWN, /* 还没有建立slub分配机制 */
PARTIAL, /* SLUB: kmem_cache_node 缓存建立 */
PARTIAL_NODE, /* SLUB分配没有使用 */
UP, /* slub通用缓存创建 */
FULL /* slub “/sys/kernel/slab/”节点已经创建*/
};start_kernel ---->mm_init----> kmem_cache_init
void __init kmem_cache_init(void)
{
static __initdata struct kmem_cache boot_kmem_cache,
boot_kmem_cache_node;
/*由于slub架构还没有建立先使用局部结构体boot_kmem_cache_node和boot_kmem_cache创建
"kmem_cache_node"和 "kmem_cache"缓存*/
kmem_cache_node = &boot_kmem_cache_node;
kmem_cache = &boot_kmem_cache;
//创建"kmem_cache_node"缓存,object大小为sizeof(struct kmem_cache_node)具体创建过程后面讲解
create_boot_cache(kmem_cache_node, "kmem_cache_node",
sizeof(struct kmem_cache_node), SLAB_HWCACHE_ALIGN);
slab_state = PARTIAL; //slub状态设置为PARTIAL
//创建"kmem_cache"缓存,在单内存节点系统中object大小为sizeof(struct kmem_cache_node *)
create_boot_cache(kmem_cache, "kmem_cache",
offsetof(struct kmem_cache, node) +
nr_node_ids * sizeof(struct kmem_cache_node *),
SLAB_HWCACHE_ALIGN);
//动态分配缓存"kmem_cache"对应的kmem_cache,并将临时局部结构boot_kmem_cache拷贝到动态分配的结构中去
kmem_cache = bootstrap(&boot_kmem_cache);
//动态分配缓存"kmem_cache"对应的kmem_cache_node,并将临时局部结构boot_kmem_cache_node拷贝到动态分配的结构中去
kmem_cache_node = bootstrap(&boot_kmem_cache_node);
//初始化数组size_index[],该数组保存小于192大小slub缓存在kmalloc_caches[idx]中的索引
setup_kmalloc_cache_index_table();
//创建通用缓存最大KMALLOC_SHIFT_HIGH (PAGE_SHIFT + 1) ,两页。并且设置slab_state = UP
create_kmalloc_caches(0);
//cpu offline的时候将对应cpu_slab中的slab flash到kmem_cache_node中
cpuhp_setup_state_nocalls(CPUHP_SLUB_DEAD, "slub:dead", NULL,
slub_cpu_dead);
}创建"/sys/kernel/slab"节点并且设置 slab_state = FULL
static int __init slab_sysfs_init(void)
{
struct kmem_cache *s;
int err;
mutex_lock(&slab_mutex);
slab_kset = kset_create_and_add("slab", &slab_uevent_ops, kernel_kobj);
if (!slab_kset) {
mutex_unlock(&slab_mutex);
pr_err("Cannot register slab subsystem.\n");
return -ENOSYS;
}
slab_state = FULL;
list_for_each_entry(s, &slab_caches, list) {
err = sysfs_slab_add(s);
if (err)
pr_err("SLUB: Unable to add boot slab %s to sysfs\n",
s->name);
}
……
}通用缓存
通用缓存就是用kmalloc(size)分配内存的时候使用的缓存,与之对应的由专用缓存,比如用于分配struct inode的专用缓存" inode_cache",。数组kmalloc_info[]包含通用缓存信息,(name,size)的形式。最大可以创建object大小为64M的slub缓存。
const struct kmalloc_info_struct kmalloc_info[] __initconst = {
{NULL, 0}, {"kmalloc-96", 96},
{"kmalloc-192", 192}, {"kmalloc-8", 8},
{"kmalloc-16", 16}, {"kmalloc-32", 32},
{"kmalloc-64", 64}, {"kmalloc-128", 128},
{"kmalloc-256", 256}, {"kmalloc-512", 512},
{"kmalloc-1024", 1024}, {"kmalloc-2048", 2048},
{"kmalloc-4096", 4096}, {"kmalloc-8192", 8192},
{"kmalloc-16384", 16384}, {"kmalloc-32768", 32768},
{"kmalloc-65536", 65536}, {"kmalloc-131072", 131072},
{"kmalloc-262144", 262144}, {"kmalloc-524288", 524288},
{"kmalloc-1048576", 1048576}, {"kmalloc-2097152", 2097152},
{"kmalloc-4194304", 4194304}, {"kmalloc-8388608", 8388608},
{"kmalloc-16777216", 16777216}, {"kmalloc-33554432", 33554432},
{"kmalloc-67108864", 67108864}
};
#define KMALLOC_SHIFT_HIGH (PAGE_SHIFT + 1) //slub中设置最大创建object为两页大小的缓存
struct kmem_cache *kmalloc_caches[KMALLOC_SHIFT_HIGH + 1]; //保存所有通用缓存的kmem_cache指针
size_index[24] 是保存object size小于192的slub缓存在kmalloc_caches[]中的索引,idx = size_index[object size/8],kmalloc_caches[idx]就是对应object size的缓存指针。
static s8 size_index[24] = {
3, /* 8 */
4, /* 16 */
5, /* 24 */
5, /* 32 */
6, /* 40 */
6, /* 48 */
6, /* 56 */
6, /* 64 */
1, /* 72 */
1, /* 80 */
1, /* 88 */
1, /* 96 */
7, /* 104 */
7, /* 112 */
7, /* 120 */
7, /* 128 */
2, /* 136 */
2, /* 144 */
2, /* 152 */
2, /* 160 */
2, /* 168 */
2, /* 176 */
2, /* 184 */
2 /* 192 */
};函数create_kmalloc_caches实现了通用缓存的创建:
void __init create_kmalloc_caches(unsigned long flags)
{
int i;
for (i = KMALLOC_SHIFT_LOW; i <= KMALLOC_SHIFT_HIGH; i++) {
if (!kmalloc_caches[i])
new_kmalloc_cache(i, flags); //创建缓存,i表示在kmalloc_caches[]中的索引
if (KMALLOC_MIN_SIZE <= 32 && !kmalloc_caches[1] && i == 6)
new_kmalloc_cache(1, flags);
if (KMALLOC_MIN_SIZE <= 64 && !kmalloc_caches[2] && i == 7)
new_kmalloc_cache(2, flags);
}
slab_state = UP;
……
}函数create_kmalloc_cache是创建缓存的接口,具体实现后面会将解
static void __init new_kmalloc_cache(int idx, unsigned long flags)
{
kmalloc_caches[idx] = create_kmalloc_cache(kmalloc_info[idx].name,
kmalloc_info[idx].size, flags);
}cat /proc/slabinfo可以看到通用缓存信息:

创建slub缓存
4.1 slub结构框架

slab是一组object的集合,如果缓存中没有空闲内存了,一次从伙伴系统分配一个slab,slab是一个页阶为order的联合页,这个order是根据object大小计算出来的几个最佳值,这个值得计算后面会细讲。
4.2 slub缓存创建流程
创建slub缓存的主要工作就是分配和初始化这三个管理结构:kmem_cache,kmem_cache_node和kmem_cache_cpu。缓存创建的接口是kmem_cache_create。下面以创建缓存"inode_cache"为例说明缓存的创建过程。
void __init inode_init(void)
{
unsigned int loop;
//传入参数分别是缓存名,缓存object大小,对齐大小,分配参数,object构造函数
inode_cachep = kmem_cache_create("inode_cache",
sizeof(struct inode),
0,
(SLAB_RECLAIM_ACCOUNT|SLAB_PANIC|
SLAB_MEM_SPREAD|SLAB_ACCOUNT),
init_once);
……
}缓存创建流程图如下:
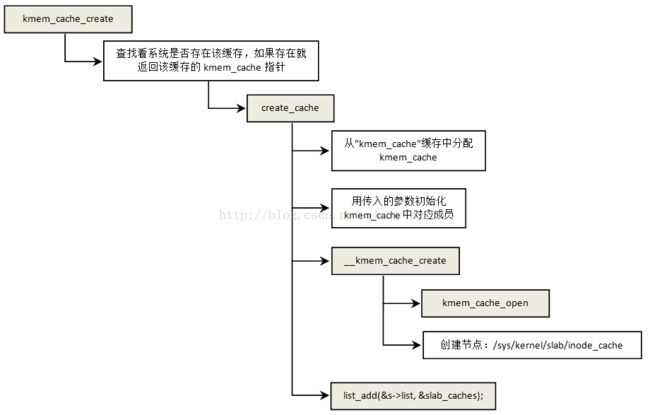
上面流程比较清楚就不过多解释了,唯一需要说明一点的是每个缓存创建之后就会链接到全局链表slab_caches上去。函数kmem_cache_open中进一步初始化kmem_cache中的各个成员。
static int kmem_cache_open(struct kmem_cache *s, unsigned long flags)
{
s->flags = kmem_cache_flags(s->size, flags, s->name, s->ctor);
s->reserved = 0;
//如果设置了SLAB_TYPESAFE_BY_RCU就在slab中预留出用于struct rcu_head的空间
if (need_reserve_slab_rcu && (s->flags & SLAB_TYPESAFE_BY_RCU))
s->reserved = sizeof(struct rcu_head);
//计算slab order,后面详述
if (!calculate_sizes(s, -1))
goto error;
// 设置s->min_partial,如果kmem_cache_node中部slab数量大于这个值就尝试释放掉部分全空闲的slab。
// s->size越大保留的slab数越多,反之月少,因为s->size小一个slab中的object数多
set_min_partial(s, ilog2(s->size) / 2);
//设置s->cpu_partial数,即缓存在per cpu partial中的object数
if (!kmem_cache_has_cpu_partial(s))
s->cpu_partial = 0;
else if (s->size >= PAGE_SIZE)
s->cpu_partial = 2;
else if (s->size >= 1024)
s->cpu_partial = 6;
else if (s->size >= 256)
s->cpu_partial = 13;
else
s->cpu_partial = 30;
//如果slub机制已经建立完成就生成一个随机数组s->random_seq,freelist在slab中随机指向下一个object而不是顺序排列。
if (slab_state >= UP) {
if (init_cache_random_seq(s))
goto error;
}
//分配kmem_cache_nodes并初始化具体实现后面讲解
if (!init_kmem_cache_nodes(s))
goto error;
// 通过函数__alloc_percpu 分配s->cpu_slab
if (alloc_kmem_cache_cpus(s))
return 0;
……
error:
return -EINVAL;
}4.3创建kmem_cache_nodes

kmem_cache_alloc_node : 从"kmem_cache_node"缓存中分配一个kmem_cache_nodes结构。
init_kmem_cache_node :初始化结构kmem_cache_nodes中的成员
当系统启动阶段slub还没有建立起来的时候通过函数early_kmem_cache_node_alloc来分配kmem_cache_nodes结构。系统实现的第一个slub缓存就是"kmem_cache_node",slab_state 等于 DOWN
说明正在创建"kmem_cache_node"缓存,缓存的kmem_cache是静态定义的。具体实现如下:
static void early_kmem_cache_node_alloc(int node)
{
struct page *page;
struct kmem_cache_node *n;
//分配缓存的第一个slab
page = new_slab(kmem_cache_node, GFP_NOWAIT, node);
//slab的第一个object分配给"kmem_cache_node"缓存的kmem_cache_node结构
n = page->freelist;
// 函数get_freepointer 只有一行代码*(void **)(object + s->offset);也就是取下一个空闲object
page->freelist = get_freepointer(kmem_cache_node, n);
page->inuse = 1; //slab中已经使用一个object
page->frozen = 0; //表示该slab不在s->cpu_slab中
// kmem_cache_node是一个全局的指针变量指向"kmem_cache_node"缓存的kmem_cache
kmem_cache_node->node[node] = n;
//初始化kmem_cache_node中各个成员
init_kmem_cache_node(n);
inc_slabs_node(kmem_cache_node, node, page->objects);
//将slab添加到s->node->partial
__add_partial(n, page, DEACTIVATE_TO_HEAD);
}4.4 计算slab order
下图是object在开启了SLUB_DEBUG之后完整的内部结构:

static int calculate_sizes(struct kmem_cache *s, int forced_order)
{
unsigned long flags = s->flags;
size_t size = s->object_size; //一个缓存对象的大小
int order;
//对齐到一个指针大小,比如是object_size6个字节大小对齐之后变成8个字节
size = ALIGN(size, sizeof(void *));
#ifdef CONFIG_SLUB_DEBUG //后面专门开一节来讲解slub debug
//如果设置了SLAB_RED_ZONE,增加用于标识危险区的空间,如果对齐之后的size 和原始s->object_size
//不等就将对齐后的填充空间用于标识危险区,就不用增加额外的空间
if ((flags & SLAB_RED_ZONE) && size == s->object_size)
size += sizeof(void *);
#endif
// inuse标识经过对齐之后的数据区的大小,如果设置了SLAB_RED_ZONE包含危险区
s->inuse = size;
/*如果有下面三个设置就在object后面预留free pointer指针空间,否者就用object的起始位置存放free pointer指针。之所以要额外分配是因为有下面三个设置后object中的内容已经有了其他用途或者不能改变*/
if (((flags & (SLAB_TYPESAFE_BY_RCU | SLAB_POISON)) ||
s->ctor)) {
s->offset = size;
size += sizeof(void *);
}
//如果设置了SLAB_STORE_USER就预留两个struct track用于存放分配和释放的backtrace
#ifdef CONFIG_SLUB_DEBUG
if (flags & SLAB_STORE_USER)
size += 2 * sizeof(struct track);
#endif
//如果设置了SLAB_RED_ZONE需要在左边预留一个区域用于标识危险区,危险区左右都需要
#ifdef CONFIG_SLUB_DEBUG
if (flags & SLAB_RED_ZONE) {
size += sizeof(void *);
s->red_left_pad = sizeof(void *);
s->red_left_pad = ALIGN(s->red_left_pad, s->align);
size += s->red_left_pad;
}
#endif
//对齐
size = ALIGN(size, s->align);
s->size = size; //加上debug区域的缓存对象大小
if (forced_order >= 0)
order = forced_order;
else
order = calculate_order(size, s->reserved); //根据s->size计算slab order大小后面讲解
if (order < 0)
return 0;
s->allocflags = 0;
if (order)
s->allocflags |= __GFP_COMP; //一个slab组成一个联合页
if (s->flags & SLAB_CACHE_DMA)
s->allocflags |= GFP_DMA;
if (s->flags & SLAB_RECLAIM_ACCOUNT)
s->allocflags |= __GFP_RECLAIMABLE;
// s->oo的高16位记录order,低16位记录object数量
s->oo = oo_make(order, size, s->reserved);
s->min = oo_make(get_order(size), size, s->reserved);
if (oo_objects(s->oo) > oo_objects(s->max))
s->max = s->oo;
return !!oo_objects(s->oo);
}根据size计算一个最佳的slab order,最佳的意思就是找出一个order值可以让slab中浪费的内存最少
static inline int calculate_order(int size, int reserved)
{
int order;
int min_objects;
int fraction;
int max_objects;
min_objects = slub_min_objects;
if (!min_objects)
min_objects = 4 * (fls(nr_cpu_ids) + 1); //object最少4倍cpu个数
// slub_max_order等于3,下面计算最大允许的objects数和最少objects数
max_objects = order_objects(slub_max_order, size, reserved);
min_objects = min(min_objects, max_objects);
/*最佳order满足的条件;1)slab中object大于min_objects小于max_objects;2)slab中剩余内存不能超过1/ fraction。如果找不到合适的可以放宽条件,减少min_objects,允许多浪费部分内存*/
while (min_objects > 1) {
fraction = 16;
while (fraction >= 4) {
order = slab_order(size, min_objects,
slub_max_order, fraction, reserved);
if (order <= slub_max_order)
return order;
fraction /= 2;
}
min_objects--;
}
order = slab_order(size, 1, slub_max_order, 1, reserved);
if (order <= slub_max_order)
return order;
//如果order 等于slub_max_order,说明object太大,所以放宽最大order限制到MAX_ORDER重新计算
order = slab_order(size, 1, MAX_ORDER, 1, reserved);
if (order < MAX_ORDER)
return order;
return -ENOSYS;
}Kmalloc
5.1 kmalloc分配流程:

kmalloc_slab(size, flags): 根据size找到在kmalloc_caches[]中找到对应的缓存;
__slab_alloc: 如果per cpu中没有空闲的object了就到s->cpu_slab->partial或者s->node->partial中去分配
static void *___slab_alloc(struct kmem_cache *s, gfp_t gfpflags, int node,
unsigned long addr, struct kmem_cache_cpu *c)
{
void *freelist;
struct page *page;
/*如果是第一次从缓存中分配这里的page为NULL,直接跳转到new_slab去分配一个新的slab,否者这里的page是不为NULL的只不过这个slab中没有空闲的object了*/
page = c->page;
if (!page)
goto new_slab;
redo:
/*slab中的空闲object是以c->freelist为头的单项链表最后一个空闲object的free point为NULL,如果slab分配完了c->freelist就会指向NULL*/
freelist = c->freelist;
if (freelist)
goto load_freelist;
/*如果slab中没有空闲object了这里的get_freelist 会将new.frozen 设置为0,表示slab不在s->cpu_slab中了, 此时的page->freelist也为NULL,然后跳转到new_slab 分配新的slab*/
freelist = get_freelist(s, page);
if (!freelist) {
c->page = NULL;
stat(s, DEACTIVATE_BYPASS);
goto new_slab;
}
stat(s, ALLOC_REFILL);
load_freelist: //已经分配到slab需要重新加载到c->page
c->freelist = get_freepointer(s, freelist);
c->tid = next_tid(c->tid);
return freelist;
new_slab: //c->page中的object已经被分配完了,需要获取新的slab
if (c->partial) {//如果c->partial中有部分空闲的slab就从c->partial中取一个slab到c->page
page = c->page = c->partial;
c->partial = page->next;
stat(s, CPU_PARTIAL_ALLOC);
c->freelist = NULL;
goto redo;
}
//尝试从s->node->partial中去取,如果没有就从伙伴系统中分配并放到c->page
freelist = new_slab_objects(s, gfpflags, node, &c);
page = c->page;
if (likely(!kmem_cache_debug(s) && pfmemalloc_match(page, gfpflags)))
goto load_freelist;
……
return freelist;
} 5.2 分配slab

尝试从s-> n->partial获取slab
static void *get_partial_node(struct kmem_cache *s, struct kmem_cache_node *n,
struct kmem_cache_cpu *c, gfp_t flags)
{
struct page *page, *page2;
void *object = NULL;
int available = 0;
int objects;
if (!n || !n->nr_partial) //如果s-> n->partial中没有slab就返回NULL
return NULL;
spin_lock(&n->list_lock);
list_for_each_entry_safe(page, page2, &n->partial, lru) {
void *t;
if (!pfmemalloc_match(page, flags))
continue;
/*设置 new.frozen = 1,slab的frozen设置为1表示slab在s->cpu_slab->partial或者c->page中。如果object == NULL 表示第一个循环,这个slab将放到c->page中,这种情况new.freelist要设置为NULL,因为slab的freelist要移交给c->freelist来管理*/
t = acquire_slab(s, n, page, object == NULL, &objects);
if (!t)
break;
available += objects;
if (!object) { //取出的第一个slab放到c->page中
c->page = page;
stat(s, ALLOC_FROM_PARTIAL);
object = t;
} else { //如果不是第一个slab就放到s->cpu_slab->partial中
put_cpu_partial(s, page, 0);
stat(s, CPU_PARTIAL_NODE);
}
//如果available大于s->cpu_partial / 2就退出。
if (!kmem_cache_has_cpu_partial(s)
|| available > s->cpu_partial / 2)
break;
}
spin_unlock(&n->list_lock);
return object;
}从伙伴系统中获取slab
static struct page *allocate_slab(struct kmem_cache *s, gfp_t flags, int node)
{
struct page *page;
struct kmem_cache_order_objects oo = s->oo; //slab order
gfp_t alloc_gfp;
void *start, *p;
int idx, order;
bool shuffle;
flags &= gfp_allowed_mask;
if (gfpflags_allow_blocking(flags))
local_irq_enable();
flags |= s->allocflags;
//从伙伴系统中分配一个slab
page = alloc_slab_page(s, alloc_gfp, node, oo);
......
page->objects = oo_objects(oo);
//分配标志设置了__GFP_COMP的,所以一个slab是一个以order阶的联合页
order = compound_order(page);
page->slab_cache = s;
__SetPageSlab(page); //设置页用于slab
if (page_is_pfmemalloc(page))
SetPageSlabPfmemalloc(page);
//获取页的起始地址
start = page_address(page);
if (unlikely(s->flags & SLAB_POISON))
memset(start, POISON_INUSE, PAGE_SIZE << order);
//初始化slab内部freelist,如果有s->random_seq,object的free point指向的下一个空闲object是随机的
shuffle = shuffle_freelist(s, page);
//如果没有s->random_seq就按照前后位置顺序排列freelist
if (!shuffle) {
for_each_object_idx(p, idx, s, start, page->objects) {
setup_object(s, page, p);
if (likely(idx < page->objects))
set_freepointer(s, p, p + s->size);
else
set_freepointer(s, p, NULL);
}
page->freelist = fixup_red_left(s, start);
}
page->inuse = page->objects; //slab将要放到c->page中
page->frozen = 1; //表示slab要放到s->cpu_slab->partial或者c->page中
out:
......
return page;
}Slab freelist

Kfree
6.1将object放到c->page中

6.2将object放到partial
static void __slab_free(struct kmem_cache *s, struct page *page,
void *head, void *tail, int cnt,
unsigned long addr)
{
void *prior;
int was_frozen;
struct page new;
unsigned long counters;
struct kmem_cache_node *n = NULL;
unsigned long uninitialized_var(flags);
…….
do {
prior = page->freelist;
counters = page->counters;
set_freepointer(s, tail, prior);
new.counters = counters;
was_frozen = new.frozen;
new.inuse -= cnt;
if ((!new.inuse || !prior) && !was_frozen) {
/*程序有两种情况会周到这里:1)整个slab都是空闲的new.inuse为0;2)一个被用完了的slab第一次收到有释放的object,page->freelist为NULL说明在c->page中或者已经分配完,frozen为0说明没有在c->page中所以slab是被分配完*/
if (kmem_cache_has_cpu_partial(s) && !prior) {
new.frozen = 1; //如果是第二种情况就设置frozen为1,后面将其加到s->cpu_slab中去
} else { //如果是第一种情况slab将被加入到s->node->partial或者释放到伙伴系统中去
n = get_node(s, page_to_nid(page));
spin_lock_irqsave(&n->list_lock, flags);
}
}
} while (!cmpxchg_double_slab(s, page,
prior, counters,
head, new.counters,
"__slab_free"));//这里将让page->freelist指向head,slab不在s->cpu_slab中所以page->freelist被赋值
if (likely(!n)) {
if (new.frozen && !was_frozen) {//如果是前面提到的第二种情况就将其放到s->cpu_slab中去
put_cpu_partial(s, page, 1); //将slab放到s->cpu_slab中,这个后面讲
stat(s, CPU_PARTIAL_FREE);
}
if (was_frozen)
stat(s, FREE_FROZEN);
return;
}
//如果s->node->partial中的slab超过阀值s->min_partial并且,这次释放使slab变为完全空闲,就将整个slab返还给伙伴系统
if (unlikely(!new.inuse && n->nr_partial >= s->min_partial))
goto slab_empty;
if (!kmem_cache_has_cpu_partial(s) && unlikely(!prior)) {
if (kmem_cache_debug(s))
remove_full(s, n, page);
add_partial(n, page, DEACTIVATE_TO_TAIL);// 将slab添加到s->node->partial
stat(s, FREE_ADD_PARTIAL);
}
spin_unlock_irqrestore(&n->list_lock, flags);
return;
slab_empty:
if (prior) {
remove_partial(n, page); //移除slab
stat(s, FREE_REMOVE_PARTIAL);
} else {
remove_full(s, n, page);
}
spin_unlock_irqrestore(&n->list_lock, flags);
stat(s, FREE_SLAB);
discard_slab(s, page); //将slab返还给伙伴系统
}6.3将slab放到s->cpu_slab
static void put_cpu_partial(struct kmem_cache *s, struct page *page, int drain)
{
#ifdef CONFIG_SLUB_CPU_PARTIAL
struct page *oldpage;
int pages;
int pobjects;
preempt_disable();
do {
pages = 0;
pobjects = 0;
oldpage = this_cpu_read(s->cpu_slab->partial);
if (oldpage) {
pobjects = oldpage->pobjects;
pages = oldpage->pages;
//如果s->cpu_slab中缓存的objects数量多于阀值s->cpu_partial就将s->cpu_slab->partial中的slab释放到s->node->partial中去。
if (drain && pobjects > s->cpu_partial) {
unsigned long flags;
local_irq_save(flags);
unfreeze_partials(s, this_cpu_ptr(s->cpu_slab));
local_irq_restore(flags);
oldpage = NULL;
pobjects = 0;
pages = 0;
stat(s, CPU_PARTIAL_DRAIN);
}
}
pages++;
pobjects += page->objects - page->inuse;
page->pages = pages;
page->pobjects = pobjects;
// oldpage指向s->cpu_slab->partial,page->next指向oldpage,下面s->cpu_slab->partial再指向page,这样就完成将slab插入链表s->cpu_slab->partial
page->next = oldpage;
} while (this_cpu_cmpxchg(s->cpu_slab->partial, oldpage, page)
!= oldpage);
//如果禁止s->cpu_slab->partial中缓存slab就将slab直接放到s->node->partial中
if (unlikely(!s->cpu_partial)) {
unsigned long flags;
local_irq_save(flags);
unfreeze_partials(s, this_cpu_ptr(s->cpu_slab));
local_irq_restore(flags);
}
preempt_enable();
#endif
}6.4将s->cpu_slab->partial释放到s->node->partial中
static void unfreeze_partials(struct kmem_cache *s,
struct kmem_cache_cpu *c)
{
#ifdef CONFIG_SLUB_CPU_PARTIAL
struct kmem_cache_node *n = NULL, *n2 = NULL;
struct page *page, *discard_page = NULL;
while ((page = c->partial)) {
struct page new;
struct page old;
c->partial = page->next; //将slab从s->cpu_slab->partial中取下来
n2 = get_node(s, page_to_nid(page));
if (n != n2) {
if (n)
spin_unlock(&n->list_lock);
n = n2;
spin_lock(&n->list_lock);
}
do {
old.freelist = page->freelist;
old.counters = page->counters;
VM_BUG_ON(!old.frozen);
new.counters = old.counters;
new.freelist = old.freelist;
new.frozen = 0; //slab将从s->cpu_slab->partial中移除所以将frozen设置为0
} while (!__cmpxchg_double_slab(s, page,
old.freelist, old.counters,
new.freelist, new.counters,
"unfreezing slab"));
//如果s->node->partial中的slab超过阀值s->min_partial并且,而且slab为完全空闲,就将整个slab返还给伙伴系统
if (unlikely(!new.inuse && n->nr_partial >= s->min_partial)) {
page->next = discard_page;
discard_page = page;
} else {//否者就将slab释放到s->node->partial中去
add_partial(n, page, DEACTIVATE_TO_TAIL);
stat(s, FREE_ADD_PARTIAL);
}
}
if (n)
spin_unlock(&n->list_lock);
while (discard_page) { //将完全空闲的slab释放到伙伴系统中去
page = discard_page;
discard_page = discard_page->next;
stat(s, DEACTIVATE_EMPTY);
discard_slab(s, page);
stat(s, FREE_SLAB);
}
#endif
}