《redis设计与实现》-第7章压缩列表ziplist
一 序
压缩列表是 Redis 为了节约内存而开发的(上一篇还看了intset,都是时间换空间吧), 由一系列特殊编码的连续内存块组成的顺序型(sequential)数据结构。书上分了两部分:介绍结构及连锁更新。本文也是从结构及API源码两部分。
ziplist是hash键以及zset键的底层实现之一(3.0之后list键已经不直接用ziplist和linkedlist作为底层实现了,取而代之的是quicklist),当元素较少、并且每个元素要么是小整数要么是长度较小的字符串时hash,zset就采用ziplist,主要是为了节省内存。
二 数据结构
2.1 ziplist
ziplist并没有定义明确的结构体, 通常的ziplist.h跟其他位置没有定义
#ifndef _ZIPLIST_H
#define _ZIPLIST_H
#define ZIPLIST_HEAD 0
#define ZIPLIST_TAIL 1
unsigned char *ziplistNew(void);
unsigned char *ziplistMerge(unsigned char **first, unsigned char **second);
unsigned char *ziplistPush(unsigned char *zl, unsigned char *s, unsigned int slen, int where);
unsigned char *ziplistIndex(unsigned char *zl, int index);
unsigned char *ziplistNext(unsigned char *zl, unsigned char *p);
unsigned char *ziplistPrev(unsigned char *zl, unsigned char *p);
unsigned int ziplistGet(unsigned char *p, unsigned char **sval, unsigned int *slen, long long *lval);
unsigned char *ziplistInsert(unsigned char *zl, unsigned char *p, unsigned char *s, unsigned int slen);
unsigned char *ziplistDelete(unsigned char *zl, unsigned char **p);
unsigned char *ziplistDeleteRange(unsigned char *zl, int index, unsigned int num);
unsigned int ziplistCompare(unsigned char *p, unsigned char *s, unsigned int slen);
unsigned char *ziplistFind(unsigned char *p, unsigned char *vstr, unsigned int vlen, unsigned int skip);
unsigned int ziplistLen(unsigned char *zl);
size_t ziplistBlobLen(unsigned char *zl);看到ziplist.h只是定义了接口。根据ziplist.c zlentry节点,还有操作api,认为它的结构如下:
一个压缩列表可以包含任意多个节点(entry), 每个节点可以保存一个字节数组或者一个整数值。
下图展示了压缩列表的各个组成部分

各个组成部分的类型、长度、以及用途。
| 属性 | 类型 | 长度 | 用途 |
|---|---|---|---|
zlbytes |
uint32_t |
4 字节 |
记录整个压缩列表占用的内存字节数:在对压缩列表进行内存重分配, 或者计算 zlend的位置时使用。 |
zltail |
uint32_t |
4 字节 |
记录压缩列表表尾节点距离压缩列表的起始地址有多少字节: 通过这个偏移量,程序无须遍历整个压缩列表就可以确定表尾节点的地址。 |
zllen |
uint16_t |
2 字节 |
记录了压缩列表包含的节点数量: 当这个属性的值小于 UINT16_MAX (65535)时, 这个属性的值就是压缩列表包含节点的数量; 当这个值等于 UINT16_MAX 时, 节点的真实数量需要遍历整个压缩列表才能计算得出。 |
entryX |
列表节点 | 不定 | 压缩列表包含的各个节点,节点的长度由节点保存的内容决定。 |
zlend |
uint8_t |
1 字节 |
特殊值 0xFF (十进制 255 ),用于标记压缩列表的末端。 |
书上还举个实例:
- 列表
zlbytes属性的值为0x50(十进制80), 表示压缩列表的总长为80字节。 - 列表
zltail属性的值为0x3c(十进制60), 这表示如果我们有一个指向压缩列表起始地址的指针p, 那么只要用指针p加上偏移量60, 就可以计算出表尾节点entry3的地址。 - 列表
zllen属性的值为0x3(十进制3), 表示压缩列表包含三个节点。 
创建一个新的ziplist:
/* Create a new empty ziplist. */
unsigned char *ziplistNew(void) { //创建并返回一个新的压缩列表
//ZIPLIST_HEADER_SIZE是压缩列表的表头大小,1字节是末端的end大小
unsigned int bytes = ZIPLIST_HEADER_SIZE+1;
unsigned char *zl = zmalloc(bytes); //为表头和表尾end成员分配空间
ZIPLIST_BYTES(zl) = intrev32ifbe(bytes); //将bytes成员初始化为bytes=11
ZIPLIST_TAIL_OFFSET(zl) = intrev32ifbe(ZIPLIST_HEADER_SIZE); //空列表的tail_offset成员为表头大小为10
ZIPLIST_LENGTH(zl) = 0; //节点数量为0
zl[bytes-1] = ZIP_END; //将表尾end成员设置成默认的255
return zl;
}接下来我们看看节点的结构。
2.2 节点
typedef struct zlentry {
// prevrawlen :前置节点的长度
// prevrawlensize :编码 prevrawlen 所需的字节大小
unsigned int prevrawlensize, prevrawlen;
// len :当前节点值的长度
// lensize :编码 len 所需的字节大小
unsigned int lensize, len;
// 当前节点 header 的大小
// 等于 prevrawlensize + lensize
unsigned int headersize;
// 当前节点值所使用的编码类型
unsigned char encoding;
// 指向当前节点的指针
unsigned char *p;
} zlentry;虽然定义了结构体,但是没有真正的使用,因为用来存储短字节跟整数太浪费内存了,所以实际如下:
每个压缩列表节点都由 previous_entry_length 、 encoding 、 content 三个部分组成

2.2.1 previous_entry_length :
节点的 previous_entry_length 属性以字节为单位, 记录了压缩列表中前一个节点的长度。
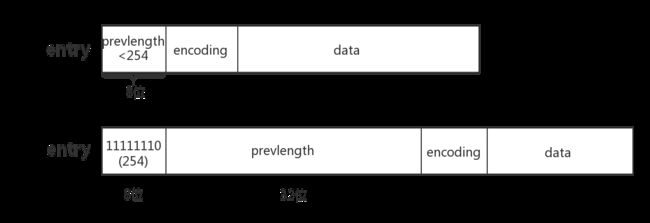
zlentry中prevrawlen进行了压缩编码, 如果字段小于254, 则直接用一个字节保存, 如果大于254字节, 则使用5个字节进行保存, 第一个字节固定值254(0xFE )标示prev_entry_len占用了5个字节, 后面四个字节才是真正保存长度值prevlength.
因为,对于访问的指针都是char 类型,它能访问的范围1个字节,如果这个字节的大小等于0xFE,那么就会继续访问四个字节来获取前驱节点的长度,如果该字节的大小小于0xFE,那么该字节就是要获取的前驱节点的长度。因此这样就使prev_entry_len同时具有了prevrawlen和prevrawlensize的功能,而且更加节约内存。看下代码:
//对前驱节点的长度len进行编码,并写入p中,如果p为空,则仅仅返回编码len所需要的字节数
static unsigned int zipPrevEncodeLength(unsigned char *p, unsigned int len) {
// 仅返回编码 len 所需的字节数量
if (p == NULL) {
return (len < ZIP_BIGLEN) ? 1 : sizeof(len)+1; //如果前驱节点的长度len字节小于254则返回1个字节,否则返回5个
} else {
if (len < ZIP_BIGLEN) { //如果前驱节点的长度len字节小于254
p[0] = len; //将len保存在p[0]中
return 1; //返回所需的编码数1字节
} else { //前驱节点的长度len大于等于255字节
p[0] = ZIP_BIGLEN; //添加5字节的标示,0xFE
memcpy(p+1,&len,sizeof(len)); //从p+1的起始地址开始拷贝len,拷贝四个字节
memrev32ifbe(p+1);
return 1+sizeof(len); //返回所需的编码数5字节
}
}代码里面的ZIP_BIGLEN是254,sizeof(254)=4. 为啥用254作为为分界是因为255是zlend的值,它用于判断ziplist是否到达尾部。举个例子, 如果我们有一个指向当前节点起始地址的指针 c , 那么我们只要用指针 c 减去当前节点 previous_entry_length 属性的值, 就可以得出一个指向前一个节点起始地址的指针 p , 如图所示:
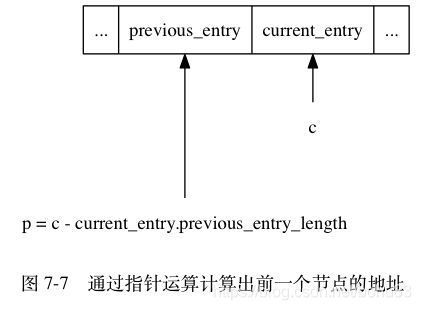
压缩列表的从表尾向表头遍历操作就是使用这一原理实现的: 只要我们拥有了一个指向某个节点起始地址的指针, 那么通过这个指针以及这个节点的 previous_entry_length 属性, 程序就可以一直向前一个节点回溯, 最终到达压缩列表的表头节点。
2.2.2 编码encoding
和prev_entry_len一样,encoding成员同样可以看做成zlentry结构中lensize和len的压缩版。 节点的 encoding 属性记录了节点的 content 属性所保存数据的类型以及长度。
- len:当前节点值长度。
- lensize: 编码当前节点长度len所需的字节数。
同样的lensize和len都是占4个字节的,因此将两者压缩为一个成员encoding,只要encoding能够同时具有lensize和len成员的功能,而且对当前节点保存的是字节数组还是整数分别编码。
- 一字节、两字节或者五字节长, 值的最高位为
00、01或者10的是字节数组编码: 这种编码表示节点的content属性保存着字节数组, 数组的长度由编码除去最高两位之后的其他位记录; - 一字节长, 值的最高位以
11开头的是整数编码: 这种编码表示节点的content属性保存着整数值, 整数值的类型和长度由编码除去最高两位之后的其他位记录;
我们分别对于字节数组和整数进行讨论:
下表记录了所有可用的字节数组编码. 表格中的下划线 _ 表示留空, 而 b 、 x 等变量则代表实际的二进制数据, 为了方便阅读, 多个字节之间用空格隔开。
| 编码 | 编码长度 | content 属性保存的值 |
|---|---|---|
00bbbbbb |
1 字节 |
长度小于等于 63 字节的字节数组。 |
01bbbbbb xxxxxxxx |
2 字节 |
长度小于等于 16383 字节的字节数组。 |
10______ aaaaaaaa bbbbbbbb cccccccc dddddddd |
5 字节 |
长度小于等于 4294967295 的字节数组。 |
字节数组的长度可以是:1字节,2字节,5字节。编码范围的前两位分别是00,01,10,因此除去最高2位用来区别编码长度,剩下的位则用来表示value成员的长度
//从ptr中取出节点信息,并将其保存在encoding、lensize和len中
#define ZIP_DECODE_LENGTH(ptr, encoding, lensize, len) do { \
/*从ptr数组中取出节点的编码格式并将其赋值给encoding*/ \
ZIP_ENTRY_ENCODING((ptr), (encoding)); \
/*如果是字符串编码格式*/ \
if ((encoding) < ZIP_STR_MASK) { \
if ((encoding) == ZIP_STR_06B) { /*6位字符串编码格式*/ \
(lensize) = 1; /*编码长度需要1个字节*/ \
(len) = (ptr)[0] & 0x3f; /*当前字节长度保存到len中*/ \
} else if ((encoding) == ZIP_STR_14B) { /*14位字符串编码格式*/ \
(lensize) = 2; /*编码长度需要2个字节*/ \
(len) = (((ptr)[0] & 0x3f) << 8) | (ptr)[1]; /*当前字节长度保存到len中*/ \
} else if (encoding == ZIP_STR_32B) { /*32串编码格式*/ \
(lensize) = 5; /*编码长度需要5节*/ \
(len) = ((ptr)[1] << 24) | /*当前字节长度保存到len中*/ \
((ptr)[2] << 16) | \
((ptr)[3] << 8) | \
((ptr)[4]); \
} else { \
assert(NULL); \
} \
} else { /*整数编码格式*/ \
(lensize) = 1; /*需要1个字节*/ \
(len) = zipIntSize(encoding); \
} \
} while(0);再看下整数:
下表记录了所有可用的整数编码
| 编码 | 编码长度 | content 属性保存的值 |
|---|---|---|
11000000 |
1 字节 |
int16_t 类型的整数。 |
11010000 |
1 字节 |
int32_t 类型的整数。 |
11100000 |
1 字节 |
int64_t 类型的整数。 |
11110000 |
1 字节 |
24 位有符号整数。 |
11111110 |
1 字节 |
8 位有符号整数。 |
1111xxxx |
1 字节 |
使用这一编码的节点没有相应的 content 属性, 因为编码本身的 xxxx 四个位已经保存了一个介于 0 和 12之间的值, 所以它无须 content 属性。 |
看下源码:
- 整数节点的encoding的长度为8位,其中高2位用来区分整数节点和字符串节点(高2位为11时是整数节点),低6位用来区分整数节点的类型,定义如下:
#define ZIP_STR_MASK 0xc0 //1100 0000 字节数组的掩码
#define ZIP_STR_06B (0 << 6) //0000 0000
#define ZIP_STR_14B (1 << 6) //0100 0000
#define ZIP_STR_32B (2 << 6) //1000 0000
#define ZIP_INT_MASK 0x30 //0011 0000 整数的掩码
#define ZIP_INT_16B (0xc0 | 0<<4) //1100 0000
#define ZIP_INT_32B (0xc0 | 1<<4) //1101 0000
#define ZIP_INT_64B (0xc0 | 2<<4) //1110 0000
#define ZIP_INT_24B (0xc0 | 3<<4) //1111 0000
#define ZIP_INT_8B 0xfe //1111 1110
/* 4 bit integer immediate encoding |1111xxxx| with xxxx between
* 0001 and 1101. */
//整数值1~13的节点没有data,encoding的低四位用来表示data
#define ZIP_INT_IMM_MASK 0x0f
#define ZIP_INT_IMM_MIN 0xf1 /* 11110001 */
#define ZIP_INT_IMM_MAX 0xfd /* 11111101 */
//掩码个功能就是区分一个encoding是字节数组编码还是整数编码
//如果这个宏返回 1 就代表该enc是字节数组,如果是 0 就代表是整数的编码
#define ZIP_IS_STR(enc) (((enc) & ZIP_STR_MASK) < ZIP_STR_MASK)真的很好的利用了位移。
//以encoding编码方式,将value写到p中
static void zipSaveInteger(unsigned char *p, int64_t value, unsigned char encoding) {
int16_t i16;
int32_t i32;
int64_t i64;
// 根据encoding的编码格式不同,将value写到p中
if (encoding == ZIP_INT_8B) {
((int8_t*)p)[0] = (int8_t)value;
} else if (encoding == ZIP_INT_16B) {
i16 = value;
memcpy(p,&i16,sizeof(i16));
memrev16ifbe(p);
} else if (encoding == ZIP_INT_24B) {
i32 = value<<8;
memrev32ifbe(&i32);
memcpy(p,((uint8_t*)&i32)+1,sizeof(i32)-sizeof(uint8_t));
} else if (encoding == ZIP_INT_32B) {
i32 = value;
memcpy(p,&i32,sizeof(i32));
memrev32ifbe(p);
} else if (encoding == ZIP_INT_64B) {
i64 = value;
memcpy(p,&i64,sizeof(i64));
memrev64ifbe(p);
} else if (encoding >= ZIP_INT_IMM_MIN && encoding <= ZIP_INT_IMM_MAX) {
/* Nothing to do, the value is stored in the encoding itself. */
} else {
assert(NULL);
}
}
/* Read integer encoded as 'encoding' from 'p'
*
* 以 encoding 指定的编码方式,读取并返回指针 p 中的整数值。
*
* T = O(1)
*/
int64_t zipLoadInteger(unsigned char *p, unsigned char encoding) {
int16_t i16;
int32_t i32;
int64_t i64, ret = 0;
if (encoding == ZIP_INT_8B) {
ret = ((int8_t*)p)[0];
} else if (encoding == ZIP_INT_16B) {
memcpy(&i16,p,sizeof(i16));
memrev16ifbe(&i16);
ret = i16;
} else if (encoding == ZIP_INT_32B) {
memcpy(&i32,p,sizeof(i32));
memrev32ifbe(&i32);
ret = i32;
} else if (encoding == ZIP_INT_24B) {
i32 = 0;
memcpy(((uint8_t*)&i32)+1,p,sizeof(i32)-sizeof(uint8_t));
memrev32ifbe(&i32);
ret = i32>>8;
} else if (encoding == ZIP_INT_64B) {
memcpy(&i64,p,sizeof(i64));
memrev64ifbe(&i64);
ret = i64;
} else if (encoding >= ZIP_INT_IMM_MIN && encoding <= ZIP_INT_IMM_MAX) {
ret = (encoding & ZIP_INT_IMM_MASK)-1;
} else {
assert(NULL);
}
return ret;
}save是比较好理解,我一开始看load的时候,对于为啥要 (encoding & ZIP_INT_IMM_MASK)-1不理解。
这项特殊:编码和content是放在一起,该项bbbb表示实际的数据项,由于0xff与zipend冲突,0xfe与int8_t编码冲突,ox10与ZIP_INT_24B冲突,所以encoding大小介于ZIP_INT_24B与ZIP_INT_8B之间(1~13)。仔细看了下ZIP_INT_IMM_MIN(11110001),ZIP_INT_IMM_MAX(11111101), 跟掩码ZIP_INT_IMM_MASK(1111)按位与计算就只剩后四位了,就是0001-1101,也就是1-13,为了表示0-12只能-1.
2.2.3 content
节点的 content 属性负责保存节点的值, 节点值可以是一个字节数组或者整数, 值的类型和长度由节点的 encoding 属性决定。
下图展示了一个保存字节数组的节点示例:
- 编码的最高两位
00表示节点保存的是一个字节数组; - 编码的后六位
001011记录了字节数组的长度11; content属性保存着节点的值"hello world"。

三 ziplist API
3.1 ziplistFind
从ziplist里找出一个entry O(n)
//返回p节点之后data与vstr(长度是vlen)相等的节点,只找p节点之后每隔skip的节点
//时间复杂度 O(n)
unsigned char *ziplistFind(unsigned char *p, unsigned char *vstr, unsigned int vlen, unsigned int skip) {
int skipcnt = 0;
unsigned char vencoding = 0;
long long vll = 0;
while (p[0] != ZIP_END) {
unsigned int prevlensize, encoding, lensize, len;
unsigned char *q;
ZIP_DECODE_PREVLENSIZE(p, prevlensize);
ZIP_DECODE_LENGTH(p + prevlensize, encoding, lensize, len);
q = p + prevlensize + lensize;//当前节点的data
if (skipcnt == 0) {
/* Compare current entry with specified entry */
if (ZIP_IS_STR(encoding)) {//判断当前节点是不是字符串节点,如果没有编码,直接以字符串形式比较
if (len == vlen && memcmp(q, vstr, vlen) == 0) {
return p;
}
} else {
/* Find out if the searched field can be encoded. Note that
* we do it only the first time, once done vencoding is set
* to non-zero and vll is set to the integer value. */
// 因为传入值有可能被编码了,
// 所以当第一次进行值对比时,程序会对传入值进行解码
// 这个解码操作只会进行一次
if (vencoding == 0) {
if (!zipTryEncoding(vstr, vlen, &vll, &vencoding)) {
//将参数给的节点vstr当做整数节点转换;将data值返回给vll,节点编码返回给vencoding
//进入这个代码块说明将vstr转换成整数失败,vencoding不变,下次判断当前节点是整数节点之后可以跳过这个节点
/* If the entry can't be encoded we set it to
* UCHAR_MAX so that we don't retry again the next
* time. */
vencoding = UCHAR_MAX;//当前节点是整数节点,但是vstr是字符串节点,跳过不用比较了
}
/* Must be non-zero by now */
assert(vencoding);
}
/* Compare current entry with specified entry, do it only
* if vencoding != UCHAR_MAX because if there is no encoding
* possible for the field it can't be a valid integer. */
// 对比整数值
if (vencoding != UCHAR_MAX) {
long long ll = zipLoadInteger(q, encoding);//算出当前节点的data
if (ll == vll) {
return p;
}
}
}
/* Reset skip count */
skipcnt = skip;
} else {
/* Skip entry */
skipcnt--;
}
/* Move to next entry */
p = q + len; // 后移指针,指向后置节点
}
return NULL;
}3.2 插入节点
可以调用ziplistpush 或者ziplistInsert,二者的区别在于push只能在列表头部或尾部插入,而insert则可以在任意位置插入 。这两个函数最终都是通过调用__ziplistInsert来完成插入操作的。
/*
* 将长度为 slen 的字符串 s 推入到 zl 中。
*
* where 参数的值决定了推入的方向:
* - 值为 ZIPLIST_HEAD 时,将新值推入到表头。
* - 否则,将新值推入到表末端。
*
* 函数的返回值为添加新值后的 ziplist 。
*
* T = O(N^2)
*/
unsigned char *ziplistPush(unsigned char *zl, unsigned char *s, unsigned int slen, int where) {
// 根据 where 参数的值,决定将值推入到表头还是表尾
unsigned char *p;
p = (where == ZIPLIST_HEAD) ? ZIPLIST_ENTRY_HEAD(zl) : ZIPLIST_ENTRY_END(zl);
// 返回添加新值后的 ziplist
// T = O(N^2)
return __ziplistInsert(zl,p,s,slen);
}
/* Insert item at "p". */
/*
* 根据指针 p 所指定的位置,将长度为 slen 的字符串 s 插入到 zl 中。
*
* 函数的返回值为完成插入操作之后的 ziplist
*
* T = O(N^2)
*/
unsigned char *__ziplistInsert(unsigned char *zl, unsigned char *p, unsigned char *s, unsigned int slen) {
size_t curlen = intrev32ifbe(ZIPLIST_BYTES(zl)), reqlen; // 记录当前 ziplist 的长度
unsigned int prevlensize, prevlen = 0;
size_t offset;
int nextdiff = 0;
unsigned char encoding = 0;
long long value = 123456789; /* initialized to avoid warning. Using a value
that is easy to see if for some reason
we use it uninitialized. */
zlentry tail;
/* Find out prevlen for the entry that is inserted. */
if (p[0] != ZIP_END) { // 如果不是在尾部插入
ZIP_DECODE_PREVLEN(p, prevlensize, prevlen); // 获取prevlen
} else { // 在尾部插入
unsigned char *ptail = ZIPLIST_ENTRY_TAIL(zl); // 获取最后一个entry
if (ptail[0] != ZIP_END) { // 如果ziplist不为空
prevlen = zipRawEntryLength(ptail); // prevlen就是最后一个enrty的长度
}
}
/* See if the entry can be encoded */
if (zipTryEncoding(s,slen,&value,&encoding)) { // 尝试对value进行整数编码
/* 'encoding' is set to the appropriate integer encoding */
reqlen = zipIntSize(encoding); // 数据长度
} else {
/* 'encoding' is untouched, however zipEncodeLength will use the
* string length to figure out how to encode it. */
reqlen = slen; // 字符数组长度
}
/* We need space for both the length of the previous entry and
* the length of the payload. */
reqlen += zipPrevEncodeLength(NULL,prevlen); // 获取前一个节点的长度prevlen
reqlen += zipEncodeLength(NULL,encoding,slen); // 获取存储encoding需要的编码长度
/* When the insert position is not equal to the tail, we need to
* make sure that the next entry can hold this entry's length in
* its prevlen field. */
int forcelarge = 0;
nextdiff = (p[0] != ZIP_END) ? zipPrevLenByteDiff(p,reqlen) : 0; // 如果不在尾部插入,需要判断当前prelen大小是否够用,否会引起后面节点的长度变化
if (nextdiff == -4 && reqlen < 4) { // 如果当前节点prelen为5个字节或1个字节已经够用
nextdiff = 0;
forcelarge = 1;
}
/* Store offset because a realloc may change the address of zl. */
offset = p-zl; // 记录偏移量,因为realloc可能会改变ziplist的地址
zl = ziplistResize(zl,curlen+reqlen+nextdiff); // 重新申请内存
p = zl+offset; // 拿到p指针
/* Apply memory move when necessary and update tail offset. */
if (p[0] != ZIP_END) { // 不是在尾部插入
/* Subtract one because of the ZIP_END bytes */
memmove(p+reqlen,p-nextdiff,curlen-offset-1+nextdiff); // 通过内存拷贝将原有数据后移,因为移动前后内存地址有重叠需要用memmove
/* Encode this entry's raw length in the next entry. */
if (forcelarge)
zipPrevEncodeLengthForceLarge(p+reqlen,reqlen); // 当下一个节点的prelen空间已经够用时,不需要压缩,防止连锁更新
else
zipPrevEncodeLength(p+reqlen,reqlen); // 将reqlen保存到后一个节点中
/* Update offset for tail */
ZIPLIST_TAIL_OFFSET(zl) =
intrev32ifbe(intrev32ifbe(ZIPLIST_TAIL_OFFSET(zl))+reqlen); // 更新tail值
zipEntry(p+reqlen, &tail);
if (p[reqlen+tail.headersize+tail.len] != ZIP_END) { // 如果下一个节点的prelen扩展了需要加上nextdiff
ZIPLIST_TAIL_OFFSET(zl) =
intrev32ifbe(intrev32ifbe(ZIPLIST_TAIL_OFFSET(zl))+nextdiff);
}
} else { // 如果是在尾部插入直接更新tail_offset
/* This element will be the new tail. */
ZIPLIST_TAIL_OFFSET(zl) = intrev32ifbe(p-zl);
}
if (nextdiff != 0) { // 连锁更新
offset = p-zl; // 记录offset预防地址变更
zl = __ziplistCascadeUpdate(zl,p+reqlen);
p = zl+offset;
}
/* Write the entry */
p += zipPrevEncodeLength(p,prevlen); // 记录prelen
p += zipEncodeLength(p,encoding,slen); // 记录encoding和len
if (ZIP_IS_STR(encoding)) { // 保存字符串
memcpy(p,s,slen);
} else { // 保存数字
zipSaveInteger(p,value,encoding);
}
ZIPLIST_INCR_LENGTH(zl,1); // ziplist的len加1
return zl;
}插入的大致流程如下:
- 获取p指针的prelen,判断插入点是不是尾部
- 根据prelen值计算当前带插入节点的reqlen
- 校验p指针对应的节点的prelen是否够reqlen使用,不够需要扩展,够不进行压缩
- 重新申请内存,如果不是在尾部插入需要将对应数据后移
- 更新ziplist的tailoffset值
- 尝试进行连锁更新
- 保存当前节点,分表保存prevlen、encoding、对应内容
- ziplist的len加1
3.3 连锁更新
当加入新节点后,后一个节点需要保存新节点的长度信息,当后一个节点的长度字段在内存中占有的长度不足以表示该长度信息时,就需要对后一个节点进行更新,并扩展其内存。因此这个步骤可能会导致连锁更新。而删除操作也类似。书上花了图来介绍:
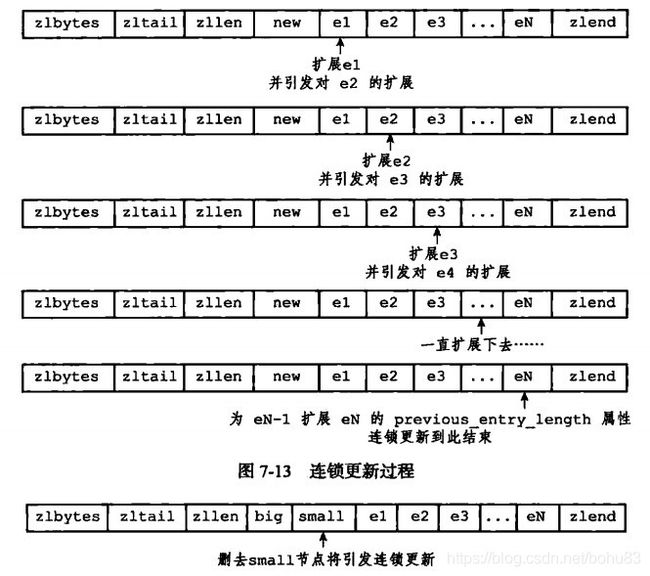
看下代码:
/* When an entry is inserted, we need to set the prevlen field of the next
* entry to equal the length of the inserted entry. It can occur that this
* length cannot be encoded in 1 byte and the next entry needs to be grow
* a bit larger to hold the 5-byte encoded prevlen. This can be done for free,
* because this only happens when an entry is already being inserted (which
* causes a realloc and memmove). However, encoding the prevlen may require
* that this entry is grown as well. This effect may cascade throughout
* the ziplist when there are consecutive entries with a size close to
* ZIP_BIGLEN, so we need to check that the prevlen can be encoded in every
* consecutive entry.
*
* 当将一个新节点添加到某个节点之前的时候,
* 如果原节点的 header 空间不足以保存新节点的长度,
* 那么就需要对原节点的 header 空间进行扩展(从 1 字节扩展到 5 字节)。
*
* 但是,当对原节点进行扩展之后,原节点的下一个节点的 prevlen 可能出现空间不足,
* 这种情况在多个连续节点的长度都接近 ZIP_BIGLEN 时可能发生。
*
* 这个函数就用于检查并修复后续节点的空间问题。
*
* Note that this effect can also happen in reverse, where the bytes required
* to encode the prevlen field can shrink. This effect is deliberately ignored,
* because it can cause a "flapping" effect where a chain prevlen fields is
* first grown and then shrunk again after consecutive inserts. Rather, the
* field is allowed to stay larger than necessary, because a large prevlen
* field implies the ziplist is holding large entries anyway.
*
* 反过来说,
* 因为节点的长度变小而引起的连续缩小也是可能出现的,
* 不过,为了避免扩展-缩小-扩展-缩小这样的情况反复出现(flapping,抖动),
* 我们不处理这种情况,而是任由 prevlen 比所需的长度更长。
* The pointer "p" points to the first entry that does NOT need to be
* updated, i.e. consecutive fields MAY need an update.
*
* 注意,程序的检查是针对 p 的后续节点,而不是 p 所指向的节点。
* 因为节点 p 在传入之前已经完成了所需的空间扩展工作。
* */
unsigned char *__ziplistCascadeUpdate(unsigned char *zl, unsigned char *p) {
size_t curlen = intrev32ifbe(ZIPLIST_BYTES(zl)), rawlen, rawlensize; //cur保存当前列表的总字节数
size_t offset, noffset, extra;
unsigned char *np;
zlentry cur, next;
while (p[0] != ZIP_END) {//只要没有到压缩列表的end成员就继续循环
zipEntry(p, &cur); //将p指向的节点信息保存到cur结构中
rawlen = cur.headersize + cur.len; // 当前节点的长度
rawlensize = zipPrevEncodeLength(NULL,rawlen); // 计算编码当前节点的长度所需的字节数
/* Abort if there is no next entry. */
if (p[rawlen] == ZIP_END) break; // 到结尾了,跳出
zipEntry(p+rawlen, &next); // 取出后续节点的信息,保存到 next 结构中
/* Abort when "prevlen" has not changed. */
// 后续节点编码当前节点的空间已经足够,无须再进行任何处理,跳出
// 可以证明,只要遇到一个空间足够的节点,
// 那么这个节点之后的所有节点的空间都是足够的,第2个跳出条件
if (next.prevrawlen == rawlen) break;
if (next.prevrawlensize < rawlensize) {
/* The "prevlen" field of "next" needs more bytes to hold
* the raw length of "cur". */
// 执行到这里,表示 next 空间的大小不足以编码 cur 的长度
// 所以程序需要对 next 节点的(header 部分)空间进行扩展
offset = p-zl; // 记录 p 的偏移量
extra = rawlensize-next.prevrawlensize; //需要扩展的字节数
zl = ziplistResize(zl,curlen+extra); //调整压缩链表的空间大小
p = zl+offset; // 还原指针 p位置
/* Current pointer and offset for next element. */
np = p+rawlen; // 记录next节点的新地址
noffset = np-zl; //记录next节点的偏移量
/* Update tail offset when next element is not the tail element. */
//更新压缩列表的表头tail_offset成员,如果next节点是尾部节点就不用更新
if ((zl+intrev32ifbe(ZIPLIST_TAIL_OFFSET(zl))) != np) {
ZIPLIST_TAIL_OFFSET(zl) =
intrev32ifbe(intrev32ifbe(ZIPLIST_TAIL_OFFSET(zl))+extra);
}
/* Move the tail to the back. */
//移动next节点到新地址,为前驱节点cur腾出空间
memmove(np+rawlensize,
np+next.prevrawlensize,
curlen-noffset-next.prevrawlensize-1);
zipPrevEncodeLength(np,rawlen);
/* Advance the cursor */
p += rawlen; //更新p指针,移动到next节点,处理下下个节点
curlen += extra; //更新压缩列表的总字节数
} else {
//如果next节点的prevrawlensize足够对前驱节点cur进行编码,但是不会进行缩小
if (next.prevrawlensize > rawlensize) {
/* This would result in shrinking, which we want to avoid.
* So, set "rawlen" in the available bytes. */
//执行到这里说明, next 节点编码前置节点的 header 空间有 5 字节,而编码 rawlen 只需要 1 字节
//因此,用5字节的空间将1字节的编码重新编码
zipPrevEncodeLengthForceLarge(p+rawlen,rawlen);
} else {
//执行到这里说明,next.prevrawlensize = rawlensize
//刚好足够空间进行编码,只需更新next节点的header
zipPrevEncodeLength(p+rawlen,rawlen);
}
/* Stop here, as the raw length of "next" has not changed. */
break;
}
}
return zl;
}
- 添加新节点到压缩列表, 或者从压缩列表中删除节点, 可能会引发连锁更新操作, 但这种操作出现的几率并不高。本身数据量小,所以性能还是有保障的。
剩余的限于篇幅不在注意列出。
总结:
看书上介绍会觉得ziplist相对其他类型代码简单,但其中所涉及的内容还是十分多的,为了节省内存只是无所不用,看起来费劲,通过不同的编码方式,使得ziplist可以用十分高效的方法存储整数和字符串,从而节省内存;并且由于**ziplist是内存连续,因此载入缓存速度将会很快。
越发有个感觉,书上只是侧重介绍概念,大的流程,真的自己看代码跟读书不一会回事,经常看不懂,不知啥为啥。网上别人写一堆,都跟你自己的无关。
| function | description | time complexity | |
|---|---|---|---|
| ziplistNew | 创建一个新的压缩列表 | O(1) | |
| ziplistPush | 创建一个新节点,并防止到ziplist的表头或表尾 | 平均O(N),最坏O(N^2) | |
| ziplistIndex | 返回给定位置的节点 | O(N) | |
| ziplistnext | 返回给定节点的下一个节点 | O(1) | |
| ziplistPrev | 返回给定节点的前一个节点 | O(1) | |
| ziplistGet | 返回给定节点的值 | O(1) | |
| ziplistInsert | 创建一个节点,并放置到指定位置 | 平均O(N),最坏O(N^2) | |
| ziplistDelete | 删除给定节点 | 平均O(N),最坏O(N^2) | |
| ziplistDeleteRange | 删除连续多个节点 | 平均O(N),最坏O(N^2) | |
| ziplistFind | 查找并返回节点 | 需要遍历列表并逐个比较,因此O(N^2) | |
| ziplistLen | 返回列表节点数量 | 数量小于0xfffe时O(1),否则O(N) |
参考:
https://www.jianshu.com/p/afaf78aaf615
https://www.cnblogs.com/ourroad/p/4896387.html
https://blog.csdn.net/men_wen/article/details/70176753
https://www.jianshu.com/p/a634c14ba49c