不再错过短视频风口,用python一键生成短视频,就是这么简单!
最近在网上查资料,正好看到百度开放平台又解锁一项能力【图文生成视频】。
利用这个api接口,可以可以把你的图文自动生成一个视频,完全不需要再借助其他任何的软件。
不过目前能力,一次只能转一条图文。
对于目前做短视频的人来说,我觉得还是非常方便的,所以就花点时间捣鼓了下,把代码写了出来。
在使用之前,我们先需要做做前期的准备。
1.一个百度账号
要使用百度API的接口,我们需要有一个百度开放平台的账号(生成视频需要),可以直接使用百度账号登陆。
我们需要的是该应用下的AppID、API Key、Secret Key。
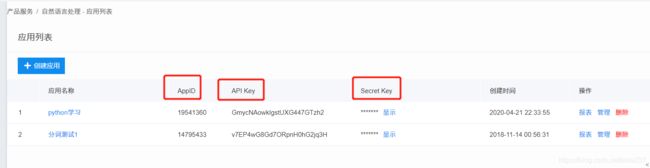
这块有不懂的可以百度,或者私信我,这里不细讲。
2.一个百家号
这个接口的麻烦之处在于,提供的图文链接必须是百度官方的百家号文章,其他的一概不行
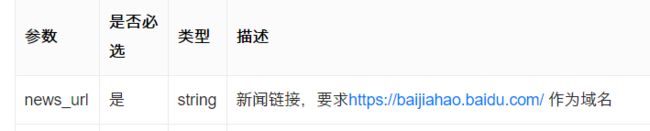
这个,说实话确实有点麻烦,因为要注册百家号,其实还是有一些麻烦的,很多同学不一定会弄。
如果确实有需要的同学可以注册一个,也可以当做自媒体玩玩。
如果只是想用接口,不想这么麻烦的,我正好有一个闲置的百家号,每天可以发5篇文章。
那么可以私信我,我帮你把内容发出去,然后把链接发回给你。(不收费)
这里还要注意的一点是:
图文内容不要太长,文字控制在500字以内
原因我后面会说到。
3.获取access_token
关于url,文档里面有一个参数access_token,这个是必须要的,也是我之前让注册百度账号的缘故。
在对url发送请求前,我们先要去获取access_token,代码已经帮大家写好了。
# 获取sccess token函数
def get_AccessToken():
url_a = 'https://aip.baidubce.com/oauth/2.0/token'
data = {
'grant_type':'client_credentials',
'client_id':api_key,
'client_secret':s_key
}
r = requests.get(url=url_a,params=data)
return r.json()['access_token']4.图文生成视频
4-1创建视频任务
前期准备完成了,我们可以开始看API文档,看视频怎么生成。
当然,只想使用这个功能,而不想那么多细节的同学,可以拉到最后,我会把整个代码贴出来。
我们继续。
关于接口的描述是这样的:
创建图文生成视频任务,提供新闻链接和必要的参数,即可创建一个视频任务,得到任务id,用于后续的查询或中止操作。 目前同一用户仅能创建一个视频任务。
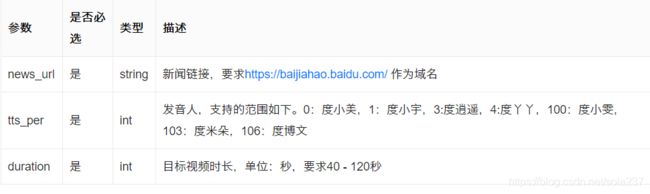
图文链接和access_token有了,可以开始对url发送请求。
请求的内容还有2个,一个是请求头,一个是请求参数
其中请求头是固定的
而请求参数有几个,图文链接我们有了,发音人有7种声音可以选择。
我只试了度小美的,大家可以试试其他的声音,看看是不是你想要的。
特别要注意的是这个duration参数,视频的时长它有一个时间范围,嗯,就是只能创建40-120s内的视频,短视频最符合了。
但是,这说明了什么呢?
说明我们的图文内容中,文字的数量要控制在一定范围内。
其中生成的视频会自动包含片头片尾,时间约8秒。
我大概测试了一下,每秒钟大约4-5个字(包含标点符号),所以视频时长设置可以参考:字数/(时长+8秒)
生成图文视频的代码如下:
# 获取是否创建成功函数
def get_video():
data = {
'news_url':news_url,
'tts_per':tts_per,
'duration':duration
}
r = requests.post(url = url.format(get_AccessToken()),data = data,headers=headers)
info = r.json()
if info['error_code'] == 0:
print('视频创建成功!')
job_id = info['result']['job_id']
time_e = info['result']['estimate_finish_time']
print('预计需结束时间为:%s' % time_e)
print('视频id为:%s,请注意保存!' % job_id)
else:
# 查询任务
print(info['error_msg'])以上只是我们把图文转视频的任务创建成功。
成功之后,后台就会开始生成视频,这肯定是需要花费一点时间(1分钟的视频大概两三分钟就可以完成)。
那么中间的这段时间干嘛呢?一是查一下创建的视频情况,如果完成了,我们要把视频下载下来;
二是假如我突然不需要这条,要转其他的图文,那怎么办?这个我待会儿说,先说第一条。
4-2 查询视频任务+下载视频
查询任务API提供的是另外一个url,不过我代码里面已经帮大家写好了,无需担心。
发起查询请求后,会返回这样几个任务状态码(status)
1:已创建,2:排队中,3:生成中,4:生成成功,5:生成失败
我们可以用if条件判断语句,根据返回的状态码不同,得到不同的结果。
如果视频已经生成了,那么要输出视频相关的一些信息。
比如视频下载链接,封面下载链接,链接失效时间,它还会自动帮我们把视频进行分类。(我这个属于娱乐类)
把下载链接复制粘贴到浏览器中,就可以自动播放,也可以直接下载使用。
假如出现错误可以再次查询,应该是接口本身有点问题。
如果还在生成中,那么会返回视频完成的一个大概时间点。
以及还会返回一个视频的任务ID,用于视频任务的中止。
def find_task():
print('正在查询进行中的任务。。。')
r = requests.get(url = url_f.format(get_AccessToken(),headers=headers))
info = r.json()
if info['error_code'] == 0:
# print('进行中的任务信息为:%s' %info['result'])
result = info['result']
# 假如result有内容,也即创建任务成功
if len(result):
s = list(result.keys())[0]
data = result[s]
if data['status'] == '4':
print('恭喜视频生成成功!')
print('视频文件失效时间:%s ' % data['expire_time'])
print('视频下载链接为:%s ' %data['video_addr'])
print('视频封面下载链接为:%s ' % data['video_cover_addr'])
print('视频时长%s 秒' % data['video_duration'])
print('视频标题:%s ' % data['video_title'])
print('视频摘要:%s ' % data['video_summary'])
print('视频分类:%s ' % data['video_category'])
elif data['status'] == '5':
print('视频生成失败!')
print(data['fail_reason'])
elif data['status'] == '2' or data['status'] == '3':
print('任务排队或者生成中。。。')
print('任务信息id为%s' % data['job_id'])
print('预计结束时间为:%s' %data['estimate_finish_time'])
else:
print('视频还在生成中,请耐心等待。。。')
print('任务信息id为%s' % data['job_id'])
print('预计结束时间为:%s' %data['estimate_finish_time'])
else:
print('不知道这是什么')
else:
print('服务暂时不可用,可能是视频已经生成,请重试!')4-3 中止视频任务
API接口还提供了中止功能,就是我上面讲到的。
中止任务是需要提供任务id的,可以在第二步查询获得。
这一步其实比较简单,就不在重复那么多。
# 中止任务
def stop_task():
print('准备中止任务。。。')
job_id = int(input('请输入你要中止的任务id:'))
data = {
'job_id':job_id
}
r = requests.get(url = url_d.format(get_AccessToken(),data = data,headers=headers))
info = r.json()
if info['error_code'] == 0:
print('中止的任务信息为:%s' %info['result'])
else:
print('该任务不存在,请检查输入数据后再试!')
关于API的详细说明,感兴趣的同学也可以去参考官方文档:https://ai.baidu.com/ai-doc/NLP/Zk7ylspjv
5-完整代码
最后的代码我把一些需要手动输入的参数重新添加了进去,不过没有对输入的内容进行判断,不然代码写起来也太长了…
输入的顺序是:
(1)输入要进行的操作:【0:创建任务】 【1:查询任务】 【2:中止任务】
如果是0,那么需要输入以下:
(2)输入文章链接
(3)输入发音人(数字代号)
(4)输入视频时长(40-120),单位是秒
如果是2,那么需要输入任务id
(5)请输入要中止的任务ID(不知道可以通过1查询获得)
完整代码,我把账户的几个key都删除了,需要用的记得填好后再用,不然会报错的…
完结,撒花~~~
import requests
import json
'''
1.视频任务创建接口
2.视频任务查询接口
3.视频任务中止接口
其他:
1.每秒钟大约5个字(包含标点符号)
2.视频会自动包含片头片尾,总计约8秒时长
3.视频时长设置为:字数/(时长+8秒)
4.接口调用说明文档:https://ai.baidu.com/ai-doc/NLP/Zk7ylspjv#%E8%BF%94%E5%9B%9E%E8%AF%B4%E6%98%8E-1
5.程序基于百度AI开放平台
'''
# 自然语言处理账户
appid = ***
api_key = '输入你自己的'
s_key = '输入你自己的'
# 几个接口的url
url = 'https://aip.baidubce.com/rest/2.0/nlp/v1/create_vidpress?access_token={}'
url_f = 'https://aip.baidubce.com/rest/2.0/nlp/v1/query_vidpress?access_token={}'
url_d = 'https://aip.baidubce.com/rest/2.0/nlp/v1/delete_vidpress?access_token={}'
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3704.400 QQBrowser/10.4.3587.400',
'Content-Type':'application/x-www-form-urlencoded'
}
# 获取sccess token函数
def get_AccessToken():
url_a = 'https://aip.baidubce.com/oauth/2.0/token'
data = {
'grant_type':'client_credentials',
'client_id':api_key,
'client_secret':s_key
}
r = requests.get(url=url_a,params=data)
return r.json()['access_token']
# 获取是否创建成功函数
def get_video():
# 百家号文章url
news_url = input('请粘贴你需要转为视频的百家号图文链接:')
# 发音人
print('发音人【0:度小美,1:度小宇,3:度逍遥,4:度丫丫,100:度小雯,103:度米朵,106:度博文】')
tts_per = int(input('请按照上述输入发音人数字:'))
# 目标视频时长,单位:秒,要求40 - 120秒
# 40秒字数:160个字;120秒字数:560个字
duration = int(input('请输入视频时长(范围是40-120),单位是秒:'))
# 请求参数
data = {
'news_url':news_url,
'tts_per':tts_per,
'duration':duration
}
r = requests.post(url = url.format(get_AccessToken()),data = data,headers=headers)
info = r.json()
if info['error_code'] == 0:
print('视频创建成功!')
job_id = info['result']['job_id']
time_e = info['result']['estimate_finish_time']
print('预计需结束时间为:%s' % time_e)
print('视频id为:%s,请注意保存!' % job_id)
else:
# 查询任务
print(info['error_msg'])
find_task()
# 查找进行中的任务
def find_task():
print('正在查询进行中的任务。。。')
r = requests.get(url = url_f.format(get_AccessToken(),headers=headers))
info = r.json()
if info['error_code'] == 0:
# print('进行中的任务信息为:%s' %info['result'])
result = info['result']
# 假如result有内容,也即创建任务成功
if len(result):
s = list(result.keys())[0]
data = result[s]
if data['status'] == '4':
print('恭喜视频生成成功!')
print('视频文件失效时间:%s ' % data['expire_time'])
print('视频下载链接为:%s ' %data['video_addr'])
print('视频封面下载链接为:%s ' % data['video_cover_addr'])
print('视频时长%s 秒' % data['video_duration'])
print('视频标题:%s ' % data['video_title'])
print('视频摘要:%s ' % data['video_summary'])
print('视频分类:%s ' % data['video_category'])
elif data['status'] == '5':
print('视频生成失败!')
print(data['fail_reason'])
elif data['status'] == '2' or data['status'] == '3':
print('任务排队或者生成中。。。')
print('任务信息id为%s' % data['job_id'])
print('预计结束时间为:%s' %data['estimate_finish_time'])
else:
print('视频还在生成中,请耐心等待。。。')
print('任务信息id为%s' % data['job_id'])
print('预计结束时间为:%s' %data['estimate_finish_time'])
else:
print('不知道这是什么')
else:
print('服务暂时不可用,可能是视频已经生成,请重试!')
# 中止任务
def stop_task():
print('准备中止任务。。。')
job_id = int(input('请输入你要中止的任务id:'))
data = {
'job_id':job_id
}
r = requests.get(url = url_d.format(get_AccessToken(),data = data,headers=headers))
info = r.json()
if info['error_code'] == 0:
print('中止的任务信息为:%s' %info['result'])
else:
print('该任务不存在,请检查输入数据后再试!')
def main():
num = int(input('请输入你要进行的操作:【0:创建任务】 【1:查询任务】 【2:中止任务】'))
if num == 0:
get_video()
if num == 1:
find_task()
if num == 2:
stop_task()
if __name__ == '__main__':
main()