Docker监控平台prometheus和grafana,监控redis,mysql,docker,服务器信息
Docker监控平台prometheus和grafana,监控redis,mysql,docker,服务器信息
- 一、通过redis_exporter监控redis
-
- 1.1 下载镜像
- 1.2 运行服务
- 1.3 配置 Prometheus 添加redis监控目标主机
- 1.4 监控Redis集群,配置Prometheus.yml
- 1.5 重启Prometheus
- 1.6 接入Grafana监控展示模板
- 1.7 告警规则
- 二、通过CAdvisor监控Docker
-
- 2.1 启动CAdvisor
- 2.2 配置Prometheus
- 2.3 重启prometheus容器
- 2.4 Prometheus监控端查看是否介入
- 2.5 访问被监控端cAdvisor捕获的数据
- 2.6 配置Grafana监控图表
- 三、通过mysql_exporter监控Mysql
-
- 3.1 mysqld exporter方式监控Mysql
- 3.2 配置alertmanager报警,添加prometheus配置
- 四、通过node_exporter监控服务器信息
- 五、Prometheus监控JVM
相关博文原文地址:
博客园:小哥boy:Prometheus入门到放弃(7)之redis_exporter部署
豌豆代理:Prometheus 监控Docker服务器及Granfanna可视化
简书:baiyongjie:prometheus 监控Docker
博客园:海口-熟练工:参考Redis集群监控方案:Prometheus 监控 Redis 集群的正确姿势
一、通过redis_exporter监控redis
1.1 下载镜像
docker pull oliver006/redis_exporter
1.2 运行服务
docker run -d --name redis_exporter -p 9121:9121 oliver006/redis_exporter --redis.addr redis://172.16.11.51:6379 --redis.password '123456'
参数解释:
- –redis.addr 指定redis地址,由于这里使用docker起的服务,所以不能使用127.0.0.1地址。
- –redis.password redis认证密码,如果没有密码,该参数不需要
Docker方式启动Prometheus:
docker run -d -p 9090:9090 --name=prometheus -v /root/software/prometheus/prometheus-config.yml:/etc/prometheus/prometheus.yml prom/prometheus
1.3 配置 Prometheus 添加redis监控目标主机
- job_name: "redis-sit"
static_configs:
- targets: ['172.16.11.51:9121']
1.4 监控Redis集群,配置Prometheus.yml
切记注意yml的格式缩进问题!!!
- job_name: 'redis_exporter_targets'
static_configs:
- targets:
- redis://172.18.11.139:7000
- redis://172.18.11.139:7001
- redis://172.18.11.140:7002
- redis://172.18.11.140:7003
- redis://172.18.11.141:7004
- redis://172.18.11.141:7005
metrics_path: /scrape
relabel_configs:
- source_labels: [__address__]
target_label: __param_target
- source_labels: [__param_target]
target_label: instance
- target_label: __address__
replacement: 172.18.11.139:9121
启动Redis_exporter的命令如上:
只要能连接到一个集群的一个节点,自然就能查询其他节点的指标了。
docker run -d --name redis_exporter -p 9121:9121 oliver006/redis_exporter --redis.addr redis://172.16.11.51:6379 --redis.password '123456'
1.5 重启Prometheus
Docker方式启动Prometheus:
docker run -d -p 9090:9090 --name=prometheus -v /root/software/prometheus/prometheus-config.yml:/etc/prometheus/prometheus.yml prom/prometheus
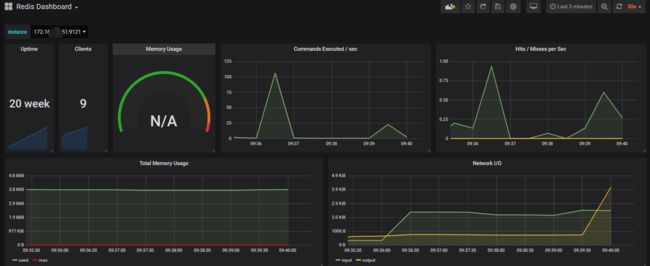
重启prometheus后,可以看到redis主机已经添加到prometheus监控列表:

1.6 接入Grafana监控展示模板
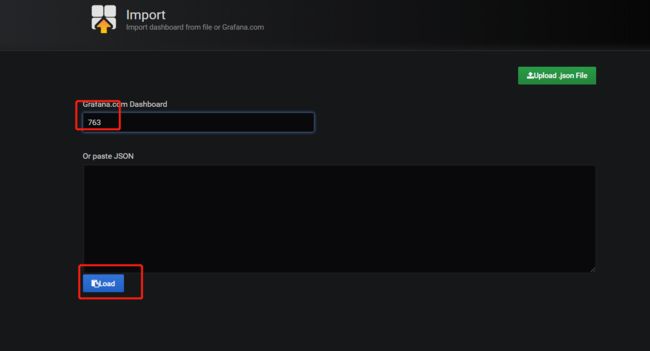
redis_exporter 监控模板,业界普遍推荐使用Grafana模板库中编号为763的,https://grafana.com/dashboards/763
如下图所示,填写,模板编号,点击加载即可。
1.7 告警规则
groups:
- name: Redis
rules:
- alert: RedisDown
expr: redis_up == 0
for: 5m
labels:
severity: error
annotations:
summary: "Redis down (instance {
{ $labels.instance }})"
description: "Redis 挂了啊,mmp\n VALUE = {
{ $value }}\n LABELS: {
{ $labels }}"
- alert: MissingBackup
expr: time() - redis_rdb_last_save_timestamp_seconds > 60 * 60 * 24
for: 5m
labels:
severity: error
annotations:
summary: "Missing backup (instance {
{ $labels.instance }})"
description: "Redis has not been backuped for 24 hours\n VALUE = {
{ $value }}\n LABELS: {
{ $labels }}"
- alert: OutOfMemory
expr: redis_memory_used_bytes / redis_total_system_memory_bytes * 100 > 90
for: 5m
labels:
severity: warning
annotations:
summary: "Out of memory (instance {
{ $labels.instance }})"
description: "Redis is running out of memory (> 90%)\n VALUE = {
{ $value }}\n LABELS: {
{ $labels }}"
- alert: ReplicationBroken
expr: delta(redis_connected_slaves[1m]) < 0
for: 5m
labels:
severity: error
annotations:
summary: "Replication broken (instance {
{ $labels.instance }})"
description: "Redis instance lost a slave\n VALUE = {
{ $value }}\n LABELS: {
{ $labels }}"
- alert: TooManyConnections
expr: redis_connected_clients > 1000
for: 5m
labels:
severity: warning
annotations:
summary: "Too many connections (instance {
{ $labels.instance }})"
description: "Redis instance has too many connections\n VALUE = {
{ $value }}\n LABELS: {
{ $labels }}"
- alert: NotEnoughConnections
expr: redis_connected_clients < 5
for: 5m
labels:
severity: warning
annotations:
summary: "Not enough connections (instance {
{ $labels.instance }})"
description: "Redis instance should have more connections (> 5)\n VALUE = {
{ $value }}\n LABELS: {
{ $labels }}"
- alert: RejectedConnections
expr: increase(redis_rejected_connections_total[1m]) > 0
for: 5m
labels:
severity: error
annotations:
summary: "Rejected connections (instance {
{ $labels.instance }})"
description: "Some connections to Redis has been rejected\n VALUE = {
{ $value }}\n LABELS: {
{ $labels }}"
二、通过CAdvisor监控Docker
2.1 启动CAdvisor
docker run --volume=/:/rootfs:ro --volume=/var/run:/var/run:rw \
--volume=/sys:/sys:ro \
--volume=/var/lib/docker/:/var/lib/docker:ro \
--volume=/dev/disk/:/dev/disk:ro \
--publish=8081:8080 \
--detach=true \
--name=cadvisor \
google/cadvisor:latest
2.2 配置Prometheus
scrape_configs:
# 添加作业,自定义名称
- job_name: 'docker'
# 静态添加
static_configs:
# 指定监控实例
- targets: ['192.168.21.55:8081']
2.3 重启prometheus容器
docker restart prometheus
2.4 Prometheus监控端查看是否介入
浏览器输入ip:9090查看Prometheus的targets状态,看看数据是否接入正常。
2.5 访问被监控端cAdvisor捕获的数据
http://192.168.0.50:8089/metrics
2.6 配置Grafana监控图表
推荐模板ID:893
三、通过mysql_exporter监控Mysql
使用Docker部署监控系统,Prometheus,Grafana,监控服务器信息及Mysql
51CTO:wfwf1990:使用prometheus的mysql exporter监控mysql
3.1 mysqld exporter方式监控Mysql
mysqld exporter的功能是收集mysql服务器的数据, 并向外提供api接口, 用于prometheus主要获取数据。
在被监控端mysql服务器上创建账号用于mysql exporter收集使用
GRANT REPLICATION CLIENT, PROCESS ON *.* to 'exporter'@'%' identified by '123456';
GRANT SELECT ON performance_schema.* TO 'exporter'@'%';
flush privileges;
在被监控端mysql服务器上安装mysql exporter。
docker run -d --restart=always --name mysqld-exporter -p 9104:9104 -e DATA_SOURCE_NAME="user:password@(hostname:port)/" prom/mysqld-exporter
docker run -d --restart=always --name mysqld-exporter -p 9104:9104 -e DATA_SOURCE_NAME="exporter:123456@(192.168.1.82:3306)/" prom/mysqld-exporter
要查看容器是否报错, 主要是验证exporter与mysql服务端之间正常连接和获取数据;
docker logs -f mysqld-exporter 看有没有报错
3.2 配置alertmanager报警,添加prometheus配置
alerting:
alertmanagers:
- scheme: http
static_configs:
- targets:
- "10.100.110.171:9093"
rule_files:
- /opt/prometheus/rules/mysql*.rules
制定mysql报警规则:
groups:
- name: MySQLStatsAlert
rules:
- alert: MySQL is down
expr: mysql_up == 0
for: 1m
labels:
severity: critical
annotations:
summary: "Instance {
{ $labels.instance }} MySQL is down"
description: "MySQL database is down. This requires immediate action!"
- alert: open files high
expr: mysql_global_status_innodb_num_open_files > (mysql_global_variables_open_files_limit) * 0.75
for: 1m
labels:
severity: warning
annotations:
summary: "Instance {
{ $labels.instance }} open files high"
description: "Open files is high. Please consider increasing open_files_limit."
- alert: Read buffer size is bigger than max. allowed packet size
expr: mysql_global_variables_read_buffer_size > mysql_global_variables_slave_max_allowed_packet
for: 1m
labels:
severity: warning
annotations:
summary: "Instance {
{ $labels.instance }} Read buffer size is bigger than max. allowed packet size"
description: "Read buffer size (read_buffer_size) is bigger than max. allowed packet size (max_allowed_packet).This can break your replication."
- alert: Sort buffer possibly missconfigured
expr: mysql_global_variables_innodb_sort_buffer_size <256*1024 or mysql_global_variables_read_buffer_size > 4*1024*1024
for: 1m
labels:
severity: warning
annotations:
summary: "Instance {
{ $labels.instance }} Sort buffer possibly missconfigured"
description: "Sort buffer size is either too big or too small. A good value for sort_buffer_size is between 256k and 4M."
- alert: Thread stack size is too small
expr: mysql_global_variables_thread_stack <196608
for: 1m
labels:
severity: warning
annotations:
summary: "Instance {
{ $labels.instance }} Thread stack size is too small"
description: "Thread stack size is too small. This can cause problems when you use Stored Language constructs for example. A typical is 256k for thread_stack_size."
- alert: Used more than 80% of max connections limited
expr: mysql_global_status_max_used_connections > mysql_global_variables_max_connections * 0.8
for: 1m
labels:
severity: warning
annotations:
summary: "Instance {
{ $labels.instance }} Used more than 80% of max connections limited"
description: "Used more than 80% of max connections limited"
- alert: InnoDB Force Recovery is enabled
expr: mysql_global_variables_innodb_force_recovery != 0
for: 1m
labels:
severity: warning
annotations:
summary: "Instance {
{ $labels.instance }} InnoDB Force Recovery is enabled"
description: "InnoDB Force Recovery is enabled. This mode should be used for data recovery purposes only. It prohibits writing to the data."
- alert: InnoDB Log File size is too small
expr: mysql_global_variables_innodb_log_file_size < 16777216
for: 1m
labels:
severity: warning
annotations:
summary: "Instance {
{ $labels.instance }} InnoDB Log File size is too small"
description: "The InnoDB Log File size is possibly too small. Choosing a small InnoDB Log File size can have significant performance impacts."
- alert: InnoDB Flush Log at Transaction Commit
expr: mysql_global_variables_innodb_flush_log_at_trx_commit != 1
for: 1m
labels:
severity: warning
annotations:
summary: "Instance {
{ $labels.instance }} InnoDB Flush Log at Transaction Commit"
description: "InnoDB Flush Log at Transaction Commit is set to a values != 1. This can lead to a loss of commited transactions in case of a power failure."
- alert: Table definition cache too small
expr: mysql_global_status_open_table_definitions > mysql_global_variables_table_definition_cache
for: 1m
labels:
severity: page
annotations:
summary: "Instance {
{ $labels.instance }} Table definition cache too small"
description: "Your Table Definition Cache is possibly too small. If it is much too small this can have significant performance impacts!"
- alert: Table open cache too small
expr: mysql_global_status_open_tables >mysql_global_variables_table_open_cache * 99/100
for: 1m
labels:
severity: page
annotations:
summary: "Instance {
{ $labels.instance }} Table open cache too small"
description: "Your Table Open Cache is possibly too small (old name Table Cache). If it is much too small this can have significant performance impacts!"
- alert: Thread stack size is possibly too small
expr: mysql_global_variables_thread_stack < 262144
for: 1m
labels:
severity: page
annotations:
summary: "Instance {
{ $labels.instance }} Thread stack size is possibly too small"
description: "Thread stack size is possibly too small. This can cause problems when you use Stored Language constructs for example. A typical is 256k for thread_stack_size."
- alert: InnoDB Buffer Pool Instances is too small
expr: mysql_global_variables_innodb_buffer_pool_instances == 1
for: 1m
labels:
severity: page
annotations:
summary: "Instance {
{ $labels.instance }} InnoDB Buffer Pool Instances is too small"
description: "If you are using MySQL 5.5 and higher you should use several InnoDB Buffer Pool Instances for performance reasons. Some rules are: InnoDB Buffer Pool Instance should be at least 1 Gbyte in size. InnoDB Buffer Pool Instances you can set equal to the number of cores of your machine."
- alert: InnoDB Plugin is enabled
expr: mysql_global_variables_ignore_builtin_innodb == 1
for: 1m
labels:
severity: page
annotations:
summary: "Instance {
{ $labels.instance }} InnoDB Plugin is enabled"
description: "InnoDB Plugin is enabled"
- alert: Binary Log is disabled
expr: mysql_global_variables_log_bin != 1
for: 1m
labels:
severity: warning
annotations:
summary: "Instance {
{ $labels.instance }} Binary Log is disabled"
description: "Binary Log is disabled. This prohibits you to do Point in Time Recovery (PiTR)."
- alert: Binlog Cache size too small
expr: mysql_global_variables_binlog_cache_size < 1048576
for: 1m
labels:
severity: page
annotations:
summary: "Instance {
{ $labels.instance }} Binlog Cache size too small"
description: "Binlog Cache size is possibly to small. A value of 1 Mbyte or higher is OK."
- alert: Binlog Statement Cache size too small
expr: mysql_global_variables_binlog_stmt_cache_size <1048576 and mysql_global_variables_binlog_stmt_cache_size > 0
for: 1m
labels:
severity: page
annotations:
summary: "Instance {
{ $labels.instance }} Binlog Statement Cache size too small"
description: "Binlog Statement Cache size is possibly to small. A value of 1 Mbyte or higher is typically OK."
- alert: Binlog Transaction Cache size too small
expr: mysql_global_variables_binlog_cache_size <1048576
for: 1m
labels:
severity: page
annotations:
summary: "Instance {
{ $labels.instance }} Binlog Transaction Cache size too small"
description: "Binlog Transaction Cache size is possibly to small. A value of 1 Mbyte or higher is typically OK."
- alert: Sync Binlog is enabled
expr: mysql_global_variables_sync_binlog == 1
for: 1m
labels:
severity: page
annotations:
summary: "Instance {
{ $labels.instance }} Sync Binlog is enabled"
description: "Sync Binlog is enabled. This leads to higher data security but on the cost of write performance."
- alert: IO thread stopped
expr: mysql_slave_status_slave_io_running != 1
for: 1m
labels:
severity: critical
annotations:
summary: "Instance {
{ $labels.instance }} IO thread stopped"
description: "IO thread has stopped. This is usually because it cannot connect to the Master any more."
- alert: SQL thread stopped
expr: mysql_slave_status_slave_sql_running == 0
for: 1m
labels:
severity: critical
annotations:
summary: "Instance {
{ $labels.instance }} SQL thread stopped"
description: "SQL thread has stopped. This is usually because it cannot apply a SQL statement received from the master."
- alert: SQL thread stopped
expr: mysql_slave_status_slave_sql_running != 1
for: 1m
labels:
severity: critical
annotations:
summary: "Instance {
{ $labels.instance }} Sync Binlog is enabled"
description: "SQL thread has stopped. This is usually because it cannot apply a SQL statement received from the master."
- alert: Slave lagging behind Master
expr: rate(mysql_slave_status_seconds_behind_master[1m]) >30
for: 1m
labels:
severity: warning
annotations:
summary: "Instance {
{ $labels.instance }} Slave lagging behind Master"
description: "Slave is lagging behind Master. Please check if Slave threads are running and if there are some performance issues!"
- alert: Slave is NOT read only(Please ignore this warning indicator.)
expr: mysql_global_variables_read_only != 0
for: 1m
labels:
severity: page
annotations:
summary: "Instance {
{ $labels.instance }} Slave is NOT read only"
description: "Slave is NOT set to read only. You can accidentally manipulate data on the slave and get inconsistencies..."
四、通过node_exporter监控服务器信息
Grafana+Prometheus通过node_exporter监控Linux服务器信息
五、Prometheus监控JVM
简书:袁先生的教程:Prometheus监控JVM
使用Prometheus+Grafana监控JVM