elasticsearch 聚合搜索
bucket:一个数据分组
metric,就是对一个bucket执行的某种聚合分析的操作,比如说求平均值,求最大值,求最小值
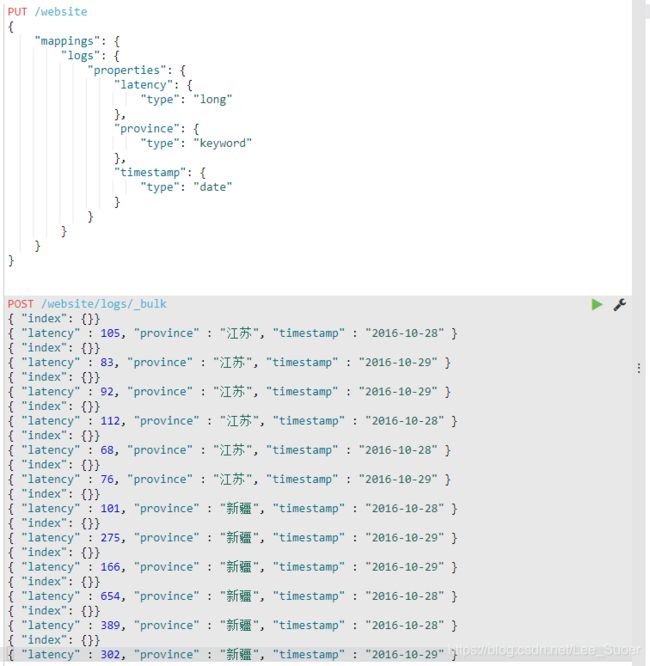
先准备一些数据:

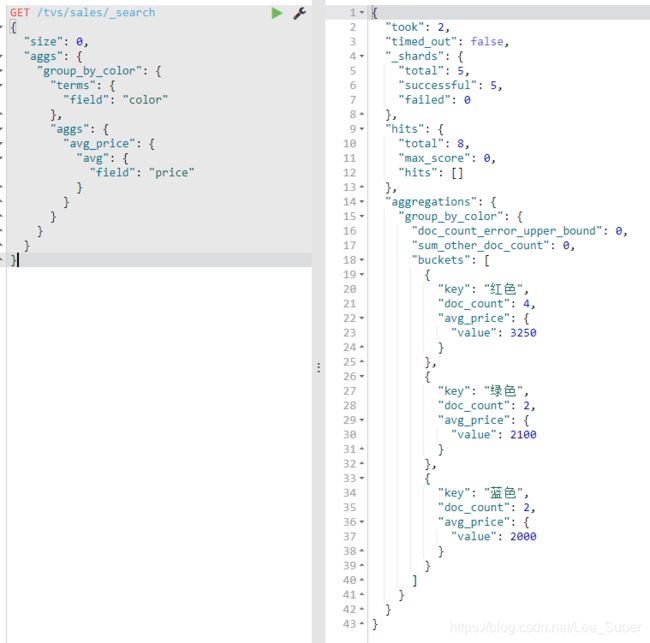
统计哪种颜色的电视销量最高
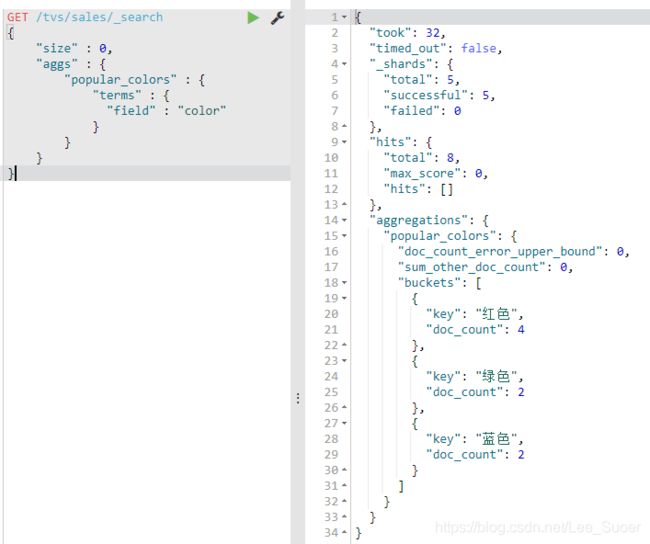
size:只获取聚合结果,而不要执行聚合的原始数据
aggs:固定语法,要对一份数据执行分组聚合操作
popular_colors:就是对每个aggs,都要起一个名字,这个名字是随机的,你随便取什么都ok
terms:根据字段的值进行分组
field:根据指定的字段的值进行分组
hits.hits:我们指定了size是0,所以hits.hits就是空的,否则会把执行聚合的那些原始数据给你返回回来
aggregations:聚合结果
popular_color:我们指定的某个聚合的名称
buckets:根据我们指定的field划分出的buckets
key:每个bucket对应的那个值
doc_count:这个bucket分组内,有多少个数据
数量,其实就是这种颜色的销量
每种颜色对应的bucket中的数据的
默认的排序规则:按照doc_count降序排序
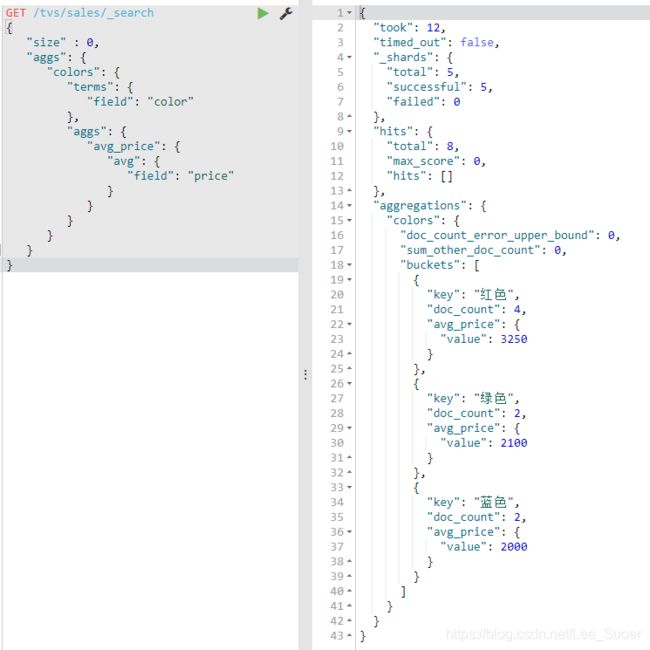
select avg(price) from tvs.sales group by color

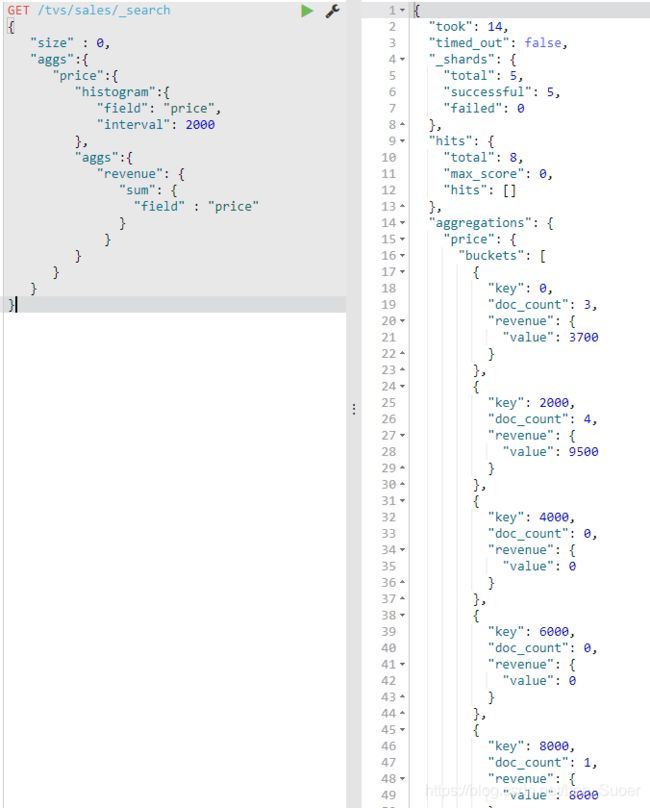
histogram:类似于terms,也是进行bucket分组操作,接收一个field,按照这个field的值的各个范围区间,进行bucket分组操作
"histogram":{
"field": "price",
"interval": 2000
},
interval:2000,划分范围,0~2000,2000~4000,4000~6000,6000~8000,8000~10000,buckets
date histogram,按照我们指定的某个date类型的日期field,以及日期interval,按照一定的日期间隔,去划分bucket
date interval = 1m,
2017-01-01~2017-01-31,就是一个bucket
2017-02-01~2017-02-28,就是一个bucket
min_doc_count:即使某个日期interval,2017-01-01~2017-01-31中,一条数据都没有,那么这个区间也是要返回的,不然默认是会过滤掉这个区间的
extended_bounds,min,max:划分bucket的时候,会限定在这个起始日期,和截止日期内
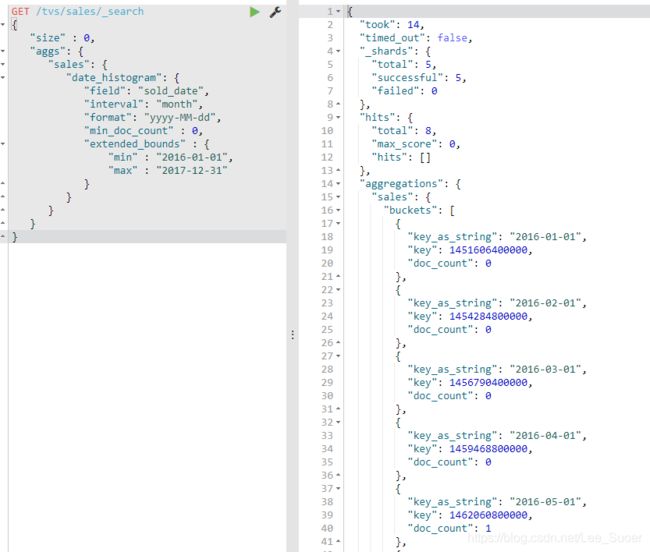
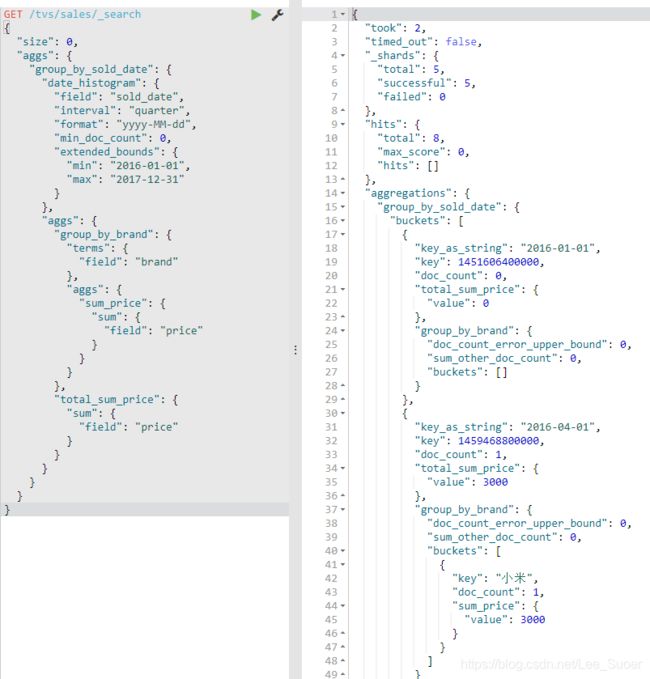
"interval": "quarter", 按照季度来
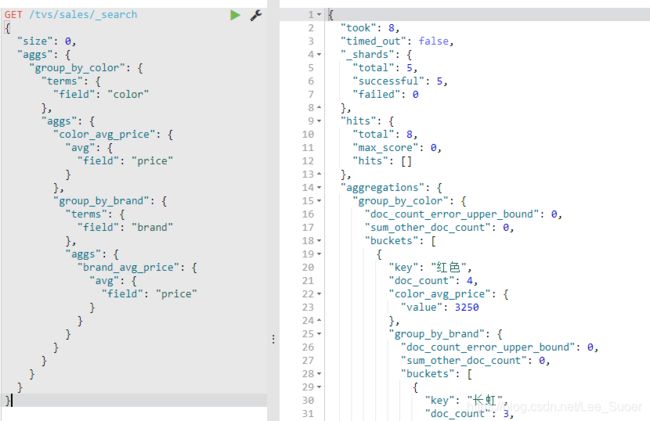
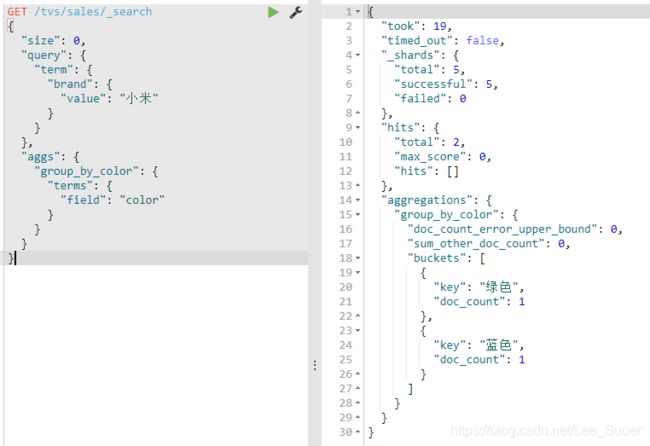
select count(*) from tvs.sales where brand like "%小米%" group by color
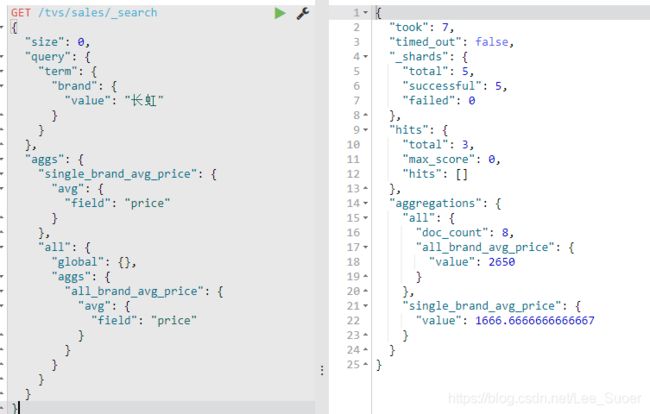
global:就是global bucket,就是将所有数据纳入聚合的scope,而不管之前的query
single_brand_avg_price:就是针对query搜索结果,执行的,拿到的,就是长虹品牌的平均价格
all.all_brand_avg_price:拿到所有品牌的平均价格
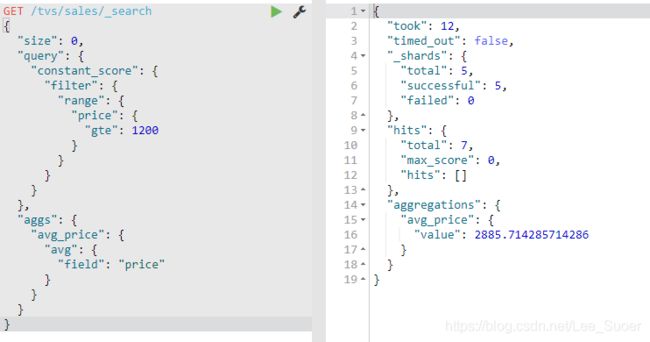
过滤之后再聚合

bucket filter:对不同的bucket下的aggs,进行filter
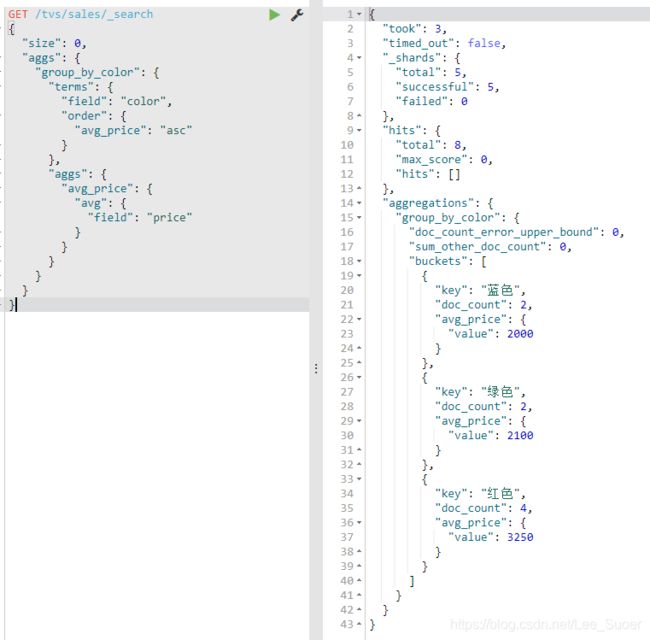
对聚合结果升序或者降序

有些聚合分析的算法,是很容易就可以并行的,比如说max
有些聚合分析的算法,是不好并行的,比如说,count(distinct),并不是说,在每个node上,直接就出一些distinct value,就可以的,因为数据可能会很多
es会采取近似聚合的方式,就是采用在每个node上进行近估计的方式,得到最终的结论,cuont(distcint),100万,1050万/95万 --> 5%左右的错误率
近似估计后的结果,不完全准确,但是速度会很快,一般会达到完全精准的算法的性能的数十倍
精准+实时+大数据 --> 选择2个
(1)精准+实时: 没有大数据,数据量很小,那么一般就是单击跑,随便你则么玩儿就可以
(2)精准+大数据:hadoop,批处理,非实时,可以处理海量数据,保证精准,可能会跑几个小时
(3)大数据+实时:es,不精准,近似估计,可能会有百分之几的错误率
cartinality metric,对每个bucket中的指定的field进行去重,取去重后的count,类似于count(distcint)

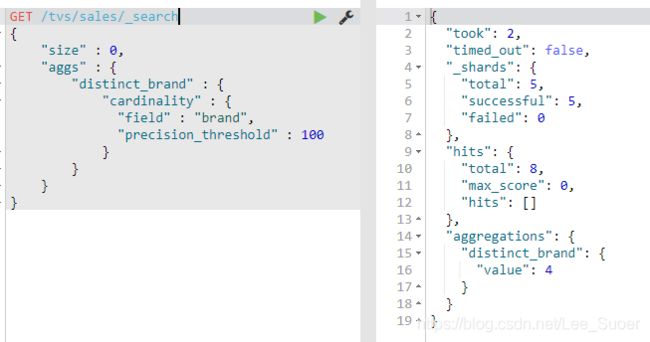
precision_threshold,值设置的越大,占用内存越大,1000 * 8 = 8000 / 1000 = 8KB,更准确
HyperLogLog++ (HLL)算法性能优化
cardinality底层算法:HLL算法,HLL算法的性能
会对所有的uqniue value取hash值,通过hash值近似去求distcint count
默认情况下,发送一个cardinality请求的时候,会动态地对所有的field value,取hash值; 将取hash值的操作,前移到建立索引的时候,会更快

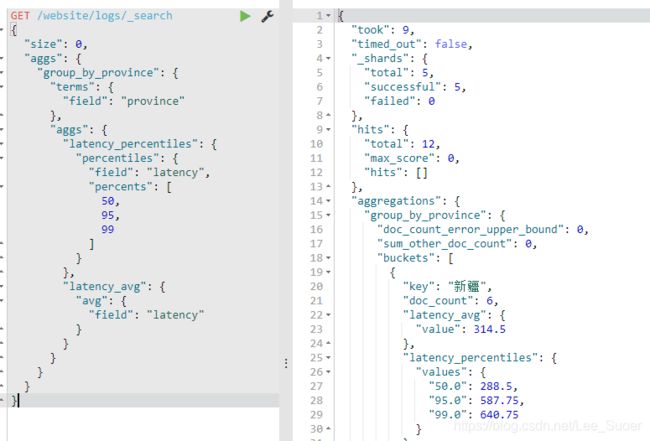
对百分之多少的数据进行聚合分析