二分图常见问题总结
文章目录
-
- 1.二分图
- 2.二分图的判定
-
- 2.1 定义法判定二分图
- 2.2 二分图判定方法的应用
- 3.二分图匹配
-
- 3.1 增广路
- 3.2 匈牙利算法
- 3.3 网络流求二分图匹配
- 3.4 二分图匹配的应用
- 4.二分图最小点覆盖
-
- 4.1 定义
- 4.2 二分图最小点覆盖定理
- 5.二分图最大独立集
-
- 5.1 定义
- 5.2 二分图最大独立集定理
- 5.3 二分图最大团
- 6.DAG上最长反链
-
- 6.1 定义
- 6.2 建立模型
- 6.3 DAG上最长反链的应用
- 7.带权二分图匹配/二分图最优匹配
-
- 7.1 KM算法
- 7.2 网络流求带权二分图匹配
- 8.slack优化KM算法
- 9.写在最后
1.二分图
二分图是指一个图能够分成两部分,每一部分的点之间互相没有连边
比如说这个东西就是一个二分图
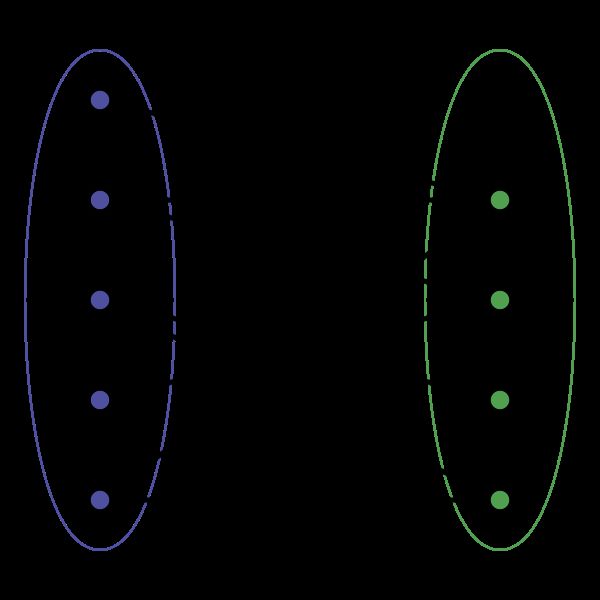
因为他能够被分成 u u u, v v v两部分, u u u中的点相互之间没有连边, v v v中的点相互之间也没有连边
二分图也叫做二部图,偶图等等
在OI中,几乎所有二分图的题目都可以用网络流来实现,但是二分图本身是有非常优秀的算法的,下面我们来介绍一下
2.二分图的判定
2.1 定义法判定二分图
二分图的判定方法就是基于他的定义的
显然,根据定义,一个二分图不能存在奇环
如果存在奇环的话显然不是一个二分图,这个大家可以参照上面的图理解一下,应该不难
那么这道题的内容就转化成了判断一个图是否有奇环
这个做法怎么做呢?
我们常见的做法是进行黑白染色
给有边连接的两个点染成不同的颜色,如果dfs(bfs)的过程中,出现一个点的标记颜色和我们要标的颜色不同的话,那么就出现了奇环,这个图就不是二分图
当然判断二分图还有其他方法比如拓扑排序之类的,但是这种做法有一个优点就是他最后直接为我们分好了两部分
简单的放一下这种做法的代码
inline void dfs(int u,int c){
color[u]=c;
for(int i=head[u];~i;i=e[i].next){
int v=e[i].to;
if(color[v]==-1)dfs(v,c^1);
else if(color[v]==c){
puts("0");
exit(0);
}
}
}
2.2 二分图判定方法的应用
NOIP2008 双栈排序
这道题的做法就是根据进哪个栈预处理出一个图,如果不是二分图就无解,如果是二分图就有解,然后根据题目要求输出就可以了
3.二分图匹配
3.1 增广路
先说题目意思吧,二分图匹配是我们要让二分图一部分的点尽可能的去匹配另一部分的点,当然一个点只能匹配一个点啦
这里我们要引入一个叫做增广路的东西,这也是网络流的基础
比如说对于这样的一个二分图
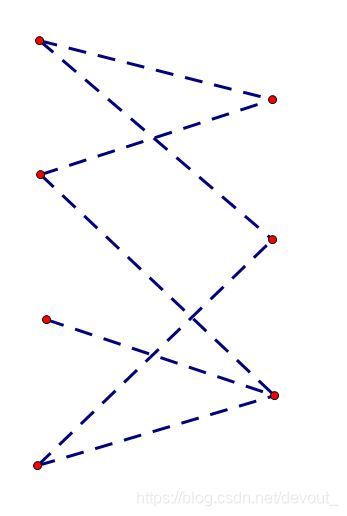
我们现在要进行匹配,那么我们先枚举左边的点,从第一个开始
匹配右边的第一个

当我们枚举第二个点的时候,我们发现,他已经不能和第一个匹配了,所以我们连向右边第三个点
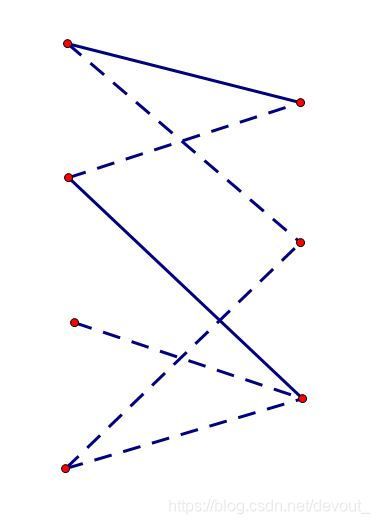
然后我们枚举左边的第三个点,他已经不能和右边第三个匹配了,但是他没有别的出边了,怎么办呢,我们观察这条红色的路径

这条路径,从左3出发,经过未匹配边->匹配边->未匹配边->匹配边->未匹配边,我们发现,如果我们把这条路径上的匹配情况整体取反一下,匹配边变成未匹配边,未匹配边变成匹配边,就变成了
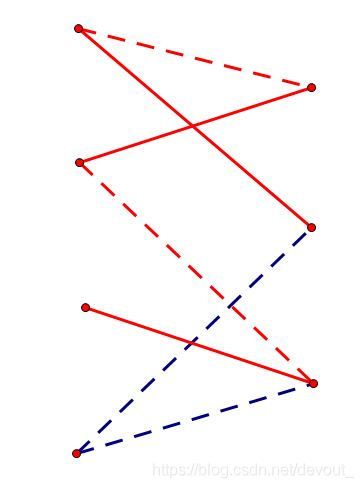
那么我们发现,这时候匹配数就增加了1!
像这样,经过未匹配边->匹配边->…->匹配边->未匹配边的一条路径,就叫做一条增广路
3.2 匈牙利算法
匈牙利算法正是基于增广路的一种解决二分图匹配的做法
我们发现,当我们找到一条增广路,我们把这条路径上的所有匹配关系取反之后,匹配数就+1,那么匈牙利算法就是不停的找增广路,一旦找到一条,那么就整体匹配关系取反,答案+1
那么实现也很简单,大概放下代码吧
bool dfs(int u){
if(vis[u])return false;//vis表示这一次找增广路的时候有没有访问过这个点,如果一个点之前已经访问过了说明找不到增广路
vis[u]=true;
RepG(i,u){
//枚举出边
int v=e[i].to;
if(!match[v]||dfs(match[v])){
//match[v]表示v点之前匹配的点,如果v之前还没有一个点和他匹配,或者往他之前匹配的那个点去找增广路找到了
//就把匹配关系在回溯的时候整体取反一下,让match[v]=u,然后返回true说明找到了一条增广路
match[v]=u;
return true;
}
}
return false;//如果没找到,返回false
}
void hungary(){
Rep(i,1,totx){
memset(vis,0,sizeof(vis));
if(dfs(i))ans++;//如果找到了增广路,就说明这个点能匹配上,答案+1
}
}
匈牙利算法的复杂度可以证明是 O ( n m ) O(nm) O(nm)的,因为每个点都要枚举一遍,最差情况下每条边都要经过一遍,但是这只是最差情况下复杂度,大家如果接触过网络流的话就知道网络流的复杂度是很难跑满的
3.3 网络流求二分图匹配
网络流我之前有讲过,大家可以看这里
用网络流跑二分图匹配就是建立一个超级源点和汇点,源点往左半部分每个点连一个容量为1的边,右半部分每个点往汇点连一个容量为1的点,然后每条边都相应的连上,容量均为1,就可以跑最大流了,最后的答案就是最大流量
那么问题来了,怎么判断最后匹配的情况呢?
因为用匈牙利的话我们可以直接用match看出匹配情况,但是网络流怎么看呢?
我们可以判断原图上的每一条边,他的反边是否有流量(因为这道题容量都是1,看正边容量是不是0也行),如果有,说明这两个点是匹配的
用 d i n i c dinic dinic求二分图匹配的复杂度最差可以证明是 O ( n n ) O(n\sqrt n) O(nn),一样也是通常跑不到
而且一般出题人也不会看匈牙利吧
代码就不放了
3.4 二分图匹配的应用
应用就很多了,这也是二分图匹配最常考的了
最常见的就是两种题型吧,一个是题目里明确说了要匹配的,正常连边就可以
还有一个是二分图的一个转化模型,比如说放棋子,每行只能放一个,每列只能放一个这种的,那么我们可以把每一行当成左半部分的点,每一列当成右半部分的点,每个能放棋子的地方就把他的行向列连一条边就可以了,这样的题目也不少,比如说
P1263 宫廷守卫 上面的模型稍微变化一下就好了
[SCOI2015] 小凸玩矩阵 二分一下就好等等
然后还有一些其他的,比如说
[JSOI2016] 反质数序列判断质数,按奇偶性连边
这里就不一一列举了
4.二分图最小点覆盖
4.1 定义
二分图最小点覆盖的定义对于一个二分图,选择最少的点,让图中所有的边至少有一个端点属于这些点
4.2 二分图最小点覆盖定理
内容
二分图最小点覆盖定理:二分图最小点覆盖=二分图最大匹配数
证明
我们先构造出一个二分图的匹配情况
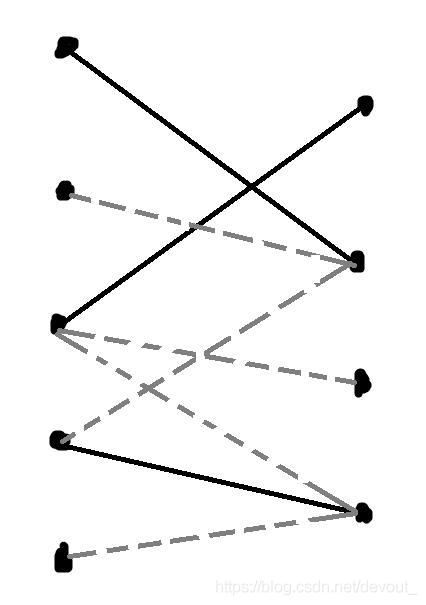
我们从左侧每一个没有被匹配的点出发(在这幅图是左2,5),走所有不完全的增广路,就是说构成是 未匹配边->匹配边->…->匹配边这样的路径,标记经过的点,这幅图中应该有两条,分别是
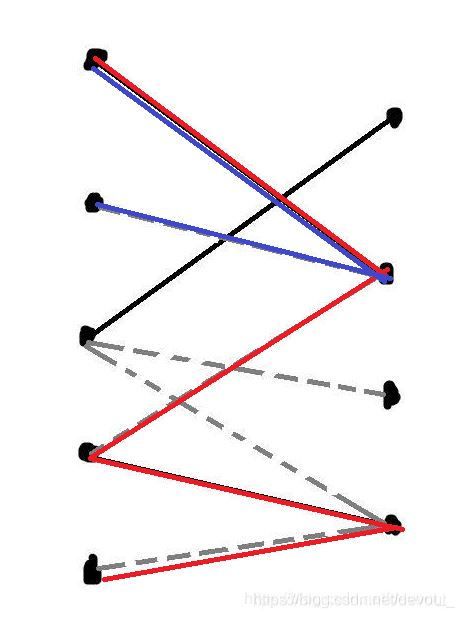
红色的和蓝色的这两条
然后我们看左半部分没有被访问过的(左3)和右半部分被访问过的(右2,4)
这就是我们二分图的一个最大独立集
为什么呢?
我们可以用反证法来证明
假设还有一条边没有被这几个点覆盖,那么显然他的左端点是一个匹配了的点
当这条边是一个匹配边时
如果这条边的右端点只有一条边,那么他的右端点不会访问到,所以没有一条不完全增广路会从右边过来,而左端点又不是不完全增广路的起点(因为已经匹配),所以他不会被覆盖,所以他的左端点属于左边没有被访问到的点,矛盾
如果这条边的右端点有大于一条边,那么他一定会属于一条不完全增广路,那么右端点一定属于右边别访问到的点,矛盾
当这条边不是一个匹配边时
他连向的点一定是右边被访问的,所以这条边也别覆盖,矛盾。
所以这些点一定可以覆盖所有的边
下面要证明这些点少一个一定不行,这个证明方法跟上面类似,这里就不再过多赘述了,大家可以下去自己证一下。
那么通过这种构造方法,就得到了一个二分图最小点覆盖。
那么为啥这个最小点覆盖是最大匹配数呢?
我们可以逆着增广路来想,每个右边被访问过的点一定对应一条匹配边,左边每个没有被访问过的点一定也对应一条匹配边(如果左边点没有被匹配他就是不完全增广路的起点了),所以我们得到结论
二 分 图 最 小 点 覆 盖 = 二 分 图 最 大 匹 配 数 \boxed{二分图最小点覆盖=二分图最大匹配数} 二分图最小点覆盖=二分图最大匹配数
5.二分图最大独立集
5.1 定义
二分图最大独立集是指,从二分图中选出一些点,让这些点之间互相没有边相连
5.2 二分图最大独立集定理
内容
二分图最大独立集=总点数-二分图最小点覆盖=总点数-二分图最大匹配数
证明
一句话证明:把最小点覆盖挖掉剩下的就是最大独立集了嘛,严格的证明就不写了qwq
略去过程QED,由上可知证毕
所以我们得到结论
二 分 图 最 大 独 立 集 = 总 点 数 − 二 分 图 最 小 点 覆 盖 \boxed{二分图最大独立集=总点数-二分图最小点覆盖} 二分图最大独立集=总点数−二分图最小点覆盖
5.3 二分图最大团
定义
二分图最大独立集是指,从二分图中选出一些点,让这些点之间互相都有边相连
好像和最大独立集很像?仔细看
二分图最大独立集是指,从二分图中选出一些点,让这些点之间互相都有边相连
二分图最大团定理
这个东西我们发现,就是二分图的补图的最大独立集吗
所以求二分图最大团就是求出他的补图,然后跑最大独立集就可以了
二 分 图 最 大 团 = 二 分 图 的 补 图 的 最 大 独 立 集 \boxed{二分图最大团=二分图的补图的最大独立集} 二分图最大团=二分图的补图的最大独立集
6.DAG上最长反链
6.1 定义
DAG上最长反链是指在一个DAG上选择一些点,让这些点之间互相不连通(对于任意两个点 x x x, y y y, x x x不能到 y y y, y y y也不能到 x x x)
那么我们可以用 D i l w o r t h Dilworth Dilworth定理,一个DAG中最长反链大小,等于最小可重链覆盖大小
其实也很好理解啦,因为在一条链上的点,我们最多只能选一个,所以让可重链覆盖的大小尽量的小,那么就是最长反链的大小了
6.2 建立模型
那么这个最小可重链覆盖大小怎么求呢,我们可以把每一个点拆成两部分——出发点和到达点(这也是网络流中常见的建模方法)和他能够到达的点连一条边,然后跑最大独立集就可以了,为什么呢?因为我们连出去的每一条边,都可以抽象成一条链,我们选出来的每个点都不在一条链上,那么就是最小可重链大小了
所以我们可以先 f l o y d floyd floyd传递闭包,然后连边,然后跑最大独立集就好了
6.3 DAG上最长反链的应用
[CTSC2008] 祭祀
这道题就是一个求DAG上最长反链的模板
第一问就是构造二分图,输出最大独立集
第二问就运用我们构造最小点覆盖的方法,取反一下就是最大独立集
第三问,枚举每个点,把这个点和与其相邻的点都删掉,然后再跑最大独立集,判断如果最大独立集=第一问答案-1,说明他在最长反链上
代码:
#include 7.带权二分图匹配/二分图最优匹配
7.1 KM算法
KM算法运用到了贪心的思想其实
这里要引入一个东西——顶标,用来表达预期
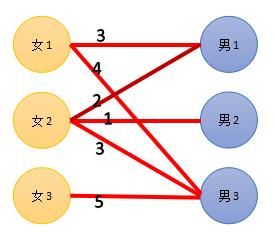
开始时,我们把左边的点的顶标设成他出边的最大值,右边设成0
我们用顶标表示我们期望的匹配的权值
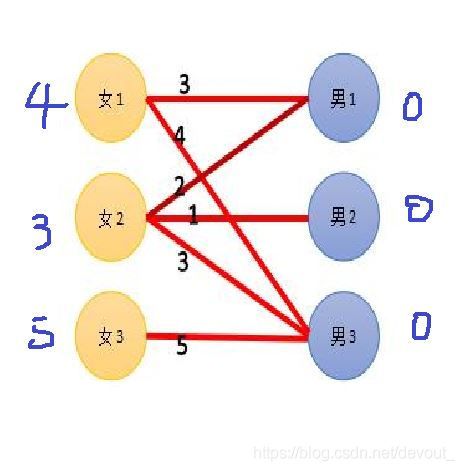
然后,还是仿照匈牙利的做法,我们枚举左边的每个点,尝试匹配,还是找增广路,但是我们只能走一条路径的边权=两端点的顶标之和的路,这样我们就保证了让匹配权值尽量大
我们先匹配1,1->1的路径上,4+0>3,不能走,1->3这条路可以走,所以我们把1和3连上
然后看2,他想去3,但是3已经被占了,所以他要降低要求,怎么降低要求呢?我们用和最小点覆盖相似的做法,找出一条不完全的增广路 2 − 3 − 1 2-3-1 2−3−1,然后找到这条路径上的左右边中,两个顶点的顶标-边权最小的那个 Δ \Delta Δ(相等的不算),然后把这条路径经过的左半部分的顶标 − Δ -\Delta −Δ,右半部分的点的顶标 + Δ +\Delta +Δ,因为这条不完全的增广路左半部分的点数比右半部分多1,所以我们这样做就可以达到减少预期的结果
第一次找完之后顶标变成
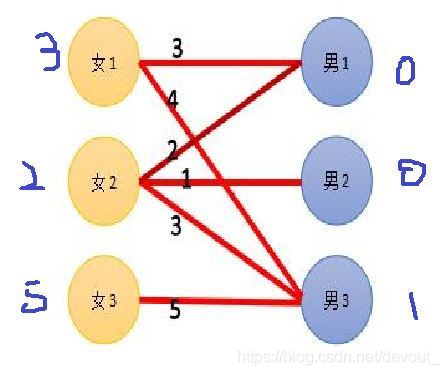
但是我们注意,这个时候,我们的2还没有匹配,左1和右3还是在一起
所以我们还要从左2出发去匹配,那么这个时候, 2 − 1 2-1 2−1这条路就可以被选择了,所以我们把左2和右1匹配上
然后我们尝试给3进行匹配,那么这个时候我们发现顶标5+1>5,所以我们再按照上面的方法把顶标降到4,然后再匹配就可以啦
简单放一下代码吧
bool dfs(int u){
if(visl[u])return false;//visl,visr分别表示左边,右边的点这次有没有被访问到
visl[u]=true;
Rep(v,1,n)//这里我默认是一个完全图
if(g[u][v]==l[u]+r[v]){
//如果可以走
visr[v]=true;//正常匈牙利
if(!match[v]||dfs(match[v])){
match[v]=u;
return true;
}
}
else delta=min(delta,l[u]+r[v]-g[u][v]);//否则找差最小的
return false;
}
void KM(){
Rep(i,1,n)
while(1){
//直到找到了才能停
delta=inf;
memset(visl,0,sizeof(visl));
memset(visr,0,sizeof(visr));
if(dfs(i))break;
Rep(i,1,n){
if(visl[i])l[i]-=delta;//更改顶标值
if(visr[i])r[i]+=delta;
}
}
}
但是注意,KM算法只能求最大完美匹配值,如果想求不完备的,就需要用下面的费用流做法了
这种KM的写法复杂度最差是 O ( n 4 ) O(n^4) O(n4)的( n 2 m n^2m n2m)
7.2 网络流求带权二分图匹配
这里运用了费用流的做法
按照题意连容量为1,费用为权值的边,跑费用流就可以
8.slack优化KM算法
我们发现,普通KM的复杂度是 O ( n 4 ) O(n^4) O(n4)实在是有点大
我们考虑能不能优化一下
我们发现,我们找 Δ \Delta Δ的值得时候因为我们只有一个数组,所以很容易求出来的 Δ \Delta Δ是容易不对的,所以优化的方法就是给右半部分的每一个点都开一个slack数组表示松弛量,然后我们找的时候就不会出现因为每次松弛量不准而造成的复杂度太大的问题了,可以证明这种做法的复杂度是 O ( n 3 ) O(n^3) O(n3)( n m nm nm)
然而我不会证qwq
代码:
bool dfs(int u,int x,int y){
if(visl[u])return false;
visl[u]=true;
Rep(v,1,n){
if(u==x&&v==y)continue;
if(lx[u]+rx[v]==g[u][v]){
visr[v]=true;
if(!match[v]||dfs(match[v],x,y)){
match[v]=u;
return true;
}
}
else if(lx[u]+rx[v]>g[u][v])slack[v]=min(slack[v],lx[u]+rx[v]-g[u][v]);//更新slack
}
return false;
}
int KM(int x,int y){
memcpy(lx,_max,sizeof(_max));
memset(match,0,sizeof(match));
memset(rx,0,sizeof(rx));
Rep(i,1,n){
memset(slack,0x3f,sizeof(slack));
while(1){
memset(visl,0,sizeof(visl));
memset(visr,0,sizeof(visr));
delta=inf;
if(dfs(i,x,y))break;
Rep(i,1,n)
if(!visr[i])delta=min(delta,slack[i]);//找走过的中slack最小的那个
Rep(i,1,n){
if(visl[i])lx[i]-=delta;
if(visr[i])rx[i]+=delta;
else slack[i]-=delta;//如果没有经过整体slack也减去松弛量
}
}
}
int res=0;
Rep(i,1,n)res+=lx[i]+rx[i];
return res;
}
9.写在最后
这篇 b l o g blog blog大概写了两个多小时吧,总算是写完了,基本上总结了一下二分图上常见的考点吧
这篇文章中的图片有的来自百度百科,但是大部分是我手画的qwq,所以顺手点个赞呗>_< (最后卖个萌qwq