- PaperWeekly
sapienst
PapersPaperwithCodeGeneralML
1.Python软件包解决DL在未见过的数据分布下性能差的问题:(1)神经网络和损失分离的模块化设计(2)强大便捷的基准测试能力(3)易于使用但难以修改(4)github:https://github.com/marrlab/domainlabTrainer和Models之间是什么关系Trainer和Models是DomainLab中的两个核心概念。Trainer是一个用于指导数据流向模型并计算S
- ChatGPT技巧大揭秘:AI写代码新境界
2401_83550420
chatgpt4.0chatgptchatgpt人工智能AI写作
ChatGPT无限次数:点击直达ChatGPT技巧大揭秘:AI写代码新境界随着人工智能技术的不断进步,开发人员现在有了更多有趣的工具来提高他们的工作效率。其中,ChatGPT作为一种基于深度学习的自然语言处理模型,已经成为许多开发者的新宠。在本文中,我们将揭秘使用ChatGPT来帮助编写代码的技巧,探索AI在编程领域的新境界。ChatGPT简介ChatGPT是一种基于大型神经网络的对话生成模型,它
- AI大模型学习:开启智能时代的新篇章
游向大厂的咸鱼
人工智能学习
随着人工智能技术的不断发展,AI大模型已经成为当今领先的技术之一,引领着智能时代的发展。这些大型神经网络模型,如OpenAI的GPT系列、Google的BERT等,在自然语言处理、图像识别、智能推荐等领域展现出了令人瞩目的能力。然而,这些模型的背后是一系列复杂的学习过程,深度学习技术的不断演进推动了AI大模型学习的发展。首先,AI大模型学习的基础是深度学习技术。深度学习是一种模仿人类大脑结构的机器
- 【循环神经网络rnn】一篇文章讲透
CX330的烟花
rnn人工智能深度学习算法python机器学习数据结构
目录引言二、RNN的基本原理代码事例三、RNN的优化方法1长短期记忆网络(LSTM)2门控循环单元(GRU)四、更多优化方法1选择合适的RNN结构2使用并行化技术3优化超参数4使用梯度裁剪5使用混合精度训练6利用分布式训练7使用预训练模型五、RNN的应用场景1自然语言处理2语音识别3时间序列预测六、RNN的未来发展七、结论引言众所周知,CNN与循环神经网络(RNN)或生成对抗网络(GAN)等算法结
- 深度学习与(复杂系统)事物的属性
科学禅道
深度学习模型专栏深度学习人工智能
深度学习与复杂系统中事物属性的关系体现在:特征学习与表示:深度学习通过多层神经网络结构,能够自动从原始输入数据中学习和提取出丰富的特征表示。每一层神经网络都可能对应着事物属性的不同抽象层次,底层可能对应简单直观的属性,而随着网络深度的增加,顶层可以学习到更抽象、复杂的属性及其相互关系。非线性关系建模:深度学习特别擅长处理非线性关系,而在复杂系统中,事物属性间的相互作用往往表现为非线性,例如,某些属
- 神经网络(深度学习,计算机视觉,得分函数,损失函数,前向传播,反向传播,激活函数)
MarkHD
深度学习神经网络计算机视觉
神经网络,特别是深度学习,在计算机视觉等领域有着广泛的应用。以下是关于你提到的几个关键概念的详细解释:神经网络:神经网络是一种模拟人脑神经元结构的计算模型,用于处理复杂的数据和模式识别任务。它由多个神经元(或称为节点)组成,这些神经元通过权重和偏置进行连接,并可以学习调整这些参数以优化性能。深度学习:深度学习是神经网络的一个子领域,主要关注于构建和训练深度神经网络(即具有多个隐藏层的神经网络)。通
- 飞桨科学计算套件PaddleScience
skywalk8163
人工智能paddlepaddle人工智能飞桨
PaddleScience是一个基于深度学习框架PaddlePaddle开发的科学计算套件,利用深度神经网络的学习能力和PaddlePaddle框架的自动(高阶)微分机制,解决物理、化学、气象等领域的问题。支持物理机理驱动、数据驱动、数理融合三种求解方式,并提供了基础API和详尽文档供用户使用与二次开发。安装当然要先安装好飞桨PaddlePaddle,再安装PaddleSciencepipinst
- 训练时损失出现负数,正常吗?为什么
苏苏大大
机器学习深度学习人工智能
在训练神经网络时,通常期望损失函数的值是非负的,因为损失函数是用来度量模型预测与真实值之间的差异的。然而,有时候在训练过程中,损失函数可能会出现负数的情况,这可能是正常的,也可能是因为某些原因导致了不寻常的行为。出现损失函数为负数的情况可能有以下几种原因:1.数值不稳定性:如果在计算损失函数时使用了数值不稳定的操作,比如过大或过小的数值,可能会导致损失函数出现负数。这可能是由于数值计算中的舍入误差
- 神经网络量化
小厂程序猿
人工智能
神经网络量化(NeuralNetworkQuantization)是一种技术,旨在减少神经网络模型的计算和存储资源需求,同时保持其性能。在深度学习中,神经网络模型通常使用高精度的参数(例如32位浮点数)来表示权重和激活值。然而,这种表示方式可能会占用大量的内存和计算资源,特别是在部署到资源受限的设备(如移动设备或嵌入式系统)时会受到限制。神经网络量化通过将模型参数和激活值从高精度表示(例如32位浮
- 神奇的微积分
科学的N次方
人工智能人工智能ai
微积分在人工智能(AI)领域扮演着至关重要的角色,以下是其主要作用:优化算法:•梯度下降法:微积分中的导数被用来计算损失函数相对于模型参数的梯度,这是许多机器学习和深度学习优化算法的核心。梯度指出了函数值增加最快的方向,通过沿着负梯度方向更新权重,可以最小化损失函数并优化模型。•反向传播:在神经网络训练中,微积分的链式法则用于计算整个网络中每个参数对于最终损失函数的影响(偏导数),这一过程就是反向
- 看见光,追逐光,成为光~
默涵在当下
高屋建瓴的人,散发着高贵气质,周遭牛人很多,咬紧他们~杜总,从看网知网背景出发,讲到发现流量痛点,讲到站点布局,讲到下一步机会,从而又契合到自动驾驶网络。从如何构建五级驾驶,到如何结合现状落地~研究字节跳动对神经网络的改造,注入人的干预分类,优化再到聚类,让算法匹配人的干预能力~基础操作效能提升达到90%,告警防护率达到90%,两者交叉防护有效率达到多少?99%一切皆可AI~一切皆可AI~优秀自觉
- 线性代数在卷积神经网络(CNN)中的体现
科学的N次方
人工智能线性代数cnn人工智能
案例:深度学习中的卷积神经网络(CNN)在图像识别领域,卷积神经网络(ConvolutionalNeuralNetworks,CNN)是一个广泛应用深度学习模型,它在人脸识别、物体识别、医学图像分析等方面取得了显著成效。CNN中的核心操作——卷积,就是一个直接体现线性代数应用的例子。假设我们正在训练一个用于识别猫和狗的图像分类器,原始输入是一幅RGB彩色图片,可以将其视为一个高度、宽度和通道数(R
- Pytorch nn.Module
霖大侠
pytorch人工智能python深度学习cnn神经网络卷积神经网络
一、torch.nn简介torch.nn是PyTorch中用于构建神经网络的模块。它提供了一系列的类和函数,用于定义神经网络的各种层、损失函数、优化器等。torch.nn提供的类:Module:所有神经网络模型的基类,用于定义自定义神经网络模型。Linear:线性层,进行线性变换。Conv2d:二维卷积层。RNN,LSTM,GRU:循环神经网络层,分别对应简单RNN、长短时记忆网络(LSTM)、门
- 计算机设计大赛 题目:基于卷积神经网络的手写字符识别 - 深度学习
iuerfee
python
文章目录0前言1简介2LeNet-5模型的介绍2.1结构解析2.2C1层2.3S2层S2层和C3层连接2.4F6与C5层3写数字识别算法模型的构建3.1输入层设计3.2激活函数的选取3.3卷积层设计3.4降采样层3.5输出层设计4网络模型的总体结构5部分实现代码6在线手写识别7最后0前言优质竞赛项目系列,今天要分享的是基于卷积神经网络的手写字符识别该项目较为新颖,适合作为竞赛课题方向,学长非常推荐
- 神经网络模型的保存和读取
tiny_PIkid
基于pytorch的深度学习pytorch神经网络深度学习
保存神经网络的两种方法:(还是以我之前自建的神经网络模型Gu为例,保存这个神经网络)gu=Gu()1.torch.save(gu,"gu_module.pth")2.torch.save(gu.state_dict(),"gu_module.pth")importtorchfromtorchimportnnfromtorch.nnimportSequential,Conv2d,MaxPool2d,
- 基于Python和OpenCV的产品码识别与验证案例
GT开发算法工程师
pythonopencv开发语言人工智能计算机视觉
引言:本案例展示了如何使用Python结合OpenCV库来实现产品码的识别与验证。首先,通过图像预处理技术(如灰度化、二值化、降噪等)优化产品码图像,然后利用OpenCV中的模板匹配或机器学习算法(如SVM、神经网络等)来定位并识别产品码。目录原理:代码部分:注意:原理:产品码识别与验证的核心在于图像处理与模式识别技术。首先,通过图像处理技术提取出产品码区域,去除背景干扰,增强产品码的可识别性。然
- 图像算法实习生--面经1
小豆包的小朋友0217
算法
系列文章目录文章目录系列文章目录前言一、为什么torch里面要用optimizer.zero_grad()进行梯度置0二、Unet神经网络为什么会在医学图像分割表现好?三、transformer相关问题四、介绍一下胶囊网络的动态路由五、yolo系列出到v9了,介绍一下你最熟悉的yolo算法六、一阶段目标检测算法和二阶段目标检测算法有什么区别?七、讲一下剪枝八、讲一下PTQandQAT量化的区别九、
- 深度学习——梯度消失、梯度爆炸
小羊头发长
深度学习机器学习人工智能
本文参考:深度学习之3——梯度爆炸与梯度消失梯度消失和梯度爆炸的根源:深度神经网络结构、反向传播算法目前优化神经网络的方法都是基于反向传播的思想,即根据损失函数计算的误差通过反向传播的方式,指导深度网络权值的更新。为什么神经网络优化用到梯度下降的优化方法?深度网络是由许多非线性层(带有激活函数)堆叠而成,每一层非线性层可以视为一个非线性函数f(x),因此整个深度网络可以视为一个复合的非线性多元函数
- 深度学习如何入门?
nanshaws
yolov5深度学习
深度学习是机器学习的一个子领域,它基于人工神经网络的研究。入门深度学习可以分为以下几个步骤:基础知识准备:(1)掌握基础数学知识,特别是线性代数、概率论和统计学、微积分。(2)学习编程语言,Python是目前最流行的深度学习语言,因其简洁易学且有大量的库支持。(3)了解机器学习基础,包括监督学习和非监督学习的概念、模型评估与选择等。学习深度学习理论:(1)理解神经网络的基本组成,如神经元、激活函数
- 从零使用Python 实现对抗神经网络GAN
算法channel
神经网络python生成对抗网络开发语言人工智能
你好,我是郭震这篇从零使用Python,实现生成对抗网络(GAN)的基本版本。GAN使用两套网络,分别是判别器(D)网络和生成器(G)网络,最重要的是弄清楚每套网络的输入和输出分别是什么,两套网络如何结合在一起,及优化的目标即costfunction如何定义。通俗来讲,两套网络结合的方法,就是G会从D的判分中不断提升生成能力,要知道G最开始的输入全部是噪点,这个思想也是文生图,文生视频的基石。下面
- PyTorch 实现图像卷积和反卷积操作及代码
算法channel
pytorch人工智能python深度学习机器学习
你好,我是郭震在深度学习中,尤其是在处理图像相关任务时,卷积和反卷积(转置卷积)都是非常核心的概念。它们在神经网络中扮演着重要的角色,但用途和工作原理有所不同。以下是对传统卷积和反卷积的介绍,以及它们在PyTorch中的应用示例。传统卷积(nn.Conv2d)用途传统卷积通常用于特征提取。在处理图像时,通过应用卷积核(也称为滤波器)来扫描输入图像或特征映射,可以有效地识别图像中的局部特征(如边缘、
- 【深度学习模型】6_3 语言模型数据集
RIKI_1
深度学习深度学习语言模型人工智能
注:本文为《动手学深度学习》开源内容,部分标注了个人理解,仅为个人学习记录,无抄袭搬运意图6.3语言模型数据集(周杰伦专辑歌词)本节将介绍如何预处理一个语言模型数据集,并将其转换成字符级循环神经网络所需要的输入格式。为此,我们收集了周杰伦从第一张专辑《Jay》到第十张专辑《跨时代》中的歌词,并在后面几节里应用循环神经网络来训练一个语言模型。当模型训练好后,我们就可以用这个模型来创作歌词。6.3.1
- 机器学习、深度学习、神经网络之间的关系
你好,工程师
AI机器学习
机器学习(MachineLearning)、深度学习(DeepLearning)和神经网络(NeuralNetworks)之间存在密切的关系,它们可以被看作是一种逐层递进的关系。下面简要介绍它们之间的关系:机器学习(MachineLearning):机器学习是一种人工智能的分支,关注如何通过数据让计算机系统从经验中学习,提高性能。机器学习算法可以分为监督学习、无监督学习、半监督学习和强化学习等不同
- 【深度学习笔记】6_4 循环神经网络的从零开始实现
RIKI_1
深度学习深度学习笔记rnn
注:本文为《动手学深度学习》开源内容,部分标注了个人理解,仅为个人学习记录,无抄袭搬运意图6.4循环神经网络的从零开始实现在本节中,我们将从零开始实现一个基于字符级循环神经网络的语言模型,并在周杰伦专辑歌词数据集上训练一个模型来进行歌词创作。首先,我们读取周杰伦专辑歌词数据集:importtimeimportmathimportnumpyasnpimporttorchfromtorchimport
- ENAS:首个权值共享的神经网络搜索方法,千倍加速 | ICML 2018
VincentTeddy
NAS是自动设计网络结构的重要方法,但需要耗费巨大的资源,导致不能广泛地应用,而论文提出的EfficientNeuralArchitectureSearch(ENAS),在搜索时对子网的参数进行共享,相对于NAS有超过1000x倍加速,单卡搜索不到半天,而且性能并没有降低,十分值得参考 来源:【晓飞的算法工程笔记】公众号论文:EfficientNeuralArchitectureSearchvia
- 深度学习,人工智能总结
qq_14827935
人工智能深度学习
1,入门建议少看书,多看csdn上帖子总结(主要就是BP神经网络,CNN,rnn),建立宏观的概念和主要框架,书可以作为进阶补充作为工具书查阅。2,目前的神经网络还处于前牛顿时代,就是实践中图像识别效果很好,但是原理不太清楚3,现在的人工智能有点像通信行业2g时代,从2012年alexnet到openai的chatgpt,未来还有很长的发展潜力。丰田不是汽车的发明者,但现在销量最高。oepnai在
- 【深度学习笔记】6_10 双向循环神经网络bi-rnn
RIKI_1
深度学习深度学习笔记rnn
注:本文为《动手学深度学习》开源内容,部分标注了个人理解,仅为个人学习记录,无抄袭搬运意图6.10双向循环神经网络之前介绍的循环神经网络模型都是假设当前时间步是由前面的较早时间步的序列决定的,因此它们都将信息通过隐藏状态从前往后传递。有时候,当前时间步也可能由后面时间步决定。例如,当我们写下一个句子时,可能会根据句子后面的词来修改句子前面的用词。双向循环神经网络通过增加从后往前传递信息的隐藏层来更
- Python图像处理【21】基于卷积神经网络增强微光图像
AI technophile
Python图像处理实战python图像处理cnn
基于卷积神经网络增强微光图像0.前言1.MBLLEN网络架构2.增强微光图像小结系列链接0.前言在本节中,我们将学习如何基于预训练的深度学习模型执行微光/夜间图像增强。由于难以同时处理包括亮度、对比度、伪影和噪声在内的所有因素,因此微光图像增强一直是一项具有挑战性的问题。为了解决这一问题,提出了多分支微光增强网络(multi-branchlow-lightenhancementnetwork,MB
- 精读《深度学习 - 函数式之美》
可口可乐Vip
前端深度学习人工智能
1引言函数式语言在深度学习领域应用很广泛,因为函数式与深度学习模型的契合度很高,TheBeautyofFunctionalLanguagesinDeepLearning — ClojureandHaskell就很好的诠释了这个道理。通过这篇文章可以加深我们对深度学习与函数式编程的理解。2概述与精读深度学习是机器学习中基于人工神经网络模型的一个分支,通过模拟多层神经元的自编码神经网络,将特征逐步抽象
- Transformer、BERT和GPT 自然语言处理领域的重要模型
Jiang_Immortals
人工智能自然语言处理transformerbert
Transformer、BERT和GPT都是自然语言处理领域的重要模型,它们之间有一些区别和联系。区别:架构:Transformer是一种基于自注意力机制的神经网络架构,用于编码输入序列和解码输出序列。BERT(BidirectionalEncoderRepresentationsfromTransformers)是基于Transformer架构的双向编码模型,用于学习上下文无关的词向量表示。GP
- LeetCode[Math] - #66 Plus One
Cwind
javaLeetCode题解AlgorithmMath
原题链接:#66 Plus One
要求:
给定一个用数字数组表示的非负整数,如num1 = {1, 2, 3, 9}, num2 = {9, 9}等,给这个数加上1。
注意:
1. 数字的较高位存在数组的头上,即num1表示数字1239
2. 每一位(数组中的每个元素)的取值范围为0~9
难度:简单
分析:
题目比较简单,只须从数组
- JQuery中$.ajax()方法参数详解
AILIKES
JavaScriptjsonpjqueryAjaxjson
url: 要求为String类型的参数,(默认为当前页地址)发送请求的地址。
type: 要求为String类型的参数,请求方式(post或get)默认为get。注意其他http请求方法,例如put和 delete也可以使用,但仅部分浏览器支持。
timeout: 要求为Number类型的参数,设置请求超时时间(毫秒)。此设置将覆盖$.ajaxSetup()方法的全局
- JConsole & JVisualVM远程监视Webphere服务器JVM
Kai_Ge
JVisualVMJConsoleWebphere
JConsole是JDK里自带的一个工具,可以监测Java程序运行时所有对象的申请、释放等动作,将内存管理的所有信息进行统计、分析、可视化。我们可以根据这些信息判断程序是否有内存泄漏问题。
使用JConsole工具来分析WAS的JVM问题,需要进行相关的配置。
首先我们看WAS服务器端的配置.
1、登录was控制台https://10.4.119.18
- 自定义annotation
120153216
annotation
Java annotation 自定义注释@interface的用法 一、什么是注释
说起注释,得先提一提什么是元数据(metadata)。所谓元数据就是数据的数据。也就是说,元数据是描述数据的。就象数据表中的字段一样,每个字段描述了这个字段下的数据的含义。而J2SE5.0中提供的注释就是java源代码的元数据,也就是说注释是描述java源
- CentOS 5/6.X 使用 EPEL YUM源
2002wmj
centos
CentOS 6.X 安装使用EPEL YUM源1. 查看操作系统版本[root@node1 ~]# uname -a Linux node1.test.com 2.6.32-358.el6.x86_64 #1 SMP Fri Feb 22 00:31:26 UTC 2013 x86_64 x86_64 x86_64 GNU/Linux [root@node1 ~]#
- 在SQLSERVER中查找缺失和无用的索引SQL
357029540
SQL Server
--缺失的索引
SELECT avg_total_user_cost * avg_user_impact * ( user_scans + user_seeks ) AS PossibleImprovement ,
last_user_seek ,
- Spring3 MVC 笔记(二) —json+rest优化
7454103
Spring3 MVC
接上次的 spring mvc 注解的一些详细信息!
其实也是一些个人的学习笔记 呵呵!
- 替换“\”的时候报错Unexpected internal error near index 1 \ ^
adminjun
java“\替换”
发现还是有些东西没有刻子脑子里,,过段时间就没什么概念了,所以贴出来...以免再忘...
在拆分字符串时遇到通过 \ 来拆分,可是用所以想通过转义 \\ 来拆分的时候会报异常
public class Main {
/*
- POJ 1035 Spell checker(哈希表)
aijuans
暴力求解--哈希表
/*
题意:输入字典,然后输入单词,判断字典中是否出现过该单词,或者是否进行删除、添加、替换操作,如果是,则输出对应的字典中的单词
要求按照输入时候的排名输出
题解:建立两个哈希表。一个存储字典和输入字典中单词的排名,一个进行最后输出的判重
*/
#include <iostream>
//#define
using namespace std;
const int HASH =
- 通过原型实现javascript Array的去重、最大值和最小值
ayaoxinchao
JavaScriptarrayprototype
用原型函数(prototype)可以定义一些很方便的自定义函数,实现各种自定义功能。本次主要是实现了Array的去重、获取最大值和最小值。
实现代码如下:
<script type="text/javascript">
Array.prototype.unique = function() {
var a = {};
var le
- UIWebView实现https双向认证请求
bewithme
UIWebViewhttpsObjective-C
什么是HTTPS双向认证我已在先前的博文 ASIHTTPRequest实现https双向认证请求
中有讲述,不理解的读者可以先复习一下。本文是用UIWebView来实现对需要客户端证书验证的服务请求,网上有些文章中有涉及到此内容,但都只言片语,没有讲完全,更没有完整的代码,让人困扰不已。但是此知
- NoSQL数据库之Redis数据库管理(Redis高级应用之事务处理、持久化操作、pub_sub、虚拟内存)
bijian1013
redis数据库NoSQL
3.事务处理
Redis对事务的支持目前不比较简单。Redis只能保证一个client发起的事务中的命令可以连续的执行,而中间不会插入其他client的命令。当一个client在一个连接中发出multi命令时,这个连接会进入一个事务上下文,该连接后续的命令不会立即执行,而是先放到一个队列中,当执行exec命令时,redis会顺序的执行队列中
- 各数据库分页sql备忘
bingyingao
oraclesql分页
ORACLE
下面这个效率很低
SELECT * FROM ( SELECT A.*, ROWNUM RN FROM (SELECT * FROM IPAY_RCD_FS_RETURN order by id desc) A ) WHERE RN <20;
下面这个效率很高
SELECT A.*, ROWNUM RN FROM (SELECT * FROM IPAY_RCD_
- 【Scala七】Scala核心一:函数
bit1129
scala
1. 如果函数体只有一行代码,则可以不用写{},比如
def print(x: Int) = println(x)
一行上的多条语句用分号隔开,则只有第一句属于方法体,例如
def printWithValue(x: Int) : String= println(x); "ABC"
上面的代码报错,因为,printWithValue的方法
- 了解GHC的factorial编译过程
bookjovi
haskell
GHC相对其他主流语言的编译器或解释器还是比较复杂的,一部分原因是haskell本身的设计就不易于实现compiler,如lazy特性,static typed,类型推导等。
关于GHC的内部实现有篇文章说的挺好,这里,文中在RTS一节中详细说了haskell的concurrent实现,里面提到了green thread,如果熟悉Go语言的话就会发现,ghc的concurrent实现和Go有点类
- Java-Collections Framework学习与总结-LinkedHashMap
BrokenDreams
LinkedHashMap
前面总结了java.util.HashMap,了解了其内部由散列表实现,每个桶内是一个单向链表。那有没有双向链表的实现呢?双向链表的实现会具备什么特性呢?来看一下HashMap的一个子类——java.util.LinkedHashMap。
- 读《研磨设计模式》-代码笔记-抽象工厂模式-Abstract Factory
bylijinnan
abstract
声明: 本文只为方便我个人查阅和理解,详细的分析以及源代码请移步 原作者的博客http://chjavach.iteye.com/
package design.pattern;
/*
* Abstract Factory Pattern
* 抽象工厂模式的目的是:
* 通过在抽象工厂里面定义一组产品接口,方便地切换“产品簇”
* 这些接口是相关或者相依赖的
- 压暗面部高光
cherishLC
PS
方法一、压暗高光&重新着色
当皮肤很油又使用闪光灯时,很容易在面部形成高光区域。
下面讲一下我今天处理高光区域的心得:
皮肤可以分为纹理和色彩两个属性。其中纹理主要由亮度通道(Lab模式的L通道)决定,色彩则由a、b通道确定。
处理思路为在保持高光区域纹理的情况下,对高光区域着色。具体步骤为:降低高光区域的整体的亮度,再进行着色。
如果想简化步骤,可以只进行着色(参看下面的步骤1
- Java VisualVM监控远程JVM
crabdave
visualvm
Java VisualVM监控远程JVM
JDK1.6开始自带的VisualVM就是不错的监控工具.
这个工具就在JAVA_HOME\bin\目录下的jvisualvm.exe, 双击这个文件就能看到界面
通过JMX连接远程机器, 需要经过下面的配置:
1. 修改远程机器JDK配置文件 (我这里远程机器是linux).
- Saiku去掉登录模块
daizj
saiku登录olapBI
1、修改applicationContext-saiku-webapp.xml
<security:intercept-url pattern="/rest/**" access="IS_AUTHENTICATED_ANONYMOUSLY" />
<security:intercept-url pattern=&qu
- 浅析 Flex中的Focus
dsjt
htmlFlexFlash
关键字:focus、 setFocus、 IFocusManager、KeyboardEvent
焦点、设置焦点、获得焦点、键盘事件
一、无焦点的困扰——组件监听不到键盘事件
原因:只有获得焦点的组件(确切说是InteractiveObject)才能监听到键盘事件的目标阶段;键盘事件(flash.events.KeyboardEvent)参与冒泡阶段,所以焦点组件的父项(以及它爸
- Yii全局函数使用
dcj3sjt126com
yii
由于YII致力于完美的整合第三方库,它并没有定义任何全局函数。yii中的每一个应用都需要全类别和对象范围。例如,Yii::app()->user;Yii::app()->params['name'];等等。我们可以自行设定全局函数,使得代码看起来更加简洁易用。(原文地址)
我们可以保存在globals.php在protected目录下。然后,在入口脚本index.php的,我们包括在
- 设计模式之单例模式二(解决无序写入的问题)
come_for_dream
单例模式volatile乱序执行双重检验锁
在上篇文章中我们使用了双重检验锁的方式避免懒汉式单例模式下由于多线程造成的实例被多次创建的问题,但是因为由于JVM为了使得处理器内部的运算单元能充分利用,处理器可能会对输入代码进行乱序执行(Out Of Order Execute)优化,处理器会在计算之后将乱序执行的结果进行重组,保证该
- 程序员从初级到高级的蜕变
gcq511120594
框架工作PHPandroidhtml5
软件开发是一个奇怪的行业,市场远远供不应求。这是一个已经存在多年的问题,而且随着时间的流逝,愈演愈烈。
我们严重缺乏能够满足需求的人才。这个行业相当年轻。大多数软件项目是失败的。几乎所有的项目都会超出预算。我们解决问题的最佳指导方针可以归结为——“用一些通用方法去解决问题,当然这些方法常常不管用,于是,唯一能做的就是不断地尝试,逐个看看是否奏效”。
现在我们把淫浸代码时间超过3年的开发人员称为
- Reverse Linked List
hcx2013
list
Reverse a singly linked list.
/**
* Definition for singly-linked list.
* public class ListNode {
* int val;
* ListNode next;
* ListNode(int x) { val = x; }
* }
*/
p
- Spring4.1新特性——数据库集成测试
jinnianshilongnian
spring 4.1
目录
Spring4.1新特性——综述
Spring4.1新特性——Spring核心部分及其他
Spring4.1新特性——Spring缓存框架增强
Spring4.1新特性——异步调用和事件机制的异常处理
Spring4.1新特性——数据库集成测试脚本初始化
Spring4.1新特性——Spring MVC增强
Spring4.1新特性——页面自动化测试框架Spring MVC T
- C# Ajax上传图片同时生成微缩图(附Demo)
liyonghui160com
1.Ajax无刷新上传图片,详情请阅我的这篇文章。(jquery + c# ashx)
2.C#位图处理 System.Drawing。
3.最新demo支持IE7,IE8,Fir
- Java list三种遍历方法性能比较
pda158
java
从c/c++语言转向java开发,学习java语言list遍历的三种方法,顺便测试各种遍历方法的性能,测试方法为在ArrayList中插入1千万条记录,然后遍历ArrayList,发现了一个奇怪的现象,测试代码例如以下:
package com.hisense.tiger.list;
import java.util.ArrayList;
import java.util.Iterator;
- 300个涵盖IT各方面的免费资源(上)——商业与市场篇
shoothao
seo商业与市场IT资源免费资源
A.网站模板+logo+服务器主机+发票生成
HTML5 UP:响应式的HTML5和CSS3网站模板。
Bootswatch:免费的Bootstrap主题。
Templated:收集了845个免费的CSS和HTML5网站模板。
Wordpress.org|Wordpress.com:可免费创建你的新网站。
Strikingly:关注领域中免费无限的移动优
- localStorage、sessionStorage
uule
localStorage
W3School 例子
HTML5 提供了两种在客户端存储数据的新方法:
localStorage - 没有时间限制的数据存储
sessionStorage - 针对一个 session 的数据存储
之前,这些都是由 cookie 完成的。但是 cookie 不适合大量数据的存储,因为它们由每个对服务器的请求来传递,这使得 cookie 速度很慢而且效率也不
 :模型,
:模型, :特征提取器,
:特征提取器, :分类器,
:分类器, :有限训练数据存储
:有限训练数据存储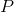 :旧类被学习时的初始状态,
:旧类被学习时的初始状态, :当前增加新类后的状态,
:当前增加新类后的状态, :state数
:state数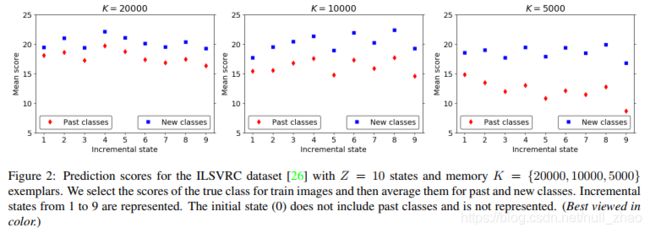

 训练数据的,平均分类scores(即网络原始输出)。由图2有,
训练数据的,平均分类scores(即网络原始输出)。由图2有,