JS(正则|JSON)
* JSON
1. 基础知识
1、$("#ddlLevel").empty(); 移除备选元素中所有内容
$("#ddlLevel").show(); 移除备选元素中所有内容,包括备选元素
var type = parseInt($("#ddlType").val());
var jsonTemp = eval("(" + msg + ")");
"day": new Date().getDate()
2. json和字符串转换

1、json对象转换为json字符串: JSON.stringify(obj);
2、json字符串转换为json对象: JSON.parse(str); 或者 eval("("+str+")") ; json字符串格式:
var json = '{"name":"Harvy", "age":36, "gender":"male"}'; //注意外面的''单引号不要忘记了
3. eval()
注:eval函数接收一个参数s,若s不是字符串则直接返回s;若s是字符串则执行s语句,如果s语句执行结果是一个值则返回此值,否则返回undefined;
对象声明语法{}不能返回一个值,需要用括号括起来转换为表达式,才会返回值。
var code1 = '"a" + 2'; //表达式 var code2='{a:2}'; //语句 var code3 = {a :2}; //对象, eval(code2); // 2,当成语句来执行 eval(code3); // {a :2},不是字符串直接返回 eval("("+code2+")"); // {a :2},添加()转换为表达式,才能计算其值 eval("var k = 3"); //声明了一个变量k=3


1 var JSONObject = { 2 "name":"菜鸟教程", 3 "url":"www.runoob.com", 4 "slogan":"学的不仅是技术,更是梦想!" 5 }; 6 7 console.log(JSON.stringify(JSONObject)); 8 9 //对象,JSON.parse 的第二个参数 reviver,一个转换结果的函数,对象的每个成员调用此函数 10 var text = '{ "name":"Runoob", "initDate":"2013-12-14", "site":"www.runoob.com"}'; 11 var obj = JSON.parse(text, function (key, value) { 12 if (key == "initDate") { 13 return new Date(value); 14 } else { 15 return value; 16 }}); 17 18 document.getElementById("demo").innerHTML = obj.name + "创建日期:" + obj.initDate; 19 20 21 //数组 22 "sites":[ 23 {"name":"Runoob", "url":"www.runoob.com"}, 24 {"name":"Google", "url":"www.google.com"}, 25 {"name":"Taobao", "url":"www.taobao.com"} 26 ] 27 28 29 //eval(string):函数可计算某个字符串,并执行其中的的 JavaScript 代码。 30 eval("var a=1"); // 声明一个变量a并赋值1。 31 eval("2+3"); // 执行加运算,并返回运算值。 32 eval("mytest()"); // 执行mytest()函数。 33 eval("{b:2}"); // 声明一个对象。 34 35 36 //使用 JSON.parse 的 reviver 函数时一定要注意遍历到最后的顶层对象 key 为 "",需要返回 value。 37 38 var json = '{"name":"Harvy", "age":36, "gender":"male"}'; 39 var person = JSON.parse(json, function (key, value) { 40 if(key != "") 41 return ""+value+""; 42 else 43 return value; 44 });
* 正则表达式
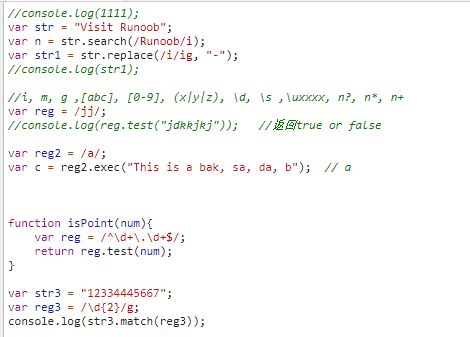
1、正向负向预查
eg:var s1 = "abcdkgjkjk233ab213332k";
1.1 (exp)
var k1 = s1.match(/ab(c)/); // k1 = ["abc", "c"] 匹配abc,并且将c保存在结果中1.2 (?:exp)
var k2 = s1.match(/ab(?:c)/); //k2 = ["abc"] 匹配abc,不会将c保存在结果中1.3 (?=exp)
//匹配ab,c启限定作用,当解析器找到ab后没有马上放回,而是再查看ab后面是c吗?如果是才返回ab,佛则匹配失败。 【正向预查】
var k3 = s1.match(/ab(?=c)/); //k3= ["ab"] ["ab", index: 0, input: "abcdkgjkjk233ab213332k", groups: undefined]1.4 (?!exp)
//匹配后面不是紧跟c的ab。【负向预查】
var k4 = s1.match(/ab(?!c)/); //k4= ["ab"] ["ab", index: 13, input: "abcdkgjkjk233ab213332k", groups: undefined]//console.log(1111);
var str = "Visit Runoob";
var n = str.search(/Runoob/i); //返回xiab
var str1 = str.replace(/i/ig, "-");
console.log(n);
//i, m, g ,[abc], [0-9], (x|y|z), \d, \s ,\uxxxx, n?, n*, n+
var reg = /jj/;
//console.log(reg.test("jdkkjkj")); //返回true or false
var reg2 = /a/;
var c = reg2.exec("This is a bak, sa, da, b"); // a
function isPoint(num){
var reg = /^\d+\.\d+$/;
return reg.test(num);
}
var str3 = "12334445667";
var reg3 = /\d{2}/;
console.log(str3.match(reg3));
2、正则表达式的创建方式
- 字面量创建方式,不能进行字符串拼接,特殊含义字符不用转义
- 实例创建方式,可以字符串拼接,特殊含义字符需要转义
var reg = /pattern/flags 字面量创建方式
var reg = new RegExp(pattern,flags); 实例创建方式
pattern:正则表达式
flags:标识(修饰符) 标识主要包括:
1. i 忽略大小写匹配
2. m 多行匹配,即在到达一行文本末尾时还会继续寻常下一行中是否与正则匹配的项
3. g 全局匹配 模式应用于所有字符串,而非在找到第一个匹配项时停止
//字面量创建方式不能进行字符串拼接,实例创建方式可以 var regParam = 'cm'; var reg1 = new RegExp(regParam+'1'); var reg2 = /regParam/; console.log(reg1); // /cm1/ console.log(reg2); // /regParam/ //字面量创建方式特殊含义的字符不需要转义,实例创建方式需要转义 var reg1 = new RegExp('\d'); // /d/ var reg2 = new RegExp('\\d') // /\d/ var reg3 = /\d/; // /\d/
3、元字符
见上图
量词出现在元字符后面 如\d+,限定出现在前面的元字符的次数
var str = '1223334444'; var reg = /\d{2}/g; var res = str.match(reg); console.log(res) //["12", "23", "33", "44", "44"] var str =' 我是空格君 '; var reg = /^\s+|\s+$/g; //匹配开头结尾空格 var res = str.replace(reg,''); console.log('('+res+')') //(我是空格君)
正则中的()和[]和重复子项 //拿出来单独说一下
注:一般[]中的字符没有特殊含义 如+就表示+, 但是像\w这样的还是有特殊含义的
var str1 = 'abc'; var str2 = 'dbc'; var str3 = '.bc'; var reg = /[ab.]bc/; //此时的.就表示. reg.test(str1) //true reg.test(str2) //false reg.test(str3) //true
注:[]中,不会出现两位数,即匹配的结果只是一位数
//[12]表示1或者2 [0-9]这样的表示0到9 [a-z]表示a到z //例如:匹配从18到65年龄段所有的人 var reg = /[18-65]/; // 这样写对么 reg.test('50') 实际上我们匹配这个18-65年龄段的正则我们要拆开来匹配 我们拆成3部分来匹配 18-19 20-59 60-65 reg = /(18|19)|([2-5]\d)|(6[0-5])/; //正确
()的提高优先级功能:凡是有|出现的时候,我们一定要注意是否有必要加上()来提高优先级;
()的分组 重复子项 (两个放到一起说)
分组:
只要正则中出现了小括号那么就会形成一份分组
只要有分组,exec(match)和replace中的结果就会发生改变(后边的正则方法中再说)
分组的引用(重复子项) :
只要在正则中出现了括号就会形成一个分组,我们可以通过\n (n是数字代表的是第几个分组)来引用这个分组,第一个小分组我们可以用\1来表示
例如:求出这个字符串'abAAbcBCCccdaACBDDabcccddddaab'中出现最多的字母,并求出出现多少次(忽略大小写)。
var str = 'abbbbAAbcBCCccdaACBDDabcccddddaab';
str = str.toLowerCase().split('').sort(function(a,b){return a.localeCompare(b)}).join(''); var reg = /(\w)\1+/ig; var maxStr = ''; var maxLen = 0; str.replace(reg,function($0,$1){ var regLen = $0.length; if(regLen>maxLen){ maxLen = regLen; maxStr = $1; }else if(maxLen == regLen){ maxStr += $1; } }) console.log(`出现最多的字母是${maxStr},共出现了${maxLen}次`)- 当我们加()只是为了提高优先级而不想捕获小分组时,可以在()中加?:来取消分组的捕获
var str = 'aaabbb';
var reg = /(a+)(?:b+)/;
var res =reg.exec(str); console.log(res) //["aaabbb", "aaa", index: 0, input: "aaabbb"] //只捕获第一个小分组的内容2、正则运算符的优先级
- 正则表达式从左到右进行计算,并遵循优先级顺序,这与算术表达式非常类似。
- 相同优先级的会从左到右进行运算,不同优先级的运算先高后低。
下面是常见的运算符的优先级排列
依次从最高到最低说明各种正则表达式运算符的优先级顺序:
\ : 转义符
(), (?:), (?=), [] => 圆括号和方括号
*, +, ?, {n}, {n,}, {n,m} => 量词限定符
^, $, \任何元字符、任何字符
| => 替换,"或"操作
字符具有高于替换运算符的优先级,一般用 | 的时候,为了提高 | 的优先级,我们常用()来提高优先级
如: 匹配 food或者foot的时候 reg = /foo(t|d)/ 这样来匹配正则的特性
-
贪婪性
所谓的贪婪性就是正则在捕获时,每一次会尽可能多的去捕获符合条件的内容。
如果我们想尽可能的少的去捕获符合条件的字符串的话,可以在量词元字符后加? -
懒惰性
懒惰性则是正则在成功捕获一次后不管后边的字符串有没有符合条件的都不再捕获。
如果想捕获目标中所有符合条件的字符串的话,我们可以用标识符g来标明是全局捕获
var str = '123aaa456';
var reg = /\d+/; //只捕获一次,一次尽可能多的捕获
var res = str.match(reg)
console.log(res)
// ["123", index: 0, input: "123aaa456"] reg = /\d+?/g; //解决贪婪性、懒惰性 res = str.match(reg) console.log(res) // ["1", "2", "3", "4", "5", "6"]3、和正则相关的一些方法
这里我们只介绍test、exec、match和replace这四个方法
- reg.test(str) 用来验证字符串是否符合正则 符合返回true 否则返回false
var str = 'abc';
var reg = /\w+/;
console.log(reg.test(str)); //true- reg.exec() 用来捕获符合规则的字符串
var str = 'abc123cba456aaa789';
var reg = /\d+/;
console.log(reg.exec(str))
// ["123", index: 3, input: "abc123cba456aaa789"]; console.log(reg.lastIndex) // lastIndex : 0 reg.exec捕获的数组中 // [0:"123",index:3,input:"abc123cba456aaa789"] 0:"123" 表示我们捕获到的字符串 index:3 表示捕获开始位置的索引 input 表示原有的字符串 当我们用exec进行捕获时,如果正则没有加'g'标识符,则exec捕获的每次都是同一个,当正则中有'g'标识符时 捕获的结果就不一样了,我们还是来看刚刚的例子
var str = 'abc123cba456aaa789';
var reg = /\d+/g; //此时加了标识符g console.log(reg.lastIndex) // lastIndex : 0 console.log(reg.exec(str)) // ["123", index: 3, input: "abc123cba456aaa789"] console.log(reg.lastIndex) // lastIndex : 6 console.log(reg.exec(str)) // ["456", index: 9, input: "abc123cba456aaa789"] console.log(reg.lastIndex) // lastIndex : 12 console.log(reg.exec(str)) // ["789", index: 15, input: "abc123cba456aaa789"] console.log(reg.lastIndex) // lastIndex : 18 console.log(reg.exec(str)) // null console.log(reg.lastIndex) // lastIndex : 0 每次调用exec方法时,捕获到的字符串都不相同 lastIndex :这个属性记录的就是下一次捕获从哪个索引开始。 当未开始捕获时,这个值为0。 如果当前次捕获结果为null。那么lastIndex的值会被修改为0.下次从头开始捕获。 而且这个lastIndex属性还支持人为赋值。 exec的捕获还受分组()的影响
var str = '2017-01-05';
var reg = /-(\d+)/g
// ["-01", "01", index: 4, input: "2017-01-05"] "-01" : 正则捕获到的内容 "01" : 捕获到的字符串中的小分组中的内容- str.match(reg) 如果匹配成功,就返回匹配成功的数组,如果匹配不成功,就返回null
//match和exec的用法差不多
var str = 'abc123cba456aaa789';
var reg = /\d+/;
console.log(reg.exec(str)); //["123", index: 3, input: "abc123cba456aaa789"] console.log(str.match(reg)); //["123", index: 3, input: "abc123cba456aaa789"]上边两个方法console的结果有什么不同呢?二个字符串是一样滴。
当我们进行全局匹配时,二者的不同就会显现出来了.
var str = 'abc123cba456aaa789';
var reg = /\d+/g;
console.log(reg.exec(str));
// ["123", index: 3, input: "abc123cba456aaa789"] console.log(str.match(reg)); // ["123", "456", "789"]当全局匹配时,match方法会一次性把符合匹配条件的字符串全部捕获到数组中,
如果想用exec来达到同样的效果需要执行多次exec方法。
我们可以尝试着用exec来简单模拟下match方法的实现。
String.prototype.myMatch = function (reg) {
var arr = []; var res = reg.exec(this); if (reg.global) { while (res) { arr.push(res[0]); res = reg.exec(this) } }else{ arr.push(res[0]); } return arr; } var str = 'abc123cba456aaa789'; var reg = /\d+/; console.log(str.myMatch(reg)) // ["123"] var str = 'abc123cba456aaa789'; var reg = /\d+/g; console.log(str.myMatch(reg)) // ["123", "456", "789"]此外,match和exec都可以受到分组()的影响,不过match只在没有标识符g的情况下才显示小分组的内容,如果有全局g,则match会一次性全部捕获放到数组中
var str = 'abc';
var reg = /(a)(b)(c)/;
console.log( str.match(reg) );
// ["abc", "a", "b", "c", index: 0, input: "abc"] console.log( reg.exec(str) ); // ["abc", "a", "b", "c", index: 0, input: "abc"] 当有全局g的情况下 var str = 'abc'; var reg = /(a)(b)(c)/g; console.log( str.match(reg) ); // ["abc"] console.log( reg.exec(str) ); // ["abc", "a", "b", "c", index: 0, input: "abc"]- str.replace() 这个方法大家肯定不陌生,现在我们要说的就是和这个方法和正则相关的东西了。
正则去匹配字符串,匹配成功的字符去替换成新的字符串
写法:str.replace(reg,newStr);
var str = 'a111bc222de';
var res = str.replace(/\d/g,'Q') console.log(res) // "aQQQbcQQQde" replace的第二个参数也可以是一个函数 str.replace(reg,fn); var str = '2017-01-06'; str = str.replace(/-\d+/g,function(){ console.log(arguments) }) 控制台打印结果: ["-01", 4, "2017-01-06"] ["-06", 7, "2017-01-06"] "2017undefinedundefined" 从打印结果我们发现每一次输出的值似乎跟exec捕获时很相似,既然与exec似乎很相似,那么似乎也可以打印出小分组中的内容喽 var str = '2017-01-06'; str = str.replace(/-(\d+)/g,function(){ console.log(arguments) }) ["-01", "01", 4, "2017-01-06"] ["-06", "06", 7, "2017-01-06"] "2017undefinedundefined" 从结果看来我们的猜测没问题。 此外,我们需要注意的是,如果我们需要替换replace中正则找到的字符串,函数中需要一个返回值去替换正则捕获的内容。通过replace方法获取url中的参数的方法
(function(pro){
function queryString(){ var obj = {}, reg = /([^?&#+]+)=([^?&#+]+)/g; this.replace(reg,function($0,$1,$2){ obj[$1] = $2; }) return obj; } pro.queryString = queryString; }(String.prototype)); // 例如 url为 https://www.baidu.com?a=1&b=2 // window.location.href.queryString(); // {a:1,b:2} 零宽断言
用于查找在某些内容(但并不包括这些内容)之前或之后的东西,如\b,^,$那样用于指定一个位置,这个位置应该满足一定的条件(即断言),因此它们也被称为零宽断言。
在使用正则表达式时,捕获的内容前后必须是特定的内容,而我们又不想捕获这些特定内容的时候,零宽断言就可以派上用场了。
- 零宽度正预测先行断言 (?=exp)
- 零宽度负预测先行断言 (?!exp)
- 零宽度正回顾后发断言 (?<=exp)
- 零宽度负回顾后发断言 (?
这四胞胎看着名字好长,给人一种好复杂好难的感觉,我们还是挨个来看看它们究竟是干什么的吧。
- (?=exp) 这个简单理解就是说字符出现的位置的右边必须匹配到exp这个表达式。
var str = "i'm singing and dancing";
var reg = /\b(\w+(?=ing\b))/g
var res = str.match(reg); console.log(res) // ["sing", "danc"] 注意一点,这里说到的是位置,不是字符。 var str = 'abc'; var reg = /a(?=b)c/; console.log(res.test(str)); // false // 这个看起来似乎是正确的,实际上结果是false reg中a(?=b)匹配字符串'abc' 字符串a的右边是b这个匹配没问题,接下来reg中a(?=b)后边的c匹配字符串时是从字符串'abc'中a的后边b的前边的这个位置开始匹配的, 这个相当于/ac/匹配'abc',显然结果是false了- (?!exp) 这个就是说字符出现的位置的右边不能是exp这个表达式。
var str = 'nodejs';
var reg = /node(?!js)/;
console.log(reg.test(str)) // false- (?<=exp) 这个就是说字符出现的位置的前边是exp这个表达式。
var str = '¥998$888';
var reg = /(?<=\$)\d+/;
console.log(reg.exec(str)) //888- (?位置的前边不能是exp这个表达式。
var str = '¥998$888';
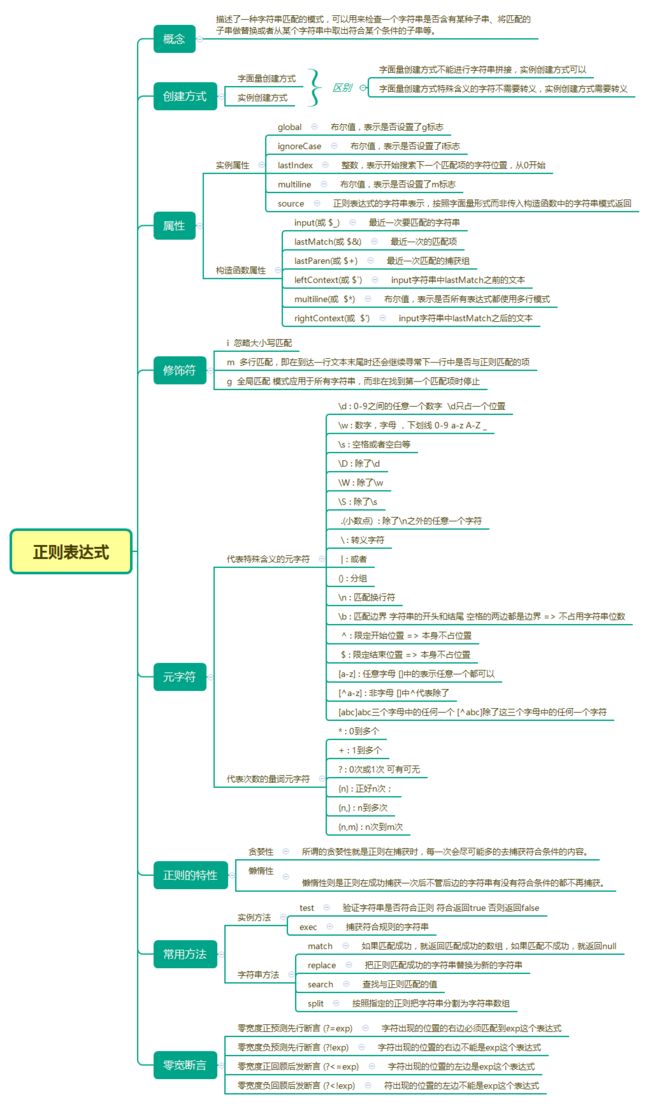
var reg = /(?console.log(reg.exec(str)) //998最后,来一张思维导图
- JS数据类型
typeof的返回值共有六种:
number, boolean, string, undefined, object, function.
//1.number typeof(10); typeof(NaN); //NaN在JavaScript中代表的是特殊非数字值,它本身是一个数字类型。 typeof(Infinity); //2.boolean typeof(true); typeof(false); //3.string typeof("abc"); //4.undefined typeof(undefined); typeof(a);//不存在的变量 //5.object 对象,数组,null返回object typeof(null); typeof(window); //6.function typeof(Array); typeof(Date); /*对于Array,Null等特殊对象使用typeof一律返回object,这正是typeof的局限性。 获取一个对象是否是数组,或判断某个变量是否是某个对象的实例则要选择使用instanceof。instanceof用于判断一个变量是否某个对象的实例 */ var a=new Array(); alert(a instanceof Array); //会返回true,同时alert(a instanceof Object)也会返回true;这是因为Array是object的子类。 function test(){};var a=new test(); alert(a instanceof test)会返回true。 /*友情提示: a instanceof Object 得到true并不是因为 Array是Object的子对象,而是因为 Array的prototype属性构造于Object,Array的父级是Function*/
- typeof 不会抛出异常
-. 返回undefined: 1、变量没有声明;2、变量没有赋值; 3、var d = undefined;
-. 判断一个值不等于undefined也不等于null:if (x !== undefined && x !== null) ? x : y ;
-. typeof null ,返回object; typeof undefined 返回undefined
-.检测对象值: function isObject2(x) { return x === Object(x); } var date = new Date(); date === object(date);
- typeof 返回的都是string类型, typeof x === "undefined"