简记MobileNet系列
《简记MobileNet系列》
ImageNet竞赛至今,为了追求精度,模型深度越来越深,参数量也越来越大,这导致移动端场景的算力是无法支撑的。所以轻量级模型应运而生,Google提出了MobileNet系列模型,专注于移动端或者嵌入式设备中的轻量级CNN网络,在保持模型性能(acc)的前提下减少模型的参数量。重新回顾了mobilenet系列,可以看出,准确率在逐步提高,延时也不断下降。虽然在ImageNet上的准确率不能达到sota,但在同等资源消耗下,其优势就能大大体现出来。
Key Words:Depthwise Conv、Pointwise Conv、RELU6、H-swish、SE-layer、NAS
Beijing, 2020
作者:Google
Paper:
2017年 MobileNet
2018年 MobileNet V2
2019年 MobileNet V3
Code: Caffe MobileNet
Parameters & FLOP
概述
这里从论文中截取的关于MobileNet系列网络的信息,总的来说参数量是越来越少的,而且精度是越来越高的。
| Params | Model Size | ImageNet Accuracy | |
|---|---|---|---|
| MobileNet | 4.2M | 16.2M | 70.6% |
| MobileNetV2 | 3.4M | 13.5M | 72.0% |
| MobileNetV3(small) | 2.5M | 10M | 67.4% |
| MobileNetV3(large) | 5.4M | 22M | 75.2% |
f i l e s i z e = p a r a m s ∗ 4 file\space size = params * 4 file size=params∗4
BTW: 一般模型中参数是以float32保存的,也就是一个参数由4个bytes表示,那么就可以将参数量估算为存储大小。相差的部分是模型文件中除了需要存储实际参数外还需要存储一些网络信息,总体差异不大。可以通过from thop import profile来计算模型的参数量及计算量。
核心思想&亮点
MobileNet
MobileNet 的典型的类似于VGG的直筒结构,主要工作是对标注的卷积层进行了改进。
核心思想
- 深度可分离卷积,也就是分组卷积的极端情况,即分组数与网络的channel数相等
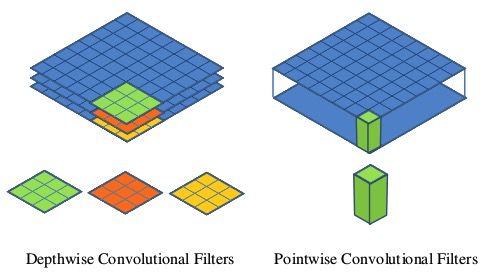
- Depthwise后接BN层和RELU6,Pointwise后也接BN层和RELU6

-
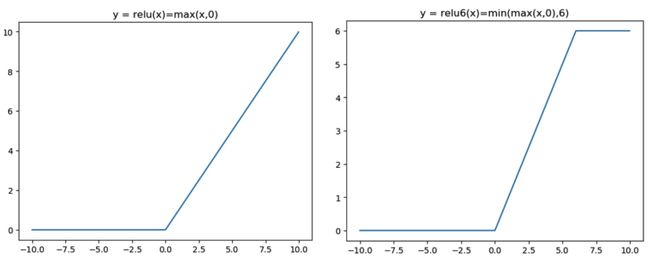
使用了RELU6作为激活函数:
-
ReLU6就是普通的ReLU但是限制最大输出值为6(对输出值做clip),这是为了适应移动端设备float16的低精度,让在这样的数值分辨率下也能有很好的表示,如果对ReLU的激活范围不加限制,输出范围为0到正无穷,如果激活值非常大,分布在一个很大的范围内,则低精度的float16无法很好地精确描述如此大范围的数值,带来精度损失。
-
正确的做法是去掉最后输出的ReLU6,直接线性输出,理由是:ReLU变换后保留非0区域对应于一个线性变换,仅当输入高维时ReLU能保留所有完整信息。因为Xception已经实验证明了DepthWise卷积后再加ReLU效果会变差,但不代表DepthWise后面不可以接ReLU,在MobileNet v2论文中对此做了详细解释。
-
- Paper中给出了两个超参数 α 、 β \alpha 、\beta α、β,用于缩放模型,分别用于缩放模型的宽度和分辨率的大小。我们反过来看,扩大宽度和分辨率,都能提高网络的准确率,但如果单一提升一个的话,准确率很快就会达到饱和,思想和2019年谷歌提出EfficientNet的原因之一,动态提高深度、宽度、分辨率来提高网络的准确率。
MobileNet V2
上述的 MobileNet 在实际的使用中,发现深度卷积部分的卷积核被废掉了,训练之后发现深度卷积核有不少是空的即为0的情况,这样就导致了信息的损失。如下图所示,在MobileNetv2的paper中对ReLU进行了较为深入的研究,并引入了Linear Bottleneck 和 逆残差模块 。

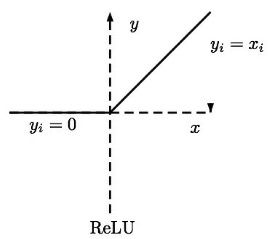
ReLU 函数分析
-
ReLU对0值的梯度是0,后续无论怎么迭代这个节点的值都不会恢复了。而 通过ResNet结构的特征复用,可以很大程度上缓解这种特征退化问题 (这也从一个侧面说明ResNet为何好于VGG)
-
一般情况训练网络使用的是float32浮点数;当使用低精度的float16时,这种特征复用可以更加有效的减缓退化
-
ReLU在低维变换后使用会导致 数据坍塌 信息损失严重
论文关于ReLU的实验
Moblienet V2文中提出,假设在2维空间有一组由 n 个点组成的螺旋线 x 2 × n x_{2\times n} x2×n 数据,经随机矩阵 T m × 2 T_{m\times2} Tm×2 映射到 m 维并进行ReLU运算,即:
y m × n = R e L U ( T m × 2 ⋅ x 2 × n ) y_{m\times n} = ReLU(T_{m\times2}\cdot x_{2\times n}) ym×n=ReLU(Tm×2⋅x2×n)
再通过 T 矩阵的广义逆矩阵 T − 1 T^{-1} T−1 将 y m × n y_{m\times n} ym×n 映射回2维空间:
x ~ 2 × n = T 2 × m − 1 ⋅ y m × n \tilde{x}_{2\times n}=T^{-1}_{2\times m}\cdot y_{m\times n} x~2×n=T2×m−1⋅ym×n
我用Python完全复现了一下,论文这部分的内容,得到的结果如下


和论文的结果大体是一致的,对比 x 和 x ~ \tilde{x} x~ 发现,当映射维度 m={2, 3} 时,数据坍塌;当 m>15 时,数据基本被保存。虽然这不是严格的数学证明,但是至少说明:低维的线性变换后接ReLU会导致信息损失严重,越高维的线性变换越能够保持信息,即低维度的Depthwise后不应该接ReLU。
核心思想
-
Expansion Layer
-
为了对ReLU的缺陷进行回避,在结构上采取了先用1x1对数据进行升维,然后ReLU,再DepthWise之后再ReLU,然后降维之后接线性激活函数。
-
并不是说DepthWise后面都不可以接ReLU,因为通过前面的升维后的结果是高维的了,所以可以在DepthWise后加ReLU
-

-
Linear Bottleneck
- 所谓的线性激活函数就是1x1卷积,不做非线性变换而已,为什么非线性可能会损失原始信息还要引入非线性呢?因为线性的操作只能拟合线性问题,我们面对的复杂问题都是非线性的,所以引入非线性是必要的。而这里还是为了避免ReLU的缺陷而使用的线性
-
逆残差模块
-
引入了特征复用结构,即采取了ResNet的思想
-
ResNet使用标准的卷积来提取特征,而M2使用DW卷积提取特征
-
M2将bottleneck结构变成了纺锤型,ResNet是先缩小为原来的1/4,再放大。M2是放大到原来的6倍,再缩小,所以命名为 “Inverted Residual Block”
-

- M2网络由以下两种类型的Block组成,DW卷积的步长为1时,使用short cut连接,当DW卷积步长为2的时候由于input与output尺寸不一样,所以使用直筒结构

- 激活函数仍旧使用ReLU6
MobileNetV3
核心思想
MobileNet V3发表于2019年,该v3版本结合了v1的深度可分离卷积、v2的Inverted Residuals和Linear Bottleneck、SE模块,利用NAS(神经结构搜索)来搜索网络的配置和参数。
-
降低计算量
-
作者发现,计算资源耗费最多的层是网络的输入和输出层,因此作者对这两部分进行了改进。如下图所示,上面是v2的最后输出几层,下面是v3的最后输出的几层。可以看出,v3版本将avg pooling提前了。在使用1×1卷积进行扩张后,就紧接池化层-激活函数,最后使用1×1的卷积进行输出。通过这一改变,能减少7ms的延迟,提高了11%的运算速度,且几乎没有任何精度损失。
-
其次,首层的stride=2的卷积层的改变,对于v2的输入层,通过3×3卷积将输入扩张成32维。作者发现使用ReLU或者hard swish激活函数,能将通道数缩减到16维,且准确率保持不变。这又能节省2ms的延时,因为32个滤波器经常是互为镜像的,冗余的,这个在GhostNet论文中有详细介绍,且提出了Ghost模块再减少参数量的条件下,解决这个问题。

-
-
新的非线性激活函数
-
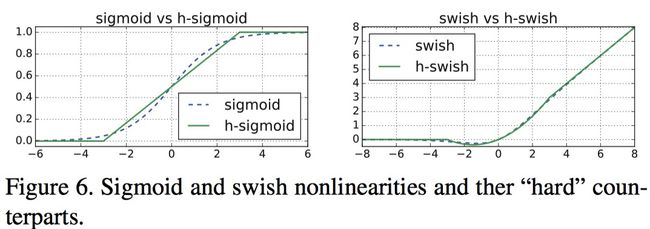
swish 是谷歌大脑2017的论文 《Searching for Activation functions》提出的激活函数,具有无上界有下界,平滑及非单调的特性,并且在实验上证明了深层模型上优于ReLU
-
s w i s h ( x ) = x ⋅ σ ( β x ) swish(x) = x \cdot \sigma(\beta x) swish(x)=x⋅σ(βx) ( β \beta β可作为超参或可训练参数),由于嵌入式设备对于计算sigmoid较耗计算资源,因此作者使用ReLU6(x+3)/6来近似替代sigmoid,即h-swish来替换swish,h-swish ( x ) = x ⋅ R e L U 6 ( x + 3 ) 6 (x) = x \cdot \frac{ReLU6(x + 3)}{6} (x)=x⋅6ReLU6(x+3),从下右图可以看出在和swish几乎一样,但计算量大幅减少
-
实验显示h-swish在更深的层中使用的好处更大,所以M3在中后部分使用了h-swish
-
-
基于Squeeze & Excitation(SE)的轻量级注意力结构
-
在v2的block上引入SE模块,SE模块是一种轻量级的通道注意力模块。在 DepthWise之后 ,经过池化层,然后第一个fc层,通道数缩小4倍,再经过第二个fc层,通道数变换回去(扩大4倍),然后与depthwise进行按位相乘。
-
和SENet不同的是M3在残差层中使用了SE模块,而且在SE模块中使用了不同的非线性激活函数(ReLU、H-swish)
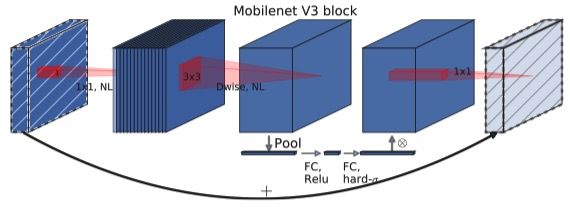
-
-
资源受限的NAS,利用NAS(神经结构搜索)来搜索网络的配置和参数
-
先通用NAS算法,优化每一个block,得到大体的网络结构,然后使用NetAdapt 算法来确定每个filter的channel的数量
-
先用NAS找到一个可用的结构A
-
在A的基础上生成一系类的候选结构,并且这些候选结构消耗在一点点减少,其实就是穷举子结构
-
对于每个候选结构,使用前一个模型进行初始化,(前一个模型没有的参数随机初始化就行),finetune T个epoch,得到一个大致的精度
-
在这些候选结构中,找到最好的
-
反复迭代,知道目标时间到达,找到最合适的结果
-
-
基于M3的结构,提出了一个语义分割的head,Lite R-ASPP 混合网络多个分辨率的特征得到了一个快速的语义分割head

总结&思考
Q1: MobileNet为什么会快?
A1: MobileNet 的各种类型的操作占比如下,而在计算机计算卷积运算的时候,先要把图像和卷积核载入到内存中,有个“按行优先次序”存储的过程,即需要对图像和卷积核做img2col操作,然后在做矩阵相乘加速,而1x1卷积恰恰避免这个费时的步骤,大大节省了数据重排列的时间和空间,因此在底层计算中相对更快。
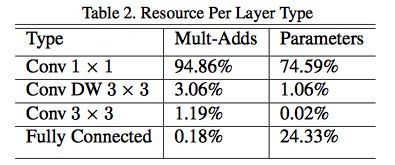
Q2: 为什么使用ReLU6?
A2: ReLU6只是对ReLU的上限进行了设置 max(6, max(x, 0)),其优势在于,在嵌入式运算中使用fp16进行运算的时候,能够减少精度带来的损失,0~6的区间,在低精度运算的情况下也能够有很好分辨率。
Q1: MobileNetV2比MobileNet有哪些改进?
A1:
- MobileNetV2的改进主要来自于MobileNet存在的问题,对ReLU函数进行了深入的探讨,发现低维线性变换输入到ReLU中会造成比较严重的信息损失,所以提出了逆残差模块即先对特征的channel扩大,ReLU6,然后Depthwise卷积,ReLU6,(所有的ReLU函数都是在升维后进行的)然后再缩小,并在模块的最后一层使用了线性激活函数来减少信息的损失。
- Inverted Residual Block + Linear Bottleneck
Q2: MobileNetV3比MobileNetV2有哪些改进?
A2:
-
为了减少计算量,对M2的输入部分的channel由32减少到了16,然后对模型输出部分把avg pooling提前了。而且把每层的channel数也相应的减小了。
-
为了提高精度,加入了SE模块和H-swish激活函数。
-
利用NAS来搜索模型结构。
附录
各种卷积可视化
https://www.cnblogs.com/hellcat/p/10246646.html
https://www.cnblogs.com/dengshunge/p/11334640.html
https://blog.csdn.net/Chunfengyanyulove/article/details/91358187
https://www.jianshu.com/p/2d58e5fc9f59?from=groupmessage
https://www.cnblogs.com/makefile/p/activation-function.html
MobileNetv3_caffe