Kafka Connect相关插件配置文档
Kafka Connect相关插件配置文档
文章目录
- Kafka Connect相关插件配置文档
- 前言
- 一、HDFS 2 Sink 插件
-
- 1.1主要功能点
- 1.2 环境准备
- 1.3 HDFS 2 Sink 安装
- 1.4 快速开始
- 1.5 HDFS 2连接器配置选项
-
- 1.5.1 HDFS
- 1.5.2 安全
- 1.5.3 连接器
- 1.5.4 存储
- 1.5.5 分区器
- 1.5.6 Hive
- 1.5.7 Schema
- 1.6 格式和分区
- 1.7 蜂巢整合
- 1.8 安全的HDFS和Hive Metastore
- 1.9 模式演变
- 二 、JDBC Source 插件
-
- 2.1 简介
- 2.2 环境准备
- 2.3 增量查询模式
- 2.4 Message Keys
- 2.5 Mapping Column Types
- 2.6 Configuration
- 2.7 Schema Evolution
- 2.8 Configuration Properties
-
- 2.8.1 配置类
- 2.8.2 数据库连接安全
- 2.8.3 数据库
- 2.8.4 Mode
- 2.8.5 Connector
- 2.9 示例
- 三 、JDBC Sink 插件
-
- 3.1 Data mapping
- 3.2 Key handling
- 3.3 Delete mode
- 3.4 Idempotent writes
- 3.5 Auto-creation and Auto-evoluton
- 3.6 环境准备
- 3.7 Configuration Properties
-
- 3.7.1配置类
- 3.7.2 数据库连接安全
- 3.7.3 Connection
- 3.7.4 Writes
- 3.7.5 Data Mapping
- 3.7.6 DDL Support
- 3.7.6 Retries
- 3.8 示例
- 四、问题汇总及其解决方案
-
-
-
- hive内依赖的guava.jar和hadoop内的版本不一致造成的。
-
-
- 附录:
-
- mysql表信息
- DataX 任务配置信息
前言
本文档主要是对JDBC Source、Sink与HDFS Sink插件相关文档的介绍以及简单的demo示例。对应的HDFS3 版本、HDFS2 Source 版本官方没有开源需要授权后使用(试用期30天),本文档暂不涉及。对HDFS3-Sink组件相关文档的整理过程中与到组件内部目前存在bug需要待修复,可以把数据存储到HDFS,但是在自动创建Hive的外部表时无法获取到对应的MetaStore的元数据信息,导致创建失败。经过测试HDFS2-Sink目前满足数据到Hadoop3 集群存储数据以及自动创建Hive的外部表。**HDFS-Sink的替代方案目前可以使用HDFS2-Sink版本。**针对HDFS2-Sink目前针对相关业务存储bug,内部实现是依靠flush.size来刷新文件的,当写入的条数不足时将不会刷新导致数据丢失(需要针对特定版本进行完善)。JDBC在本次的测试整理中未发现问题。
一、HDFS 2 Sink 插件
通过Kafka Connect HDFS 2连接器,您可以将多种格式的数据从Kafka主题导出到HDFS 3.x文件,并与Hive集成以使数据立即可用于通过HiveQL查询。
连接器会定期轮询来自ApacheKafka®的数据,并将其写入HDFS。来自每个Kafka主题的数据由提供的分区程序进行分区,并分为多个块。每个数据块都表示为一个HDFS文件,其中包含主题,Kafka分区,该数据块在文件名中的开始和结束偏移量。如果未在配置中指定分区程序,则使用保留Kafka分区的默认分区程序。每个数据块的大小取决于写入HDFS的记录数,写入HDFS的时间以及架构兼容性。
HDFS连接器与Hive集成在一起,启用后,该连接器会自动为每个Kafka主题创建一个外部Hive分区表,并根据HDFS中的可用数据更新该表。
1.1主要功能点
-
完全一次交付:连接器使用预写日志来确保每个记录仅一次导出到HDFS。另外,连接器通过将Kafka偏移信息编码到文件中来管理偏移提交,以便我们可以从最后提交的偏移开始,以防失败和任务重新启动。
-
可扩展的数据格式:该连接器开箱即用,支持以Avro和Parquet格式将数据写入HDFS。另外,您可以通过扩展
Format类将其他格式写入HDFS 。 -
Hive集成:连接器开箱即用地支持Hive集成,启用后,连接器会为导出到HDFS的每个主题自动创建Hive外部分区表。
-
安全HDFS和Hive Metastore支持:连接器支持Kerberos身份验证,因此可与安全HDFS和Hive Metastore一起使用。
-
可插拔分区程序:该连接器支持默认分区程序,字段分区程序和基于时间的分区程序,包括开箱即用的每日和每小时分区程序。您可以通过扩展
Partitioner类来实现自己的分区程序。另外,您可以通过扩展TimeBasedPartitioner类来自定义基于时间的分区程序。 -
**模式演变:**仅当使用默认命名策略()生成记录时,模式演变才起作用
TopicNameStrategy。如果使用其他命名策略,则可能会发生错误。这是因为记录彼此不兼容。如果使用其他命名策略,schema.compatibility则应设置为NONE。这可能会导致目标文件较小,因为每次模式ID在记录之间更改时,接收器连接器都会创建一个新文件。有关命名策略的更多信息,请参见主题名称策略。
1.2 环境准备
- Kafka 0.11.0版本以上
- Kafka connect 版本0.11.0以上
- Java 1.8
- HDFS 3.X集群
- Hive 3.x
1.3 HDFS 2 Sink 安装
本安装推荐手动安装(未使用confluent-hub)。
- 下载并解压缩您的连接器的ZIP文件,然后按照手动的连接器安装说明进行操作。
- 解压缩ZIP文件内容,然后将内容复制到所需位置。例如,您可以创建一个名为的目录,
/share/kafka/plugins(自定义此路径)然后复制连接器插件的内容。 - 将此添加到Connect属性文件中的插件路径。例如,
plugin.path=/usr/local/share/kafka/plugins(自定义的路径)Kafka Connect使用其插件路径查找插件。插件路径是在Kafka Connect的worker配置中定义的目录的逗号分隔列表。 - 使用该配置启动Connect worker。Connect将发现这些插件中定义的所有连接器。
- 对运行Connect的每台计算机重复这些步骤。每个工人上必须有每个连接器。
- 运行命令查看刚安装的插件是否显示
curl -X GET http://localhost:8083/connector-plugins
1.4 快速开始
此快速入门使用HDFS连接器将Avro控制台生产者产生的数据导出到HDFS。请确保Hadoop在本地或远程运行,并且您知道HDFS URL。对于Hive集成,您需要安装Hive并了解metastore thrift URI。此快速入门假定您使用默认配置启动了所需的服务,并且应根据使用的实际配置进行必要的更改。
注意: 您需要确保连接器用户对
topics.dir和中指定的目录具有写权限logs.dir。的默认值topics.dir是/topics和的默认值logs.dir是/logs。如果您未指定两个配置,请确保连接器用户对/topics和具有写权限/logs。您可能需要先创建/topics和/logs在运行连接器之前,因为连接器可能没有对的写权限/。
# 流作业
curl -i -k -H "Content-type: application/json" -X POST -d '{
"name": "hdfs3-sink-hive",
"config": {
"connector.class": "io.confluent.connect.hdfs.HdfsSinkConnector",
"tasks.max": "1",
"topics": "dataxhive",
"hdfs.url": "hdfs://master:9002",
"flush.size": "3",
"key.converter": "org.apache.kafka.connect.storage.StringConverter",
"value.converter": "io.confluent.connect.avro.AvroConverter",
"value.converter.schema.registry.url":"http://master:8081",
"confluent.topic.bootstrap.servers": "slaver:9092",
"confluent.topic.replication.factor": "1",
"hive.integration":"true",
"hive.metastore.uris":"thrift://master:9083",
"schema.compatibility":"BACKWARD"
}
}' http://localhost:8083/connectors
注意:前几个设置是您将为所有连接器指定的通用设置。该
topics参数指定要从中导出数据的主题。在这种情况下dataxtest。hdfs.url指定已写入数据的HDFS。您应该根据您的配置进行设置。flush.size指定在调用文件提交之前连接器需要写入的记录数(重要此参数控制着什么时间刷新并提交文件,可能会造成数据丢失)。对于高可用性HDFS部署,设置hadoop.conf.dir为包含的目录hdfs-site.xml。之后hdfs-site.xml到位,并hadoop.conf.dir已定,hdfs.url可设置为namenodes名称服务ID,例如nameservice1。
# 批作业读取数据后写入hdfs中并创建hive外部表
curl -i -k -H "Content-type: application/json" -X POST -d '{
"name": "hdfs3-sink-hive",
"config": {
"connector.class": "io.confluent.connect.hdfs.HdfsSinkConnector",
"tasks.max": "1",
"topics": "dataxhive",
"hdfs.url": "hdfs://master:9002",
"flush.size": "3",
"key.converter": "org.apache.kafka.connect.storage.StringConverter",
"value.converter": "io.confluent.connect.avro.AvroConverter",
"value.converter.schema.registry.url":"http://slaver:8081",
"confluent.topic.bootstrap.servers": "master:9092",
"confluent.topic.replication.factor": "1",
"hive.integration":"true",
"hive.metastore.uris":"thrift://master:9083",
"schema.compatibility":"BACKWARD",
"type":"key",
"offsetKey":"dataxhive"
}
}' http://localhost:8083/connectors
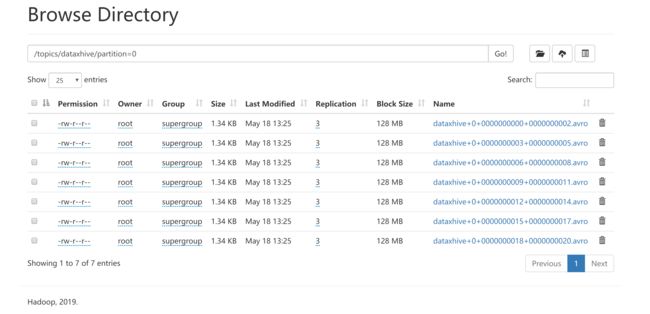
- Hive表数据查询(此处数据不完整是因为在配置flush.size=3导致剩余不够的数据没有刷新,flush.size=1时可以解决数据问题,会导致大量小文件的存在,通过配置发现可以根据时间滚动文件但都是最理想的情况)

2. HDFS 存储数据展示
# 查询现有的作业
curl -X GET http://localhost:8083/connectors
# 删除指定的作业
curl -X DELETE http://localhost:8083/connectors/hdfs3-sink
1.5 HDFS 2连接器配置选项
要使用此连接器,请在connector.class配置属性中指定连接器类的名称。
connector.class=io.confluent.connect.hdfs.HdfsSinkConnector
连接器特定的配置属性如下所述。
1.5.1 HDFS
hdfs.url
HDFS连接URL。此配置的格式为hdfs :: // hostname:port,并指定要将数据导出到的HDFS。此属性已弃用,并将在以后的版本中删除。使用store.url代替。
- 类型:字符串
- 默认值:空
- 重要性:高
hadoop.conf.dir
Hadoop配置目录。
- 类型:字符串
- 默认值:“”
- 重要性:高
hadoop.home
Hadoop主目录。
- 类型:字符串
- 默认值:“”
- 重要性:高
logs.dir
顶级目录,用于存储预写日志。
- 类型:字符串
- 默认值:日志
- 重要性:高
1.5.2 安全
hdfs.authentication.kerberos
指示HDFS是否使用Kerberos进行身份验证的配置。
- 类型:布尔值
- 默认值:false
- 重要性:高
- 家属:
connect.hdfs.principal,connect.hdfs.keytab,hdfs.namenode.principal,kerberos.ticket.renew.period.ms
connect.hdfs.principal
HDFS使用Kerberos进行身份验证时使用的主体。
- 类型:字符串
- 默认值:“”
- 重要性:高
connect.hdfs.keytab
HDFS连接器主体的密钥表文件的路径。此密钥表文件仅应由连接器用户读取。
- 类型:字符串
- 默认值:“”
- 重要性:高
hdfs.namenode.principal
HDFS Namenode的主体。
- 类型:字符串
- 默认值:“”
- 重要性:高
kerberos.ticket.renew.period.ms
续订Kerberos票证的时间(以毫秒为单位)。
- 类型:长
- 默认值:3600000
- 重要性:低
1.5.3 连接器
format.class
将数据写入存储时使用的格式类。格式类实现io.confluent.connect.storage.format.Format接口。
- 类型:类
- 默认:
io.confluent.connect.hdfs.avro.AvroFormat - 重要性:高
这些类默认情况下可用:
io.confluent.connect.hdfs.avro.AvroFormatio.confluent.connect.hdfs.json.JsonFormatio.confluent.connect.hdfs.parquet.ParquetFormatio.confluent.connect.hdfs.string.StringFormat
flush.size
在调用文件提交之前写入存储的记录数。
- 类型:int
- 重要性:高
rotate.interval.ms
调用文件提交的时间间隔(以毫秒为单位)。此配置可确保在每个配置的间隔内调用文件提交。当数据摄取率较低且连接器未写入足够的消息来提交文件时,此配置很有用。默认值-1表示此功能已禁用。
- 类型:长
- 默认值:-1
- 重要性:高
rotate.schedule.interval.ms
定期调用文件提交的时间间隔(以毫秒为单位)。此配置可确保在每个配置的间隔内调用文件提交。提交时间将调整为所选时区的00:00。无论先前的提交时间或消息数量如何,提交都将在计划的时间执行。当您必须基于当前服务器时间(例如每小时开始时)提交数据时,此配置很有用。默认值-1表示此功能已禁用。
- 类型:长
- 默认值:-1
- 重要性:中等
schema.cache.size
Avro转换器中使用的架构缓存的大小。
- 类型:int
- 默认值:1000
- 重要性:低
retry.backoff.ms
重试退避(以毫秒为单位)。此配置用于通知Connect,以在发生临时异常时重试传递消息批处理或执行恢复。
- 类型:长
- 默认值:5000
- 重要性:低
shutdown.timeout.ms
清除关机超时。这样可以确保在连接器关闭期间完成异步Hive Metastore更新。
- 类型:长
- 默认值:3000
- 重要性:中等
filename.offset.zero.pad.width
如果偏移量太短,则商店的文件名中的宽度到零填充的偏移量可以提供固定宽度的文件名,可以通过简单的词典编目排序对其进行排序。
- 类型:int
- 默认值:10
- 有效值:[0,…]
- 重要性:低
1.5.4 存储
storage.class
基础存储层。
- 类型:类
- 默认值:io.confluent.connect.hdfs.storage.HdfsStorage
- 重要性:高
topics.dir
顶级目录,用于存储从ApacheKafka®提取的数据。
- 类型:字符串
- 默认值:主题
- 重要性:高
store.url
商店的连接URL(如果适用)。例如:hdfs://hostname:port。
- 类型:字符串
- 默认值:空
- 重要性:高
directory.delim
目录定界符模式
- 类型:字符串
- 默认值:/
- 重要性:中等
file.delim
文件分隔符模式
- 类型:字符串
- 默认值:+
- 重要性:中等
1.5.5 分区器
partitioner.class
将数据写入存储时使用的分区程序。以下分区可用:
-
DefaultPartitioner保留Kafka分区。 -
DailyPartitioner根据日期对数据进行分区。 -
HourlyPartitioner根据小时划分数据。 -
FieldPartitioner根据中指定的分区字段的值将数据分区到不同的目录partition.field.name。 -
TimeBasedPartitioner根据摄取时间对数据进行分区。 -
类型:类
-
默认值:io.confluent.connect.storage.partitioner.DefaultPartitioner
-
重要性:高
-
家属:
partition.field.name,partition.duration.ms,path.format,locale,timezone
partition.field.name
使用分区字段的名称FieldPartitioner。您可以使用逗号分隔的名称输入多个分区字段名称。
- 类型:字符串
- 默认值:“”
- 重要性:中等
partition.duration.ms
所使用的分区毫秒数的持续时间TimeBasedPartitioner。默认值-1表示我们不使用TimeBasedPartitioner。
- 类型:长
- 默认值:-1
- 重要性:中等
path.format
当使用进行分区时,此配置用于设置数据目录的格式TimeBasedPartitioner。在此配置中设置的格式将Unix时间戳转换为正确的目录字符串。例如,如果设置path.format='year'=YYYY/'month'=MM/'day'=dd/'hour'=HH,则数据目录的格式为/year=2015/month=12/day=07/hour=15/。
- 类型:字符串
- 默认值:“”
- 重要性:中等
locale
使用进行分区时使用的语言环境TimeBasedPartitioner,用于格式化日期和时间。例如,en-US用于美国英语,en-GB英国英语或fr-FR法语(在法国)。这些可能因Java版本而异。查看可用的语言环境。
- 类型:字符串
- 默认值:“”
- 重要性:中等
timezone
使用进行分区时要使用的时区TimeBasedPartitioner,用于格式化和计算日期和时间。使用时区的标准短名称如UTC或(无日光节约)PST,EST和ECT,或更长的标准名称,如America/Los_Angeles,America/New_York,和Europe/Paris。这些可能因Java版本而异。查看每个语言环境中的可用时区,例如美国英语语言环境中的可用时区。
- 类型:字符串
- 默认值:“”
- 重要性:中等
timestamp.extractor
使用进行分区时获取记录时间戳记的提取器TimeBasedPartitioner。可以将其设置为Wallclock,Record或者RecordField使用内置的时间戳提取器之一,或者为其指定扩展TimestampExtractor接口的用户定义类的标准类名。
- 类型:字符串
- 默认值:挂钟
- 重要性:中等
timestamp.field
时间戳提取器用作时间戳的记录字段。
- 类型:字符串
- 默认值:时间戳
- 重要性:中等
1.5.6 Hive
hive.integration
指示运行连接器时是否与Hive集成的配置。
- 类型:布尔值
- 默认值:false
- 重要性:高
- 家属:
hive.metastore.uris,hive.conf.dir,hive.home,hive.database,schema.compatibility
hive.metastore.uris
Hive Metastore URI可以是IP地址或Metastore主机的标准域名和端口。
- 类型:字符串
- 默认值:“”
- 重要性:高
hive.conf.dir
配置单元配置目录
- 类型:字符串
- 默认值:“”
- 重要性:高
hive.home
配置单元主目录。
- 类型:字符串
- 默认值:“”
- 重要性:高
hive.database
连接器在Hive中创建表时要使用的数据库。
- 类型:字符串
- 默认值:default
- 重要性:高
1.5.7 Schema
schema.compatibility
连接器观察架构更改时要使用的架构兼容性规则。支持的配置为NONE,BACKWARD,FORWARD和FULL。
- 类型:字符串
- 默认值:无
- 重要性:高
1.6 格式和分区
如果要将其他格式写入HDFS或使用其他分区程序format.class,partitioner.class则需要指定和。以下示例配置演示了如何编写Parquet格式和使用每小时分区程序:
format.class=io.confluent.connect.hdfs.parquet.ParquetFormat
partitioner.class=io.confluent.connect.hdfs.partitioner.HourlyPartitioner
注意:
如果要使用字段分区器,则还需要指定
partition.field.name配置以指定记录的字段名称。
1.7 蜂巢整合
至少,你需要指定hive.integration,hive.metastore.uris并 schema.compatibility整合蜂巢时。这是一个示例配置:
hive.integration=true
hive.metastore.uris=thrift://localhost:9083 # FQDN for the host part
schema.compatibility=BACKWARD
您应该hive.metastore.uris根据您的Hive配置进行调整。
注意
如果您未指定hive.metastore.uris,则连接器将在运行连接器的目录中将本地元存储与Derby一起使用。您需要在此目录中运行Hive才能查看Hive元数据的更改。
注意
由于连接器任务长时间运行,因此与Hive Metastore的连接将保持打开状态,直到任务停止为止。在默认的Hive配置中,重新连接到Hive Metastore将创建一个新连接。当任务数量很大时,重试可能导致打开的连接数超过操作系统中允许的最大连接数。因此建议设置hcatalog.hive.client.cache.disabled为truein hive.xml。
此外,为了支持模式演变的schema.compatibility是BACKWARD,FORWARD和 FULL。这样可以确保Hive可以使用最新的Hive表架构查询使用不同架构写入HDFS的数据。有关架构兼容性的更多信息,请参见Schema Evolution。
1.8 安全的HDFS和Hive Metastore
要使用安全的HDFS和蜂巢metastore工作,你需要指定hdfs.authentication.kerberos, connect.hdfs.principal,connect.keytab,hdfs.namenode.principal:
hdfs.authentication.kerberos=true
connect.hdfs.principal=connect-hdfs/[email protected]
connect.hdfs.keytab=path to the connector keytab
hdfs.namenode.principal=namenode principal
您需要通过Kerberos创建Kafka连接主体和密钥表文件,并将密钥表文件分发给运行连接器的所有主机,并确保只有连接器用户具有对密钥表文件的读取访问权限。
注意
当启用安全,您需要使用的FQDN的主机部分 hdfs.url和hive.metastore.uris。
注意
当前,连接器要求在运行连接器的所有主机上,主体和密钥表路径必须相同。hdfs.namenode.prinicipal需求的主机部分必须是Namenode主机的实际FQDN,而不是_HOST占位符。
1.9 模式演变
重要
仅当使用默认命名策略()生成记录时,方案演化才有效TopicNameStrategy。如果使用其他命名策略,则可能会发生错误。这是因为记录彼此不兼容。如果使用其他命名策略,schema.compatibility则应设置为NONE。这可能会导致目标文件较小,因为每次模式ID在记录之间更改时,接收器连接器都会创建一个新文件。有关命名策略的更多信息,请参见主题名称策略。
HDFS连接器支持架构演变,并根据schema.compatibility配置对数据的架构更改做出反应 。在本部分中,我们将说明连接器如何在不同的值下对架构演变做出反应schema.compatibility。的 schema.compatibility可设置为NONE,BACKWARD,FORWARD和FULL,这意味着没有兼容性,向后兼容性,前向兼容性和FULL兼容性分别。
-
否兼容性:默认情况下,
schema.compatibility设置为NONE。在这种情况下,连接器确保每个写入HDFS的文件都具有正确的架构。当连接器观察到数据中的架构更改时,它会为受影响的主题分区提交当前文件集,并将具有新架构的数据写入新文件中。 -
向后兼容性:如果以向后兼容的方式发展模式,我们总是可以使用最新的模式统一查询所有数据。例如,删除字段是对模式的向后兼容更改,因为当我们遇到使用旧模式编写的包含这些字段的记录时,我们可以忽略它们。添加具有默认值的字段也向后兼容。
如果
BACKWARD在中指定schema.compatibility,则连接器将跟踪用于将数据写入HDFS的最新模式,并且如果到达具有比当前最新模式更大的模式版本的数据记录,则连接器将提交当前文件集并写入数据记录与新架构的新文件。对于使用较早版本的架构在以后到达的数据记录,连接器将数据记录投影到最新的架构,然后再写入HDFS中的同一组文件。 -
FORWARD兼容性:如果以向前兼容的方式发展模式,我们总是可以使用最早的模式统一查询所有数据。删除具有默认值的字段是向前兼容的,因为缺少该字段时,旧模式将使用默认值。
如果
FORWARD在中指定schema.compatibility,则连接器会将数据投影到最早的架构,然后再写入HDFS中的同一组文件。 -
完全兼容性:完全兼容性意味着可以使用新架构读取旧数据,也可以使用旧架构读取新数据。
如果
FULL在中指定schema.compatibility,则连接器执行与相同的操作BACKWARD。
如果蜂巢集成启用时,我们需要指定schema.compatibility为BACKWARD, FORWARD或FULL。这样可以确保Hive表架构能够查询使用不同架构编写的主题下的所有数据。如果将schema.compatibility设置为BACKWARD或 FULL,则主题的Hive表架构将等同于该主题下的HDFS文件中的最新架构,该架构可以查询该主题的整个数据。如果将schema.compatibility设置为FORWARD,则主题的Hive表架构等同于该主题下的HFDS文件的最早架构,该架构可以查询该主题的整个数据。
二 、JDBC Source 插件
2.1 简介
通过Kafka Connect JDBC源连接器,您可以使用JDBC驱动程序将任何关系数据库中的数据导入ApacheKafka®主题。通过使用JDBC,此连接器可以支持各种数据库,而无需为每个数据库使用自定义代码。
通过定期执行SQL查询并为结果集中的每一行创建输出记录来加载数据。默认情况下,数据库中的所有表都被复制,每个表都复制到其自己的输出主题。监视数据库中的新表或删除表,并自动进行调整。从表复制数据时,连接器可以通过指定应使用哪些列来检测新数据或修改的数据来仅加载新行或修改的行。
您可以配置Java流应用程序以多种方式反序列化和摄取数据,包括Kafka控制台生产者,JDBC源连接器和Java客户端生产者。有关完整的代码示例,请参见connect-streams-pipeline。
2.2 环境准备
- Kafka和Schema Registry在默认端口上本地运行
- mysql可以远程访问
- 插件安装同上HDFS Sink安装方式
2.3 增量查询模式
每种增量查询模式都为每一行跟踪一组列,用于跟踪已处理的行以及哪些行是新的或已更新的行。该mode设置控制此行为,并支持以下选项:
- 递增列:包含每一行唯一ID的单个列,其中保证较新的行具有更大的ID,即一
AUTOINCREMENT列。请注意,此模式只能检测新行。无法检测到对现有行的更新,因此该模式仅应用于不可变数据。在数据仓库中流化事实表时,您可能会使用此模式的一个示例,因为这些表通常是仅插入的。递增列必须是整数类型。 - 时间戳列:在此模式下,包含修改时间戳的单个列用于跟踪上次处理数据的时间,并仅查询自该时间以来已被修改的行。请注意,由于时间戳不一定是唯一的,因此此模式不能保证所有更新的数据都将被传递:如果2行共享相同的时间戳并由增量查询返回,但是在崩溃前仅处理了一行,则第二次更新将被处理。系统恢复时未命中。
- 时间戳和递增列:这是最健壮和准确的模式,将递增列与时间戳列结合在一起。通过将两者结合起来,只要时间戳足够精细,每个(id,时间戳)元组将唯一地标识对行的更新。即使更新在部分完成后失败,系统恢复后仍可正确检测并交付未处理的更新。
- 自定义查询:源连接器支持使用自定义查询,而不是复制整个表。对于自定义查询,只要可以将必要
WHERE子句正确附加到查询中,就可以使用其他更新自动更新模式之一。或者,指定的查询可以自己处理对新更新的过滤。但是,请注意,将不会执行偏移量跟踪(与为每个记录记录incrementing和/或timestamp列值的自动模式不同 ),因此查询必须跟踪偏移量本身。 - 批量:此模式未过滤,因此根本不增量。它将在每次迭代时从表中加载所有行。如果要定期转储整个表,最终删除条目,下游系统可以安全地处理重复表,这将很有用。
请注意,使用某些列来检测更改的所有增量查询模式都将需要这些列上的索引才能有效地执行查询。
对于使用时间戳的增量查询模式,源连接器将使用一种配置 timestamp.delay.interval.ms来控制在将包含特定时间戳的行出现在结果中之前的等待时间。额外的等待时间可以使带有较早时间戳记的事务完成,并将相关的更改包括在结果中。有关更多信息,请参见配置属性。
2.4 Message Keys
Kafka消息是键/值对。对于JDBC连接器,值(有效负载)是要提取的表行的内容。但是,默认情况下,JBDC连接器不会生成密钥。
消息键对于设置分区策略很有用。密钥可以将消息定向到特定分区,并可以支持使用联接的下游处理。如果未使用消息密钥,则使用循环分发将消息发送到分区。
要为JBDC连接器设置消息密钥,请使用两个“单个消息转换”(SMT ):ValueToKey SMT和 ExtractField SMT。您将这两个SMT添加到JBDC连接器配置中。例如,以下内容显示了添加到配置的代码片段,该代码片段将表的id列accounts用作消息键。
curl -X POST http://localhost:8083/connectors -H "Content-Type: application/json" -d '{
"name": "jdbc_source_mysql_01",
"config": {
"connector.class": "io.confluent.connect.jdbc.JdbcSourceConnector",
"connection.url": "jdbc:mysql://mysql:3306/test",
"connection.user": "connect_user",
"connection.password": "connect_password",
"topic.prefix": "mysql-01-",
"poll.interval.ms" : 3600000,
"table.whitelist" : "test.accounts",
"mode":"bulk",
"transforms":"createKey,extractInt",
"transforms.createKey.type":"org.apache.kafka.connect.transforms.ValueToKey",
"transforms.createKey.fields":"id",
"transforms.extractInt.type":"org.apache.kafka.connect.transforms.ExtractField$Key",
"transforms.extractInt.field":"id"
}
}'
2.5 Mapping Column Types
源连接器具有一些选项,用于控制如何将列类型映射到“连接”字段类型。默认情况下,连接器将SQL / JDBC类型映射为Java中最精确的表示形式,这对于许多SQL类型而言很简单,但对于某些类型而言可能有点出乎意料。例如,SQL NUMERIC和DECIMAL类型具有由精度和小数位数控制的非常清晰的语义,最准确的表示形式是Decimal 使用Java 表示形式的Connect 逻辑类型BigDecimal。不幸的是,Avro将Decimal类型序列化为可能难以使用的原始字节。
源连接器的numeric.mapping配置将控制此映射。默认值为,none并且具有上述行为。
然而,该best_fit方案可能是大多数用户所期望的,因为它试图映射 NUMERIC列连接INT8,INT16,INT32,INT64,和FLOAT64 基于列的精度和刻度值:
| Precision | Scale | Connect “best fit” primitive type |
|---|---|---|
| 1 to 2 | -84 to 0 | INT8 |
| 3 to 4 | -84 to 0 | INT16 |
| 5 to 9 | -84 to 0 | INT32 |
| 10 to 18 | -84 to 0 | INT64 |
| 1 to 18 | positive | FLOAT64 |
该precision_only选项试图映射NUMERIC列连接INT8,INT16,INT32,和INT64仅基于列的精度,并在规模始终为0。
| Precision | Scale | Connect “best fit” primitive type |
|---|---|---|
| 1 to 2 | 0 | INT8 |
| 3 to 4 | 0 | INT16 |
| 5 to 9 | 0 | INT32 |
| 10 to 18 | 0 | INT64 |
NUMERIC列的精度和小数位数的任何其他组合将始终映射到Connect的Decimal类型。
注意
该numeric.precision.mapping属性较旧,现在已弃用。启用时,它完全等同于numeric.mapping=precision_only;启用时,它完全等同于numeric.mapping=none。
2.6 Configuration
源连接器使您可以灵活地从中导入数据的数据库以及如何导入数据的灵活性。本节首先介绍如何访问Confluent Platform不包含其驱动程序的数据库,然后给出一些涵盖常见场景的示例配置文件,然后提供可用配置选项的详尽描述。
完整的配置选项集在“ 配置属性”中列出,但是这里有一些模板配置,涵盖了一些常见的使用场景。
使用白名单将更改限制在MySQL数据库表的子集中,使用id和 modified所有白名单表上的标准列来检测已修改的行。此模式最可靠,因为它可以将唯一的,不可变的行ID与修改时间戳相结合,以确保即使在增量更新查询过程中过程终止,也不会丢失修改。
name=mysql-whitelist-timestamp-source
connector.class=io.confluent.connect.jdbc.JdbcSourceConnector
tasks.max=10
connection.url=jdbc:mysql://mysql.example.com:3306/my_database?user=alice&password=secret
table.whitelist=users,products,transactions
mode=timestamp+incrementing
timestamp.column.name=modified
incrementing.column.name=id
topic.prefix=mysql-
使用自定义查询而不是加载表,从而使您可以联接来自多个表的数据。只要查询不包括其自身的筛选,您仍可以将内置模式用于增量查询(在这种情况下,使用时间戳列)。请注意,这将您限制为每个连接器只有一个输出,并且由于没有表名,因此在这种情况下,主题“前缀”实际上是完整的主题名称。
name=mysql-whitelist-timestamp-source
connector.class=io.confluent.connect.jdbc.JdbcSourceConnector
tasks.max=10
connection.url=jdbc:postgresql://postgres.example.com/test_db?user=bob&password=secret&ssl=true
query=SELECT users.id, users.name, transactions.timestamp, transactions.user_id, transactions.payment FROM users JOIN transactions ON (users.id = transactions.user_id)
mode=timestamp
timestamp.column.name=timestamp
topic.prefix=mysql-joined-data
2.7 Schema Evolution
使用Avro转换器时,JDBC连接器支持架构演变。当数据库表架构发生更改时,JDBC连接器可以检测到更改,创建新的Connect架构,并尝试在Schema Registry中注册新的Avro架构。是否可以成功注册架构取决于架构注册表的兼容性级别,默认情况下该兼容性级别是向后的。
例如,如果您从表中删除一列,则更改是向后兼容的,并且相应的Avro架构可以在Schema Registry中成功注册。如果您修改数据库表架构以更改列类型或添加列,则将Avro架构注册到架构注册表时,由于更改不向后兼容,它将被拒绝。
您可以更改架构注册表的兼容性级别,以允许不兼容的架构或其他兼容性级别。有两种方法可以做到这一点:
- 使用设置连接器使用的主题的兼容级别 。受试者有格式,并 在被确定的配置和表名。
PUT /config/(string: subject)``topic-key``topic-value``topic``topic.prefix - 通过
avro.compatibility.level在架构注册表中进行设置,将架构注册表配置为使用其他架构兼容性级别 。请注意,这是一个全局设置,适用于架构注册表中的所有架构。
但是,由于JDBC API的限制,某些兼容的架构更改可能被视为不兼容的更改。例如,添加具有默认值的列是向后兼容的更改。但是,由于JDBC API的局限性,很难将其映射到Kafka Connect模式中正确类型的默认值,因此当前省略了默认值。其含义是,即使数据库表架构的某些更改是向后兼容的,在Schema Registry中注册的架构也不是向后兼容的,因为它不包含默认值。
如果将JDBC连接器与HDFS连接器一起使用,则对模式兼容性也有一些限制。启用Hive集成后,需要向后,向前和完整的架构兼容性,以确保Hive架构能够查询某个主题下的全部数据。由于某些兼容的架构更改将被视为不兼容的架构更改,因此这些更改将不起作用,因为生成的Hive架构将无法查询整个数据中的某个主题。
2.8 Configuration Properties
2.8.1 配置类
要使用此连接器,请在connector.class配置属性中指定连接器类的名称。
connector.class=io.confluent.connect.jdbc.JdbcSourceConnector
连接器特定的配置属性如下所述。
2.8.2 数据库连接安全
在连接器配置中,您会注意到没有安全参数。这是因为SSL不属于JDBC标准,而是取决于所使用的JDBC驱动程序。通常,您需要通过connection.url参数配置SSL 。例如,对于MySQL,它看起来像:
connection.url="jdbc:mysql://127.0.0.1:3306/sample?verifyServerCertificate=false&useSSL=true&requireSSL=true"
请查阅有关支持和配置的特定JDBC驱动程序文档。
2.8.3 数据库
connection.url
JDBC连接URL。
- 类型:字符串
- 重要性:高
- 家属:
table.whitelist,table.blacklist
connection.user
JDBC连接用户。
- 类型:字符串
- 默认值:空
- 重要性:高
connection.password
JDBC连接密码。
- 类型:密码
- 默认值:空
- 重要性:高
connection.attempts
检索有效JDBC连接的最大尝试次数。
- 类型:int
- 默认值:3
- 重要性:低
connection.backoff.ms
两次连接尝试之间的退避时间(以毫秒为单位)。
- 类型:长
- 默认值:10000
- 重要性:低
catalog.pattern
目录模式以从数据库中获取表元数据。
- 类型:字符串
- 默认值:空
- “”检索那些没有目录的人
- null(默认值)指示不使用架构名称来缩小搜索范围,并且所有表元数据均已获取,无论目录如何。
- 重要性:中等
table.whitelist
要包括在复制中的表的列表。如果指定,则table.blacklist可能未设置。使用逗号分隔的列表来指定多个表(例如)。table.whitelist: "User, Address, Email"
- 类型:清单
- 默认值:“”
- 重要性:中等
table.blacklist
列表中要排除的表。如果指定,则table.whitelist可能未设置。使用逗号分隔的列表来指定多个表(例如)。table.blacklist: "User, Address, Email"
- 类型:清单
- 默认值:“”
- 重要性:中等
schema.pattern
从数据库中获取表元数据的模式模式。
-
类型:字符串
-
默认值:空
""检索那些没有模式的。- null(默认值)指示不使用架构名称来缩小搜索范围,并且所有表元数据均被获取,而与架构无关。
-
重要性:高
重要
如果将其保留为默认的null设置,则连接器可能会超时并失败,原因是接收到大量的表元数据。确保为大型数据库设置此参数。
numeric.precision.mapping
是否尝试通过精度将NUMERIC值映射到整数类型。现在不推荐使用此选项。将来的版本可能会完全删除它。请numeric.mapping改用。
- 类型:布尔值
- 默认值:false
- 重要性:低
numeric.mapping
通过精度映射NUMERIC值,还可以选择缩放为整数或十进制类型。
- 类型:字符串
- 默认值:空
- 有效值:[none,precision_only,best_fit]
- 使用
none如果所有的数字列被连接的DECIMAL逻辑类型来表示。 - 使用
best_fit如果数值列应基于列的精度和规模转换为连接的INT8,INT16,INT32,INT64或FLOAT64。 - 使用
precision_only映射仅基于列的精度假设列的比例为0数字列。 - 该
none选项是默认选项,但由于Connect的DECIMAL类型映射到其二进制表示形式,因此可能会导致Avro的序列化问题,并且best_fit由于它映射到最合适的原始类型而经常会被首选。
- 使用
- 重要性:低
dialect.name
该连接器应使用的数据库方言的名称。默认情况下为空,并且连接器根据JDBC连接URL自动确定方言。如果要覆盖该行为并使用特定的方言,请使用此选项。可以使用JDBC连接器插件中所有正确包装的方言。
- 类型:字符串
- 默认值:“”
- 有效值:[ ]
, Db2DatabaseDialect, MySqlDatabaseDialect, SybaseDatabaseDialect, GenericDatabaseDialect, OracleDatabaseDialect,SqlServerDatabaseDialect, PostgreSqlDatabaseDialect, SqliteDatabaseDialect, DerbyDatabaseDialect, SapHanaDatabaseDialect, MockDatabaseDialect, VerticaDatabaseDialect - 重要性:低
2.8.4 Mode
mode
每次轮询表时更新表的方式。选项包括:
- 类型:字符串
- 默认值:“”
- 有效值:[ bulk, timestamp, incrementing, timestamp+incrementing]
- bulk:每次轮询时对整个表执行批量加载
- incrementing:在每个表上使用严格递增的列以仅检测新行。请注意,这不会检测到对现有行的修改或删除。
- timestamp:使用时间戳列(或类似时间戳的列)来检测新行和修改过的行。假设每次写入都会更新该列,并且值是单调递增的,但不一定唯一。
- timestamp + incrementing:使用两列,一个用于检测新行和已修改行的timestamp列,另一个用于更新的全局唯一ID的严格递增列,因此可以为每行分配唯一的流偏移量。
- 重要性:高
- 家属:
incrementing.column.name,timestamp.column.name,validate.non.null
incrementing.column.name
严格递增的列的名称,用于检测新行。任何空值表示应通过查找自动递增的列来自动检测该列。该列可能不能为空。
- 类型:字符串
- 默认值:“”
- 重要性:中等
timestamp.column.name
用一个或多个时间戳列的逗号分隔列表,以使用COALESCE SQL函数检测新行或修改过的行。每次轮询都会发现第一个非空时间戳值大于看到的最大先前时间戳值的行。至少一列不应为空。
- 类型:清单
- 默认值:“”
- 重要性:中等
validate.non.null
默认情况下,JDBC连接器将验证所有增量表和时间戳表是否将NOT NULL设置为用作其ID /时间戳的列。如果没有这些表,则JDBC连接器将无法启动。将此设置为false将禁用这些检查。
- 类型:布尔值
- 默认值:true
- 重要性:低
query
如果指定,则执行查询以选择新的或更新的行。如果要联接表,选择表中列的子集或过滤数据,请使用此设置。如果使用此连接器,则将仅使用此查询复制数据–整个表复制将被禁用。仍然可以使用不同的查询模式进行增量更新,但是为了正确地构造增量查询,必须有可能在此查询后附加WHERE子句(即,不得使用WHERE子句)。如果使用WHERE子句,则它本身必须处理增量查询。
- 类型:字符串
- 默认值:“”
- 重要性:中等
quote.sql.identifiers
何时在SQL语句中引用表名,列名和其他标识符。为了向后兼容,默认值为always。
- 类型:字符串
- 默认值:始终
- 重要性:中等
2.8.5 Connector
table.types
默认情况下,JDBC连接器将仅从源数据库中检测类型为TABLE的表。此配置允许提取命令分隔的表类型列表。
-
类型: list.
-
TABLE
-
VIEW
-
SYSTEM TABLE
-
GLOBAL TEMPORARY
-
LOCAL TEMPORARY
-
ALIAS
-
SYNONYM
在大多数情况下,只有TABLE或VIEW才有意义。
-
-
默认值:TABLE
-
重要性:低
poll.interval.ms
以毫秒为单位的频率,用于轮询每个表中的新数据。
- 类型:int
- 默认值:5000
- 重要性:高
batch.max.rows
轮询新数据时,单个批处理中包含的最大行数。此设置可用于限制连接器内部缓冲的数据量。
- 类型:int
- 默认值:100
- 重要性:低
table.poll.interval.ms
轮询新表或删除表的频率(以毫秒为单位),这可能导致更新的任务配置开始对添加表中的数据进行轮询或停止对删除表中的数据进行轮询。
- 类型:长
- 默认值:60000
- 重要性:低
topic.prefix
在表名之前添加前缀,以生成要向其发布数据的ApacheKafka®主题的名称,或者在自定义查询的情况下,生成要发布到的主题的全名。
- 类型:字符串
- 重要性:高
timestamp.delay.interval.ms
在将其包含在结果中之前,出现具有特定时间戳记的行之后需要等待多长时间。您可以选择添加一些延迟,以允许时间戳较早的事务完成。第一次执行将获取所有可用记录(即从时间戳0开始),直到当前时间减去延迟为止。接下来的每一次执行都会从上一次获取数据到当前时间减去延迟。
- 类型:长
- 默认值:0
- 重要性:高
db.timezone
使用基于时间的条件进行查询时,连接器中使用的JDBC时区的名称。默认为UTC。
- 类型:字符串
- 默认值:“ UTC”
- 有效值:任何有效的JDK时区
- 重要性:中等
2.9 示例
- 请求示例
-----------------------------示例JDBC Source---------------------------------------
curl -i -k -H "Content-type: application/json" -X POST -d '{
"name": "jdbc-source",
"config": {
"connector.class": "io.confluent.connect.jdbc.JdbcSourceConnector",
"tasks.max": "1",
"connection.url":"jdbc:mysql://mysql:3306/test",
"mode": "incrementing",
"connection.user":"root",
"connection.password":"root",
"dialect.name":"MySqlDatabaseDialect",
"table.whitelist":"test",
"schema.pattern":"",
"numeric.mapping":"best_fit",
"incrementing.column.name": "id",
"topic.prefix": "jdbc-source",
"key.converter":"org.apache.kafka.connect.storage.StringConverter",
"value.converter":"io.confluent.connect.avro.AvroConverter",
"value.converter.schema.registry.url":"http://master:8081"
}
}' http://localhost:8083/connectors
- 读取数据

三 、JDBC Sink 插件
Kafka Connect JDBC接收器连接器允许您使用JDBC驱动程序将数据从ApacheKafka®主题导出到任何关系数据库。通过使用JDBC,此连接器可以支持各种数据库,而无需为每个数据库使用专用的连接器。连接器根据主题订阅从Kafka轮询数据以写入数据库。可以通过upserts实现幂等写入。还支持表的自动创建和有限的自动演化。
3.1 Data mapping
接收器连接器需要架构知识,因此您应该使用合适的转换器,例如,架构注册表附带的Avro转换器或启用了架构的JSON转换器。Kafka记录键(如果存在)可以是原始类型或Connect结构,并且记录值必须是Connect结构。从“连接”结构中选择的字段必须是原始类型。如果主题中的数据不是兼容格式,则Converter可能需要实现自定义。
3.2 Key handling
缺省情况是,在pk.mode设置为none的情况下,不提取主键,这不适合高级用法(例如upsert语义)以及连接器负责自动创建目标表的情况。有多种模式可以使用来自Kafka记录键,Kafka记录值或该记录的Kafka坐标的字段。
有关更多详细信息,请参阅主键配置选项。
3.3 Delete mode
连接器使用逻辑删除记录时,该连接器可以删除数据库表中的行,该记录是具有非null键和null值的Kafka记录。默认情况下,此行为是禁用的,这意味着任何逻辑删除记录都将导致连接器发生故障,从而可以轻松升级JDBC连接器并保持先前的行为。
可以使用启用删除delete.enabled=true,但只有将pk.mode设置为时才可以启用record_key。这是因为从表中删除一行需要将主键用作条件。
启用删除模式不会影响insert.mode。
3.4 Idempotent writes
默认insert.mode值为insert。如果将其配置为upsert,则连接器将使用upsert语义而不是简单的INSERT语句。Upsert语义是指在存在主键约束冲突的情况下原子地添加新行或更新现有行,从而提供了幂等性。
如果存在故障,则用于恢复的Kafka偏移量可能与故障发生时未提交的内容保持最新,这可能导致恢复期间进行重新处理。强烈建议使用upsert模式,因为如果需要重新处理记录,它将有助于避免违反约束或重复数据。
除了故障恢复外,源主题还可以自然地随时间包含具有相同主键的多个记录,因此需要高证书。
由于没有用于upsert的标准语法,因此下表描述了所使用的特定于数据库的DML。
| Database | Upsert style |
|---|---|
| MySQL | INSERT .. ON DUPLICATE KEY REPLACE .. |
| Oracle | MERGE .. |
| PostgreSQL | INSERT .. ON CONFLICT .. DO UPDATE SET .. |
| SQLite | INSERT OR REPLACE .. |
| SQL Server | MERGE .. |
| Other | not supported |
3.5 Auto-creation and Auto-evoluton
如果auto.create启用,则连接器可以在发现目标表丢失的情况下创建目标表。由于连接器使用记录架构作为表定义的基础,因此创建是在线进行的,并使用了从该主题消费的记录。主键是根据键配置设置指定的。
如果auto.evolve启用此功能,则当连接器遇到发现缺少某列的记录时,可以通过在目标表上发出ALTER来执行有限的自动演化。由于数据类型的更改和列的删除可能很危险,因此连接器不会尝试在表上执行此类更改。也没有尝试添加主键约束。相反,如果auto.evolve禁用此选项,则不会执行任何演化,并且连接器任务将失败,并显示一条错误,指出缺少的列。
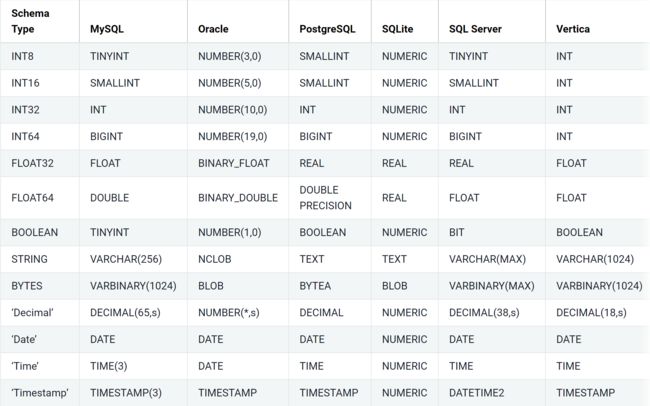
对于自动创建和自动演化,列的可空性基于架构中相应字段的可选性,并且如果适用,还基于相应字段的默认值指定默认值。我们使用以下从Connect模式类型到特定于数据库类型的映射:
3.6 环境准备
- Kafka和Schema Registry在默认端口上本地运行
- mysql可以远程访问
- 插件安装同上HDFS Sink安装方式
3.7 Configuration Properties
3.7.1配置类
要使用此连接器,请在connector.class配置属性中指定连接器类的名称。
connector.class=io.confluent.connect.jdbc.JdbcSinkConnector
连接器特定的配置属性如下所述。
3.7.2 数据库连接安全
在连接器配置中,您会注意到没有安全参数。这是因为SSL不属于JDBC标准,而是取决于所使用的JDBC驱动程序。通常,您需要通过connection.url参数配置SSL 。例如,对于MySQL,它看起来像:
connection.url="jdbc:mysql://127.0.0.1:3306/sample?verifyServerCertificate=false&useSSL=true&requireSSL=true"
请查阅有关支持和配置的特定JDBC驱动程序文档。
3.7.3 Connection
connection.url
JDBC连接URL。
- 类型:字符串
- 重要性:高
connection.user
JDBC连接用户。
- 类型:字符串
- 默认值:空
- 重要性:高
connection.password
JDBC连接密码。
- 类型:密码
- 默认值:空
- 重要性:高
dialect.name
该连接器应使用的数据库方言的名称。默认情况下为空,并且连接器根据JDBC连接URL自动确定方言。如果要覆盖该行为并使用特定的方言,请使用此选项。可以使用JDBC连接器插件中所有正确包装的方言。
- 类型:字符串
- 默认值:“”
- 有效值:[,Db2DatabaseDialect,MySqlDatabaseDialect,SybaseDatabaseDialect,GenericDatabaseDialect,OracleDatabaseDialect,SqlServerDatabaseDialect,PostgreSqlDatabaseDialect,SqliteDatabaseDialect,DerbyDatabaseDialect,SapHanaDatabaseDialect,MockDatabaseDialect,MockDatabaseDialect
- 重要性:低
3.7.4 Writes
insert.mode
要使用的插入模式。支持的模式有:
-
insert使用标准的SQL
INSERT语句。 -
upsert如果连接器支持目标数据库,请使用适当的upsert语义,例如。
INSERT OR IGNORE -
update如果连接器支持目标数据库,请使用适当的更新语义,例如
UPDATE。 -
类型:字符串
-
默认值:插入
-
有效值:[插入,向上插入,更新]
-
重要性:高
batch.size
指定在可能的情况下尝试将多少记录一起批处理以插入到目标表中。
- 类型:int
- 默认值:3000
- 有效值:[0,…]
- 重要性:中等
delete.enabled
是否将null记录值视为删除。要求pk.mode是record_key。
- 类型:布尔值
- 默认值:false
- 重要性:中等
3.7.5 Data Mapping
table.name.format
目标表名称的格式字符串,其中可以包含“ $ {topic}”作为源主题名称的占位符。
例如,kafka_${topic}对于主题“订单”将映射到表名称“ kafka_orders”。
- 类型:字符串
- 默认值:$ {topic}
- 重要性:中等
pk.mode
主键模式,也请参考pk.fields文档以了解交互作用。支持的模式有:
-
none没有使用键。
-
kafkaApacheKafka®坐标用作PK。
-
record_key使用了来自记录键的字段,该字段可以是基元或结构。
-
record_value使用记录值中的字段,该字段必须是结构。
-
类型:字符串
-
默认值:无
-
有效值:[none,kafka,record_key,record_value]
-
重要性:高
pk.fields
逗号分隔的主键字段名称列表。此配置的运行时解释取决于pk.mode:
-
none在此模式下,由于没有字段用作主键,因此将被忽略。
-
kafka必须是代表Kafka坐标的三重奏,
__connect_topic,__connect_partition,__connect_offset如果为空则默认为。 -
record_key如果为空,则将使用键结构中的所有字段,否则将用于提取所需的字段-对于原始键,仅必须配置一个字段名称。
-
record_value如果为空,将使用值struct中的所有字段,否则将提取所需的字段。
-
类型:清单
-
默认值:无
-
重要性:中等
fields.whitelist
以逗号分隔的记录值字段名称的列表。如果为空,将使用记录值中的所有字段,否则将用于过滤到所需的字段。
请注意,pk.fields在哪个字段在目标数据库中构成主键列的上下文中独立应用,而此配置适用于其他列。
- 类型:清单
- 默认值:“”
- 重要性:中等
db.timezone
插入基于时间的值时,连接器应使用的JDBC时区的名称。默认为UTC。
- 类型:字符串
- 默认值:“ UTC”
- 有效值:任何有效的JDK时区
- 重要性:中等
3.7.6 DDL Support
auto.create
如果通过发出发现缺少记录表,是否基于记录模式自动创建目标表CREATE。
- 类型:布尔值
- 默认值:false
- 重要性:中等
auto.evolve
通过发出相对于记录架构丢失时是否在表架构中自动添加列ALTER。
- 类型:布尔值
- 默认值:false
- 重要性:中等
quote.sql.identifiers
何时在SQL语句中引用表名,列名和其他标识符。为了向后兼容,默认值为always。
- 类型:字符串
- 默认值:始终
- 重要性:中等
3.7.6 Retries
-
max.retries任务失败前重试错误的最大次数。类型:int默认值:10有效值:[0,…]重要性:中等
-
retry.backoff.ms错误尝试重试之前等待的时间(以毫秒为单位)。类型:int默认值:3000有效值:[0,…]重要性:中等
3.8 示例
------------------------------------流处理---------------------------------------
curl -i -k -H "Content-type: application/json" -X POST -d '{
"name":"mysql-sink",
"config":{
"connector.class":"io.confluent.connect.jdbc.JdbcSinkConnector",
"connection.url":"jdbc:mysql://mysql:3306/test",
"connection.user":"root",
"connection.password":"root",
"dialect.name":"MySqlDatabaseDialect",
"topics":"dataxhive",
"insert.mode":"upsert",
"table.name.format":"test1",
"pk.mode":"record_value",
"pk.fields":"id",
"tasks.max":"1",
"key.converter":"org.apache.kafka.connect.storage.StringConverter",
"value.converter":"io.confluent.connect.avro.AvroConverter",
"value.converter.schema.registry.url":"http://master:8081"
}
}' http://localhost:8083/connectors
------------------------------------mudesa--------------------------------------
curl -i -k -H "Content-type: application/json" -X POST -d '{
"name":"mysql-sink",
"config":{
"connector.class":"io.confluent.connect.jdbc.JdbcSinkConnector",
"connection.url":"jdbc:mysql://mysql:3306/test",
"connection.user":"root",
"connection.password":"root",
"dialect.name":"MySqlDatabaseDialect",
"topics":"dataxhive",
"insert.mode":"upsert",
"table.name.format":"test1",
"pk.mode":"record_value",
"pk.fields":"id",
"tasks.max":"1",
"key.converter":"org.apache.kafka.connect.storage.StringConverter",
"value.converter":"io.confluent.connect.avro.AvroConverter",
"value.converter.schema.registry.url":"http://master:8081",
"type":"key",
"offsetKey":"dataxhive"
}
}' http://localhost:8083/connectors
- user原表数据
1 1.20 1.055 1.25 2020-05-16 dadadas 16:04:42.000000 2020-05-16 16:04:47.000000
2 1.20 1.055 1.25 2020-05-16 dadadas 16:04:42.000000 2020-05-16 16:04:47.000000
3 1.20 1.055 1.25 2020-05-16 dadadas 16:04:42.000000 2020-05-16 16:04:47.000000
4 1.20 1.055 1.25 2020-05-16 dadadas 16:04:42.000000 2020-05-16 16:04:47.000000
5 1.20 1.055 1.25 2020-05-16 dadadas 16:04:42.000000 2020-05-16 16:04:47.000000
6 1.20 1.055 1.25 2020-05-16 dadadas 16:04:42.000000 2020-05-16 16:04:47.000000
7 1.20 1.055 1.25 2020-05-16 dadadas 16:04:42.000000 2020-05-16 16:04:47.000000
8 1.20 1.055 1.25 2020-05-16 dadadas 16:04:42.000000 2020-05-16 16:04:47.000000
9 1.20 1.055 1.25 2020-05-16 dadadas 16:04:42.000000 2020-05-16 16:04:47.000000
10 1.20 1.055 1.25 2020-05-16 dadadas 16:04:42.000000 2020-05-16 16:04:47.000000
11 1.20 1.055 1.25 2020-05-16 dadadas 16:04:42.000000 2020-05-16 16:04:47.000000
12 1.20 1.055 1.25 2020-05-16 dadadas 16:04:42.000000 2020-05-16 16:04:47.000000
13 1.20 1.055 1.25 2020-05-16 dadadas 16:04:42.000000 2020-05-16 16:04:47.000000
14 1.20 1.055 1.25 2020-05-16 dadadas 16:04:42.000000 2020-05-16 16:04:47.000000
15 1.20 1.055 1.25 2020-05-16 dadadas 16:04:42.000000 2020-05-16 16:04:47.000000
16 1.20 1.055 1.25 2020-05-16 dadadas 16:04:42.000000 2020-05-16 16:04:47.000000
17 1.20 1.055 1.25 2020-05-16 dadadas 16:04:42.000000 2020-05-16 16:04:47.000000
18 1.20 1.055 1.25 2020-05-16 dadadas 16:04:42.000000 2020-05-16 16:04:47.000000
19 1.20 1.055 1.25 2020-05-16 dadadas 16:04:42.000000 2020-05-16 16:04:47.000000
20 1.20 1.055 1.25 2020-05-16 dadadas 16:04:42.000000 2020-05-16 16:04:47.000000
21 1.20 1.055 1.25 2020-05-16 dadadas 16:04:42.000000 2020-05-16 16:04:47.000000
22 1.20 1.055 1.25 2020-05-16 dadadas 16:04:42.000000 2020-05-16 16:04:47.000000
23 1.20 1.055 1.25 2020-05-16 dadadas 16:04:42.000000 2020-05-16 16:04:47.000000
- 导入mysql数据
1 1.20 1.055 1.25 2020-05-15 dadadas 16:04:42.000000 2020-05-16 16:04:47.000000
2 1.20 1.055 1.25 2020-05-15 dadadas 16:04:42.000000 2020-05-16 16:04:47.000000
3 1.20 1.055 1.25 2020-05-15 dadadas 16:04:42.000000 2020-05-16 16:04:47.000000
4 1.20 1.055 1.25 2020-05-15 dadadas 16:04:42.000000 2020-05-16 16:04:47.000000
5 1.20 1.055 1.25 2020-05-15 dadadas 16:04:42.000000 2020-05-16 16:04:47.000000
6 1.20 1.055 1.25 2020-05-15 dadadas 16:04:42.000000 2020-05-16 16:04:47.000000
7 1.20 1.055 1.25 2020-05-15 dadadas 16:04:42.000000 2020-05-16 16:04:47.000000
8 1.20 1.055 1.25 2020-05-15 dadadas 16:04:42.000000 2020-05-16 16:04:47.000000
9 1.20 1.055 1.25 2020-05-15 dadadas 16:04:42.000000 2020-05-16 16:04:47.000000
10 1.20 1.055 1.25 2020-05-15 dadadas 16:04:42.000000 2020-05-16 16:04:47.000000
11 1.20 1.055 1.25 2020-05-15 dadadas 16:04:42.000000 2020-05-16 16:04:47.000000
12 1.20 1.055 1.25 2020-05-15 dadadas 16:04:42.000000 2020-05-16 16:04:47.000000
13 1.20 1.055 1.25 2020-05-15 dadadas 16:04:42.000000 2020-05-16 16:04:47.000000
14 1.20 1.055 1.25 2020-05-15 dadadas 16:04:42.000000 2020-05-16 16:04:47.000000
15 1.20 1.055 1.25 2020-05-15 dadadas 16:04:42.000000 2020-05-16 16:04:47.000000
16 1.20 1.055 1.25 2020-05-15 dadadas 16:04:42.000000 2020-05-16 16:04:47.000000
17 1.20 1.055 1.25 2020-05-15 dadadas 16:04:42.000000 2020-05-16 16:04:47.000000
18 1.20 1.055 1.25 2020-05-15 dadadas 16:04:42.000000 2020-05-16 16:04:47.000000
19 1.20 1.055 1.25 2020-05-15 dadadas 16:04:42.000000 2020-05-16 16:04:47.000000
20 1.20 1.055 1.25 2020-05-15 dadadas 16:04:42.000000 2020-05-16 16:04:47.000000
21 1.20 1.055 1.25 2020-05-15 dadadas 16:04:42.000000 2020-05-16 16:04:47.000000
22 1.20 1.055 1.25 2020-05-15 dadadas 16:04:42.000000 2020-05-16 16:04:47.000000
23 1.20 1.055 1.25 2020-05-15 dadadas 16:04:42.000000 2020-05-16 16:04:47.000000
四、问题汇总及其解决方案
-
hive内依赖的guava.jar和hadoop内的版本不一致造成的。
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/data/hadoop/share/hadoop/common/lib/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/data/hive/lib/log4j-slf4j-impl-2.10.0.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
2020-05-17 15:15:01,030 INFO [main] conf.HiveConf (HiveConf.java:findConfigFile(187)) - Found configuration file file:/data/hive/conf/hive-site.xml
Exception in thread "main" java.lang.NoSuchMethodError: com.google.common.base.Preconditions.checkArgument(ZLjava/lang/String;Ljava/lang/Object;)V
at org.apache.hadoop.conf.Configuration.set(Configuration.java:1357)
at org.apache.hadoop.conf.Configuration.set(Configuration.java:1338)
at org.apache.hadoop.mapred.JobConf.setJar(JobConf.java:518)
at org.apache.hadoop.mapred.JobConf.setJarByClass(JobConf.java:536)
at org.apache.hadoop.mapred.JobConf.<init>(JobConf.java:430)
at org.apache.hadoop.hive.conf.HiveConf.initialize(HiveConf.java:5141)
at org.apache.hadoop.hive.conf.HiveConf.<init>(HiveConf.java:5099)
at org.apache.hadoop.hive.common.LogUtils.initHiveLog4jCommon(LogUtils.java:97)
at org.apache.hadoop.hive.common.LogUtils.initHiveLog4j(LogUtils.java:81)
at org.apache.hadoop.hive.cli.CliDriver.run(CliDriver.java:699)
at org.apache.hadoop.hive.cli.CliDriver.main(CliDriver.java:683)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.apache.hadoop.util.RunJar.run(RunJar.java:318)
at org.apache.hadoop.util.RunJar.main(RunJar.java:232)
------------------------------------解决方案------------------------------------------
com.google.common.base.Preconditions.checkArgument 这是因为hive内依赖的guava.jar和hadoop内的版本不一致造成的。
-
hiveserver2启动不了端口10000解决过程
- 参考文档
-
Decimal精确度引起的Hive不能解析问题
解决思路参考
------------------------------HDFS插件自动建表的sql语句----------------- CREATE EXTERNAL TABLE `dataxhive1`( ) PARTITIONED BY ( `partition` string COMMENT '') ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.avro.AvroSerDe' STORED AS INPUTFORMAT 'org.apache.hadoop.hive.ql.io.avro.AvroContainerInputFormat' OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.avro.AvroContainerOutputFormat' LOCATION 'hdfs://master:9002/topics/dataxhive' TBLPROPERTIES ( 'avro.schema.literal'='{"type":"record","name":"dataxhive","fields":[{"name":"id","type":["null",{"type":"int","connect.name":"INT"}],"default":null},{"name":"a","type":["null",{"type":"double","connect.name":"DOUBLE"}],"default":null},{"name":"b","type":["null",{"type":"float","connect.name":"FLOAT"}],"default":null},{"name":"c","type":["null",{"type":"bytes","scale":2,"precision":64,"connect.version":1,"connect.parameters":{"scale":"2"},"connect.name":"org.apache.kafka.connect.data.Decimal","logicalType":"decimal"}],"default":null},{"name":"d","type":["null",{"type":"int","connect.version":1,"connect.name":"org.apache.kafka.connect.data.Date","logicalType":"date"}],"default":null},{"name":"e","type":["null",{"type":"string","connect.name":"STRING"}],"default":null},{"name":"f","type":["null",{"type":"int","connect.version":1,"connect.name":"org.apache.kafka.connect.data.Time","logicalType":"time-millis"}],"default":null},{"name":"g","type":["null",{"type":"long","connect.version":1,"connect.name":"org.apache.kafka.connect.data.Timestamp","logicalType":"timestamp-millis"}],"default":null}],"connect.version":1,"connect.name":"dataxhive"}', 'transient_lastDdlTime'='1589767539')
- 在调试本文档时需要用到的相关指令集
# 获取所有任务
curl -X GET http://localhost:8083/connectors
# 删除指定任务
curl -X DELETE http://localhost:8083/connectors/hdfs3-sink
# metastore 后台运行
nohup hive --service metastore 1>/dev/null 2>&1 &
# hiveserver2 后台运行
nohup hiveserver2 1>/dev/null 2>&1 &
# 进入hiveSql
beeline -u jdbc:hive2://localhost:10000 -n root
# 获取Kafka集群消费组
kafka-consumer-groups.sh --bootstrap-server localhost:9092 --list
# 删除指定的消费组
kafka-consumer-groups.sh --bootstrap-server localhost:9092 --delete --group test
附录:
mysql表信息
/*
Navicat MySQL Data Transfer
Source Server : master
Source Server Version : 50721
Source Host : master:3306
Source Database : test
Target Server Type : MYSQL
Target Server Version : 50721
File Encoding : 65001
Date: 2020-05-18 17:01:06
*/
SET FOREIGN_KEY_CHECKS=0;
-- ----------------------------
-- Table structure for test
-- ----------------------------
DROP TABLE IF EXISTS `test`;
CREATE TABLE `test` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`a` double(255,2) DEFAULT NULL,
`b` float(255,3) DEFAULT NULL,
`c` decimal(56,2) DEFAULT NULL,
`d` date DEFAULT NULL,
`e` varchar(255) DEFAULT NULL,
`f` time(6) DEFAULT NULL,
`g` datetime(6) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=24 DEFAULT CHARSET=utf8;
-- ----------------------------
-- Records of test
-- ----------------------------
INSERT INTO `test` VALUES ('1', '1.20', '1.055', '1.25', '2020-05-16', 'dadadas', '16:04:42.000000', '2020-05-16 16:04:47.000000');
INSERT INTO `test` VALUES ('2', '1.20', '1.055', '1.25', '2020-05-16', 'dadadas', '16:04:42.000000', '2020-05-16 16:04:47.000000');
INSERT INTO `test` VALUES ('3', '1.20', '1.055', '1.25', '2020-05-16', 'dadadas', '16:04:42.000000', '2020-05-16 16:04:47.000000');
INSERT INTO `test` VALUES ('4', '1.20', '1.055', '1.25', '2020-05-16', 'dadadas', '16:04:42.000000', '2020-05-16 16:04:47.000000');
INSERT INTO `test` VALUES ('5', '1.20', '1.055', '1.25', '2020-05-16', 'dadadas', '16:04:42.000000', '2020-05-16 16:04:47.000000');
INSERT INTO `test` VALUES ('6', '1.20', '1.055', '1.25', '2020-05-16', 'dadadas', '16:04:42.000000', '2020-05-16 16:04:47.000000');
INSERT INTO `test` VALUES ('7', '1.20', '1.055', '1.25', '2020-05-16', 'dadadas', '16:04:42.000000', '2020-05-16 16:04:47.000000');
INSERT INTO `test` VALUES ('8', '1.20', '1.055', '1.25', '2020-05-16', 'dadadas', '16:04:42.000000', '2020-05-16 16:04:47.000000');
INSERT INTO `test` VALUES ('9', '1.20', '1.055', '1.25', '2020-05-16', 'dadadas', '16:04:42.000000', '2020-05-16 16:04:47.000000');
INSERT INTO `test` VALUES ('10', '1.20', '1.055', '1.25', '2020-05-16', 'dadadas', '16:04:42.000000', '2020-05-16 16:04:47.000000');
INSERT INTO `test` VALUES ('11', '1.20', '1.055', '1.25', '2020-05-16', 'dadadas', '16:04:42.000000', '2020-05-16 16:04:47.000000');
INSERT INTO `test` VALUES ('12', '1.20', '1.055', '1.25', '2020-05-16', 'dadadas', '16:04:42.000000', '2020-05-16 16:04:47.000000');
INSERT INTO `test` VALUES ('13', '1.20', '1.055', '1.25', '2020-05-16', 'dadadas', '16:04:42.000000', '2020-05-16 16:04:47.000000');
INSERT INTO `test` VALUES ('14', '1.20', '1.055', '1.25', '2020-05-16', 'dadadas', '16:04:42.000000', '2020-05-16 16:04:47.000000');
INSERT INTO `test` VALUES ('15', '1.20', '1.055', '1.25', '2020-05-16', 'dadadas', '16:04:42.000000', '2020-05-16 16:04:47.000000');
INSERT INTO `test` VALUES ('16', '1.20', '1.055', '1.25', '2020-05-16', 'dadadas', '16:04:42.000000', '2020-05-16 16:04:47.000000');
INSERT INTO `test` VALUES ('17', '1.20', '1.055', '1.25', '2020-05-16', 'dadadas', '16:04:42.000000', '2020-05-16 16:04:47.000000');
INSERT INTO `test` VALUES ('18', '1.20', '1.055', '1.25', '2020-05-16', 'dadadas', '16:04:42.000000', '2020-05-16 16:04:47.000000');
INSERT INTO `test` VALUES ('19', '1.20', '1.055', '1.25', '2020-05-16', 'dadadas', '16:04:42.000000', '2020-05-16 16:04:47.000000');
INSERT INTO `test` VALUES ('20', '1.20', '1.055', '1.25', '2020-05-16', 'dadadas', '16:04:42.000000', '2020-05-16 16:04:47.000000');
INSERT INTO `test` VALUES ('21', '1.20', '1.055', '1.25', '2020-05-16', 'dadadas', '16:04:42.000000', '2020-05-16 16:04:47.000000');
INSERT INTO `test` VALUES ('22', '1.20', '1.055', '1.25', '2020-05-16', 'dadadas', '16:04:42.000000', '2020-05-16 16:04:47.000000');
INSERT INTO `test` VALUES ('23', '1.20', '1.055', '1.25', '2020-05-16', 'dadadas', '16:04:42.000000', '2020-05-16 16:04:47.000000');
DataX 任务配置信息
{
"job":{
"setting":{
"speed":{
"channel":1
},
"errorLimit":{
"record":0,
"percentage":0.02
}
},
"content":[
{
"reader":{
"name":"mysqlreader",
"parameter":{
"username":"root",
"password":"",
"column":[
"id",
"a",
"b",
"c",
"d",
"e",
"f",
"g"
],
"connection":[
{
"table":[
"test"
],
"jdbcUrl":[
"jdbc:mysql://master:3306/test"
]
}
]
}
},
"writer":{
"name":"kafkaWriter",
"parameter":{
"kafkaConfig":{
"bootstrap.servers":"master:9092,slaver:9092"
},
"topics":"dataxhive",
"column":{
"type":"record",
"name":"dataxhive",
"fields":[
{
"name":"id",
"type":"int",
"index":0
},
{
"name":"a",
"type":"double",
"index":1
},
{
"name":"b",
"type":"float",
"index":2
},
{
"name":"c",
"type":"decimal",
"scale":2,
"index":3
},
{
"name":"d",
"type":"date",
"index":4
},
{
"name":"e",
"type":"string",
"index":5
},
{
"name":"f",
"type":"time",
"index":6
},
{
"name":"g",
"type":"datetime",
"index":7
}
]
},
"medusa":{
"hostName":"http://192.168.101.42:8083,http://192.168.101.43:8083",
"name":"dataxhive"
},
"schemaRegistry":{
"schema.registry.url":"http://192.168.101.43:8081",
"schemas.enable":true,
"value.converter":"io.confluent.connect.avro.AvroConverter"
}
}
}
}
]
}
}