什么是知识图谱?
知识图谱是表示事实的结构化的方法,与一般的图(Graph)不同的是,在知识图谱中节点和边通常具有一些含义,例如演员的名字或电影中的演员。
0.
罗素等人在书中论述说,“所有的数学法则,都可自下而上地用无可辩驳的基本逻辑来建立( all of mathematics could be built om the ground up using basic, indisputable logic )”
而在底层、基础的逻辑, 即为是与非两种判定。
然后,通过对这两个逻辑判定进行系列的组合操作,例如,合取(conjunction)实现“与( and )”操作、析取(disjunction)实现“或( or )”操作、取反(negation )实现“否(not)”操作,这样就可以瓦地构起复杂的数学大厦.
这里多说两句。罗素等人的论断,在思想上,其实算不上创新。早在春秋时期, 老子就在《道德经》写下了明断,“道生一,一生 ,二生三, 三生万物” 。
无论是罗素等人的论断,还是老子的明断,在哲学上都同属还原论(Reductionism) 的范畴.
这段话摘自张玉宏的《深度学习之美》。
1. 什么是知识图谱?
知识图谱,是基于二元关系的知识库,旨在描述现实世界中存在的各种实体或概念(“苹果”是一个实体;“水果”是“苹果”的概念),及其相互关系。其基本组成单位是“实体-关系-实体”的三元组,实体之间通过关系相互联结,构成网状结构。
在实践中,我们并不需要太过纠结使用哪种工具的才是知识图谱,哪些不是。关键是它的本质是什么。
而理解本质需要从知识图谱的演化过程入手。
2. 知识图谱的演化
知识图谱这个概念是近五、六年才逐渐为人所知的,但这项技术本身则可追溯到五六十年代前就已经形成的一个方向:即知识工程。我们叫它符号主义或者理性主义,也就是我们之前第3问提到过的人工智能领域内的三大学术流派之一。
60年代的语义网络
六十年代有一种东西叫做语义网络。语义网络的诞生起源于一些做认知科学的学者,他们认为人类的自然语言是很复杂的,和计算机储存信息的差别非常大。如何把人类的自然语言用一种符号化的形式表示出来,从而让计算机也能够读懂和学会。
给大家看一个语义网络的示例就很容易明白了:
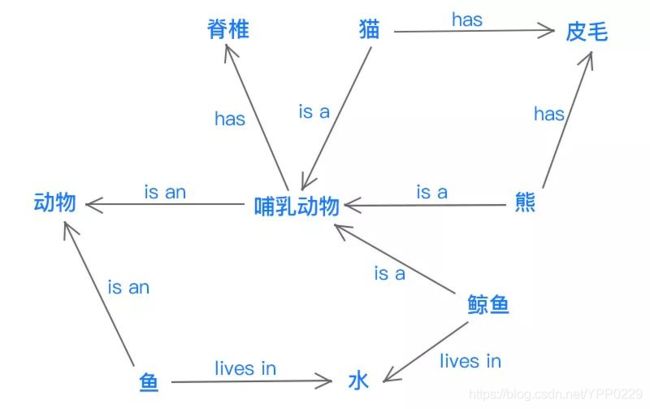
语义网络其实就是一个网络。这张图上有各种不同的概念,比如,中间的哺乳动物,猫(cat)是一种哺乳动物,猫有毛(Fur);熊是哺乳动物,熊也有毛;鲸(Whale)是哺乳动物,但生活在水里面;鱼也生活在水里面,但不是哺乳动物,而属于哺乳动物的上位概念:动物(Animal)这个类别;哺乳动物是一种脊椎动物(Vertebra),也是动物的一种。
看懂了这张示例图,大家理解起来是不是有点儿感觉了呢?
70-80年代的描述逻辑
语义网络到了七十、八十年代时演化成了描述逻辑。产生这种变化的原因在于,很多从事自然语言处理和知识表现的学者批评了这种语义网络,他们认为语义网络本身只是一种表征,而没有办法用于推理。语义网络+推理变成了新的逻辑系统,叫做“描述逻辑”

如上图所示,假设我们知道1)Gowild是一个人工智能公司;2)人工智能公司是高科技公司。那么就可以推理得出:Gowild是高科技公司。很容易理解对吧!
再比如,1)投资是投资人投资公司;2)胡海泉投资了Gowild。那么我们就可以推理出:1)胡海泉是一个投资人;2)Gowild是一个公司。
当然这都是一些比较简单的例子,人类的语言远比这些要复杂得多。
90年代-OWL
知识图谱技术的发展历史总的来说可以分为两个大的阶段:一个是从六十年代到九十年代,早期的知识图谱原型,包括语义网络、专家系统等等;第二个就是从语义网络到描述逻辑,一直发展到OWL(并行的还有另外一些,比如基于框架逻辑产生的另外一种语言“RIF”)。
这十几年的时间,实际上完成了一种从弱语义到强语义的尝试,不断加强语义表现的表达力,但最后证明这个做法是不太妥当的。
虽然在最早的语义网络里,我们无法定义一个词的意义。比如,第一个例子图中居于中间位置的词语“哺乳动物”,我们很难让计算机理解什么是真正的哺乳动物。但对于计算机而言,它只需要知道万事万物之间的联系,对于机器处理来说就够了。
虽然语义网络没有所谓的“语义”,但它的语义其实都在关系里了。
3. 元数据框架到RDF
除了学术性很强的描述逻辑OWL分支之外,知识图谱还有另外一个分支是来自于元数据框架的。这个工作最早是一个叫“Guha”的人在苹果公司做的,Ghua在某种程度上可以说是“知识图谱之父”,谷歌的知识图谱建立的背后Ghua也是主要推手。
1997年Guha发明了RDF,并且在RDF的基础上发明了RSS语言。十多年前我们看新闻都是用RSS订阅的。从本源上来讲,RSS这项技术就是RDF的第一个应用。RSS的第一个字母“R”就是RDF。
RDF的本质就是三元组,主语、谓语、宾语就是个三元组。 比如,“我叫小T”,“我”是主语,“是”是谓语,“小T”是宾语。在RDF这个框架下,万事万物各种复杂的关系最后都被拆分成三元组。
RDF是一个没有语义的元数据框架,它和前面提到的描述逻辑不同,描述逻辑是从实验室里来的,它想构建一个庞大的体系,一个完美的知识表现语言,然后再寻求落地。
而RDF从一开始就是一个从实践出发、自底向上的语言。我们日常生活中所遇到的绝大多数网站,都有着某种类型的元数据,其中相当一部分就是用RDF的不同变种来实现的。所以RDF总得来说是一个比较成功的技术,因为它来自于现实的实践基础。
4. 小 结
知识图谱的领域从 2006 年往前一直不断从弱语义到强语义的发展过程中,这个阶段最后被证明是不太成功的。2006 年之后这个领域不断的强调工程、强调应用、强调数据、强调跟实践最相关的东西,语义也进一步弱化,又从强语义再次回归到弱语义。2012 年谷歌的知识图谱是完全抛弃掉语义的。
从二十年来的历史表明,从实践中总结的方法要优于从顶向下设计的方法。简单的优于强大的,太过复杂的比如 OWL 最终用不起来,反而比较简单的的像 RDF、最近比较火的 JSON‑LD 用得越来越多。越简单越好,这就是 20 年来最核心学习到的东西。
5. 参考
原文作者作者:图灵链小T
链接:https://www.jianshu.com/p/1e7664e6c5c5
来源:简书
简书著作权归作者所有,任何形式的转载都请联系作者获得授权并注明出处。