Antlr4入门(六)实战之JSON
本章中,我们将学习编写JSON语法文件,即如何通过阅读参考手册、样例代码和已有的非ANTLR语法来构造完整的语法。接着我们将使用监听器或访问器来将JSON格式转成XML。
注:JSON是一种存储键值对的数据结构,由于值本身也可以作为键值对的容器,所以JSON中可以包含嵌套结构。
一、自顶向下的设计——编写JSON语法
在本章中,我们的目标是通过阅读JSON参考手册、查看它的语法描述图和现有的语法来构造一个能够解析JSON的ANTLR语法。下面,我们将从JSON参考手册中提取关键词汇,然后一步步将它们编写成ANTLR规则。
一个JSON文件可以是一个对象,或者是由若干个值组成的数组从语法上看,这不过是一个选择模式,因此,我们可以使用下列规则来表达:
// 一个JSON文件可以是一个对象,或者是由若干个值组成的数组
json : object
| array
;下一步是将json规则引用的各个子规则进行分解。对于对象,JSON语法是这样定义的:
一个对象是一组无序的键值对集合。一个对象以一个左花括号{开始,且以右花括号}结束。每个键后跟一个冒号:,键值对之间由逗号,分隔。JSON官网上的语法图强调对象中的键必须是字符串。为将上面这段自然语言的表述转换成语法结构,我们试着将它分解,从中提取关键的、能够指示采用何种模式的词组。第一句话中的“一个对象是”明确地告诉我们创建一个名为“object”的规则。接着,“一组无序的键值对集合”实际上是若干个“键值对”组成的序列。而“无序的集合”指明了对象的键的语义,即键的顺序没有意义。第二个句子中引入了一个词法符号依赖,一个对象是以左右花括号作为开始和结束的。最后一个句子进一步指明了键值对序列的细节:由逗号分隔。至此,我们可以得到以下ANTLR标记编写的语法:
// 一个对象是一组无序的键值对集合。一个对象以一个左花括号{开始,且以右花括号}结束。
// 每个键后跟一个冒号:,键值对之间由逗号,分隔
object : '{' pair (',' pair)* '}'
| '{' '}'
;
pair : STRING ':' value;下面,我们接着来看JSON中另外一种高级结构——数组。数组的语法描述如下:
数组是一组值的有序集合。一个数组由一个左方括号[开始,并以一个右方括号]结束。其中的值由逗号,分隔和object规则一样,array包含一个由逗号分隔的序列模式和一个左右方括号间的词法符号依赖。
// 数组是一组值的有序集合。一个数组由一个左方括号[开始,并以一个右方括号]结束。
// 其中的值由逗号,分隔
array : '[' value (',' value)* ']'
| '[' ']'
;在上诉规则的基础上进一步细分,我们就需要编写规则value。通过查看JSON参考手册,我们可以知道value的语法描述如下:
一个值可以是一个双引号包围的字符串、一个数字、true\false、null、一个对象、或者一个数组。显而易见,这是一个很简单的选择模式。
// 一个值可以是一个双引号包围的字符串、一个数字、true\false、null、一个对象、或者一个数组。
value : STRING
| NUMBER
| 'true'
| 'false'
| 'null'
| object
| array
;这里,由于value规则引用了object和array,它成为(间接)递归规则。以上就是解析JSON的所有语法规则,下面我们来看下词法规则。
根据JSON语法参考,字符串定义如下:
一个字符串就是一个由零个或多个Unicode字符组成的序列,它由双引号包围,其中的Unicode字符使用反斜杠转义。单个字符由长度为1的字符串表示。JSON的字符串定义和C/Java中的字符串非常相似。其实在前文中,我们已经编写了字符串的ANTLR词法规则,而这里的JSON字符串定义只是比我们之前编写的字符串增加了对Unicode字符的转义。我们接着查看JSON参考手册,可以得到以下需要被转义的字符。

因此,我们的string规则定义如下:
// 一个字符串就是一个由零个或多个Unicode字符组成的序列,它由双引号包围,其中的字符使用反斜杠转义。
// 单个字符由长度为1的字符串表示
STRING : '"' (ESC | ~["\\])* '"';
fragment ESC : '\\' (["\\/bfnrt] | UNICODE);
fragment UNICODE : 'u' HEX HEX HEX HEX;
fragment HEX : [0-9a-fA-F];其中ESC片段规则匹配一个Unicode序列或者预定义的转义字符。而在UNICODE片段规则中,我们又定义了一个HEX片段规则来替代需要多次重复的编写的十六进制数字。
最后一个需要编写的词法符号是NUMBER。
// 一个数字和C/Java中的数字非常相似,除了一点之外:不允许使用八进制和十六进制
NUMBER
: '-'? INT '.' [0-9]+ EXP? // 1.35, 1.35E-9, 0.3, -4.5
| '-'? INT EXP // 1e10 -3e4
| '-'? INT // -3, 45
;
fragment INT : '0' | [1-9] [0-9]* ; // 除零外的数字不允许以0开始
fragment EXP : [Ee] [+\-]? INT ; // \- 是对-的转义,因为[...]中的-用于表示“范围”和上一章CSV语法中不同的是,JSON需要额外处理空白字符。
WS : [ \t\n\r]+ -> skip ;至此,完整的JSON语法文件已经编写完毕。下面是完整的JSON语法文件并为备选分支添加标签后的结果:
grammar JSON;
// 一个JSON文件可以是一个对象,或者是由若干个值组成的数组
json : object
| array
;
// 一个对象是一组无序的键值对集合。一个对象以一个左花括号{开始,且以右花括号}结束。
// 每个键后跟一个冒号:,键值对之间由逗号,分隔
object : '{' pair (',' pair)* '}' #AnObject
| '{' '}' #EmptyObject //空对象
;
pair : STRING ':' value;
// 数组是一组值的有序集合。一个数组由一个左方括号[开始,并以一个右方括号]结束。
// 其中的值由逗号,分隔
array : '[' value (',' value)* ']' #ArrayOfValues
| '[' ']' #EmptyArray //空数组
;
// 一个值可以是一个双引号包围的字符串、一个数字、true\false、null、一个对象、或者一个数组。
value : STRING #String
| NUMBER #Atom
| 'true' #Atom
| 'false' #Atom
| 'null' #Atom
| object #ObjectValue
| array #ArrayValue
;
// 一个字符串就是一个由零个或多个Unicode字符组成的序列,它由双引号包围,其中的字符使用反斜杠转义。
// 单个字符由长度为1的字符串表示
STRING : '"' (ESC | ~["\\])* '"';
fragment ESC : '\\' (["\\/bfnrt] | UNICODE);
fragment UNICODE : 'u' HEX HEX HEX HEX;
fragment HEX : [0-9a-fA-F];
// 一个数字和C/Java中的数字非常相似,除了一点之外:不允许使用八进制和十六进制
NUMBER
: '-'? INT '.' [0-9]+ EXP? // 1.35, 1.35E-9, 0.3, -4.5
| '-'? INT EXP // 1e10 -3e4
| '-'? INT // -3, 45
;
fragment INT : '0' | [1-9] [0-9]* ; // no leading zeros
fragment EXP : [Ee] [+\-]? INT ; // \- since - means "range" inside [...]
WS : [ \t\n\r]+ -> skip ;让我们使用ANTLR工具来测试下吧。
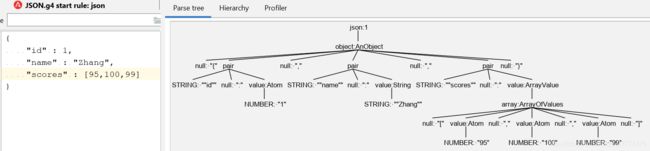
二、将JSON转成XML
在本小节中我们将构建一个从JSON到XML的翻译器。对于以下JSON输入,我们期待的输出是:

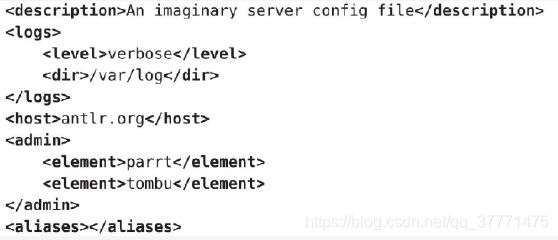
其中,
由于监听器无法存储值(返回类型是void),所以我们需要ParseTreeProperty来存放中间结果。

接着我们从最简单规则的开始翻译。value规则中的Atom备选分支用于匹配词法符号中的文本内容,对于它,我们只需要将值存入ParseTreeProperty即可。
@Override
public void exitAtom(JSONParser.AtomContext ctx) {
setXml(ctx, ctx.getText());
}而对于string,我们需要做一个额外处理——剔除首位双引号。
@Override
public void exitArrayOfValues(JSONParser.ArrayOfValuesContext ctx) {
StringBuilder stringBuilder = new StringBuilder();
stringBuilder.append("\n");
for (JSONParser.ValueContext valueContext : ctx.value()){
stringBuilder.append("");
stringBuilder.append(getXml(valueContext));
stringBuilder.append("");
stringBuilder.append("\n");
}
setXml(ctx,stringBuilder.toString());
}
@Override
public void exitString(JSONParser.StringContext ctx) {
setXml(ctx, stripQuotes(ctx.getText()));
} 而对于value规则的ObjectValue和ArrayValue备选分支,其实只需要去调用object和array规则方法就行。
@Override
public void exitObjectValue(JSONParser.ObjectValueContext ctx) {
// 类比 String value() { return object(); }
setXml(ctx,getXml(ctx.object()));
}
@Override
public void exitArrayValue(JSONParser.ArrayValueContext ctx) {
setXml(ctx,getXml(ctx.array()));
}在完成对value规则所有元素的翻译后,我们需要处理键值对,将它们转换成标签和文本。对于STRING ':' value,分别对应XML中标签名和标签值。因此,它们的翻译结果如下:
@Override
public void exitPair(JSONParser.PairContext ctx) {
String tag = stripQuotes(ctx.STRING().getText());
String value = String.format("<%s>%s<%s>\n",tag,getXml(ctx.value()),tag);
setXml(ctx,value);
}而对于object规则,我们知道它是由一系列的键值对组成,也就是说,我们需要循环遍历其中的键值对,将其对应的XML追加到语法分析树存储的结果中。
@Override
public void exitAnObject(JSONParser.AnObjectContext ctx) {
StringBuilder stringBuilder = new StringBuilder();
stringBuilder.append("\n");
for (JSONParser.PairContext pairContext : ctx.pair()){
stringBuilder.append(getXml(pairContext));
}
setXml(ctx,stringBuilder.toString());
}
@Override
public void exitEmptyObject(JSONParser.EmptyObjectContext ctx) {
setXml(ctx,"");
}
同理,对于array规则,我们采用同样的处理方式,唯一不同的是,我们需要为子节点添加标签
@Override
public void exitArrayOfValues(JSONParser.ArrayOfValuesContext ctx) {
StringBuilder stringBuilder = new StringBuilder();
stringBuilder.append("\n");
for (JSONParser.ValueContext valueContext : ctx.value()){
stringBuilder.append("");
stringBuilder.append(getXml(valueContext));
stringBuilder.append("");
stringBuilder.append("\n");
}
setXml(ctx,stringBuilder.toString());
}
@Override
public void exitEmptyArray(JSONParser.EmptyArrayContext ctx) {
setXml(ctx,"");
} 最后,我们将最终结果存入根节点中。
@Override
public void exitJson(JSONParser.JsonContext ctx) {
setXml(ctx,getXml(ctx.getChild(0)));
}完整的翻译器代码如下:
package json;
import org.antlr.v4.runtime.tree.ParseTree;
import org.antlr.v4.runtime.tree.ParseTreeProperty;
public class JSONToXMLListener extends JSONBaseListener {
// 将每棵子树翻译完的字符串存储在该子树的根节点中
private ParseTreeProperty xml = new ParseTreeProperty();
public void setXml(ParseTree node, String value){
xml.put(node, value);
}
public String getXml(ParseTree node){
return xml.get(node);
}
/**
* 去掉字符串首尾的双引号""
* @param s
* @return
*/
public String stripQuotes(String s) {
if ( s==null || s.charAt(0)!='"' ) return s;
return s.substring(1, s.length() - 1);
}
@Override
public void exitJson(JSONParser.JsonContext ctx) {
setXml(ctx,getXml(ctx.getChild(0)));
}
@Override
public void exitAnObject(JSONParser.AnObjectContext ctx) {
StringBuilder stringBuilder = new StringBuilder();
stringBuilder.append("\n");
for (JSONParser.PairContext pairContext : ctx.pair()){
stringBuilder.append(getXml(pairContext));
}
setXml(ctx,stringBuilder.toString());
}
@Override
public void exitEmptyObject(JSONParser.EmptyObjectContext ctx) {
setXml(ctx,"");
}
@Override
public void exitPair(JSONParser.PairContext ctx) {
String tag = stripQuotes(ctx.STRING().getText());
String value = String.format("<%s>%s<%s>\n",tag,getXml(ctx.value()),tag);
setXml(ctx,value);
}
@Override
public void exitArrayOfValues(JSONParser.ArrayOfValuesContext ctx) {
StringBuilder stringBuilder = new StringBuilder();
stringBuilder.append("\n");
for (JSONParser.ValueContext valueContext : ctx.value()){
stringBuilder.append("");
stringBuilder.append(getXml(valueContext));
stringBuilder.append("");
stringBuilder.append("\n");
}
setXml(ctx,stringBuilder.toString());
}
@Override
public void exitEmptyArray(JSONParser.EmptyArrayContext ctx) {
setXml(ctx,"");
}
@Override
public void exitString(JSONParser.StringContext ctx) {
setXml(ctx, stripQuotes(ctx.getText()));
}
@Override
public void exitAtom(JSONParser.AtomContext ctx) {
setXml(ctx, ctx.getText());
}
@Override
public void exitObjectValue(JSONParser.ObjectValueContext ctx) {
// 类比 String value() { return object(); }
setXml(ctx,getXml(ctx.object()));
}
@Override
public void exitArrayValue(JSONParser.ArrayValueContext ctx) {
setXml(ctx,getXml(ctx.array()));
}
}
编写main方法调用测试
import json.JSONLexer;
import json.JSONParser;
import json.JSONToXMLListener;
import org.antlr.v4.runtime.ANTLRInputStream;
import org.antlr.v4.runtime.CommonTokenStream;
import org.antlr.v4.runtime.tree.ParseTree;
import org.antlr.v4.runtime.tree.ParseTreeWalker;
import java.io.BufferedReader;
import java.io.FileReader;
public class JSONMain {
public static void main(String[] args) throws Exception{
BufferedReader reader = new BufferedReader(new FileReader("xxx\\json.txt"));
ANTLRInputStream inputStream = new ANTLRInputStream(reader);
JSONLexer lexer = new JSONLexer(inputStream);
CommonTokenStream tokenStream = new CommonTokenStream(lexer);
JSONParser parser = new JSONParser(tokenStream);
ParseTree parseTree = parser.json();
System.out.println(parseTree.toStringTree());
ParseTreeWalker walker = new ParseTreeWalker();
JSONToXMLListener listener = new JSONToXMLListener();
walker.walk(listener, parseTree);
String xml = listener.getXml(parseTree);
System.out.println(xml);
}
}
json.txt内容如下:
{
"id" : 1,
"name" : "Li",
"scores" : {
"Chinese" : "95",
"English" : "85"
},
"array" : [1.2, 2.0e1, -3]
}运行结果如下:

后记
本章我们学习了如何通过阅读参考手册、采用自顶向下设计来编写JSON语法文件。还学习了使用监听器来实现从JSON到XML的翻译器。可以看到,我们翻译的过程并不是一蹴而就的,而是采用分而治之的思想,是从最简单的开始翻译,然后将局部结果合并的。