在c++程序中调用caffe训练完毕的模型进行分类
此篇博客是一个插播的博客!!!
笔者察觉到,在使用caffe训练完毕模型后,如何在程序中调用模型是很多朋友关注的问题,因此,笔者打算通过两篇博客向大家说明如何在程序中使用c++调用caffe训练好的模型,下面开始正文。
在各位朋友从github下载caffe源码时,在源码中有一个example文件夹,在example文件夹中有一个cpp_classification的文件夹,打开它,有一个名为classification的cpp文件,这就是caffe提供给我们的调用分类网络进行前向计算,得到分类结果的接口,那么,让我们先来解析一下这个classification.cpp文件,按照惯例,先将源码及注释放出:
#include
#ifdef USE_OPENCV
#include
#include
#include
#endif // USE_OPENCV
#include
#include
#include
#include
#include
#include
#ifdef USE_OPENCV
using namespace caffe; // NOLINT(build/namespaces)
using std::string;
/* Pair (label, confidence) representing a prediction. */
typedef std::pair Prediction;//记录每一个类的名称以及概率
//Classifier为构造函数,主要进行模型初始化,读入训练完毕的模型参数,均值文件和标签文件
class Classifier {
public:
Classifier(const string& model_file,//model_file为测试模型时记录网络结构的prototxt文件路径
const string& trained_file,//trained_file为训练完毕的caffemodel文件路径
const string& mean_file,//mean_file为记录数据集均值的文件路径,数据集均值的文件的格式通常为binaryproto
const string& label_file);//label_file为记录类别标签的文件路径,标签通常记录在一个txt文件中,一行一个
std::vector Classify(const cv::Mat& img, int N = 5);//Classify函数去进行网络前传,得到img属于各个类的概率
private:
void SetMean(const string& mean_file);//SetMean函数主要进行均值设定,每张检测图输入后会进行减去均值的操作,这个均值可以是模型使用的数据集图像的均值
std::vector Predict(const cv::Mat& img);//Predict函数是Classify函数的主要组成部分,将img送入网络进行前向传播,得到最后的类别
void WrapInputLayer(std::vector* input_channels);//WrapInputLayer函数将img各通道(input_channels)放入网络的输入blob中
void Preprocess(const cv::Mat& img,
std::vector* input_channels);//Preprocess函数将输入图像img按通道分开(input_channels)
private:
shared_ptr > net_;//net_表示caffe中的网络
cv::Size input_geometry_;//input_geometry_表示了输入图像的高宽,同时也是网络数据层中单通道图像的高宽
int num_channels_;//num_channels_表示了输入图像的通道数
cv::Mat mean_;//mean_表示了数据集的均值,格式为Mat
std::vector labels_;//字符串向量labels_表示了各个标签
};
//构造函数Classifier进行了各种各样的初始化工作,并对网络的安全进行了检验
Classifier::Classifier(const string& model_file,
const string& trained_file,
const string& mean_file,
const string& label_file) {
#ifdef CPU_ONLY
Caffe::set_mode(Caffe::CPU);//如果caffe是只在cpu上运行的,将运行模式设置为CPU
#else
Caffe::set_mode(Caffe::GPU);//一般我们都是用的GPU模式
#endif
/* Load the network. */
net_.reset(new Net(model_file, TEST));//从model_file路径下的prototxt初始化网络结构
net_->CopyTrainedLayersFrom(trained_file);//从trained_file路径下的caffemodel文件读入训练完毕的网络参数
CHECK_EQ(net_->num_inputs(), 1) << "Network should have exactly one input.";//核验是不是只输入了一张图像,输入的blob结构为(N,C,H,W),在这里,N只能为1
CHECK_EQ(net_->num_outputs(), 1) << "Network should have exactly one output.";//核验输出的blob结构,输出的blob结构同样为(N,C,W,H),在这里,N同样只能为1
Blob* input_layer = net_->input_blobs()[0];//获取网络输入的blob,表示网络的数据层
num_channels_ = input_layer->channels();//获取输入的通道数
CHECK(num_channels_ == 3 || num_channels_ == 1)//核验输入图像的通道数是否为3或者1,网络只接收3通道或1通道的图片
<< "Input layer should have 1 or 3 channels.";
input_geometry_ = cv::Size(input_layer->width(), input_layer->height());//获取输入图像的尺寸(宽与高)
/* Load the binaryproto mean file. */
SetMean(mean_file);//进行均值的设置
/* Load labels. */
std::ifstream labels(label_file.c_str());//从标签文件路径读入定义的标签文件
CHECK(labels) << "Unable to open labels file " << label_file;
string line;//line获取标签文件中的每一行(每一个标签)
while (std::getline(labels, line))
labels_.push_back(string(line));//将所有的标签放入labels_
/*output_layer指向网络最后的输出,举个例子,最后的分类器采用softmax分类,且类别有10类,那么,输出的blob就会有10个通道,每个通道的长
宽都为1(因为是10个数,这10个数表征输入属于10类中每一类的概率,这10个数之和应该为1),输出blob的结构为(1,10,1,1)*/
Blob* output_layer = net_->output_blobs()[0];
CHECK_EQ(labels_.size(), output_layer->channels())//在这里核验最后网络输出的通道数是否等于定义的标签的通道数
<< "Number of labels is different from the output layer dimension.";
}
static bool PairCompare(const std::pair& lhs,
const std::pair& rhs) {
return lhs.first > rhs.first;
}//PairCompare函数比较分类得到的物体属于某两个类别的概率的大小,若属于lhs的概率大于属于rhs的概率,返回真,否则返回假
/* Return the indices of the top N values of vector v. */
/*Argmax函数返回前N个得分概率的类标*/
static std::vector Argmax(const std::vector& v, int N) {
std::vector > pairs;
for (size_t i = 0; i < v.size(); ++i)
pairs.push_back(std::make_pair(v[i], i));//按照分类结果存储输入属于每一个类的概率以及类标
std::partial_sort(pairs.begin(), pairs.begin() + N, pairs.end(), PairCompare);/*partial_sort函数按照概率大
小筛选出pairs中概率最大的N个组合,并将它们按照概率从大到小放在pairs的前N个位置*/
std::vector result;
for (int i = 0; i < N; ++i)
result.push_back(pairs[i].second);//将前N个较大的概率对应的类标放在result中
return result;
}
/* Return the top N predictions. */
std::vector Classifier::Classify(const cv::Mat& img, int N) {
std::vector output = Predict(img);//进行网络的前向传输,得到输入属于每一类的概率,存储在output中
N = std::min(labels_.size(), N);//找到想要得到的概率较大的前N类,这个N应该小于等于总的类别数目
std::vector maxN = Argmax(output, N);//找到概率最大的前N类,将他们按概率由大到小将类标存储在maxN中
std::vector predictions;
for (int i = 0; i < N; ++i) {
int idx = maxN[i];
predictions.push_back(std::make_pair(labels_[idx], output[idx]));//在labels_找到分类得到的概率最大的N类对应的实际的名称
}
return predictions;
}
/* Load the mean file in binaryproto format. */
void Classifier::SetMean(const string& mean_file) {//设置数据集的平均值
BlobProto blob_proto;
ReadProtoFromBinaryFileOrDie(mean_file.c_str(), &blob_proto);//用定义的均值文件路径将均值文件读入proto中
/* Convert from BlobProto to Blob */
Blob mean_blob;
mean_blob.FromProto(blob_proto);//将proto中存储的均值文件转移到blob中
CHECK_EQ(mean_blob.channels(), num_channels_)//核验均值的通道数是否等于输入图像的通道数,如果不相等的话则为异常
<< "Number of channels of mean file doesn't match input layer.";
/* The format of the mean file is planar 32-bit float BGR or grayscale. */
std::vector channels;//将mean_blob中的数据转化为Mat时的存储向量
float* data = mean_blob.mutable_cpu_data();//指向均值blob的指针
for (int i = 0; i < num_channels_; ++i) {
/* Extract an individual channel. */
cv::Mat channel(mean_blob.height(), mean_blob.width(), CV_32FC1, data);//存储均值文件的每一个通道转化得到的Mat
channels.push_back(channel);//将均值文件的所有通道转化成的Mat一个一个地存储到channels中
data += mean_blob.height() * mean_blob.width();//在均值文件上移动一个通道
}
/* Merge the separate channels into a single image. */
cv::Mat mean;
cv::merge(channels, mean);//将得到的所有通道合成为一张图
/* Compute the global mean pixel value and create a mean image
* filled with this value. */
cv::Scalar channel_mean = cv::mean(mean);//求得均值文件的每个通道的平均值,记录在channel_mean中
mean_ = cv::Mat(input_geometry_, mean.type(), channel_mean);//用上面求得的各个通道的平均值初始化mean_,作为数据集图像的均值
}
std::vector Classifier::Predict(const cv::Mat& img) {
Blob* input_layer = net_->input_blobs()[0];//input_layer是网络的输入blob
input_layer->Reshape(1, num_channels_,
input_geometry_.height, input_geometry_.width);//表示网络只输入一张图像,图像的通道数是num_channels_,高为input_geometry_.height,宽为input_geometry_.width
/* Forward dimension change to all layers. */
net_->Reshape();//初始化网络的各层
std::vector input_channels;//存储输入图像的各个通道
WrapInputLayer(&input_channels);//将存储输入图像的各个通道的input_channels放入网络的输入blob中
Preprocess(img, &input_channels);//将img的各通道分开并存储在input_channels中
net_->Forward();//进行网络的前向传输
/* Copy the output layer to a std::vector */
Blob* output_layer = net_->output_blobs()[0];//output_layer指向网络输出的数据,存储网络输出数据的blob的规格是(1,c,1,1)
const float* begin = output_layer->cpu_data();//begin指向输入数据对应的第一类的概率
const float* end = begin + output_layer->channels();//end指向输入数据对应的最后一类的概率
return std::vector(begin, end);//返回输入数据经过网络前向计算后输出的对应于各个类的分数
}
/* Wrap the input layer of the network in separate cv::Mat objects
* (one per channel). This way we save one memcpy operation and we
* don't need to rely on cudaMemcpy2D. The last preprocessing
* operation will write the separate channels directly to the input
* layer. */
void Classifier::WrapInputLayer(std::vector* input_channels) {
Blob* input_layer = net_->input_blobs()[0];//input_layer指向网络输入的blob
int width = input_layer->width();//得到网络指定的输入图像的宽
int height = input_layer->height();//得到网络指定的输入图像的高
float* input_data = input_layer->mutable_cpu_data();//input_data指向网络的输入blob
for (int i = 0; i < input_layer->channels(); ++i) {
cv::Mat channel(height, width, CV_32FC1, input_data);//将网络输入blob的数据同Mat关联起来
input_channels->push_back(channel);//将上面的Mat同input_channels关联起来
input_data += width * height;//一个一个通道地操作
}
}
void Classifier::Preprocess(const cv::Mat& img,
std::vector* input_channels) {
/* Convert the input image to the input image format of the network. */
cv::Mat sample;
if (img.channels() == 3 && num_channels_ == 1)
cv::cvtColor(img, sample, cv::COLOR_BGR2GRAY);
else if (img.channels() == 4 && num_channels_ == 1)
cv::cvtColor(img, sample, cv::COLOR_BGRA2GRAY);
else if (img.channels() == 4 && num_channels_ == 3)
cv::cvtColor(img, sample, cv::COLOR_BGRA2BGR);
else if (img.channels() == 1 && num_channels_ == 3)
cv::cvtColor(img, sample, cv::COLOR_GRAY2BGR);
else
sample = img;//if-else嵌套表示了要将输入的img转化为num_channels_通道的
cv::Mat sample_resized;
if (sample.size() != input_geometry_)
cv::resize(sample, sample_resized, input_geometry_);//将输入图像的尺寸强制转化为网络规定的输入尺寸
else
sample_resized = sample;
cv::Mat sample_float;
if (num_channels_ == 3)
sample_resized.convertTo(sample_float, CV_32FC3);
else
sample_resized.convertTo(sample_float, CV_32FC1);//将输入图像转化成为网络前传合法的数据规格
cv::Mat sample_normalized;
cv::subtract(sample_float, mean_, sample_normalized);//将图像减去均值
/* This operation will write the separate BGR planes directly to the
* input layer of the network because it is wrapped by the cv::Mat
* objects in input_channels. */
cv::split(sample_normalized, *input_channels);/*将减去均值的图像分散在input_channels中,由于在WrapInputLayer函数中,
input_channels已经和网络的输入blob关联起来了,因此在这里实际上是把图像送入了网络的输入blob*/
CHECK(reinterpret_cast(input_channels->at(0).data)
== net_->input_blobs()[0]->cpu_data())
<< "Input channels are not wrapping the input layer of the network.";//核验图像是否被送入了网络作为输入
}
int main(int argc, char** argv) {//主函数
if (argc != 6) {/*核验命令行参数是否为6,这6个参数分别为classification编译生成的可执行文件,测试模型时记录网络结构的prototxt文件路径,
训练完毕的caffemodel文件路径,记录数据集均值的文件路径,记录类别标签的文件路径,需要送入网络进行分类的图片文件路径*/
std::cerr << "Usage: " << argv[0]
<< " deploy.prototxt network.caffemodel"
<< " mean.binaryproto labels.txt img.jpg" << std::endl;
return 1;
}
::google::InitGoogleLogging(argv[0]);//InitGoogleLogging做了一些初始化glog的工作
//取四个参数
string model_file = argv[1];
string trained_file = argv[2];
string mean_file = argv[3];
string label_file = argv[4];
Classifier classifier(model_file, trained_file, mean_file, label_file);//进行检测网络的初始化
string file = argv[5];//取得需要进行检测的图片的路径
std::cout << "---------- Prediction for "
<< file << " ----------" << std::endl;
cv::Mat img = cv::imread(file, -1);//读入图片
CHECK(!img.empty()) << "Unable to decode image " << file;
std::vector predictions = classifier.Classify(img);//进行网络的前向计算,并且取到概率最大的前N类对应的类别名称
/* Print the top N predictions. */
for (size_t i = 0; i < predictions.size(); ++i) {//打印出概率最大的前N类并给出概率
Prediction p = predictions[i];
std::cout << std::fixed << std::setprecision(4) << p.second << " - \""
<< p.first << "\"" << std::endl;
}
}
#else
int main(int argc, char** argv) {
LOG(FATAL) << "This example requires OpenCV; compile with USE_OPENCV.";
}
#endif // USE_OPENCV
以上是classification.cpp的源码,在这个文件中,有一个类Classifier,而在这个Classifier主要由两个部分组成,首先第一个部分是这个类的构造函数Classifier:
Classifier::Classifier(const string& model_file,
const string& trained_file,
const string& mean_file,
const string& label_file)设置caffe的工作模式(CPU/GPU)->读取网络结构->读取训练得到的网络参数->获取网络规定的单张输入图片的尺寸(宽与高)->读取数据集的均值文件->读取定义的所有类别标签(类别名称)
值得一提的是,在构造函数中读取数据集的均值文件时候,使用了一个SetMean函数,该函数的主要作用是将均值文件(通常是binaryproto格式)读到proto中,再由FromProto函数将proto中的均值文件读取到blob中。
在构造函数中,还进行了其他的一些核验的工作,比如检验是不是只输入了一张图像(进行模型调用时只输入单张图像),检验模型输出结果的blob中的n是否为1,检验输入图像的通道数是否为3或者1,检验网络最后输出的通道数是否等于标签文档中定义的标签的数目。同时,在SetMean函数中,检验了均值blob的通道数是否等于输入图像的通道数(加入输入图像是三通道的,那么R,G,B通道对应各自的均值)。
除了构造函数,第二部分是进行网络前传得到分类结果的Classify函数:
std::vector Classify(const cv::Mat& img, int N = 5) Classify函数接受单张图片,并得到概率最大的前N类结果,在这里N默认为5,Classify函数的核心为Predict函数:
std::vector Predict(const cv::Mat& img) 进行网络输入blob的初始化->进行网络中各层的初始化->将输入图像的各个通道放入网络的输入blob中->进行网络的前向传播->获取输入图片属于每一个类别的概率
其中,上述各步骤中的第三步非常巧妙,caffe是在WrapInputLayer函数中首先将网络的输入blob同一个vector
下面让我们来测试一下这个classification.cpp。
笔者用alexnet训练了一个检验图片中是否包含岔路口的网络,输出包含两类:第一类为nonfork,表示图中没有岔路口;第二类为fork,表示图中有岔路口。
文件夹中包含这些文件:
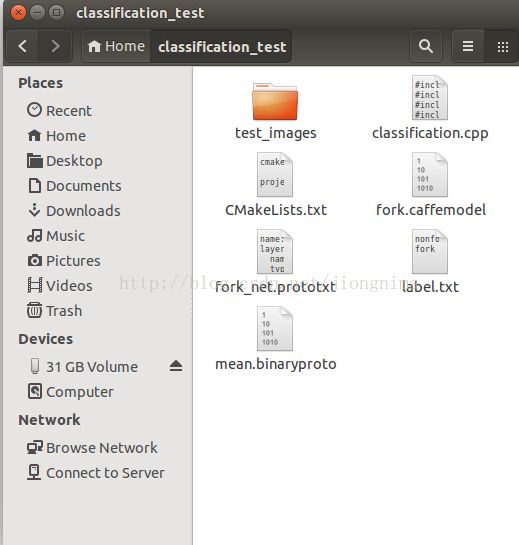
其中,test_images是一些测试文件,fork.caffemodel是训练完毕的网络参数,fork_net.prototxt是网络结构,label.txt是记录类别标签的标签文件,mean.binaryproto是数据集的均值文件。
其中,fork_net.prototxt内容如下:
name: "AlexNet"
layer {
name: "forkdata"
type: "Input"
top: "data"
input_param { shape: { dim: 1 dim: 3 dim: 227 dim: 227 } }
}
layer {
name: "conv1"
type: "Convolution"
bottom: "data"
top: "conv1"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 96
kernel_size: 11
stride: 4
}
}
layer {
name: "relu1"
type: "ReLU"
bottom: "conv1"
top: "conv1"
}
layer {
name: "norm1"
type: "LRN"
bottom: "conv1"
top: "norm1"
lrn_param {
local_size: 5
alpha: 0.0001
beta: 0.75
}
}
layer {
name: "pool1"
type: "Pooling"
bottom: "norm1"
top: "pool1"
pooling_param {
pool: MAX
kernel_size: 3
stride: 2
}
}
layer {
name: "conv2"
type: "Convolution"
bottom: "pool1"
top: "conv2"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 256
pad: 2
kernel_size: 5
group: 2
}
}
layer {
name: "relu2"
type: "ReLU"
bottom: "conv2"
top: "conv2"
}
layer {
name: "norm2"
type: "LRN"
bottom: "conv2"
top: "norm2"
lrn_param {
local_size: 5
alpha: 0.0001
beta: 0.75
}
}
layer {
name: "pool2"
type: "Pooling"
bottom: "norm2"
top: "pool2"
pooling_param {
pool: MAX
kernel_size: 3
stride: 2
}
}
layer {
name: "conv3"
type: "Convolution"
bottom: "pool2"
top: "conv3"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 384
pad: 1
kernel_size: 3
}
}
layer {
name: "relu3"
type: "ReLU"
bottom: "conv3"
top: "conv3"
}
layer {
name: "conv4"
type: "Convolution"
bottom: "conv3"
top: "conv4"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 384
pad: 1
kernel_size: 3
group: 2
}
}
layer {
name: "relu4"
type: "ReLU"
bottom: "conv4"
top: "conv4"
}
layer {
name: "conv5"
type: "Convolution"
bottom: "conv4"
top: "conv5"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 256
pad: 1
kernel_size: 3
group: 2
}
}
layer {
name: "relu5"
type: "ReLU"
bottom: "conv5"
top: "conv5"
}
layer {
name: "pool5"
type: "Pooling"
bottom: "conv5"
top: "pool5"
pooling_param {
pool: MAX
kernel_size: 3
stride: 2
}
}
layer {
name: "fc6"
type: "InnerProduct"
bottom: "pool5"
top: "fc6"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 4096
}
}
layer {
name: "relu6"
type: "ReLU"
bottom: "fc6"
top: "fc6"
}
layer {
name: "drop6"
type: "Dropout"
bottom: "fc6"
top: "fc6"
dropout_param {
dropout_ratio: 0.5
}
}
layer {
name: "fc7"
type: "InnerProduct"
bottom: "fc6"
top: "fc7"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 4096
}
}
layer {
name: "relu7"
type: "ReLU"
bottom: "fc7"
top: "fc7"
}
layer {
name: "drop7"
type: "Dropout"
bottom: "fc7"
top: "fc7"
dropout_param {
dropout_ratio: 0.5
}
}
layer {
name: "forkfc8"
type: "InnerProduct"
bottom: "fc7"
top: "fc8"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 2
}
}
layer {
name: "prob"
type: "Softmax"
bottom: "fc8"
top: "prob"
}
然后,我们的classification.cpp中内容如下,笔者将核验USE_OPENCV的部分去掉了,并改了一下main函数,不必在控制台中再输入路径,同时加入了测试构造函数Classifier和网络前传函数Classify运行时间的代码,笔者的classification.cpp代码如下:
#include
#include
#include
#include
#include
#include
#include
#include
#include
#include
using namespace caffe; // NOLINT(build/namespaces)
using std::string;
/* Pair (label, confidence) representing a prediction. */
typedef std::pair Prediction;
class Classifier {
public:
Classifier(const string& model_file,
const string& trained_file,
const string& mean_file,
const string& label_file);
std::vector Classify(const cv::Mat& img, int N = 5);
private:
void SetMean(const string& mean_file);
std::vector Predict(const cv::Mat& img);
void WrapInputLayer(std::vector* input_channels);
void Preprocess(const cv::Mat& img,
std::vector* input_channels);
private:
shared_ptr > net_;
cv::Size input_geometry_;
int num_channels_;
cv::Mat mean_;
std::vector labels_;
};
Classifier::Classifier(const string& model_file,
const string& trained_file,
const string& mean_file,
const string& label_file) {
#ifdef CPU_ONLY
Caffe::set_mode(Caffe::CPU);
#else
Caffe::set_mode(Caffe::GPU);
#endif
/* Load the network. */
net_.reset(new Net(model_file, TEST));
net_->CopyTrainedLayersFrom(trained_file);
CHECK_EQ(net_->num_inputs(), 1) << "Network should have exactly one input.";
CHECK_EQ(net_->num_outputs(), 1) << "Network should have exactly one output.";
Blob* input_layer = net_->input_blobs()[0];
num_channels_ = input_layer->channels();
CHECK(num_channels_ == 3 || num_channels_ == 1)
<< "Input layer should have 1 or 3 channels.";
input_geometry_ = cv::Size(input_layer->width(), input_layer->height());
/* Load the binaryproto mean file. */
SetMean(mean_file);
/* Load labels. */
std::ifstream labels(label_file.c_str());
CHECK(labels) << "Unable to open labels file " << label_file;
string line;
while (std::getline(labels, line))
labels_.push_back(string(line));
Blob* output_layer = net_->output_blobs()[0];
CHECK_EQ(labels_.size(), output_layer->channels())
<< "Number of labels is different from the output layer dimension.";
}
static bool PairCompare(const std::pair& lhs,
const std::pair& rhs) {
return lhs.first > rhs.first;
}
/* Return the indices of the top N values of vector v. */
static std::vector Argmax(const std::vector& v, int N) {
std::vector > pairs;
for (size_t i = 0; i < v.size(); ++i)
pairs.push_back(std::make_pair(v[i], i));
std::partial_sort(pairs.begin(), pairs.begin() + N, pairs.end(), PairCompare);
std::vector result;
for (int i = 0; i < N; ++i)
result.push_back(pairs[i].second);
return result;
}
/* Return the top N predictions. */
std::vector Classifier::Classify(const cv::Mat& img, int N) {
std::vector output = Predict(img);
N = std::min(labels_.size(), N);
std::vector maxN = Argmax(output, N);
std::vector predictions;
for (int i = 0; i < N; ++i) {
int idx = maxN[i];
predictions.push_back(std::make_pair(labels_[idx], output[idx]));
}
return predictions;
}
/* Load the mean file in binaryproto format. */
void Classifier::SetMean(const string& mean_file) {
BlobProto blob_proto;
ReadProtoFromBinaryFileOrDie(mean_file.c_str(), &blob_proto);
/* Convert from BlobProto to Blob */
Blob mean_blob;
mean_blob.FromProto(blob_proto);
CHECK_EQ(mean_blob.channels(), num_channels_)
<< "Number of channels of mean file doesn't match input layer.";
/* The format of the mean file is planar 32-bit float BGR or grayscale. */
std::vector channels;
float* data = mean_blob.mutable_cpu_data();
for (int i = 0; i < num_channels_; ++i) {
/* Extract an individual channel. */
cv::Mat channel(mean_blob.height(), mean_blob.width(), CV_32FC1, data);
channels.push_back(channel);
data += mean_blob.height() * mean_blob.width();
}
/* Merge the separate channels into a single image. */
cv::Mat mean;
cv::merge(channels, mean);
/* Compute the global mean pixel value and create a mean image
* filled with this value. */
cv::Scalar channel_mean = cv::mean(mean);
mean_ = cv::Mat(input_geometry_, mean.type(), channel_mean);
}
std::vector Classifier::Predict(const cv::Mat& img) {
Blob* input_layer = net_->input_blobs()[0];
input_layer->Reshape(1, num_channels_,
input_geometry_.height, input_geometry_.width);
/* Forward dimension change to all layers. */
net_->Reshape();
std::vector input_channels;
WrapInputLayer(&input_channels);
Preprocess(img, &input_channels);
net_->Forward();
/* Copy the output layer to a std::vector */
Blob* output_layer = net_->output_blobs()[0];
const float* begin = output_layer->cpu_data();
const float* end = begin + output_layer->channels();
return std::vector(begin, end);
}
/* Wrap the input layer of the network in separate cv::Mat objects
* (one per channel). This way we save one memcpy operation and we
* don't need to rely on cudaMemcpy2D. The last preprocessing
* operation will write the separate channels directly to the input
* layer. */
void Classifier::WrapInputLayer(std::vector* input_channels) {
Blob* input_layer = net_->input_blobs()[0];
int width = input_layer->width();
int height = input_layer->height();
float* input_data = input_layer->mutable_cpu_data();
for (int i = 0; i < input_layer->channels(); ++i) {
cv::Mat channel(height, width, CV_32FC1, input_data);
input_channels->push_back(channel);
input_data += width * height;
}
}
void Classifier::Preprocess(const cv::Mat& img,
std::vector* input_channels) {
/* Convert the input image to the input image format of the network. */
cv::Mat sample;
if (img.channels() == 3 && num_channels_ == 1)
cv::cvtColor(img, sample, cv::COLOR_BGR2GRAY);
else if (img.channels() == 4 && num_channels_ == 1)
cv::cvtColor(img, sample, cv::COLOR_BGRA2GRAY);
else if (img.channels() == 4 && num_channels_ == 3)
cv::cvtColor(img, sample, cv::COLOR_BGRA2BGR);
else if (img.channels() == 1 && num_channels_ == 3)
cv::cvtColor(img, sample, cv::COLOR_GRAY2BGR);
else
sample = img;
cv::Mat sample_resized;
if (sample.size() != input_geometry_)
cv::resize(sample, sample_resized, input_geometry_);
else
sample_resized = sample;
cv::Mat sample_float;
if (num_channels_ == 3)
sample_resized.convertTo(sample_float, CV_32FC3);
else
sample_resized.convertTo(sample_float, CV_32FC1);
cv::Mat sample_normalized;
cv::subtract(sample_float, mean_, sample_normalized);
/* This operation will write the separate BGR planes directly to the
* input layer of the network because it is wrapped by the cv::Mat
* objects in input_channels. */
cv::split(sample_normalized, *input_channels);
CHECK(reinterpret_cast(input_channels->at(0).data)
== net_->input_blobs()[0]->cpu_data())
<< "Input channels are not wrapping the input layer of the network.";
}
int main(int argc, char** argv) {
clock_t start_time1,end_time1,start_time2,end_time2;
::google::InitGoogleLogging(argv[0]);
string model_file = "/home/ubuntu/classification_test/fork_net.prototxt";
string trained_file = "/home/ubuntu/classification_test/fork.caffemodel";
string mean_file = "/home/ubuntu/classification_test/mean.binaryproto";
string label_file = "/home/ubuntu/classification_test/label.txt";
start_time1 = clock();
Classifier classifier(model_file, trained_file, mean_file, label_file);
end_time1 = clock();
double seconds1 = (double)(end_time1-start_time1)/CLOCKS_PER_SEC;
std::cout<<"init time="< predictions = classifier.Classify(img);
end_time2 = clock();
double seconds2 = (double)(end_time2-start_time2)/CLOCKS_PER_SEC;
std::cout<<"classify time="< cmake_minimum_required (VERSION 2.8)
project (classification_test)
add_executable(classification_test classification.cpp)
include_directories ( /home/ubuntu/caffe/include
/usr/local/include
/usr/local/cuda/include
/usr/include )
target_link_libraries(classification_test
/home/ubuntu/caffe/build/lib/libcaffe.so
/usr/lib/arm-linux-gnueabihf/libopencv_highgui.so
/usr/lib/arm-linux-gnueabihf/libopencv_core.so
/usr/lib/arm-linux-gnueabihf/libopencv_imgproc.so
/usr/lib/arm-linux-gnueabihf/libglog.so
/usr/lib/arm-linux-gnueabihf/libboost_system.so
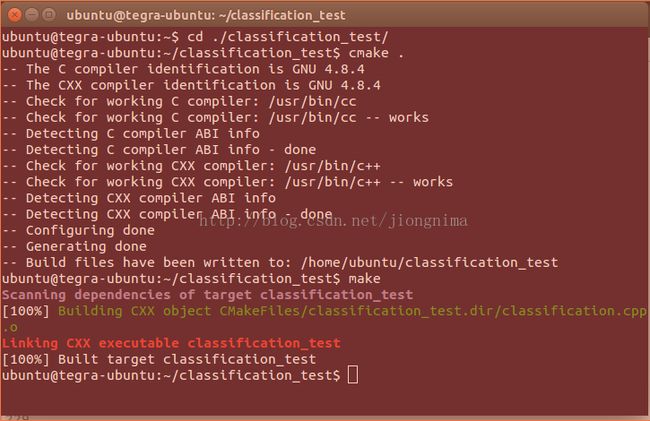
)那么,下面在相应的文件夹下执行:
cmake .
make
两条语句,编译成功,并生成可执行文件classification_test。
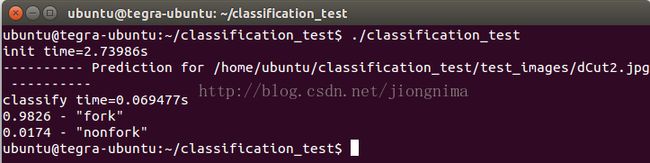
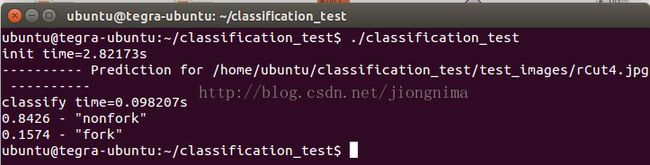
然后我们检测一张岔路口图片:

得到结果:
更改classification.cpp文件中的检测图片,再检测一张不包含岔路口的路面图片:

得到结果为:
实验成功!
不过从实验可以看出,初始化检测对象还是相当耗时的,并且,在实际工程中,检测程序往往做成一个独立的.so文件。并且作者先前提到,官方提供的classification.cpp中有大量的核验操作与判断分支,在工程中实际使用也不必要。因此,下一篇博客中,笔者将讲解一下怎么魔改简化classification.cpp,将其编译为工程使用的.so库并调用。
请对caffe分类检测接口工程化感兴趣的读者朋友们移步笔者的下一篇博客点击打开链接,各位朋友的支持与鼓励是我最大的动力!
written by jiong
开始时捱一些苦 栽种绝处的花