Hadoop、Slurm平台详细安装配置步骤
大数据Hadoop、Slurm平台
安 装 配 置 手 册
河北科技大学理学院
王子元
2018年6月
绪论
本人本科毕业设计选的是《数学系大数据环境建设》课题,实验集群采用四台惠普工作站做为节点服务器,采用一台虚拟机和3台真机作为实验环境,下文的整个配置记录全部真实有效,虽说这只是我的本科毕业设计的附件,但没有半点水分。系统完全按照刀片式服务器集群来部署,更加真实的模拟了华为刀片服务器集群的运行环境。另外有两个主要的创新之处:一、配置了时间服务器,使集群对时精准到0.05秒,精确度远远高于集群要求的时间误差3秒。二、制作了一个基于Python的自动化脚本,将绝大多数的集群操作命令集合在其中,实现半自动化集群管理操作,极大地降低的普通用户对集群操作学习的成本。 感谢周长杰老师的提供的参考依据,感谢李国刚老师、阎晨光老师的对硬件设备的支持,为我实验的顺利进行保驾护航,感谢白晓刚学长对我Slurm过程的帮助。我的本科毕业设计,虽然最后仅以4分之差没有拿到优秀,但是在公开答辩时,我得到了答辩组所有老师的认可,能够做到这样我也算满足了,这三个月的努力没白费。本人作为数学系信息与计算科学专业的学生,我感觉目前自己对整个计算机生态的理解并不比计算机系的差,而我个人认为未来的计算机发展方向是人工智能、机器学习,所以我又选择的了攻读数学系的研究生,我相信未来会在数学和计算机这个交叉方向取得一些成绩。
目录
hadoop web管理地址... 3
Linux篇... 3
HDFS篇... 7
MapReduce篇... 14
zookeeper篇... 24
Hbase篇... 25
Hive篇... 36
Slurm篇... 41
NTP时间服务器篇... 43
Python脚本篇... 45
hadoop web管理地址
1 HDFS的Web管地址
http://192.168.1.201:50070/
2 MapReduce的Web管理地址
http://192.168.1.201:8088/
3 HBase的Web管理地址
http://192.168.1.201:16010/
4 Hive的Web管理地址
http://192.168.1.201:9999/hwi/
Linux篇
一 常用命令
which java which查看文件所在位置
which javac
rm -rf /usr/bin/java rm-rf 强制删除
rm -rf /usr/bin/javac
ln -s $JAVA_HOME/bin/javac /usr/bin/java 链接位置
ln -s $JAVA_HOME/bin/javac /usr/bin/javac
netstat -an | grep 10000
ps -aux | grep 'metastore'
ifconfig 查看ip
hostname
service iptables stop
chkconfig iptables off
service network restart 重启网卡
source /etc/profile
vi
scp
cd
ll
ls
reboot
poweroff
二 操作系统安装配置
1 规划IP地址:
Router 192.168.1.1
Linux
master 192.168.1.200
slave01 192.168.1.201
slave02 192.168.1.202
slave03 192.168.1.203
2.制作U盘启动盘
2.1通过软碟通制作好U盘启动工具
准备 U盘(8G)、rhel-server-7.0-x86_64-dvd.iso、UltraISO软碟通软件
2.2 在电脑上安装上UltraISO软碟通软件
2.3 将准备好的U盘插入电脑,双击UltraISo图标,选择继续试用
2.4 选择文件--打开
2.5 启动--写入映像..
2.6 选择自己U盘,点击 写入 (在写入之前,系统先格式化U盘,请提前做好备份),等待一段时间(等待时间由电脑配置决定)
2.linux 7.0 安装步骤
2.1选择界面第一个(Install Red Hat Enterprise Linux 7.0)开始安装
2.2 选择中文和简体中文(中国),点击继续
2.3.1 选择软件选择,选择左侧带GUI的服务器。右侧为系统自带的的环境附加选项,若有需要,可以自行选择。之后,点击完成
2.3.2点击安装位置,选择硬盘,点击完成。然后会弹出对话框,点击回收空间——全部删除——回收空间
2.3.3点击网络和主机名,输入主机名(如master,slave01,slave02,slave03)点击完成;第二步,
配置网络
选择自动连接、允许所有用户使用
选择IPV4设置
方法选择手动
添加网卡并配置:地址192.168.1.xxx 掩码255.255.255.0 网关192.168.1.1
DNS 192.168.1.1,114.114.114.114
应用
3.3点击网络和主机名,输入主机名(如master,slave01,slave02,slave03)点击完成。
3.4点击开始安装,选择root密码,输入hadoop
3.5安装完成后重启,选择为许可信息,同意许可协议,完成,点击完成配置
3.6点击前进
3.7输入hadoop密码,进入界面化linux系统,等待弹出对话框,点击前进——前进——点击 Start using Red Hat Enterprise Linux Server 此时安装完成。
4 配置终端快捷方式
选择应用程序—系统工具—设置—键盘—快捷键—自定义快捷键,点击“+”号,名字:terminal
命令:gonme-terminal ,应用。点击terminal,按ctrl+t,关掉窗口。自己键盘输入:ctrl+t,弹出命令窗口,设置完成
6 配置Red Hat 7.0防火墙(需要切换到root帐户)
查看防火墙状态 systemctl status firewalld
关闭防火墙 systemctl stop firewalld
永久关闭防火墙 systemctl disable firewalld
7 检查网络互通是否正常
ping 192.168.1.1
ping 192.168.1.20x
8 查看Red Hat系列的系统版本
cat /etc/redhat-release
9 配置Red Hat hosts (需要切换到root帐户)
vim /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.1.200 master
192.168.1.201 slave01
192.168.1.202 slave02
192.168.1.203 slave03
用ping命令检查主机名通讯是否正常(e.g. ping master)
三 配置 ssh 互信
1 生成密钥 ·····
ssh1-keygen
一路回车
2 把公钥发给所有机器
ssh-copy-id master
ssh-copy-id slave01
…
中间要输入yes和密码hadoop
3 用ssh命令检查是否互信成功
ssh master
ssh slave01
…
不要求输入密码则成功
4 备注:
生成的密钥在/home/hadoop/.ssh中,其中.ssh是隐藏的
authorized_keys为已经互信的机器公钥信息
四 安装xShell、xFtp
1 在windows下安装,选择免费版本
在session管理窗口中,建立一个与linux主机同名的链接名,并配置主机IP
连接,输入用户名并保存,输入密码并保存,生成验证信息并保存
此时已经连接到Linux主机,可以用命令行操作我们安装好的CentOS了
2 安装 xFtp
在windows下安装,选择免费版本
不需要启动,我们使用时在xShell中用右数第八个图标启动,不需要用户名密码
五 安装配置 Redhat JDK
1在hadoop用户的根目录(/home/hadooop)创建文件夹app
2 从xShell启动xFtp
3 从windows本地上传jdk-8u121-linux-x64.tar.gz到app下
4 解压jdk-8u65-linux-x64.tar.g到app下
cd app
tar –zxvf jdk-8u65-linux-x64.tar.gz
cd ~
5配置环境变量(需要切换到root帐户)
5.1 gedit /etc/profile
5.2在最后增加两行
JAVA_HOME=/home/hadoop/app/jdk1.8.0_121
export PATH=$PATH:$JAVA_HOME/bin
6 把修改的环境变量生效
source /etc/profile
7 检测并配置jdk
7.1 检测jdk版本,应该为java version "1.8.0_121",javac 1.8.0_121
java –version
javac –version
7.2 检查jdk位置,应该为~/app/jdk1.8.0_121/bin/java,~/app/jdk1.8.0_121/bin/javac
which java
which javac
7.3 如果不正确,则删除原有的java/javac,链接新的
rm -rf /usr/bin/java
rm -rf /usr/bin/javac
ln –s $JAVA_HOME/bin/java /usr/bin/java
ln –s $JAVA_HOME/bin/javac /usr/bin/javac
六 Eclipse安装配置
1 在windows下解压eclipse-jee-mars-2-win32-x86_64.zip
2 配置workspace
七 常用配置文件位置
1 主机名
/etc/sysconfig/network
2 主机IP配置信息
/etc/sysconfig/network-scripts/ifcfg-eth0
3 环境变量配置信息
/etc/profile
4 静态路由配置信息
/etc/hosts
HDFS篇
一 安装配置
1.1 从xShell启动xFtp
1.2 从windows本地上传hadoop-2.6.0.tar.gz到app下
1.3 解压hadoop-2.6.0.tar.gz到app下
cd app
tar –zxvf hadoop-2.6.0.tar.gz
cd ~
1.4修改配置文件app/hadoop-2.6.0/etc/hadoop/hadoop-env.sh,
找到
export JAVA_HOME=${JAVA_HOME}
替换为
export JAVA_HOME=/home/hadoop/app/jdk1.8.0_121
1.5修改配置文件app/hadoop-2.6.0/etc/hadoop/core-site.xml
1.6修改配置文件hadoop-2.6.0/etc/hadoop/hdfs-site.xml
1.7 修改修改配置文件hadoop-2.6.0/etc/hadoop/mapred-site.xml
1.7.1复制mapred-site.xml.template,更名为mapred-site.xml
1.7.2 配置
1.8修改配置文件hadoop-2.6.0/etc/hadoop/yarn-site.xml
1.9修改配置文件hadoop-2.6.0/etc/hadoop/slaves
slave01
slave02
slave03
1.10 如果集群中其他机器没有配置,可以直接复制
scp –r app/hadoop-2.6.0 slave01:~/app/
二 HDFS 系统操作
2.1 格式化
~/app/hadoop-2.6.0/bin/hdfs namenode –format
注意:格式化只能操作一次并且在主节点格式化,如果需要再次格式化,需要把appdata/hadoop目录清空或者直接删除所有节点的appdata文件
2.2 启动
~/app/hadoop-2.6.0/sbin/start-all.sh
2.3 查看是否启动正确
2.3.1 查看日至输出
2.3.2 查看进程jps
2.3.2.1 master节点
NameNode
SecondaryNameNode
ResourceManager
2.3.2.2 datanode节点
DataNode
NodeManager
2.4 停止
app/hadoop-2.6.0/sbin/stop-all.sh
2.5 复制
scp –r ~/app/hadoop-2.6.0 slave01:~/app/
三 HDFS Shell操作
3.1创建目录
3.1.1创建单级目录
bin/hadoop dfs -mkdir /abc
3.1.2 创建多级目录
bin/hadoop dfs -mkdir -p /a/b/c
3.2查看目录的内容
bin/hadoop dfs -ls /
3.3上传文件,从linux系统把文件上传到HDFS
bin/hadoop dfs -put etc/hadoop/core-site.xml /
3.4 下载文件,从HDFS把文件下载到linux系统
bin/hadoop dfs -get /core-site.xml .
3.5 查看HDFS文件内容
bin/hadoop dfs -cat /core-site.xml
3.6 删除HDFS上的文件或目录
3.6.1 删除空的目录
bin/hadoop dfs -rmdir /a/b/c
3.6.2 删除文件
bin/hadoop dfs -rm /core-site.xml
3.6.3 递归删除目录(删除非空目录)
bin/hadoop dfs -rm -r /a
3.7 安全模式
bin/hdfs dfsadmin -safemode
hdfs dfsadmin [-safemode enter | leave | get | wait]
3.8检查整个文件系统的健康状况
bin/hdfs fsck /
Usage: fsck
-move 破损的文件移至/lost+found目录
-delete 删除破损的文件
-openforwrite 打印正在打开写操作的文件
-files 打印正在check的文件名
-blocks 打印block报告 (需要和-files参数一起使用)
-locations 打印每个block的位置信息(需要和-files参数一起使用)
-racks 打印位置信息的网络拓扑图 (需要和-files参数一起使用)
四 WEB操作
4.1 HDFS的Web管理地址
http://192.168.1.201:50070/
4.2 集群状态
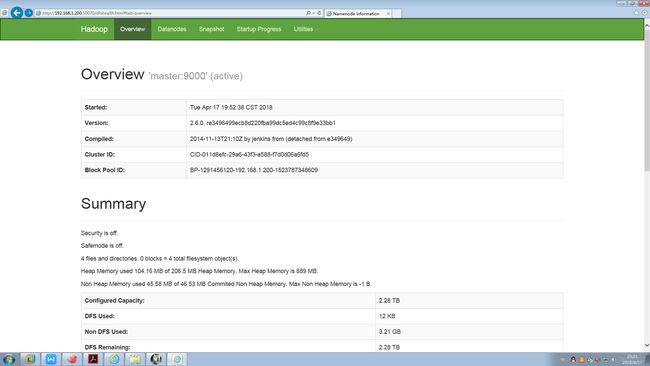
4.3 集群DataNode状态

4.3 集群文件浏览

4.4 集群文件属性

五 API操作
5.1 启动eclipse
windows下双击eclipse图标
5.2 创建工程(testHadoop)
File->new-java project
5.3 在testHadoop工程下创建文件夹lib
5.4 导入hadoop hdfs api访问需要的jar包
5.4.1 windows本地winrar解压hadoop-2.6.0.tar.gz
5.4.2 复制hadoop-2.6.0\hadoop-2.6.0\share\hadoop\common\*.jar,粘贴到lib
5.4.3 复制hadoop-2.6.0\hadoop-2.6.0\share\hadoop\common\lib\*.jar,粘贴到lib
5.4.4 复制hadoop-2.6.0\hadoop-2.6.0\share\hadoop\common\sources\*.jar,粘贴到lib
5.4.5 复制hadoop-2.6.0\hadoop-2.6.0\share\hadoop\hdfs\*.jar,粘贴到lib
5.4.6 复制hadoop-2.6.0\hadoop-2.6.0\share\hadoop\hdfs\lib\*.jar,粘贴到lib
5.4.7 复制hadoop-2.6.0\hadoop-2.6.0\share\hadoop\hdfs\sources\*.jar,粘贴到lib
5.4.8 复制hadoop-2.6.0\hadoop-2.6.0\share\hadoop\mapreduce\*.jar,粘贴到lib
5.4.9 复制hadoop-2.6.0\hadoop-2.6.0\share\hadoop\mapreduce\lib\*.jar,粘贴到lib
5.4.10 复制hadoop-2.6.0\hadoop-2.6.0\share\hadoop\mapreduce\sources\*.jar,粘贴到lib
5.4.11 复制hadoop-2.6.0\hadoop-2.6.0\share\hadoop\yarn\*.jar,粘贴到lib
5.4.12 复制hadoop-2.6.0\ hadoop-2.6.0\share\hadoop\yarn\lib\*.jar,粘贴到lib
5.4.13 复制hadoop-2.6.0\hadoop-2.6.0\share\hadoop\yarn\sources\*.jar,粘贴到lib
5.5 选择lib下的所有 .jar文件,右击鼠标选择build path->add to build path,会在工程下自动生成Referenced Libraries
5.6 写API读写程序
5.6.1 在src上右击鼠标->new->Package,输入包名testHDFS
5.6.2 在testHDFS上右击鼠标->new->Class,输入类名TestHDFSAPI,选择 public static void main(String[] args),完成。
5.6.3 编写读文件程序
import java.io.IOException;
import java.io.InputStream;
import java.net.URI;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileStatus;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.junit.Test;
public class TestHDFSAPI {
public static void main(String[] args){
Configuration conf=new Configuration();
try {
URI uri=new URI("hdfs://192.168.1.201:9000");
FileSystem fs= FileSystem.get(uri,conf);
InputStream inputStream=fs.open(new Path("/core-site.xml"));
int i;
while((i=inputStream.read())!=-1)
{
System.out.print((char)i);
}
fs.close();
}
catch (Exception e) {
e.printStackTrace();
}
}
}
5.6.4 编写上传文件程序
Configuration conf=new Configuration();
try {
URI uri=new URI("hdfs://192.168.1.201:9000");
FileSystem fs= FileSystem.get(uri,conf);
Path src=new Path("d:/logwzy.txt");
Path dest=new Path("/");
fs.copyFromLocalFile(false, true,src,dest);
fs.close();
}
catch (Exception e) {
e.printStackTrace();
}
5.6.5 编写浏览HDFS根目录程序
Configuration conf=new Configuration();
try {
URI uri=new URI("hdfs://192.168.1.201:9000");
FileSystem fs= FileSystem.get(uri,conf);
FileStatus[] fileStatus=fs.listStatus(new Path("/"));
for(int i=0;i
{
FileStatus status=fileStatus[i];
System.out.println("文件名称:"+status.getPath());
System.out.println("复制因子:"+status.getReplication());
System.out.println("文件长度:"+status.getLen());
System.out.println("--------------------------");
}
fs.close();
}
catch (Exception e) {
e.printStackTrace();
}
5.7 运行程序
鼠标右击TestHDFSAPI类代码空白处,Run As->Java Application
MapReduce篇
MapReduce Web管理
1.1 mapreduce的Web管理地址
http://192.168.1.201:8088/
1.2 mapreduce的Web管理界面
1.2.1集群信息
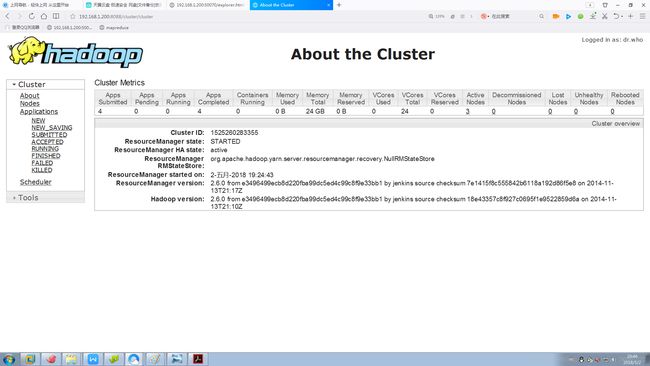
1.2.2 节点信息

1.2.3 所有任务

1.2.4 已提交任务
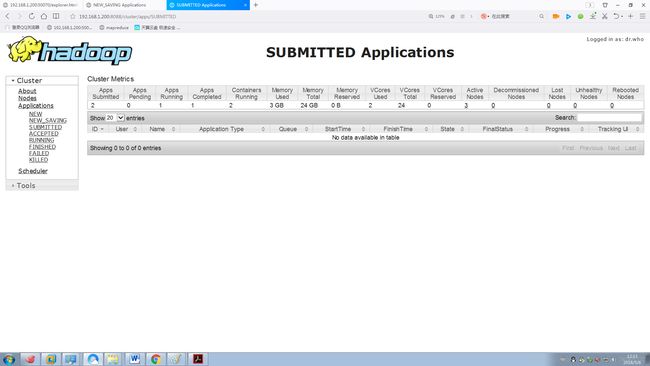
1.2.5 已接受任务

1.2.6 正在运行的任务

1.2.7 已结束的任务
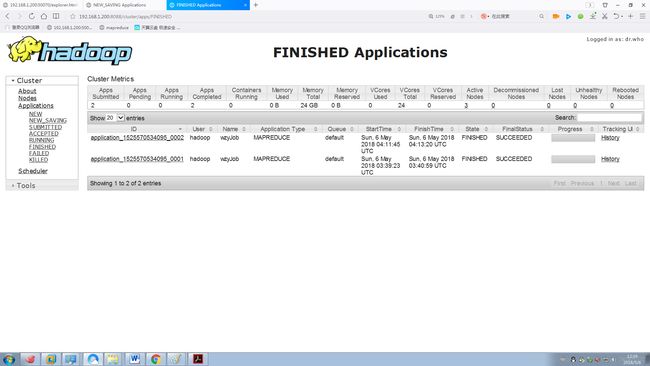
1.2.8 失败的任务

二 MapReduce程序开发准备工作
2.1 运行环境准备
2.1.1 windows本地winrar解压hadoop-2.6.0.tar.gz
2.1.2 设置HADOOP_HOME环境变量,为刚才的解压目录
2.1.3 把winutils.exe文件放到%HADOOP_HOME%的bin目录中
2.1.4 把hadoop.dll文件放到c:/windows/System32目录下,否则会报错
2.1.5 解压hadoop-2.6.0\share\hadoop\common\sources\hadoop-common-2.6.0-sources.jar文件,在解压后的文件中找到org\apache\hadoop\io\nativeio\NativeIO.java文件,把它复制到对应的eclipse的testHadoop project中src的文件夹下,NativeIO.java文件还要在原来的包名下(即project工程下,文件路径应为src\org\apache\hadoop\io\nativeio.java)
2.1.6 修改NativeIO.java文件的557行,替换为return true;
2.1.7 用管理员身份启动eclipse,修改错误级别
鼠标右击项目->Properties->Java Compiler->Errors/Warnings,勾选Enable project specific settings,把Deprecated and restricted API下的Forbidden reference的值设置为Warning
2.2本地模式 处理的文件和运算都在本地执行
2.2.1 准备数据
在d盘创建文件佳testhadoop,在testhadoop下创建input,在input下创建文件test.txt,并写入如下内容
good good study
day day up
2.2.2 配置运行参数
2.2.2.1鼠标右击WCRunner类代码空白处->Run As->Run Configurations
2.2.2.2 选择Arguments页
2.2.2.3 在Program arguments中写入运行参数
d:/testhadoop/input d:/testhadoop/output
2.2.3 运行
鼠标右击WCRunner类代码空白处->Run As->Java Application
2.3半本地模式 处理的文件在HDFS,运算在本地进行
2.3.1 准备数据
2.3.1.1 在linux /home/hadoop/testhadoop下创建test文件,内容如下
good good study
day day up
2.3.1.2 在集群上创建文件夹/testhadoop/input
bin/hadoop dfs -mkdir -p /testhadoop/input
2.3.1.2 把test文件上传到/testhadoop/input中
bin/hadoop dfs -put /home/hadoop/testhadoop/test / testhadoop/input
2.3.2 配置运行参数
2.3.2.1鼠标右击WCRunner类代码空白处->Run As->Run Configurations
2.3.2.2 选择Arguments页
2.3.2.3 在Program arguments中写入运行参数
hdfs://master:9000/input hdfs://master:9000/output
2.3.2.4 在VM arguments中写入运行参数
-DHADOOP_USER_NAME=hadoop
2.3.3 运行
鼠标右击WCRunner类代码空白处->Run As->Java Application
2.4集群模式 jar形式运行,在linux中提交
2.4.1 准备数据
2.4.1.1 在linux /home/hadoop/testhadoop下创建test文件,内容如下
good good study
day day up
2.4.1.2 在集群上创建文件夹/testhadoop/input
bin/hadoop dfs -mkdir -p /testhadoop/input
2.4.1.2 把test文件上传到/testhadoop/input中
bin/hadoop dfs -put /home/hadoop/testhadoop/test / testhadoop/input
2.4.2 导出jar包wc.jar
2.4.3 把wc.jar传到linux的/home/hadoop/testhadoop下
2.4.4 运行
bin/hadoop jar ~/testhadoop/wc.jar testMR.WCRunner /testhadoop/input /testhadoop/
output
注意:输出目录必须是不存在的
三 MapReduce程序开发
3.1 分词统计wordcount
3.1.1 新建testMR包
在src上右击鼠标->new->Package,输入包名testMR
3.1.2 新建WCMapper类,并编写代码
3.1.2.1 在testMR上右击鼠标->new->Class,输入类名WCMapper,不选择 public static void main(String[] args),完成。
3.1.2.2 代码
import java.io.IOException;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class WCMapper extends Mapper
@Override
protected void map(LongWritable key, Text value,
org.apache.hadoop.mapreduce.Mapper.Context context)
throws IOException, InterruptedException {
String line = value.toString();
String words[] = line.split(" ");
for(String word:words)
context.write(new Text(word), new LongWritable(1));
}
}
3.1.3 新建WCReducer类,并编写代码
3.1.3.1 在testMR上右击鼠标->new->Class,输入类名WCReducer,不选择 public static void main(String[] args),完成。
3.1.3.2 代码
import java.io.IOException;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
public class WCReducer extends Reducer
@Override
protected void reduce(Text key, Iterable
Reducer
long sum=0;
for(LongWritable value:values)
sum+=value.get();
context.write(key, new LongWritable(sum));
}
}
3.1.4 新建WCRunner类,并编写代码
3.1.4.1 在testMR上右击鼠标->new->Class,输入类名WCRunner,选择 public static void main(String[] args),完成。
3.1.4.2 代码
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class WCRunner {
public static void main(String[] args) {
Configuration conf=new Configuration();
try{
Job job=Job.getInstance(conf);
job.setJobName("zcjJob");
job.setJarByClass(WCRunner.class);
job.setMapperClass(WCMapper.class);
job.setReducerClass(WCReducer.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
job.waitForCompletion(true);
}
catch(Exception e){
e.printStackTrace();
}
}
}
3.2 倒排索引invertindex
3.2.1新建invertindex包
3.2.2 新建map1类,不选择main方法,并编写代码
import java.io.IOException;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
public class map1 extends Mapper
@Override
protected void map(LongWritable key, Text value,
org.apache.hadoop.mapreduce.Mapper.Context context)
throws IOException, InterruptedException {
// TODO Auto-generated method stub
FileSplit fileSplit = (FileSplit) context.getInputSplit();
String fileName = fileSplit.getPath().getName();
String line = value.toString();
String words[] = line.split(" ");
for (String word : words) {
context.write(new Text(word + "\t" + fileName), new LongWritable(1));
}
}
}
3.2.3 新建Reduce1类,不选择main方法,并编写代码
import java.io.IOException;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class Reduce1 extends Reducer
@Override
protected void reduce(Text key, Iterable
Reducer
throws IOException, InterruptedException {
// TODO Auto-generated method stub
long sum=0;
for(LongWritable value:values){
sum+=value.get();
}
context.write(key,new LongWritable(sum));
}
}
3.2.4 新建map2类,不选择main方法,并编写代码
import java.io.IOException;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class Map2 extends Mapper
@Override
protected void map(LongWritable key, Text value,
Mapper
throws IOException, InterruptedException {
// TODO Auto-generated method stub
String line= value.toString();
String[] strs=line.split("\t");
if(strs!=null && strs.length==3){
String word=strs[0];
String filename=strs[1];
String count=strs[2];
context.write(new Text(word), new Text(filename+"---"+count));
}
}
}
3.2.5 新建Reduce2类,不选择main方法,并编写代码
import java.io.IOException;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class Reduce2 extends Reducer
@Override
protected void reduce(Text key, Iterable
Reducer
throws IOException, InterruptedException {
String result="";
for(Text value:values){
if(result.length()>0){
result+=",";
}
result+=value;
}
context.write(key, new Text(result));
}
}
3.2.6 新建InvertIndexRunner类,选择main方法,并编写代码
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class InvertIndexRunner {
public static void main(String[] args) {
Configuration conf=new Configuration();
try{
Job job=Job.getInstance(conf);
job.setJobName("zcj-invertIndex 1");
job.setJarByClass(InvertIndexRunner.class);
job.setMapperClass(map1.class);
job.setReducerClass(Reduce1.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
job.waitForCompletion(true);
Job job2=Job.getInstance(conf);
job2.setJobName("zcj-invertIndex 2");
job2.setJarByClass(InvertIndexRunner.class);
job2.setMapperClass(Map2.class);
job2.setReducerClass(Reduce2.class);
job2.setMapOutputKeyClass(Text.class);
job2.setMapOutputValueClass(Text.class);
job2.setOutputKeyClass(Text.class);
job2.setOutputValueClass(Text.class);
FileInputFormat.addInputPath(job2, new Path(args[1]));
FileOutputFormat.setOutputPath(job2, new Path(args[2]));
job2.waitForCompletion(true);
}
catch(Exception e){
e.printStackTrace();
}
}
}
zookeeper篇
一 安装配置
1.1 从windows本地上传zookeeper-3.4.6.tar.gz到app下
2.2 解压zookeeper-3.4.6.tar.gz到app下
cd app
tar –zxvf zookeeper-3.4.6.tar.gz
cd ~
2.3配置zookeeper
2.3.1 复制zoo_sample.cfg,更名为zoo.cfg
2.3.2配置zoo.cfg
tickTime=2000
initLimit=5
syncLimit=2
dataDir=/home/hadoop/zkdata/data
dataLogDir=/home/hadoop/zkdata/logs
clientPort=2181
server.1=192.168.1.200:8881:7771
server.2=192.168.1.201:8881:7771
server.3=192.168.1.202:8881:7771
server.4=192.168.1.203:8881:7771
2.4 创建输出文件夹
2.4.1 创建zkdata文件夹
/home/hadoop/zkdata
2.4.2 创建data文件夹
/home/hadoop/zkdata/data
2.4.3 创建log文件夹
/home/hadoop/zkdata/log
2.5 创建myid文件
2.5.1 在/home/hadoop/zkdata/data下创建myid文件
2.5.2 在myid文件中写入该机器在zoo.cfg中配置的序号
二 时间同步(需要切换到root帐户)
2.1 打开日期/时间属性对话框
系统->管理->日期和时间
2.2 时区设置
2.2.1 选择时区tab页
2.2.2 用鼠标选取,上海亚洲
2.2.3 取消系统时间使用UTC时间选择
2.3 时间设置
2.3.1 在网络上同步日期和时间选择
2.3.2 选择正确的日期
2.3.3 在时分秒输入框中,输入比正确时间早1分分钟的整点时间,等待时间到时所有机器同时操作点击确定
2.4 调整位置
2.4.1 点击右上角日期时间显示区域
2.4.2 点击编辑,选择位置页
2.4.3 填加或者编辑,选择上海中国
2.5 调整时钟显示秒
2.4.1 点击右上角日期时间显示区域
2.4.2 点击编辑,选择位常规
2.4.3 设置时间格式24小时制
2.4.4 面板显示,勾选显示秒
三 启停操作
3.1 zookeeper启动
app/zookeeper-3.4.6/bin/zkServer.sh start
注意:多台机器尽量同时启动,减少时间误差
3.2 查看启动是否正常
3.2.1 jps
QuorumPeerMain
3.2.2 app/zookeeper-3.4.6/bin/zkServer.sh status
stand-alone Leader Follower
3.3 zookeeper停止
app/zookeeper-3.4.6/bin/zkServer.sh stop
Hbase篇
一 安装配置
1.1 从windows本地上传hbase-1.0.1.1-bin.tar.gz到app下
2.2 解压hbase-1.0.1.1-bin.tar.gz到app下
cd app
tar – zxvf hbase-1.0.1.1-bin.tar.gz
cd hbase-1.0.1.1-bin.tar.gz/
2.3配置/home/hadoop/app/hbase-1.0.1.1/conf/hbase-env.sh
复制zoo_sample.cfg,更名为zoo.cfg
export JAVA_HOME=/home/hadoop/app/jdk1.8.0_121
export HBASE_CLASSPATH=/home/hadoop/app/hadoop-2.6.0/etc/hadoop
export HBASE_MANAGES_ZK=false
2.3配置/home/hadoop/app/hbase-1.0.1.1/conf/hbase-site.xml
2.4 配置backup-masters
创建app/hbase-1.0.1.1/conf/backup-masters
向backup-masters中写入内容备份主节点主机名
2.5 配置regionservers
向regionservers中写入regionserver主机名,每行一个
slave02
slave03
二 启停操作
2.1 启动hbase
~/app/hbase-1.0.1.1/bin/start-hbase.sh
2.2 使用jps命令查看运行状态
2.2.1 master节点
HMaster
2.2.2 bakup-master节点
HMaster
2.2.3 region节点
HRegionServer
2.3停止hbase
~/app/home/hadoop/app/hbase-1.0.1.1/bin/stop-hbase.sh
三 Shell操作
3.1 shell启动
~app/hbase-1.0.1.1/bin/hbase shell
3.2 shell退出
exit;
3.3 shell常用命令
3.3.1 创建表
create 'users', 'cf1','cf2'
create 'usersx',{NAME=>'cf1',VERSIONS>=3},'cf2'
3.3.2 列出所有表
list
3.3.3 获取表描述信息
dscribe 'users'
3.3.4 写或更新入数据
3.3.4.1 添加纪录
put 'users','xiaoming','cf1:Age','24';
put 'users','xiaoming','cf1:Sex','male';
put 'users','xiaoming','cf2:Address','shi jia zhuang yu hua qu';
3.3.4.2 更新纪录
put 'users','xiaoming','cf1:Age','25';
3.3.4.3 增加版本数据
put 'usersx','xiaoming','cf1:Age' ,'29'
3.3.5 读数据
3.3.5.1 获取某行数据
get 'users','xiaoming'
3.3.5.2 获取某行某列族数据
get 'users','xiaoming','cf1'
3.3.5.3 获某单元格数据
get 'users','xiaoming','cf1:age'
3.3.5.4 获取单元格数据的版本数据,其中N为想要获取的版本个数
get 'usersx','xiaoming',{COLUMN=>'cf1:age',VERSIONS=>N}
3.3.5.5获取单元格数据的时间戳数据
get 'usersx','xiaoming',{COLUMN=>'cf1:age',TIMESTAMP=>1364874937056}
3.3.6 删除某行某列
delete 'users','xiaoming','cf1:age'
3.3.7 删除行
deleteall ‘users’,’xiaoming’
3.3.8 统计表行数
count 'users'
3.3.9 全表扫描
scan 'users'
3.3.10 清空表
truncate 'users'
3.3.11 停用表
disable 'users'
3.3.12 启用表
Enable 'users'
3.3.13删除表
disable 'users'
drop 'users
备注:向前删除需要按ctrl键,否则无效
四 API操作
4.1 开发用到的jar包
windows本地winrar解压hbase-1.0.1.1-bin.tar.gz
hbase-1.0.1.1\lib\hbase-*.jar
netty-all-4.0.23.Final.jar
htrace-core-3.1.0-incubating.jar
4.2 Hbase增删改查
4.2.1 新建testHbase包
在src上右击鼠标->new->Package,输入包名testHbase
4.2.2 新建HbaseCRUD类,并编写代码
在testHive上右击鼠标->new->Class,输入类名HbaseCRUD,不选择 public static void main(String[] args),完成。
4.2.3 代码
import java.io.IOException;
import java.util.ArrayList;
import java.util.Iterator;
import java.util.List;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.Cell;
import org.apache.hadoop.hbase.CellUtil;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.Connection;
import org.apache.hadoop.hbase.client.ConnectionFactory;
import org.apache.hadoop.hbase.client.Delete;
import org.apache.hadoop.hbase.client.Get;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.client.Result;
import org.apache.hadoop.hbase.client.ResultScanner;
import org.apache.hadoop.hbase.client.Row;
import org.apache.hadoop.hbase.client.Scan;
import org.apache.hadoop.hbase.client.Table;
import org.apache.hadoop.hbase.util.Bytes;
import org.junit.After;
import org.junit.Before;
import org.junit.Test;
public class HbaseCRUD {
private Configuration conf;
private Connection conn;
@Before
public void init()
{
conf = HBaseConfiguration.create();
conf.set("hbase.zookeeper.quorum", "slave2:2181,slave3:2181,slave4:2181");
conf.set("hbase.rootdir", "hdfs://master:9000/hbase");
try {
conn = ConnectionFactory.createConnection(conf);
}
catch (IOException e) {
e.printStackTrace();
}
}
@After
public void end() {
try {
conn.close();
}
catch (IOException e) {
e.printStackTrace();
}
}
@Test
public void testPut()
{
try {
Table table=conn.getTable(TableName.valueOf("test"));
Put put=new Put(Bytes.toBytes("zcj"));
put.addColumn(Bytes.toBytes("cf1"), Bytes.toBytes("age"), Bytes.toBytes(22));
put.addColumn(Bytes.toBytes("cf1"), Bytes.toBytes("address"), Bytes.toBytes("TianJin"));
table.put(put);
table.close();
}
catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
@Test
public void testGet() {
try {
Table table = conn.getTable(TableName.valueOf("test"));
Get get = new Get(Bytes.toBytes("xiaohong"));
get.setMaxVersions(5);
Result result = table.get(get);
List
for (Cell cell : cells)
System.out.println(Bytes.toString(CellUtil.cloneValue(cell)));
table.close();
}
catch (Exception e) {
e.printStackTrace();
}
}
@Test
public void testDelete() {
try {
Table table = conn.getTable(TableName.valueOf("test"));
Delete delete = new Delete(Bytes.toBytes("xiaohong"));
delete.addColumn(Bytes.toBytes("cf1"), Bytes.toBytes("age"));
table.delete(delete);
table.close();
}
catch (Exception e) {
e.printStackTrace();
}
}
@Test
public void testBatch() {
try {
Table table = conn.getTable(TableName.valueOf("test"));
List
actions.add(new Put(Bytes.toBytes("xiaohong1")).addColumn(Bytes.toBytes("cf1"), Bytes.toBytes("age"), Bytes.toBytes("22")));
actions.add(new Put(Bytes.toBytes("xiaohong2")).addColumn(Bytes.toBytes("cf1"), Bytes.toBytes("age"), Bytes.toBytes("23")));
actions.add(new Delete(Bytes.toBytes("xiaohong1")));
Object[] results = new Object[actions.size()];
table.batch(actions, results);
for (int i = 0; i < results.length; i++) {
System.out.println("Result[" + i + "]: type = " +
results[i].getClass().getSimpleName() + "; " + results[i]);
}
table.close();
}
catch (Exception e) {
e.printStackTrace();
}
}
@Test
public void testScan() {
try {
Table table = conn.getTable(TableName.valueOf("test"));
Scan scan =new Scan();
ResultScanner resultScanner = table.getScanner(scan);
Iterator
while(iter.hasNext()) {
Result result = iter.next();
List
for(Cell cell:cells)
System.out.println(Bytes.toString(CellUtil.cloneRow(cell))+"---"+ Bytes.toString(CellUtil.cloneValue(cell)));
}
resultScanner.close();
table.close();
}
catch (Exception e) {
e.printStackTrace();
}
}
}
4.2.4 运行
选择要运行的测试单元函数,右击鼠标->run as->JUnit test
4.3 Hbase过滤器
4.3.1 新建testFilter类,并编写代码
在testHive上右击鼠标->new->Class,输入类名testFilter,不选择 public static void main(String[] args),完成。
4.3.2 代码
import java.io.IOException;
import java.util.ArrayList;
import java.util.Iterator;
import java.util.List;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.Cell;
import org.apache.hadoop.hbase.CellUtil;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.Connection;
import org.apache.hadoop.hbase.client.ConnectionFactory;
import org.apache.hadoop.hbase.client.Result;
import org.apache.hadoop.hbase.client.ResultScanner;
import org.apache.hadoop.hbase.client.Scan;
import org.apache.hadoop.hbase.client.Table;
import org.apache.hadoop.hbase.filter.BinaryComparator;
import org.apache.hadoop.hbase.filter.CompareFilter.CompareOp;
import org.apache.hadoop.hbase.filter.Filter;
import org.apache.hadoop.hbase.filter.FilterList;
import org.apache.hadoop.hbase.filter.PageFilter;
import org.apache.hadoop.hbase.filter.QualifierFilter;
import org.apache.hadoop.hbase.filter.RegexStringComparator;
import org.apache.hadoop.hbase.filter.RowFilter;
import org.apache.hadoop.hbase.filter.SingleColumnValueFilter;
import org.apache.hadoop.hbase.filter.ValueFilter;
import org.apache.hadoop.hbase.util.Bytes;
import org.junit.After;
import org.junit.Before;
import org.junit.Test;
public class testFilter {
private Configuration conf;
private Connection conn;
@Test
public void TestFilterList(){
try {
Table table = conn.getTable(TableName.valueOf("test2"));
Scan scan =new Scan();
List
Filter filter1 = new RowFilter(CompareOp.GREATER_OR_EQUAL,new BinaryComparator(Bytes.toBytes("zcj2")));
filters.add(filter1);
Filter filter2 = new RowFilter(CompareOp.LESS_OR_EQUAL,new BinaryComparator(Bytes.toBytes("zcj5")));
filters.add(filter2);
Filter filter3 = new QualifierFilter(CompareOp.EQUAL,new RegexStringComparator("age"));
filters.add(filter3);
FilterList filterList = new FilterList(filters);
scan.setFilter(filterList);
ResultScanner resultScanner = table.getScanner(scan);
Iterator
while(iter.hasNext())
{
Result result = iter.next();
List
for(Cell cell:cells)
System.out.println(Bytes.toString(CellUtil.cloneRow(cell))+"---"+ Bytes.toString(CellUtil.cloneValue(cell)));
}
resultScanner.close();
table.close();
}
catch (Exception e) {
e.printStackTrace();
}
}
@Test
public void TestPageFilter(){
try {
byte[] POSTFIX=new byte[]{0x0};
byte[] row=null;
Table table = conn.getTable(TableName.valueOf("test"));
Scan scan =new Scan();
Filter filter=new PageFilter(1);
while(true){
if(row!=null){
row=Bytes.add(row, POSTFIX);
scan.setStartRow(row);
}
scan.setFilter(filter);
ResultScanner resultScanner = table.getScanner(scan);
Iterator
int index=0;
while(iter.hasNext()){
Result result=iter.next();
if(!result.isEmpty())
{
row=result.getRow();
List
for(Cell cell:cells)
System.out.println(Bytes.toString(CellUtil.cloneRow(cell))+"---"+ Bytes.toString(CellUtil.cloneValue(cell)));
}
index++;
}
if(index==0)
break;
resultScanner.close();
}
table.close();
}
catch (Exception e) {
e.printStackTrace();
}
}
@Test
public void TestSingleValueFilter(){
try {
Table table = conn.getTable(TableName.valueOf("test"));
Scan scan =new Scan();
Filter filter=new SingleColumnValueFilter(Bytes.toBytes("cf1"), Bytes.toBytes("address"),CompareOp.EQUAL,new BinaryComparator(Bytes.toBytes("tianjin")));
scan.setFilter(filter);
ResultScanner resultScanner = table.getScanner(scan);
Iterator
while(iter.hasNext())
{
Result result = iter.next();
List
for(Cell cell:cells)
System.out.println(Bytes.toString(CellUtil.cloneRow(cell))+"---"+ Bytes.toString(CellUtil.cloneValue(cell)));
}
resultScanner.close();
table.close();
}
catch (Exception e) {
e.printStackTrace();
}
}
@Test
public void TestValueFilter(){
try {
Table table = conn.getTable(TableName.valueOf("test"));
Scan scan =new Scan();
Filter filter=new ValueFilter(CompareOp.EQUAL,new BinaryComparator(Bytes.toBytes("tianjin")));
scan.setFilter(filter);
ResultScanner resultScanner = table.getScanner(scan);
Iterator
while(iter.hasNext()) {
Result result = iter.next();
List
for(Cell cell:cells)
System.out.println(Bytes.toString(CellUtil.cloneRow(cell))+"---"+ Bytes.toString(CellUtil.cloneValue(cell)));
}
resultScanner.close();
table.close();
}
catch (Exception e) {
e.printStackTrace();
}
}
@Test
public void TestRowFilter(){
try {
Table table = conn.getTable(TableName.valueOf("test"));
Scan scan =new Scan();
Filter filter=new RowFilter(CompareOp.EQUAL,new BinaryComparator(Bytes.toBytes("xiaohong")));
scan.setFilter(filter);
ResultScanner resultScanner = table.getScanner(scan);
Iterator
while(iter.hasNext()) {
Result result = iter.next();
List
for(Cell cell:cells)
System.out.println(Bytes.toString(CellUtil.cloneRow(cell))+"---"+ Bytes.toString(CellUtil.cloneValue(cell)));
}
resultScanner.close();
table.close();
}
catch (Exception e) {
e.printStackTrace();
}
}
@Before
public void init()
{
conf = HBaseConfiguration.create();
conf.set("hbase.zookeeper.quorum", "slave2:2181,slave3:2181,slave4:2181");
conf.set("hbase.rootdir", "hdfs://master:9000/hbase");
try {
conn = ConnectionFactory.createConnection(conf);
}
catch (IOException e) {
e.printStackTrace();
}
}
@After
public void end() {
try {
conn.close();
}
catch (IOException e) {
e.printStackTrace();
}
}
}
4.3.3 运行
选择要运行的测试单元函数,右击鼠标->run as->JUnit test
4.4 Hbase MapReduce
4.4.1 新建testHbase包
在src上右击鼠标->new->Package,输入包名testHbase.mr
4.4.2 新建ImportData类,并编写代码
在testHbase.mr上右击鼠标->new->Class,输入类名ImportData,选择 public static void main(String[] args),完成。
4.4.3 代码
import java.io.IOException;
import org.apache.commons.codec.digest.DigestUtils;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.client.Mutation;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.io.ImmutableBytesWritable;
import org.apache.hadoop.hbase.mapreduce.TableOutputFormat;
import org.apache.hadoop.hbase.util.Bytes;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
public class ImportData {
public static void main(String[] args) {
Configuration conf = HBaseConfiguration.create();
try {
Job job = Job.getInstance(conf);
job.setJarByClass(ImportData.class);
job.setMapperClass(ImportDataMapper.class);
job.setOutputKeyClass(ImmutableBytesWritable.class);
job.setOutputValueClass(Mutation.class);
job.setOutputFormatClass(TableOutputFormat.class);
job.getConfiguration().set(TableOutputFormat.OUTPUT_TABLE, "test3");
FileInputFormat.addInputPath(job, new Path(args[0]));
job.setNumReduceTasks(0);
job.waitForCompletion(true);
}
catch (Exception e) {
e.printStackTrace();
}
}
}
class ImportDataMapper extends Mapper
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();
byte[] rowKey = DigestUtils.md5(line);
Put put = new Put(rowKey);
put.addColumn(Bytes.toBytes("cf1"), Bytes.toBytes("content"), Bytes.toBytes(line));
context.write(new ImmutableBytesWritable(rowKey), put);
}
}
4.4.4 运行
鼠标右击ImportData类代码空白处,Run As->Java Application
Hive篇
一 mysql安装(需要切换到root帐户)
1.1 下载并安装mysql
yum install mysql-server mysql mysql-devel
具体步骤:
(1)下载:wget http://repo.mysql.com/mysql-community-release-el7-5.noarch.rpm
(2)安装:rpm -ivh mysql-community-release-el7-5.noarch.rpm -y
(3) 配置:vim /etc/my.cnf
1.2 启动mysql服务
service mysqld start
1.3 查看mysql运行状态
systemctl status mysql.service

1.4 设置mysql管理用户密码
mysqladmin -u root password 'root'
1.5 设置mysql开机启动
chkconfig mysqld on
1.6 启动mysql命令行
mysql -u root -p 'root'
1.7 创建数据库
mysql> create database hive;
1.8 查询数据库是否创建成功
mysql> show databases;
1.9 设置root用户对hive库的访问权限
mysql> GRANT all ON hive.* TO 'root'@'%' IDENTIFIED BY 'root';
1.10刷新mysql的系统权限相关表
mysql> flush privileges;
1.11 退出mysql
mysql> exit;
二 hive安装配置
2.1 从windows本地上传apache-hive-1.2.1-bin.tar.gz到app下
2.2 解压apache-hive-1.2.1-bin.tar.gz到app下
cd app
tar –zxvf apache-hive-1.2.1-bin.tar.gz
cd ~
2.3 替换文件
jline-2.12.jar 从hive/lib ->hadoop/share/hadoop/yarn/lib
tools.jar 从jdk1.8.0_121/lib -> apache-hive-1.2.1-bin/lib
mysql-connector-java-5.0.8-bin.jar 从本地 -> apache-hive-1.2.1-bin/lib
2.4 配置hive
2.4.1 hive-env.sh
2.4.1.1复制hive-env.sh.template,更名为hive-env.sh
2.4.1.2配置
export HADOOP_HEAPSIZE=1024
HADOOP_HOME=/home/hadoop/app/hadoop-2.6.0
2.4.2 hive-site.xml
2.4.2.1 复制hive-default.xml.template,更名为hive-site.xml
2.4.2.2 配置
注意:master节点
三 CLI
3.1 cli启动
~app/apache-hive-1.2.1-bin/bin/hive
3.2 cli退出
exit
3.3 cli常用命令
create database test_dw;
show databases;
create table zcjhive (name String,Age int);
show tables;
describe zcjhive;
select * from zcjhive;
insert into zcjhive (name,age) values ('zcj',42);
load data local inpath '/home/hadoop/mydata/hive.txt' into table zcjhive;
insert overwrite local directoy '/home/hadoop/mydata/output_hive' select * from zcjhive;
import export(只能集群操作)
四 Metastore
启动元数据服务
~app/apache-hive-1.2.1-bin/bin/hive --service metastore
~app/apache-hive-1.2.1-bin/bin/hive --service metastore & (进入后台运行)
五 HWI安装配置
5.1 hwi文件安装
5.1.1下载hive源码
http://archive.apache.org/dist/下载源码apach-hive-1.2.1-src.tar.gz
5.1.2解压apach-hive-1.2.1-src.tar.gz
tar -zxvf apach-hive-1.2.1-src.tar.gz
5.1.3 切换目录
cd apache-hive-1.2.1-src/hwi
5.1.4 打war包
jar cvM hive-hwi-1.2.1.war -C web/ .
5.1.5 拷贝hive-hwi-1.2.1.war到apache-hive-1.2.1-bin/lib/下
5.2 hwi配置,修改hive-site.xml
5.3 启动hwi服务
~app/apache-hive-1.2.1-bin/bin/hive --service hwi
~app/apache-hive-1.2.1-bin/bin/hive --service hwi & (进入后台运行)
5.4 hive web管理
5.4.1 hive的Web管理地址
http://192.168.1.201:9999/hwi/
5.4.2 hive的Web管理界面
5.4.3 查看数据库
5.4.4 创建会话
5.4.4 会话管理
5.4.5 执行语句
提示:hwi result file 在master hadoop用户根下
六 API操作
6.1 API配置,修改hive-site.xml
6.2 启动server2
~app/apache-hive-1.2.1-bin/bin/hive --service hiveserver2
6.3 开发用到的jar包
windows本地winrar解压apache-hive-1.2.1-bin.tar.gz
apache-hive-1.2.1-bin\lib\hive-*.jar
apache-hive-1.2.1-bin\lib\lib*.jar
6.4 编写程序
6.4.1 新建testHive包
在src上右击鼠标->new->Package,输入包名testHive
6.4.2 新建JDBCToHive类,并编写代码
6.4.2.1 在testHive上右击鼠标->new->Class,输入类名JDBCToHive,不选择 public static void main(String[] args),完成。
6.4.2.2 代码
private static Connection conn=JDBCToHive.getConnnection();
private static PreparedStatement ps;
private static ResultSet rs;
private static String driverName ="org.apache.hive.jdbc.HiveDriver";
private static String Url="jdbc:hive2://192.168.1.200:10000/default";
private static Connection conn;
public static Connection getConnnection()
{
try{
Class.forName(driverName);
conn = DriverManager.getConnection(Url,"hadoop","hadoop");
}
catch(ClassNotFoundException e){
e.printStackTrace();
}
catch (SQLException e) {
e.printStackTrace();
}
return conn;
}
public static PreparedStatement prepare(Connection conn, String sql)
{
PreparedStatement ps = null;
try {
ps = conn.prepareStatement(sql);
}
catch (SQLException e) {
e.printStackTrace();
}
return ps;
}
6.4.3 新建QueryHive类,并编写代码
6.4.3.1 在testHive上右击鼠标->new->Class,输入类名QueryHive,不选择 public static void main(String[] args),完成。
6.4.3.2 代码
public static void getAll(String tablename)
{
String sql="select * from "+tablename;
System.out.println(sql);
try {
ps=JDBCToHive.prepare(conn, sql);
rs=ps.executeQuery();
int columns=rs.getMetaData().getColumnCount();
while(rs.next())
{
for(int i=1;i<=columns;i++)
{
System.out.print(rs.getString(i));
System.out.print("\t");
}
System.out.println();
}
}
catch (SQLException e) {
e.printStackTrace();
}
}
6.4.4 新建QueryHiveRun类,并编写代码
6.4.4.1 在testHive上右击鼠标->new->Class,输入类名QueryHiveRun, 选择 public static void main(String[] args),完成。
6.4.4.2 代码
String tablename="zlhtest";
QueryHive.getAll(tablename);
6.4.5 运行程序
鼠标右击QueryHiveRun类代码空白处,Run As->Java Application
Slurm篇
1、安装MUNGE,需要munge-munge-0.5.13.tar.gz munge-0.5.13.tar.xz两个文件
安装解析文件的工具
yum -y install bzip2-devel openssl-devel zlib-devel
yum install -y rpm-build
解压
rpmbuild -tb --clean munge-munge-0.5.13.tar.gz
编译
cd /root/rpmbuild/RPMS/x86_64
安装munge
rpm -ivh munge*.rpm
设置互通秘钥为:helloeveryone,I'ammungekeyonkvmcluster.
echo "helloeveryone,I'ammungekeyonkvmcluster." > /etc/munge/munge.key
修改文件夹属性
chown munge:munge /etc/munge/munge.key
chmod 400 /etc/munge/munge.key
chmod -Rf 700 /etc/munge
chmod -Rf 711 /var/lib/munge
chmod -Rf 700 /var/log/munge
chmod -Rf 755 /var/run/munge
删除其他之前之前的秘钥(若之前也做过这种操作)
ssh slave02 rm -f /etc/munge/munge.key
ssh slave03 rm -f /etc/munge/munge.key
将生成的秘钥复制给其他节点
scp /etc/munge/munge.key root@slave01:/etc/munge/munge.key
scp /etc/munge/munge.key root@slave03:/etc/munge/munge.key
munge的基本操作命令
systemctl enable munge
systemctl disable munge
systemctl status munge
systemctl start munge
systemctl restart munge
systemctl stop munge
munge -n | ssh master unmunge
munge -n | ssh slave01 unmunge
munge -n | ssh slave02 unmunge
5、安装SLURM
安装解析文件的工具
yum -y install readline-devel pam-devel
yum install perl-ExtUtils-CBuilder perl-ExtUtils-MakeMaker
重新清理文件
rpmbuild -tb --clean slurm-17.02.9.tar.bz2
cd /root/rpmbuild/RPMS/x86_64
安装
rpm -ivh slurm*.rpm
6、配置SLURM
配置slurm用户
useradd slurm
passwd slurm
配置文件
vim /etc/slurm/slurm.conf
ClusterName=bxg_cluster
ControlMachine=master
ControlAddr=192.168.2.2
SlurmUser=slurm
SlurmctldPort=6817
SlurmdPort=6818
AuthType=auth/munge
StateSaveLocation=/var/spool/slurm/ctld
SlurmdSpoolDir=/var/spool/slurm/d
SwitchType=switch/none
MpiDefault=none
SlurmctldPidFile=/var/run/slurmctld.pid
SlurmdPidFile=/var/run/slusrmd.pid
ProctrackType=proctrack/pgid
ReturnToService=0
SlurmctldTimeout=300
SlurmdTimeout=300
InactiveLimit=0
MinJobAge=300
KillWait=30
Waittime=0
SchedulerType=sched/backfill
FastSchedule=1
SlurmctldDebug=3
SlurmctldLogFile=/var/log/slurmctld.log
SlurmdDebug=3
SlurmdLogFile=/var/log/slurmd.log
JobCompType=jobcomp/none
NodeName=master,slave0[1-2] Procs=1 State=UNKNOWN
PartitionName=control Nodes=master Default=NO MaxTime=INFINITE State=UP
PartitionName=compute Nodes=slave0[1-2] Default=YES MaxTime=INFINITE State=UP
:wq
将配置文件复制到其他节点
scp /etc/slurm/slurm.conf root@slave02:/etc/slurm/slurm.conf
scp /etc/slurm/slurm.conf root@slave03:/etc/slurm/slurm.conf
创建指定文件夹
mkdir /var/spool/slurm/d
mkdir /var/spool/slurm/ctld
增加权限
chown -R slurm:slurm /var/spool
主节点命令
systemctl enable slurmctld
systemctl disable slurmctld
systemctl status slurmctld
systemctl start slurmctld
systemctl restart slurmctld
systemctl stop slurmctld
主节点和从节点命令
systemctl enable slurmd
systemctl disable slurmd
systemctl status slurmd
systemctl start slurmd
systemctl restart slurmd
systemctl stop slurmd
7、简单测试SLURM
sinfo
scontrol show slurm reports
scontrol show config
scontrol show partition
scontrol show node
scontrol show jobs
srun hostname
srun -N 2 -l hostname
srun sleep 60 &
squeue -a
scancel
NTP时间服务器篇
搭建内网的NTP时间服务器的具体操作步骤
需求:搭建一台时间服务器,使得无外网的服务器可以同步时间。
一、环境
1. [root@master ~]# cat /etc/redhat-release
Red Hat Enterprise Linux Server release 7.0 (Maipo)
3. [root@ master ~]# hostname -I
4. 查看内网ip命令:ifconfig –a
192.168.1.200
5. 查看外网ip命令:curl ifconfig.me
124.236.148.6
二、安装ntp并检查是否安装成功
1.安装ntp包
yum install ntp
2.开机启用NTP服务:
systemctl enable ntpd
3. 启动ntp服务:
systemctl start ntpd
4. 查看ntp服务状态
systemctl status ntpd

三、配置可用时间服务器
配置NTP时间同步文件:# vi /etc/ntp.conf,添加时间源,如:
server 10.100.2.5 # local clock
fudge 10.100.2.5 stratum 10
四、启动ntp服务器
查看时间同步进程:# ntpq –p
查看时间服务器状态:
systemctl status ntpd
手动同步:
ntpdate –u 192.168.1.200


查看当前时间:
date

Python脚本篇
一、python2.x的源码
自动化脚本就是PyCharm开发环境来编写的,使用的语言是python2.x版本,通过pip引入paramiko模块,运行该脚本文件,实现对集群的自动化、一键式管理。
# -*- coding: UTF-8 -*-
# !/bin/python
# 运行程序前,要安装pip和paramiko
# 此程序为Python2.X程序
import subprocess
import os, commands, string, sys, time, paramiko
def out_progress():
for i in range(50):
sys.stdout.write("\033[0;32m%s\033[0m" % ".")
sys.stdout.flush()
time.sleep(0.5)
print("\n")
print("\033[0;32m%s\033[0m" % "开机成功!\n")
def start_all():
os.system("wol f4:4d:30:94:30:ad")
os.system("wol f4:4d:30:94:1c:3d")
os.system("wol f4:4d:30:94:1c:92")
def ssh_conn(_hostname, _port, _username, _password, *args):
# shclient对象
ssh = paramiko.SSHClient()
# 允许将信任的主机自动加入到host_allow 列表,此方法必须放在connect方法的前面
ssh.set_missing_host_key_policy(paramiko.AutoAddPolicy())
# 调用connect方法连接服务器
ssh.connect(hostname=_hostname, port=_port, username=_username, password=_password)
for i in range(len(args)):
stdin, stdout, stderr = ssh.exec_command(args[i])
# 结果放到stdout中,如果有错误将放到stderr中
if "ntpdate" in args[0]:
print("slave0%s节点对时:" % _hostname[-1])
#print(_hostname[-1])
print(stdout.read().decode("utf-8"))
print("成功!")
print(stdout.read().decode("utf-8"))
ssh.close()
def test_process(_commands, *args):
output = commands.getoutput(_commands)
return output
def ssh_conn_return(_hostname, _port, _username, _password, *args):
# shclient对象
ssh = paramiko.SSHClient()
# 允许将信任的主机自动加入到host_allow 列表,此方法必须放在connect方法的前面
ssh.set_missing_host_key_policy(paramiko.AutoAddPolicy())
# 调用connect方法连接服务器
ssh.connect(hostname=_hostname, port=_port, username=_username, password=_password)
for i in range(len(args)):
stdin, stdout, stderr = ssh.exec_command(args[i])
# 结果放到stdout中,如果有错误将放到stderr中
if "zookeeper" in args[0]:
print("slave0%s:" % _hostname[-1])
# print(_hostname[-1])
print(stdout.read().decode("utf-8"))
print("成功!")
print(stdout.read().decode("utf-8"))
ssh.close()
while True:
print("\033[0;34m%s\033[0m" % "\n请输入您想要的操作代号: ")
print("s. 一键开机!\t\t a. 启动集群!\t\t b. 停止集群!\t\t d. 启动时间服务器")
#print("a. 启动集群!")
print("t. 集群自动对时!\t sz.启动zookeeper \t pz.停止zookeeper \t szs.查看zookeeper状态")
print("c. 一键清屏!\t \t j. 查看当前进程!\t p.一键关机")
print("exit. 退出运行的脚本!")
in_put=raw_input("请输入:")
if in_put=='a':
os.system("~/app/hadoop-2.6.0/sbin/start-all.sh")
print("\n")
print("\033[0;32m%s\033[0m" % "集群启动 成功!")
#print("\n")
elif in_put=='sz':
#查看集群有无启动
#多台机器同时启动
# os.system("app/zookeeper-3.4.6/bin/zkServer.sh start")
# print("\n\033[0;32m%s\033[0m" % "master zookeeper 启动成功!")
ssh_conn_return("192.168.1.201", 22, "hadoop", "hadoop", "app/zookeeper-3.4.6/bin/zkServer.sh start")
ssh_conn_return("192.168.1.202", 22, "hadoop", "hadoop", "app/zookeeper-3.4.6/bin/zkServer.sh start")
ssh_conn_return("192.168.1.203", 22, "hadoop", "hadoop", "app/zookeeper-3.4.6/bin/zkServer.sh start")
elif in_put=='szs':
#停止zookeep
ssh_conn_return("192.168.1.201", 22, "hadoop", "hadoop", "app/zookeeper-3.4.6/bin/zkServer.sh status")
ssh_conn_return("192.168.1.202", 22, "hadoop", "hadoop", "app/zookeeper-3.4.6/bin/zkServer.sh status")
ssh_conn_return("192.168.1.203", 22, "hadoop", "hadoop", "app/zookeeper-3.4.6/bin/zkServer.sh status")
elif in_put=='pz':
# os.system("app/zookeeper-3.4.6/bin/zkServer.sh status")
ssh_conn_return("192.168.1.201", 22, "hadoop", "hadoop", "app/zookeeper-3.4.6/bin/zkServer.sh stop")
ssh_conn_return("192.168.1.202", 22, "hadoop", "hadoop", "app/zookeeper-3.4.6/bin/zkServer.sh stop")
ssh_conn_return("192.168.1.203", 22, "hadoop", "hadoop", "app/zookeeper-3.4.6/bin/zkServer.sh stop")
elif in_put=='s':
start_all()
out_progress()
elif in_put=='b':
#判断zookeep有没有停止
os.system("app/hadoop-2.6.0/sbin/stop-all.sh")
print("\033[0;32m%s\033[0m" % "集群停止 成功!")
elif in_put=="c":
os.system("clear")
elif in_put=="d":
ssh_conn("192.168.1.200", 22, "root", "hadoop", "systemctl restart ntpd")
t = test_process("systemctl status ntpd.service")
if ("SUCCESS" and "running") in t:
print("\n\033[0;32m%s\033[0m" % "master节点的时间服务启动成功")
elif in_put=='j':
#打印salve节点的 jps 信息
print("\n\033[0;32m%s\033[0m" % "当前master进程为:")
os.system("jps")
elif in_put=="p":
ssh_conn("192.168.1.201",22,"root","hadoop","poweroff")
print("slave01正在关机.....")
ssh_conn("192.168.1.202",22,"root","hadoop","poweroff")
print("slave02正在关机.....")
ssh_conn("192.168.1.203",22,"root","hadoop","poweroff")
print("slave03正在关机.....")
time.sleep(7)
print("\033[0;32m%s\033[0m" % "集群所有从节点已经关机!")
elif in_put=="t":
ssh_conn("192.168.1.201",22,"root","hadoop","ntpdate -u 192.168.1.200")
ssh_conn("192.168.1.202",22,"root","hadoop","ntpdate -u 192.168.1.200")
ssh_conn("192.168.1.203",22,"root","hadoop","ntpdate -u 192.168.1.200")
elif in_put=="exit":
break
二、脚本运行示例图
