Cassandra学习小总结
前言
最近机缘巧合接触了Cassandra,经历了几天的安装部署压测完成任务的同时,利用时间结合网上的博客了解学习了Cassandra,并且简单实操了下,在此进行总结。
参考链接
1. Cassandra官网: https://cassandra.apache.org
官网文档: https://cassandra.apache.org/doc/latest/
2. Cassandra下载链接: http://archive.apache.org/dist/cassandra/
3. Cassandra安装部署:http://blog.chinaunix.net/uid-20104120-id-3282195.html
对于单节点而言,基本jdk python环境部署好后,cassandra的tar包直接解压,然后配置环境变量即可。此次实操也是单节点进行,集群搭建参考:https://www.cnblogs.com/TSlover/p/11398535.html
4. Cassandra基本使用教程:https://www.w3cschool.cn/cassandra/
5. Python2.7.9安装:https://www.ucloud.cn/yun/63210.html
6. YCSB介绍:
https://www.cnblogs.com/foxmailed/archive/2012/02/29/2374595.html
https://www.jianshu.com/p/b4904a9f0d11
7. YCSB下载链接:https://github.com/brianfrankcooper/YCSB/releases
8. ycsb-cassandra-binding-0.17.0.tar.gz下载百度云链接:因为这个从github下载需要,所以提供一下我的百度云链接,可以直接下
解压后就可以直接用,无需编译
链接:https://pan.baidu.com/s/1oIv4q0HpR3AXZCtYm79T0g
提取码:v1jt
9. YCSB对Cassandra进行压力测试:https://www.cnblogs.com/lijinji/p/8591800.html】
10. YCSB核心属性:https://github.com/brianfrankcooper/YCSB/wiki/Core-Properties
知识点
1. 基本概念
Apache Cassandra是一个分布式NoSQL数据库,用于处理大量商用服务器上的大量结构化数据,可提供高可用、高可扩展的服务,无单点故障。于2009年3月被纳入Apache孵化器,自2010年2月以来成功一个Apache顶级项目。
同RDBMS相比,Cassandra在支持存储结构化数据的同时,无固定模式,面向列,可分布式存储
同HBase相比,Cassandra在面向列存储的同时,支持事务,支持存储结构化数据,无单点故障
如果仅仅是存储海量数据并且数据更新少,且要求数据不能丢失可以快速通过添加机器扩容,可选Cassandra;如果是对数据有频繁读操作,且支持倒排可选HDFS+HBase
单点故障:集群中一个节点宕机或者出现其他故障,导致集群崩溃或者数据丢失。
Cassandra的特性:
- 弹性高扩展性——允许添加更多的硬件以适应更多的客户和数据要求
- 基于架构——无单点故障,可连续用于承担故障的关键业务应用程序
- 快速线性性能——线性可扩展,可保持一个快速的响应时间
- 数据存储——适应所有可能的数据格式,包括结构化、非结构化和半结构化
- 数据分发——通过在多个数据中心间复制数据,可在需要时分发数据
- 快速写入——同HBase类似,可在廉价的PC机上运行。执行快速写入,并可存储数百TB的数据
Cassandra的应用场景: 参考https://www.cnblogs.com/starcrm/p/11943812.html
- 写大于读:分布式写操作,可在任何地方任何时间集中写数据,无单点故障
- 数据更新少
- 通过主键查询
- 不需要join
- 交易日志:例如购买记录等
- 存储时序数据
- 跟踪订单状态,物流包裹,日志信息等记录
- 气象服务等事件历史
Cassandra的不适用场景:
- 具有很多二级索引
- 应用程序依赖于底层数据库的自增主键功能
- 聚合
- join
- 锁
- 并发更新:Cassandra的上层应用一般需要先读后更新,读的时候触发数据库的数据修复操,去作清除掉节点中已经失效的数据,从而保证数据一致性
2. 架构+数据模型
Cassandra设计的目的就是处理跨越多个节点的大数据工作负载workload,同时保证没有任何单点故障。
在集群节点间为对等分布式系统,数据分布在所有的节点上,也就是说集群中所以的节点扮演相同角色(此点与hbase不同,hbase中有master和slave之分),每个节点都可以与集群中的其他节点互连。并且每个节点都可以接受读写请求,当原指定的读/写请求目标节点关闭时,可从集群网络中的其他节点获取读/写响应
Cassandra可以保证无单点故障的机制:后台使用Gossip协议,集群中的多个节点会充当给定数据片段的副本,也就是说集群中的多个节点会对数据做备份处理。同时如果检测到一些节点有过期值响应,会给客户端返回最近的值,同时在后台执行读修复以更新失效值(保证集群中节点的数据一致性)
Gossip协议:网络节点中一个节点通讯多个节点之后,此时多个节点可同时分别通讯网络中的其他节点(类似传染,一传多,多传多)参考:https://zhuanlan.zhihu.com/p/41228196
Cassandra中的组件包括:节点;数据中心;集群;提交日志;Mem-表;SSTable;布隆过滤器
- 节点:存储数据
- 数据中心:存储某个数据片段的节点集合
- 集群:一个或多个数据中心的集合
- 提交日志:崩溃恢复机制,每个写操作都会写入提交日志(当崩溃后,会从提交日志中回滚恢复数据)
- Mem-表:写数据先将数据写入提交日志后,会将数据写入mem表即内存表(类似HBase中的先hlog再memstore)
- SSTable:磁盘文件,当内存数据达到阈值后会从mem表中刷写数据到SSTable中(类似HBase中的memstore到hfile)
- 布隆过滤器:测试元素是否为集合的成员,每次查询先访问布隆过滤器 参考:https://baike.baidu.com/item/%E5%B8%83%E9%9A%86%E8%BF%87%E6%BB%A4%E5%99%A8/5384697?fr=aladdin
Cassandra中的数据模型包括:集群、键空间、列族、列
- 集群cluster:Cassandra数据库支持完全分布式存储,即多个数据库分别分布在不同的节点上并支持互连。其中每个节点都包含副本,如果说发生故障将激活副本。Cassasndra按照环形格式将节点分布在集群中并为其分配数据
- 键空间keyspace:类似于hbase中的namespace,是Cassandra中数据的最外层容器。一般keyspace包括复制因子、副本放置策略、列族三个属性。复制因子是指集群中接收相同数据副本的节点数;副本放置策略包括简单策略、旧网络拓扑策略和网络拓扑策略;列族相当于hbase中的table
- 列族column family:类似hbase中的table表,定义列族的时候可以不用先定义列,一个列族支持任意数量的列/超级列
- 列column:Cassandra基本数据结构,类似HBase中的column qualifier,具有键名称、值和时间戳三个属性。
- 超级列super column:一个特殊列,一个存储子列地图的键值对
3. 安装部署
以安装部署单节点Cassandra3.11.6为例进行说明。
1. 基础环境准备(可查看Cassandra官方说明 确定支持的基础环境版本)
JDK1.8
Python2.7.9(安装方法参考:https://www.ucloud.cn/yun/63210.html)
python依赖安装:总的来讲就是提示缺啥下载啥就行(注意版本兼容问题)
ssl:https://blog.csdn.net/sdafhkjas/article/details/103012547
pip:https://blog.csdn.net/u010971754/article/details/79692786
setuptools安装报错缺zlib包:https://blog.csdn.net/fengtian12345/article/details/80272773?utm_source=blogxgwz4
2. 安装Cassandra
//解药tar压缩包
tar -zxvf apache-cassandra-3.11.6.tar.gz
//配置环境变量/etc/profile
export JAVA_HOME=/usr/local/src/jdk1.8.0_211
export JRE_HOME=/usr/local/src/jdk1.8.0_211/jre
export PYTHON_HOME=/usr/local/python-2.7.9
export JAVA_PATH=$JAVA_HOME/bin
export JRE_PATH=$JRE_HOME/bin
export CASSANDRA_HOME=/usr/local/src/apache-cassandra-3.11.6
export CASSANDRA_PATH=$CASSANDRA_HOME/bin
export PYTHON_PATH=$PYTHON_HOME/bin
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$JRE_HOME/lib:$CLASSPATH
export PATH=$JAVA_PATH:$JRE_PATH:$CASSANDRA_PATH:$CASSANDRA_HOME/lib:$PYTHON_PATH:$PATH
//让环境变量配置生效
source /etc/profile
//检查Cassandra安装,如果出现安装部署的cassandra路径即安装成功
which cassandra
3. 启动/关闭Cassandra
//启动Cassandra,-f是在前台启动,如果使用root用户启动,添加-R 强制启动
./bin/cassandra -f -R
//启动命令行cqlsh,加当前节点的ip地址或者hostname
./bin/cqlsh ip/hostname
//退出cqlsh
quit或者exit
//关闭cassandra,直接Crtl+Z即可,如果ps -ef | grep cassandra显示还有进程的话,使用kill -9 PID杀死即可(PID为进程号)4. cqlsh操作
4.1 进入cqlsh环境

4.2 查看所有的keyspace

4.3 创建一个键空间ycsb
![]()
修改键空间
![]()
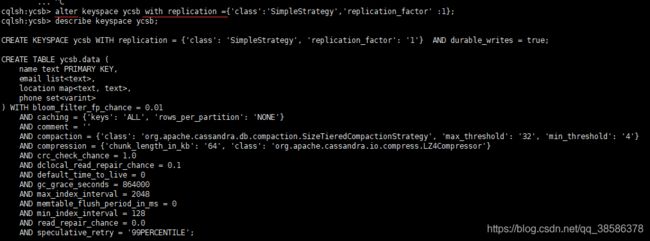
删除键空间

4.4 使用ycsb
![]()
4.5 创建表
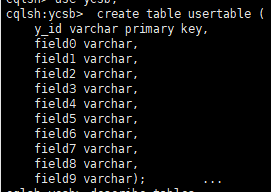
修改表
alter table table_name add column_name type(/drop column_name)
4.6 查看所有的列族即表

4.7 查看某一张表的属性

describe keyspace xxxkeyspace; 查看某个键空间,结果为这个键空间及keyspace下所有的table信息
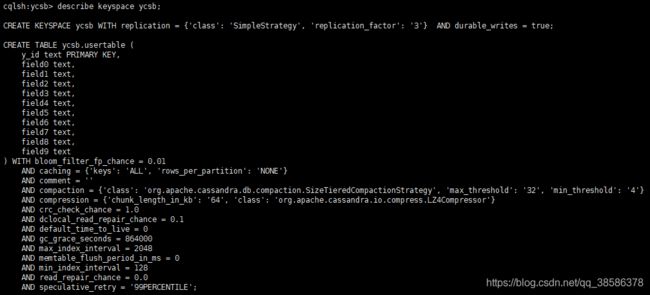
4.8 插入数据
![]()
4.9 查询数据

4.10 更新数据

4.11 删除数据

4.12 清空表

4.13 删除表
4.14 Cassandra集合
支持List、Set和Map数据类型。
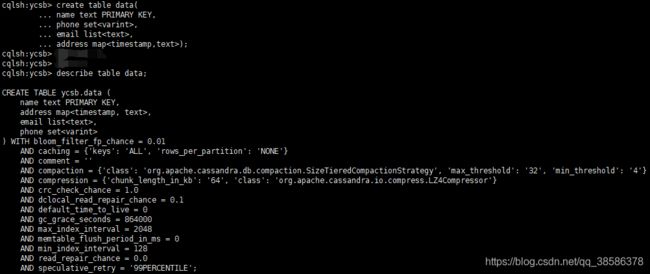
插入数据+更新数据
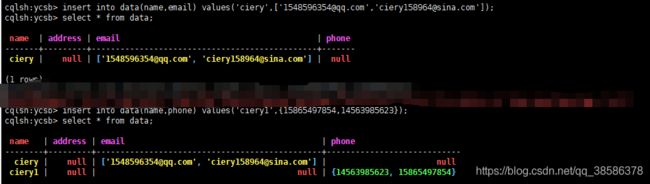
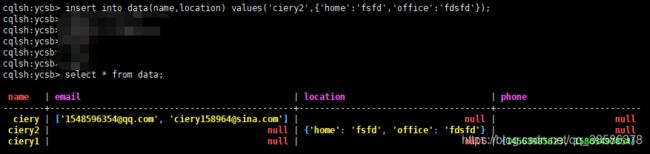
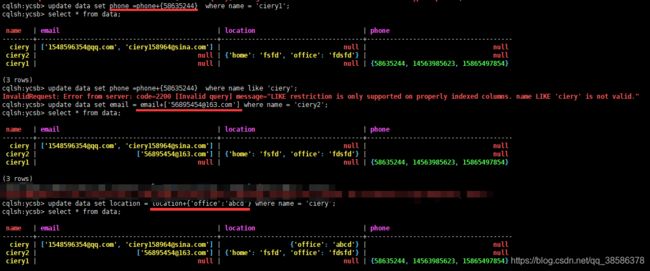
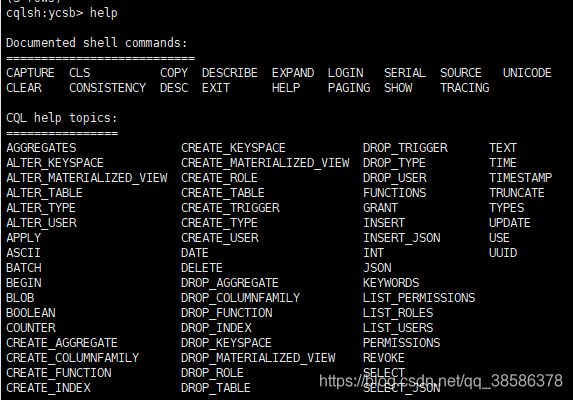
4.15 help命令
4.16 将结果输出到文本文档中(文本可以不用提前创建) 使用capture命令


可以capture off关掉此命令,停止将结果输出到指定的文本文档中

4.17 查看主机、端口号和版本号

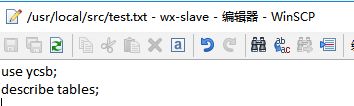
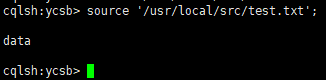
4.18 将文本文档导入cassandra
4.19 Cassandra支持用户自定义数据类型
参考:https://www.w3cschool.cn/cassandra/cassandra_cql_user_defined_datatypes.html
4.20 Java连接Cassandra
1. 添加依赖
com.datastax.cassandra
cassandra-driver-core
3.0.0
2. 创建集群和会话
Cluster cluster = Cluster.builder().addContactPoint("192.168.0.178").withPort(9042).build();
Session session = cluster.connect("ycsb");3. 编辑sql语句,不同需求对应不同的sql语句
String sql = "describe keyspace ycsb";4. 执行execute语句
session.execute(query);5. 处理结果
一般对遍历查询表的结果返回值为ResultSet,遍历根据需求进行处理即可
压力测试
使用ycsb压力测试工具对Cassandra进行压测。使用的是ycsb最新版0.17.0,官方说明此版本检验可测试Cassandra3.11.2,但我部署的是Cassandra3.11.6,想着死马当活马医试试,没想到也可以跑测试,简单记录一下测试过程。
1. 环境准备
下载yscb-cassandra-binding-0.17.0.tar.gz,解压然后就可直接使用。
2. Cassandra建立初始化表
根据官方给的readme.md文档可以直接参考在Cassandra中建立压力测试的初始化表
1. 创建键空间keyspace
2. 使用创建好的键空间keyspace
3. 创建压力测试的数据表(列族)
cqlsh> create keyspace ycsb
WITH REPLICATION = {'class' : 'SimpleStrategy', 'replication_factor': 3 };
cqlsh> USE ycsb;
cqlsh> create table usertable (
y_id varchar primary key,
field0 varchar,
field1 varchar,
field2 varchar,
field3 varchar,
field4 varchar,
field5 varchar,
field6 varchar,
field7 varchar,
field8 varchar,
field9 varchar);3. 根据压力测试需求修改YCSB的工作负载workload文档
根据自己的压力测试方案修改yscb下的workloads中的workload文档。
#实现类
workload=com.yahoo.ycsb.workloads.CoreWorkload
#域用来标识是否读取所有的字段
readallfields=false
#测试数据集的记录条数
recordcount=1000000
#测试过程中执行的操作总数
operationcount=3000000
#表示每条数据中的字段数,默认为10
fieldcount=10
#读比例(read/scan/update/delete的比例总和为1)
readproportion=0.3
#更新比例
updateproportion=0.7
#查询比例
scanproportion=0
#增加比例
insertproportion=0
#表示数据的分布情况,支持uniform,zipfian和latest
#uniform:当读一条记录的时候,任何一条记录被读取的概率都是相等的
#zipfian:选择记录的时候,遵循这个分布,这个分布的特点是有些记录就是更popular,有些记录不popular
#lastest:最近插入的数据最popular
requestdistribution=zipfian
4. 压力测试
#ycsb压力测试分为两步,分别是Load data和Run data
./bin/ycsb load cassandra-cql -P workloads/workload -p hosts=localhost -p columnfamily=usertable -threads 10 -s>load.dat
./bin/ycsb run cassandra-cql -P workloads/workload -p hosts=localhost -p columnfamily=usertable -threads 32 -s>run.dat5. 压测结果
从run.dat中可以获得此次压力测试的结果。

6. 拓展
在实际应用中如果修改Cassandra的配置参数然后进行压力测试,一般都是生成一定数量的样本,然后批量执行压力测试的load和run过程完成压力测试,并将每次压力测试的结果保存起来。这种情况下我们一般就会直接搞一个压力测试脚本文件,文件中主要的逻辑就是读样本文件,然后循环过压力测试的过程。
测试的过程就是:
1. 关闭cassandra
2. 然后读样本文件获取目标参数的名称:值,然后追加写入Cassandra的配置文件中(为方便多次测试,所以可以设置一个模板配置文件,每次先用模板覆盖此次测试的配置文件,然后追加此次目标参数的配置即可)
3. 打开cassandra
4. 开始load data和run data
5. 关闭cassandra
6. 读取run.dat压力测试的测试结果并将结果写入到文件中
注意脚本文件中应用的.sh文件都需要给chmod赋予读写权限才可使用,否则脚本运行会直接报Permission denied错误
总结
对于软件的安装部署,还是得先看官方文档的安装说明,保证基本的环境软件支持都是可以用的,不会出现版本不兼容的问题。另外有问题看软件日志/错误提示,根据提示上网搜索,然后尝试解决方法并进行总结。
要像一个海绵一样,遇到新知识新技能点多多看博客宏观掌握,迅速上手,勤于总结。对于自己找工作的技能点纵向学习发展多多联动思考并及时总结。