kafka深入浅出
一,介绍
Kafka是一种高吞吐量的分布式发布订阅消息系统,有如下特性:
1,通过O(1)的磁盘数据结构提供消息的持久化,这种结构对于即使数以TB的消息存储也能够保持长时间的稳定性能。
2,高吞吐量:即使是非常普通的硬件Kafka也可以支持每秒数百万的消息。
3,支持通过Kafka服务器和消费机集群来分区消息。
4,支持Hadoop并行数据加载。
二,适用场景
1、作为消息中间件【经管系统主要用途】
由于kafka的高吞吐量特性,能满足传输频次较高的消费场景,对于一些常规的消息系统,kafka是个不错的选择;partitons/replication和容错,可以使kafka具有良好的扩展性和性能优势.
2、网站活性跟踪
kafka可以作为"网站活性跟踪"的最佳工具;可以将网页/用户操作等信息发送到kafka中.并实时监控,或者离线统计分析等
3、日志收集中心
kafka的特性决定它非常适合作为"日志收集中心";application可以将操作日志"批量""异步"的发送到kafka集群中,而不是保存在本地或者DB中;kafka可以批量提交消息/压缩消息等,这对producer端而言,几乎感觉不到性能的开支.此时consumer端可以使hadoop等其他系统化的存储和分析系统.
三,详细介绍
kafka可以作为消息中间件,提供类似于rabbitmq,activeMQ的功能,但是kafka不是JMS的实现。
kafka在保存消息的时候按照topic进行分类,发送消息的为生产者【producer】,消费消息的为消费者【consumer】,生产者和消费者都可以做集群,此外,kafaka本身也可以做集群。无论是生产者消费者集群,还是kafka服务本身的集群,都依赖于zookeeper来保证集群的可用性。
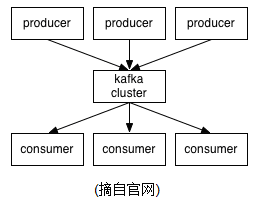
基本术语
topic
一个topic相当于一类消息,生产者发送一个topic消息到kafka,kafka将其存储在一个分区【partition】中【存储在哪个分区可以通过代码指定】。
partition【分区】
分区可以看作是物理存储,将每个消息存储在分区中。分区在存储层面是append log的方式,每个分区维护一个log文件,当有新的消息加进来的时候,就在文件的末尾添加即可,所以它的效率是极高的。每个消息在文件中有一个offset【long型数字】,它可以唯一标识一条消息,这也是每次读取消息的时候都会根据offset来记录当前读取的位置。需要注意的是,与MQ不同的是,消息被消费之后,这条消息并不会在log文件中删除,这就意味着可以利用程序重复消费。【log文件的自动给删除时间需要配置】
partition可以备份在多台kafka服务器上,保证系统的可用性
producer【生产者】
发送消息给kafka的应用称为生产者,生产者可以指定topic,也可以指定发送给到哪个partition【根据partition的分区策略,比如基于"round-robin"方式或者通过其他的一些算法等】。
消息到达分区的时候,会在分区的log文件追加一条记录,保存这条消息。
经管系统指定分区的方式:经管系统是根据传入的id字段,按照分区数量取模得到的即是具体分区。例如id=20,分区数量=6,则id为20的这条消息会被放在20%6=2这个分区里面
生产者常用的配置信息:
bootstrap.servers :kafka集群地址,ip+端口,以逗号隔开。不管这边配置的是什么服务器,客户端会使用所有的服务器。配置的列表只会影响初始发现所有主机。配置的格式应该是:ip:port,ip:port,因为配置的内容只是用于服务集群的初始发现(集群地址可能会变化),配置可以不包含所有的服务器(你可能需要配置多于一个,防止某个服务挂掉)
key.serializer: 实现Serializer接口的序列化类键
value.serializer: 实现Serializer接口的序列化类值
acks: 生产者认为一个请求完成,所需要kafka集群主服务的应答次数。这个配置控制已发送消息的持久性。下面是这个配置可能的值。acks=0:如果设置为0,生产者不会等待kafka的响应。消息会被立刻加到发送缓冲通道中,并且认为已经发送成功。这种情况下,不能保证kafka接收到了这条消息,retries配置不会生效,每条消息的偏移量都是1;acks=1:这个配置意味着kafka会把这条消息写到本地日志文件中,但是不会等待集群中其他机器的成功响应。这种情况下,在写入日志成功后,集群主机器挂掉,同时从机器还没来得及写的话,消息就会丢失掉。acks=all:这个配置意味着leader会等待所有的follower同步完成。这个确保消息不会丢失,除非kafka集群中所有机器挂掉。这是最强的可用性保证。
retries: 配置为大于0的值的话,客户端会在消息发送失败时重新发送。重试等同于在发送有异常时重新发送消息。如果不把max.in.flight.requests.per.connection设为1,重试可能会改变消息的顺序。两条消息同时发送到同一个分区,第一条失败了,并在第二条发送成功后重新发送,那么第二条消息可能在第一条消息前到达。
batch.size :当多条消息需要发送到同一个分区时,生产者会尝试合并网络请求。这会提高client和生产者的效率。如果消息体大于这个配置,生产者不会尝试发送消息。发送给kafka的消息包含不同的批次,每批发送给一个分区。批次大小太小的话可能会降低吞吐量。如果设为0,会禁用批处理功能。如果批次设置很大,可能会有些浪费内存,因为我们会预留这部分内存用于额外的消息。
client.id :发送请求给kafka时带上的生产者标识。目的是为了在ip+端口之外,通过逻辑上的应用名称跟踪请求,以便记录在kafka日志中。
partitioner.class :实现Partitioner接口的分区类
consumer【消费者】
从kafka服务器拉去消息的应用称为消费者,每个消费者都应该属于一个消费者组【consumer_group】,同一时间,同一个消费组中只会有一个消费者去消费partition中的消息,这样就保证了同一个partition中消息的顺序性,这也是经管系统用kafka作为消息中间件的主要原因【同一个id的数据只会保存在同一个partition中,所以同一个id的消息消费的时候是顺序的,这就不会发生同时修改同一份数据的时候的并发问题了】。需要注意的是,这个顺序性只是在partition的层面来看是顺序的,但是在topic的层面来看,依旧是无法保证的。
消费者常用配置信息:
bootstrap.servers:消费者初始连接kafka集群时的地址列表。不管这边配置的什么地址,消费者会使用所有的kafka集群服务器。消费者会通过这些地址列表,找到所有的kafka集群机器。
key.serializer: 实现Serializer接口的序列化类键
value.serializer: 实现Serializer接口的序列化类值
fetch.min.bytes:每次请求,kafka返回的最小的数据量。如果数据量不够,这个请求会等待,直到数据量到达最小指标时,才会返回给消费者。如果设置大于1,会提高kafka的吞吐量,但是会有额外的等待期的代价。
group.id:标识这台消费者属于那个消费组。如果消费者通过订阅主题来实现组管理功能,或者使用基于kafka的偏移量管理策略,这个配置是必须的。
session.timeout.ms:使用kafka集群管理工具时检测失败的超时时间。
enable.auto.commit:如果设为true,消费者的偏移量会定期在后台提交。
max.poll.records:一次poll调用返回的最大消息数量。
partition.assignment.strategy:使用组管理时,客户端使用的分区策略的类名,根据这个策略来进行消费分区。
kafka生产者发送消息核心源码
1.首先根据前面提到的生产者配合信息创建一个生产者
| 1 2 3 4 5 6 7 8 9 |
|
2.调用生产者的send方法发送消息
| 1 |
|
这是一个不带回调函数的send方法
3.send方法的具体代码
| 1 2 3 4 5 6 |
|
this.interceptors是拦截器,消息在发送到kafka服务器之前,会被拦截器拦截到,通过onSend方法做一些操作。我们可以自己写一个拦截类,实现ProducerInterceptors接口,重写其中的onSend方法
我们可以利用拦截器来做一些操作,例如加工消息的内容,等等
4.核心源码
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 |
|
个人在源码上写了一些注释