【代码使用】YOLOv3以及Gaussian YOLOv3模型转caffe的使用指南
目录
1.yolov3的darknet使用
2. yolov3训练自己的数据集
1)普通的训练
2)将anchor换成自己数据集匹配的值:
3. yolov3的caffe使用
1)转成caffe模型
2)使用caffe模型:
Gaussian yolov3使用
1).训练自己数据集
2)caffe使用:
其他:
环境:Ubuntu16.04
python2.7(caffe)
cuda8.0/9.0(8.0和9.0都一样)
opencv3.3.0/3.4.0(这俩都一样能成)
1.yolov3的darknet使用
- clone darknet
git clone https://github.com/pjreddie/darknet.git
- 修改darknet中的makefile文件(两处):
1.前5行,选择使用的配置,置1
GPU=1
CUDNN=1
OPENCV=1
OPENMP=0
DEBUG=0
2.nvcc,第24行
将:NVCC=nvcc
改:NVCC=/usr/local/cuda-9.0/bin/nvcc[自己的nvcc地址]- make编译一下:
cd darknet
make - demo的使用:
下载:yolov3.weights
wget https://pjreddie.com/media/files/yolov3.weights
或者用百度云,给个地址:https://pan.baidu.com/s/1kPxCb1baKOtkoKju-aJWeA 提取码:mv2w
./darknet detect cfg/yolov3.cfg yolov3.weights data/dog.jpg
2. yolov3训练自己的数据集
1)普通的训练
- 下载与训练模型
wget https://pjreddie.com/media/files/darknet53.conv.74
或者用百度云,给个地址:https://pan.baidu.com/s/1KvSmjrs2fMBNMvGtpwEb8A 提取码:8vtz
- 准备数据集
前提:数据集的标注方式与voc一样是xml文件
1.下载voc_label.py
wget https://pjreddie.com/media/files/voc_label.py
2.修改voc_label.py文件:
sets=[ ('2007', 'train'), ('2007', 'val'), ('2007', 'test')]
#删除2012
classes = ["car","person","bicycle"]
#改自己的类别3.修改./cfg/voc.data文件,刚刚我们得到生成文件:2007_test.txt,2007_train.txt,2007_val.txt,train.txt,train.all.txt;
classes= 3
train = /home/ubuntu247/liliang/algorithms/darknet/VOCdevkit/VOC2007/train.txt
valid = /home/ubuntu247/liliang/algorithms/darknet/VOCdevkit/VOC2007/2007_test.txt
names = data/voc.names
backup = backup4.修改./cfg/yolov3-voc.cfg(4处):
第一处:修改batch和subdivisions
[net]
# Testing 测试的时候把这个参数打开
#batch=1
#subdivisions=1
# Training 现在是训练的时候,打开这个部分
batch=64
subdivisions=16第2-4处:修改类别:先查找文件中“yolo”出现的3处
举其中一处为例,剩下两处都一样
[convolutional]
size=1
stride=1
pad=1
filters=24 #改这里 3*(类别数+5) 我的类别是3类,所以是24
activation=linear
[yolo]
mask = 6,7,8
anchors = 7, 15, 16, 18, 22, 32, 9, 40, 20, 71, 37, 39, 52, 65, 70, 110, 105, 208
classes=3#这里类别数
num=9
jitter=.3
ignore_thresh = .5
truth_thresh = 1
random=05.开始训练:
./darknet detector train cfg/voc.data cfg/yolov3-voc.cfg darknet53.conv.742)将anchor换成自己数据集匹配的值:
参考:https://blog.csdn.net/cgt19910923/article/details/82154401
- clone anchor生成工具:
git clone https://github.com/lars76/kmeans-anchor-boxes- 修改一下example.py代码:
import glob
import xml.etree.ElementTree as ET
import numpy as np
from kmeans import kmeans, avg_iou
ANNOTATIONS_PATH = "/home/ubuntu247/liliang/Data/INF_20191030/Annotations1107/"
CLUSTERS = 9
def load_dataset(path):
dataset = []
for xml_file in glob.glob("{}/*xml".format(path)):
tree = ET.parse(xml_file)
height = float(tree.findtext("./size/height"))
width = float(tree.findtext("./size/width"))
for obj in tree.iter("object"):
xmin = float(obj.findtext("bndbox/xmin")) / width
ymin = float(obj.findtext("bndbox/ymin")) / height
xmax = float(obj.findtext("bndbox/xmax")) / width
ymax = float(obj.findtext("bndbox/ymax")) / height
dataset.append([xmax - xmin, ymax - ymin])
return np.array(dataset)
if __name__ == '__main__':
data = load_dataset(ANNOTATIONS_PATH)
out = kmeans(data, k=CLUSTERS)
print("Accuracy: {:.2f}%".format(avg_iou(data, out) * 100))
print("Boxes:\n {}".format(out))
ratios = np.around(out[:, 0] / out[:, 1], decimals=2).tolist()
print("Ratios:\n {}".format(sorted(ratios)))- 运行代码:
sudo python example.py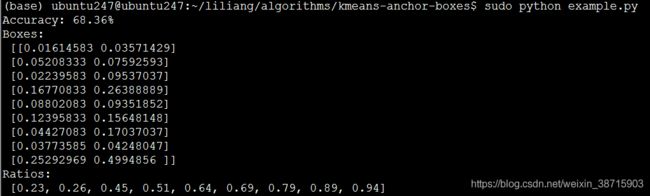
- 将boxes乘以416(图片resize后的大小),会得到9个box,再按照大小排列以后得到anchors
anchors = 7, 15, 16, 18, 22, 32, 9, 40, 20, 71, 37, 39, 52, 65, 70, 110, 105, 208-
更改./yolov3-voc.cfg文件:【之前提到的查找yolo存在的位置,更改3处】,每一处的anchors都替换成自己的值
以其中一处为例子,剩余两处一样的格式
[yolo]
mask = 0,1,2
anchors = 7, 15, 16, 18, 22, 32, 9, 40, 20, 71, 37, 39, 52, 65, 70, 110, 105, 208
classes=3
num=9
jitter=.3
ignore_thresh = .5
truth_thresh = 1
random=0- 重新开始训练:
./darknet detector train cfg/voc.data cfg/yolov3-voc.cfg darknet53.conv.743. yolov3的caffe使用
1)转成caffe模型
前提:刚刚训练得到了相应的weights,准备好yolo需要的layer--upsample_layer.cpp,upsample_layer.cu,upsample_layer.h
参考:https://blog.csdn.net/watermelon1123/article/details/82083522
将新的layer添加进去,完成caffe的准备工作。然后还要安装好pytorch。
- clone 转换工具:
git clone https://github.com/marvis/pytorch-caffe-darknet-convert- 开始转换:最后会得到 yolov3.prototxt yolov3.caffemodel
python2.7 darknet2caffe.py cfg/yolov3-voc.cfg yolov3-voc.weights yolov3.prototxt yolov3.caffemodel
将yolov3-voc.weights放在文件夹下
然后将yolov3-voc.cfg放在./cfg文件夹下面
yolov3.prototxt yolov3.caffemodel是要生成的caffe模型和pro文件命名2)使用caffe模型:
- clone使用工具:
git clone https://github.com/ChenYingpeng/caffe-yolov3
cd caffe-yolov3- 将生成的caffemodel和prototxt放在./caffemodel和./prototxt文件下【没有就建一个】
- 修改cmakelist.txt
"""全部都要改成自己的caffe路径"""
# build C/C++ interface
include_directories(${PROJECT_INCLUDE_DIR} ${GIE_PATH}/include)
include_directories(${PROJECT_INCLUDE_DIR}
/home/ubuntu247/liliang/caffe-ssd/include
/home/ubuntu247/liliang/caffe-ssd/build/include
)
file(GLOB inferenceSources *.cpp *.cu )
file(GLOB inferenceIncludes *.h )
cuda_add_library(yolov3-plugin SHARED ${inferenceSources})
target_link_libraries(yolov3-plugin
/home/ubuntu247/liliang/caffe-ssd/build/lib/libcaffe.so
/usr/lib/x86_64-linux-gnu/libglog.so
/usr/lib/x86_64-linux-gnu/libgflags.so.2
/usr/lib/x86_64-linux-gnu/libboost_system.so
/usr/lib/x86_64-linux-gnu/libGLEW.so.1.13
)- 如果你在训练中使用的是自己的anchors值,要修改anchors的值(yolo.cpp中),再进行编译;还有yolo.h中的classes数
/*
* Company: Synthesis
* Author: Chen
* Date: 2018/06/04
*/
#include "yolo_layer.h"
#include "blas.h"
#include "cuda.h"
#include "activations.h"
#include "box.h"
#include
#include
//yolov3
//float biases[18] = {10,13,16,30,33,23,30,61,62,45,59,119,116,90,156,198,373,326};
float biases[18] = {7, 15, 16, 18, 22, 32, 9, 40, 20, 71, 37, 39, 52, 65, 70, 110, 105, 208};
/*
* Company: Synthesis
* Author: Chen
* Date: 2018/06/04
*/
#ifndef __YOLO_LAYER_H_
#define __YOLO_LAYER_H_
#include
#include
#include
using namespace caffe;
const int classes = 3;
const float thresh = 0.5;
const float hier_thresh = 0.5;
const float nms_thresh = 0.5;
const int num_bboxes = 3;
const int relative = 1; - 编译
mkdir build
cd build
cmake ..
make -j12- 运行:
./x86_64/bin/detectnet ../prototxt/yolov3.prototxt ../caffemodel/yolov3.caffemodel ../images/dog.jpgGaussian yolov3使用
1).训练自己数据集
整体与yolov3的步骤一样,数据准备与yolov3一致。准备好数据以后:
- 将yolov3中的./cfg/voc.data,./data/voc.names,./cfg/yolov3-voc.cfg,分别复制到对应文件夹下面
- 对./cfg/yolov3-voc.cfg进行修改,将它重命名为./cfg/gaussian-yolov3-voc.cfg,查找yolo的位置,修改内容【3处】
还是以其中一处为例
[convolutional]
batch_normalize=1
size=3
stride=1
pad=1
filters=1024
activation=leaky
[convolutional]
size=1
stride=1
pad=1
filters=36 # 3*(类别数+5+4) 我的类别是3类,所以是36
activation=linear
[Gaussian_yolo]
mask = 6,7,8
anchors = 7, 15, 16, 18, 22, 32, 9, 40, 20, 71, 37, 39, 52, 65, 70, 110, 105, 208
classes=3
num=9
jitter=.3
ignore_thresh = .5
truth_thresh = 1
random=0- 开始训练:
./darknet detector train cfg/voc.data cfg/gaussian-yolov3-voc.cfg darknet53.conv.742)caffe使用:
- 转caffe的环境刚刚在yolov3中已经配置好了,所以一样的转模型就可以
python2.7 darknet2caffe.py cfg/gaussian-yolov3-voc.cfg gaussian-yolov3-voc.weights gaussian-yolov3.prototxt gaussian-yolov3.caffemodel
- 将caffe-yolov3中的yolo.cpp和yolo.h替换成gaussian_yolo_layer.h和gaussian_yolo_layer.cpp,重新编译
cd caffe-yolov3
rm -rf build
mkdir build
cd build
cmake ..
make -j12- 一样的放好模型以后,开始检测
./x86_64/bin/detectnet ../prototxt/gaussian-yolov3.prototxt ../caffemodel/gaussian-yolov3.caffemodel ../images/dog.jpg其他:
1.检测一个文件夹下面的多张图片(有txt标注),并计算map,修改caffe-yolov3中./detectnet/detectnet.cpp文件就可以了。
2.我自己修改的一些代码存放地址:
https://github.com/hualuluu/gaussian-yolov3-detection-caffe
【代码修改参考:https://github.com/ChenYingpeng/caffe-yolov3 yolo.cpp和yolo.h文件还有yolov3的源码】