Hadoop安装、伪分布式配置及运行Hadoop示例wordcount
本博客没有讲解Java的安装,如未安装Java请看这篇教程:https://blog.csdn.net/wyg1973017714/article/details/106474003
本博客默认所有读者均已安装Java环境
1、Hadoop下载
下载Hadoop请前往官网
官网地址:http://hadoop.apache.org/

点击Download跳转至下载页面
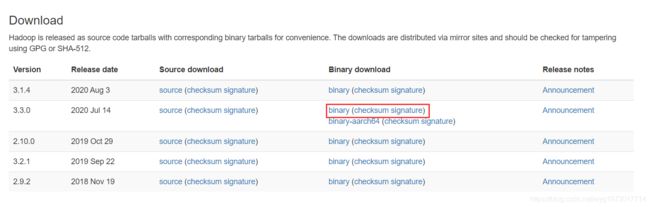
我这里选择的是3.3.0版本的Hadoop
2、将Hadoop上传至服务器
我这里使用的是阿里云服务器,使用xshell和xftp进行命令行以及文件上传的操作
我这里是通过xftp将Hadoop压缩包上传到了/home/hadoop目录下

3、安装Hadoop
使用如下命令直接在本目录下解压(读者可自行更换相应的目录):
tar -zxvf hadoop-3.3.0.tar.gz
解压完成以后需要配置环境变量,我这里通过vim的方式进行配置
首先,使用vim编辑/etc/profile。命令如下:
vim /etc/profile
进入vim编辑器以后,键入i表示在文档中写入数据,添加完成以后,使用Esc键退出insert模式,使用Shift+:进入底线命令模式,然后键入wq(保存并退出)即可。
在末尾添加如下配置:
export HADOOP_HOME=/home/hadoop/hadoop-3.3.0/ #替换为自己的安装目录
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
配置完成后运行如下命令使配置生效
source /etc/profile
然后需要修改配置文件yarn-env.sh和hadoop-env.sh,这两个文件在安装目录下的/etc/hadoop目录下,如图所示:

如果不习惯vim编辑器的话,可以通过使用如下命令进行修改:
echo "export JAVA_HOME=/usr/java/latest" >> /home/hadoop/hadoop-3.3.0/etc/hadoop/yarn-env.sh
echo "export JAVA_HOME=/usr/java/latest" >> /home/hadoop/hadoop-3.3.0/etc/hadoop/hadoop-env.sh
以上配置完成后可以测试hadoop是否安装成功,运行hadoop version命令可查看安装的版本,出现下图的内容即安装成功

4、Hadoop伪分布式配置
1、修改core-site.xml文件
在Hadoop安装目录下使用vim编辑器
vim etc/hadoop/core-site.xml
或者指定全局路径
vim /home/hadoop/hadoop-3.3.0/etc/hadoop/core-site.xml
键入i,进行编辑模式
在< configuration> < /configuration>节点中添加如下内容,具体目录要进行更改
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/home/hadoop/hadoop-3.3.0/tmp</value>
<description>location to store temporary files</description>
</property>
键入Esc,退出编辑模式,通过Shift+:进入底线命令模式,键入wq,保存并退出
2、修改hdfs-site.xml
vim etc/hadoop/hdfs-site.xml
修改内容如下:
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/home/hadoop/hadoop-3.3.0/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/home/hadoop/hadoop-3.3.0/tmp/dfs/data</value>
</property>
3、修改yarn-site.xml文件
vim etc/hadoop/yarn-site.xml
添加如下内容:
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
4、修改mapred-site.xml
vim etc/hadoop/mapred-site.xml
添加如下内容
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.application.classpath</name>
<value>
$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/*:$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/lib/*
5、设置SSH免密登录
执行如下命令创建公钥和私钥:
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
回车即可
执行如下命令,将公钥添加到authorized_keys文件中
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
chmod 0600 ~/.ssh/authorized_keys
执行如下命令,如果不需要密码就可以连上本地账户,那么此设置成功
ssh localhost
6、初始化Hadoop
执行如下命令,初始化namenode
hadoop namenode -format
多次初始化会出现启动失败的情况,因此切记不要多次初始化
执行如下命令,启动Hadoop
start-dfs.sh
start-yarn.sh
通过jps命令查看进程
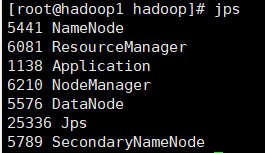
7、运行wordcount示例
首先在linux创建文件,我这里创建的是myfile文件
写入如下内容:
hello world hello hadoop
wyg hadoop wdn hello world
java count test spring elasticsearch
然后将这个文件上传至Hadoop
通过如下命令创建Hadoop文件目录,wordcount文件输入目录
hadoop fs -mkdir -p /input/wordcount
结果输出目录
hadoop fs -mkdir -p /output
将刚才创建的文件上传至/input/wordcount目录下
hadoop fs -put /home/hadoop/myfile /input/wordcount
进入到Hadoop安装目录下的share/hadoop/mapreduce
执行如下命令即可运行:
hadoop jar hadoop-mapreduce-examples-3.3.0.jar wordcount /input/wordcount /output/wordcount
运行截图
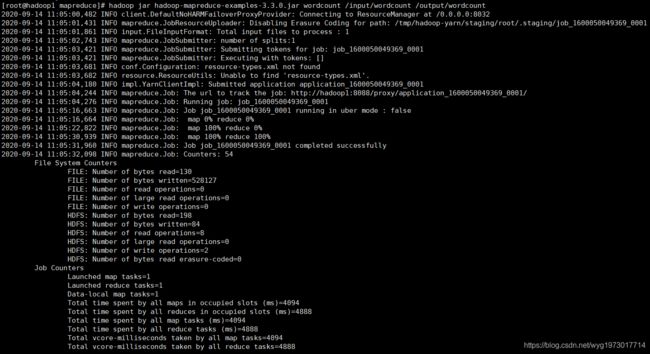
结果

参考
https://www.cnblogs.com/zingp/p/11223220.html
https://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-common/SingleCluster.html
https://zhuanlan.zhihu.com/p/225589920