Java基础--------(4)集合Conllection
一、简述
Collection
Java集合框架Collection在java.util包下。
集合用来存储一组元素,与数组作用类似,Collection是所有集合的父接口,规定了集合所应当具备的功能。
Collection接口是List、 Set、和Queue接口的父接口。
java.util.List:可重复集,有放入顺序.
java.util.Set:不可重复集,无放入顺序,元素虽然无放入顺序,但是元素在set中的位置是有该元素的HashCode决定的,其位置其实是固定的。
java.util.Queue:模拟了队列这种数据结构,队列通常是“先进先出”的数据结构,通常不允许随机访问队列中的元素。
Map
java.util.Map是为查找而设计的集合, 用于存储key-value对象数据, 使用时候根据key查找value.
二、常用集合
常用集合类的继承结构:
Collection<--List<--ArrayList
Collection<--List<--LinkedList
Collection<--List<--Vector
Collection<--List<--Vector<--Stack
Collection<--Set<--HashSet
Collection<--Set<--HashSet<--LinkedHashSet
Collection<--Set<--SortedSet<--TreeSet
Collection<--Queue<--Deque<--LinkedList
Collection<--Queue<--AbstractQueue<--PriorityQueue
Map<--SortedMap<--TreeMap
Map<--HashMap
Map<--Hashtable
1. List接口
List是有序的Collection,使用此接口能够精确的控制每个元素插入的位置。和数组一样能够使用索引来访问List中的元素。
(1)ArrayList 和Vector
主要区别:ArrayList是线程不安全的,Vector是线程安全的。
他们底层都是靠数组实现的,由于ArrayList不是线程安全的,所以性能好一点,但是还是会受数组性能的限制。
(2)LinkedList
LinkedList不是基于数组的。
它每一个节点(Node)都包含两方面的内容:
1.节点本身的数据(data);
2.下一个节点的信息(nextNode)。
所以,在添加删除数据时,LinkedList性能要好些,因为只需要修改nextNode的信息就好。基于数组的List查询性能更好。
(3)Stack
Stack是Vector的子类,它用于模拟“栈”这种数据结构,栈通常是先进后出的容器,就像是一边开口的容器。
2. Set接口
Set是一种不包含重复的元素且无插入顺序的Collection,内部通过hashcode维持着顺序。
(1)HashSet
通过源码可以看出它是基于HashMap来实现的,底层采用HashMap来保存元素,构造函数会先创建一个初始容量16,加载因子0.75的HashMap。
特点:
1)不保证元素的排列顺序,有可能变化;
2)HashSet不是同步的;
3)集合元素可以为空。
(2)LinkedHashSet
HashSet的一个子类,一个链表。
(3)TreeSet
SortedSet的子类,它不同于HashSet的根本就是TreeSet是有序的。它是通过SortedMap来实现的。
3. Queue接口
Queue是一种先进先出(FIFO)的数据结构。它只允许在表的前端(front)进行删除操作,而在表的后端(rear)进行插入操作。
(1)Deque
双端队列,既具有队列的特征,也具有栈stack的特征,Dueue接口是Queue的子接口。
(2)PriorityQueue
优先级队列,是不同于先进先出队列的另一种队列。每次从队列中取出的是具有最高优先权的元素。
4. Map接口
(1)HashMap
特点:线程不安全,元素可为空
实现了Map接口,继承AbstractMap类,底层通过数组和链表实现,默认初始容量为16,默认负载因子为0.75。(负载因子:负载因子=map的size/初始化容量)
HashMap散列表查找性能非常好
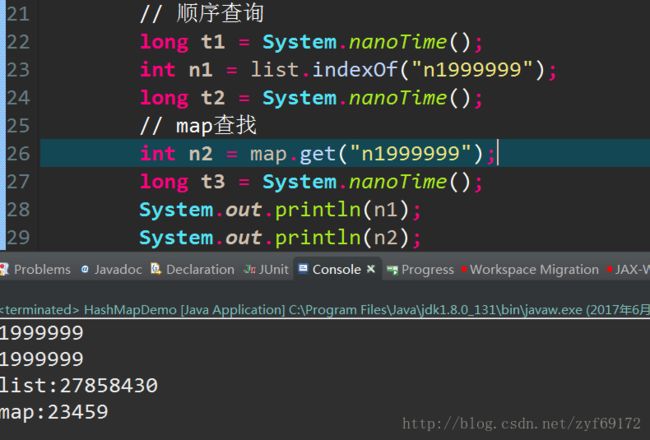
HashMap查询原理
1.先根据key的hashcode 计算出数组下标位置
2.在根据下标位置找到被查找元素,但是很有可能不同的key计算后hashcode值一样,这就出现了哈希冲突,HashMap是通过链表解决的,两个不同的key以链表形式放到了同一个数组的同一下标位置,所以需要用equals方法验证哪个是你在查找的。
所以在使用HashMap和set存放数据时,要重写hashcode方法和equals方法,切必须保证 equals和hashCode方法是一对方法,即
如果两个对象相等(equals) 则 其HashCode一样
如果两个对象不等, 其hashCode一般不同.
当HashMap中的数据超过了默认负载因子定义的容量,那么将会创建原来HashMap大小的两倍的数组,来重新调整map的大小,并将原来的对象放入新的数组中,这种操作叫做rehash,但是它会比较消耗性能,所以,在使用HashMap前,最好能确定要存放的数据量。
(2)Hashtable
特点:线程安全,元素不可为空
和HashMap相比,最大区别是线程安全,所以性能差点,而且key和value都不可以为null,但是HashMap可以
(3)TreeMap
特点:底层是二叉树数据结构,线程不同步,可用于给Map集合中的键进行排序。