爬虫入门(4)—— Selenium的使用
文章目录
- 1.selenium
-
- 1.1.安装
- 1.2.采用百度进行搜索
-
- 1.2.1.结果
- 1.3.selenium方法的使用
-
- 1.3.1.通过ID查找元素
- 1.3.2.通过Name查找元素
- 1.3.3.通过XPath查找元素
- 1.3.4.通过链接文本获取超链接
- 1.3.5.通过标签名查找元素
- 1.3.6.通过Class name 定位元素
- 1.3.7.通过CSS选择器查找元素
- 1.3.8.webDriver的使用
- 1.4.页面对象
-
- 1.4.1.测试用例
-
- 1.4.1.1.main.py的内容
- 1.4.1.2.page.py
- 1.4.1.3.element.py
- 1.4.1.4.locators.py
- 1.4.1.5.测试效果
- reference
前面几节,我们学习了用 requests 构造页面请求来爬取静态网页中的信息以及通过 requests 构造 Ajax 请求直接获取返回的 JSON 信息。
还记得前几节,我们在构造请求时会给请求加上浏览器 headers,目的就是为了让我们的请求模拟浏览器的行为,防止被网站的反爬虫策略限制。今天要介绍的 Selenium 是一款强大的工具,它可以控制我们的浏览器,这样一来程序的行为就和人类完全一样了。
通过使用 Selenium 可以解决几个问题:
- 页面内容是由 JavaScript 动态生成,通过 requests 请求页面无法获取内容。
- 爬虫程序被反爬虫策略限制
- 让程序的行为和人一样
1.selenium
1.1.安装
pip install selenium
文档:
https://selenium-python-zh.readthedocs.io/en/latest/index.html
各种浏览器版本对应的selenium的driver版本。
http://npm.taobao.org/mirrors/chromedriver/
查看浏览器版本:
1.打开“谷歌浏览器”,点击右上角“三个点”。
2.选择“帮助”选项,点击“关于Google Chrome”。
3.进入界面后即可看到谷歌浏览器版本。
谷歌浏览器版本不对:
问题:selenium.common.exceptions.SessionNotCreatedException: Message: session not created: This version of ChromeDriver only supports Chrome version 81
1.2.采用百度进行搜索
from selenium import webdriver
driver = webdriver.Chrome() # 打开谷歌浏览器
driver.get('https://www.baidu.com/') # 输入网页地址
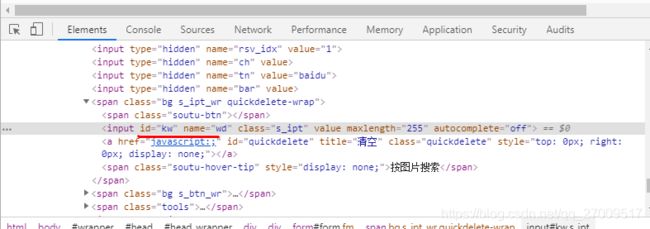
search_input = driver.find_element_by_id("kw") # 获取到百度搜索框
search_input.send_keys("刘亦菲") # 输入要搜索的关键词
submit = driver.find_element_by_id("su") # 获取百度一下的搜索按钮
submit.click() # 点击搜索
su的id查找如下:

kd的id查找如下:
1.2.1.结果

1.3.selenium方法的使用
在一个页面中有很多不同的策略可以定位一个元素。在你的项目中, 你可以选择最合适的方法去查找元素。Selenium提供了下列的方法给你:
find_element_by_id
find_element_by_name
find_element_by_xpath
find_element_by_link_text
find_element_by_partial_link_text
find_element_by_tag_name
find_element_by_class_name
find_element_by_css_selector
一次查找多个元素 (这些方法会返回一个list列表):
find_elements_by_name
find_elements_by_xpath
find_elements_by_link_text
find_elements_by_partial_link_text
find_elements_by_tag_name
find_elements_by_class_name
find_elements_by_css_selector
1.3.1.通过ID查找元素
当你知道一个元素的 id 时,你可以使用本方法。在该策略下,页面中第一个该 id 元素 会被匹配并返回。如果找不到任何元素,会抛出 NoSuchElementException 异常。
作为示例,页面元素如下所示:
<html>
<body>
<form id="loginForm">
<input name="username" type="text" />
<input name="password" type="password" />
<input name="continue" type="submit" value="Login" />
form>
body>
<html>
可以这样查找表单(form)元素:
login_form = driver.find_element_by_id(‘loginForm’)
1.3.2.通过Name查找元素
当你知道一个元素的 name 时,你可以使用本方法。在该策略下,页面中第一个该 name 元素 会被匹配并返回。如果找不到任何元素,会抛出 NoSuchElementException 异常。
作为示例,页面元素如下所示:
<html>
<body>
<form id="loginForm">
<input name="username" type="text" />
<input name="password" type="password" />
<input name="continue" type="submit" value="Login" />
<input name="continue" type="button" value="Clear" />
form>
body>
<html>
name属性为 username & password 的元素可以像下面这样查找:
username = driver.find_element_by_name(‘username’)
password = driver.find_element_by_name(‘password’)
这会得到“Login” 按钮,因为他在 “Clear” 按钮之前:
continue = driver.find_element_by_name(‘continue’)
1.3.3.通过XPath查找元素
XPath教程:https://www.w3school.com.cn/xpath/index.asp
XPath是XML文档中查找结点的语法。因为HTML文档也可以被转换成XML(XHTML)文档, Selenium的用户可以利用这种强大的语言在web应用中查找元素。 XPath扩展了(当然也支持)这种通过id或name属性获取元素的简单方式,同时也开辟了各种新的可能性, 例如获取页面上的第三个复选框。
使用XPath的主要原因之一就是当你想获取一个既没有id属性也没有name属性的元素时, 你可以通过XPath使用元素的绝对位置来获取他(这是不推荐的),或相对于有一个id或name属性的元素 (理论上的父元素)的来获取你想要的元素。XPath定位器也可以通过非id和name属性查找元素。
绝对的XPath是所有元素都从根元素的位置(HTML)开始定位,只要应用中有轻微的调整,会就导致你的定位失败。 但是通过就近的包含id或者name属性的元素出发定位你的元素,这样相对关系就很靠谱, 因为这种位置关系很少改变,所以可以使你的测试更加强大。
作为示例,页面元素如下所示:
<html>
<body>
<form id="loginForm">
<input name="username" type="text" />
<input name="password" type="password" />
<input name="continue" type="submit" value="Login" />
<input name="continue" type="button" value="Clear" />
form>
body>
<html>
可以这样查找表单(form)元素:
login_form = driver.find_element_by_xpath("/html/body/form[1]")
login_form = driver.find_element_by_xpath("//form[1]")
login_form = driver.find_element_by_xpath("//form[@id=‘loginForm’]")
绝对定位 (页面结构轻微调整就会被破坏)
HTML页面中的第一个form元素
包含 id 属性并且其值为 loginForm 的form元素
username元素可以如下获取:
username = driver.find_element_by_xpath("//form[input/@name=‘username’]")
username = driver.find_element_by_xpath("//form[@id=‘loginForm’]/input[1]")
username = driver.find_element_by_xpath("//input[@name=‘username’]")
第一个form元素中包含name属性并且其值为 username 的input元素
id为 loginForm 的form元素的第一个input子元素
第一个name属性为 username 的input元素
“Clear” 按钮可以如下获取:
clear_button = driver.find_element_by_xpath("//input[@name=‘continue’][@type=‘button’]")
clear_button = driver.find_element_by_xpath("//form[@id=‘loginForm’]/input[4]")
1.3.4.通过链接文本获取超链接
当你知道在一个锚标签中使用的链接文本时使用这个。 在该策略下,页面中第一个匹配链接内容锚标签 会被匹配并返回。如果找不到任何元素,会抛出 NoSuchElementException 异常。
作为示例,页面元素如下所示:
<html>
<body>
<p>Are you sure you want to do this?p>
<a href="continue.html">Continuea>
<a href="cancel.html">Cancela>
body>
<html>
continue.html 超链接可以被这样查找到:
continue_link = driver.find_element_by_link_text(‘Continue’)
continue_link = driver.find_element_by_partial_link_text(‘Conti’)
1.3.5.通过标签名查找元素
当你向通过标签名查找元素时使用这个。 在该策略下,页面中第一个匹配该标签名的元素 会被匹配并返回。如果找不到任何元素,会抛出 NoSuchElementException 异常。
作为示例,页面元素如下所示:
<html>
<body>
<h1>Welcomeh1>
<p>Site content goes here.p>
body>
<html>
h1 元素可以如下查找:
heading1 = driver.find_element_by_tag_name(‘h1’)
1.3.6.通过Class name 定位元素
当你向通过class name查找元素时使用这个。 在该策略下,页面中第一个匹配该class属性的元素 会被匹配并返回。如果找不到任何元素,会抛出 NoSuchElementException 异常。
作为示例,页面元素如下所示:
<html>
<body>
<p class="content">Site content goes here.p>
body>
<html>
p 元素可以如下查找:
content = driver.find_element_by_class_name(‘content’)
1.3.7.通过CSS选择器查找元素
当你向通过CSS选择器查找元素时使用这个。 在该策略下,页面中第一个匹配该CSS 选择器的元素 会被匹配并返回。如果找不到任何元素,会抛出 NoSuchElementException 异常。
作为示例,页面元素如下所示:
<html>
<body>
<p class="content">Site content goes here.p>
body>
<html>
p 元素可以如下查找:
content = driver.find_element_by_css_selector(‘p.content’)
Selenium Tips: CSS Selectors:
https://saucelabs.com/resources/articles/selenium-tips-css-selectors
1.3.8.webDriver的使用
浏览器的类型:
webdriver.Firefox
webdriver.FirefoxProfile
webdriver.Chrome
webdriver.ChromeOptions
webdriver.Ie
webdriver.Opera
webdriver.PhantomJS
webdriver.Remote
webdriver.DesiredCapabilities
webdriver.ActionChains
webdriver.TouchActions
webdriver.Proxy
1.4.页面对象
一个页面对象表示在你测试的WEB应用程序的用户界面上的区域。
使用页面对象模式的好处:
创建可复用的代码以便于在多个测试用例间共享
减少重复的代码量
如果用户界面变化,只需要修改一处
1.4.1.测试用例
下面是一个在python.org网站搜索一个词并保证一些结果可以找到的测试用例。
1.4.1.1.main.py的内容
import unittest
from selenium import webdriver
import page
class PythonOrgSearch(unittest.TestCase):
"""A sample test class to show how page object works"""
def setUp(self):
self.driver = webdriver.Chrome()
# 定义验证页面
self.driver.get("http://www.python.org")
def test_search_in_python_org(self):
"""
测试python.org的搜索部分,查找词pycon,然后验证是否有结果,
"""
# 加载 Python.org的主页面
main_page = page.MainPage(self.driver)
# 验证python.org在页面上
assert main_page.is_title_matches(), "python.org title doesn't match."
# 设置搜索文本为:"pycon"
main_page.search_text_element = "pycon"
main_page.click_go_button()
search_results_page = page.SearchResultsPage(self.driver)
# 验证搜索结果不为空
assert search_results_page.is_results_found(), "No results found."
def tearDown(self):
import time
time.sleep(5)
self.driver.close()
if __name__ == "__main__":
unittest.main()
1.4.1.2.page.py
页面对象为每个网页模拟创建出一个对象。 按照此技术,在测试代码和技术实施之间的一个分离层被创建。
这个 page.py 看起来像这样:
# coding: utf-8
# Author: shelley
# 2020/9/15,10:04
# from element import BasePageElement
# from locators import MainPageLocators
import element
import locators
class SearchTextElement(element.BasePageElement):
"""This class gets the search text from the specified locator"""
# The locator for search box where search string is entered
# find_element_by_name的name为q
locator = 'q'
class BasePage(object):
"""Base class to initialize the base page that will be called from all pages"""
def __init__(self, driver):
self.driver = driver
class MainPage(BasePage):
"""Home page action methods come here. I.e. Python.org"""
#Declares a variable that will contain the retrieved text
search_text_element = SearchTextElement()
def is_title_matches(self):
"""Verifies that the hardcoded text "Python" appears in page title"""
return "Python" in self.driver.title
def click_go_button(self):
"""Triggers the search"""
element = self.driver.find_element(*locators.MainPageLocators.GO_BUTTON)
element.click()
class SearchResultsPage(BasePage):
"""Search results page action methods come here"""
def is_results_found(self):
# Probably should search for this text in the specific page
# element, but as for now it works fine
return "No results found." not in self.driver.page_source
1.4.1.3.element.py
页面元素
这个 element.py 看起来像这样:
# coding: utf-8
# Author: shelley
# 2020/9/15,10:05
from selenium.webdriver.support.ui import WebDriverWait
class BasePageElement(object):
"""Base page class that is initialized on every page object class."""
def __set__(self, obj, value):
"""Sets the text to the value supplied"""
driver = obj.driver
WebDriverWait(driver, 100).until(
lambda driver: driver.find_element_by_name(self.locator))
driver.find_element_by_name(self.locator).send_keys(value)
def __get__(self, obj, owner):
"""Gets the text of the specified object"""
driver = obj.driver
WebDriverWait(driver, 100).until(
lambda driver: driver.find_element_by_name(self.locator))
element = driver.find_element_by_name(self.locator)
return element.get_attribute("value")
1.4.1.4.locators.py
其中一个做法是,从它们正在使用的地方分离定位字符。在这个例子中,同一页面的定位器属于同一个类。
这个 locators.py 看起来像这样:
from selenium.webdriver.common.by import By
class MainPageLocators(object):
"""A class for main page locators. All main page locators should come here"""
GO_BUTTON = (By.ID, 'submit')
class SearchResultsPageLocators(object):
"""A class for search results locators. All search results locators should come here"""
pass
1.4.1.5.测试效果


reference
https://mp.weixin.qq.com/s/YJGjZkUejEos_yJ1ukp5kw