Kubernetes Notes以及最新的k3s安装介绍
一.快速安装入门
1.docker
2.kubernetes
3.为kubectl配置别名和命令行补全
4.卸载k8s
5.K3s – a lightweight Kubernetes
6.资源的清理工作及删除k3s
7.利用Vagrant Cloud现有资源实践k8s
二.k8s Notes
1.kubernetes配置文件
2.k8s相关问题修复
- 2.1etcd connection refuse问题修复
- 2.2node:no resource found问题修复
一.快速安装入门
1.docker
sudo yum updatesudo yum list docker
sudo yum install dockersudo systemctl enable docker.service
sudo sytemctl start docker.service
sudo systemctl status docker.servicesudo usermod -aG docker ${USER}
注意:如果更改了已登陆系统账户所属的用户组,该用户必须退出系统后在登陆,组关系的更改才能生效rpm -ql docker | less
Notes:
首先在一个终端中运行:journalctl -f -u docker
打开另一个终端运行docker的相关命令:
docker search | pull | run
注意区别registry和repository:例如对于docker hub registry来说repository应为你的DockerHubID
registry:早期中所有系统中的registry都为Docker Hub Registry(docker.io),但由于大企业连接公共registry的风险问题,RHEL以将默认的Docker Hub Registry改为了registry.access.redhat.com,我在ubuntu中并为找到相关可以自己修改的registry项,在fedora中应可以找到,下面就来找一下。
首先找出Docker的相关配置文件:
sudo find /etc -name docker

ls -alF /etc/sysconfig/docker
ls -alF /etc/docker
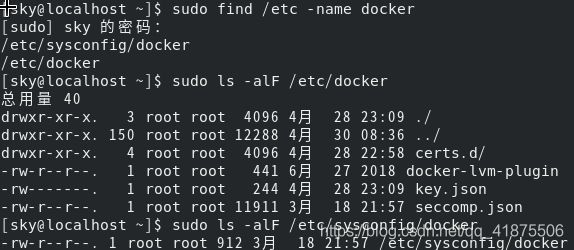 可以看出相关的配置应该在/etc/sysconfig/docker文件中
可以看出相关的配置应该在/etc/sysconfig/docker文件中
less /etc/sysconfig/docker
 由标注处可以看出原本可以在该文件中设置的registry改为了在
由标注处可以看出原本可以在该文件中设置的registry改为了在/etc/containers/registries.conf中进行设置
man 5 registries.conf:可查看联机帮助页
less /etc/containers/registries.conf

[registries.search]
registries = ['docker.io', 'registry.fedoraproject.org', 'quay.io', 'registry.access.redhat.com', 'registry.centos.org']
可以看出fedora中的第一个查找的registry为docker.io即Docker Hub Registry,但其后又有多个按顺序查找的registry,其中就有RHEL的,还有fedora项目自身的以及centos的registry。
2.kubernetes
sudo yum updateyum list kubernetes
sudo yum install -y --enablerepo=updates-testing kubernetes etcd
若你安装的k8s集群不稳定,去掉–enablerepo项sudo systemctl stop firewalld
sudo systemctl disable firewalld
修改/etc/kubernetes/apiserver文件:去掉ACL中的ServiceAccount项MSERVICES="etcd kube-apiserver kube-controller-manager kube-scheduler"
sudo systemctl restart $MSERVICES
sudo systemctl enable $MSERVICES
sudo systemctl is-active $MSERVICES
sudo systemctl is-enabled $MSERVICESNSERVICES="kube-proxy kubelet docker"
sudo systemctl restart $NSERVICES
sudo systemctl enable $NSERVICES
sudo systemctl is-active $NSERVICES
sudo systemctl is-enabled $NSERVICESkubectl cluster-info
kubectl get node
kubectl describe node 127.0.0.1
Notes
找出k8s的相关配置文件,自行查看


3.为kubectl配置别名和命令行补全
docker内置了命令行补全功能,而k8s需要我们自己配置才可以使用命令行补全功能。
创建别名
你可以一直使用kubectl可执行文件的全名(可以使用type命令查看kubectl的可执行文件:type kubectl)
![]()
但是你可以利用linux中的别名特性,为kubectl添加一个较短的别名,如k,这样就不用每次都输入kubectl了。
编辑~/.bashrc文件,添加如下内容:
alias k=kubectl

编辑完成后保存退出,在terminal中运行alias k命令,查看你添加的别名是否生效。注意:若你在编辑bashrc文件前已经打开了一个terminal,请在打开一个新的terminal运行上述命令才能看到生效的改动。

为kubectl配置tab补全
kubectl可以配置bash和zsh shell的代码补全。
tab不仅可以补全命令名,还能补全对象名。
首先运行:kubectl
可以查看到kubectl的所有可用命令
 看到其中的
看到其中的completion命令,该命令即为kebectl的命令行自动补全的脚本文件,也可以利用:kubectl completion bash | less查看该脚本文家的内容。
原本:docker内置了命令行补全功能,而k8s需要我们自己配置才可以使用命令行补全功能。 ,但是现在看来最新版的Fedora中已经内置了k8s的kubectl命令行tab补全功能,而当初在centos中是需要我们自己下载这个名为bashcompletion的包来启用bash中的tab命令行补全功能。
那么既然如此如果你使用的是centos且用的是配置国内k8s的yum源的方式,你可以使用如下方法来启用k8s的kubectl命令行tab补全功能:
-
首先安装bashcompletion包
yum updates
yum list bashcompletion
如果显示了相关的包,安装该包即可,如果没有显示,证明你的/etc/yum.repos.d中搜索不到该包,那么你就可以放弃下面的操作了,你需要运行:kubectl bashcompletion -h自己查看相关安装说明。
如果你的系统中不可以运行上述命令,那么你需要自己查看一下你到底能否安装,下面是官网的相关说明:
Detailed instructions on how to do this are available here: https://kubernetes.io/docs/tasks/tools/install-kubectl/#enabling-shell-autocompletion
搜索到该包的,进行包的安装:
yum install -y bashcompletion -
然后运行:
source < (kubectl completion bash)
注意:若想让上述命令永久有效,需将上述命令添加到/etc/profile或是$HOME/.bash_profile或是$HOME/.bashrc文件中。
我将上述命令添加到了~/.bashrc文件中而不是/etc/profile文件中,因为这样当我重新开启一个终端时上述命令即可生效,而若是添加到了只有登录式shell才会扫描的/etc/profile文件中,你需要重启电脑才能使上述命令生效。
这里存在的一个问题是:tab命令自动补全只有在使用完整的kubectl命令时才有效,当时用别名时不会有效:这需要改变kubectl completion的输出来修复:
即最终在你的~/.bashrc文件中添加如下内容:
source <(kubectl completion bash | sed s/kubectl/k/g)

-
现在你可以打开一个新的终端运行下述命令以检查你的tab命令补全是否生效:
kubcg no
k gno
4.卸载k8s
yum list installed kubernetes
sudo yum erase kubernetes


Notes
yum remove :只删除软件包,而保留配置文件和数据。
yum erase :删除软件包和他所有的文件。
5.K3s – a lightweight Kubernetes
由于使用了fedora,我发现了他的一个更轻量级的k8s替代方案:k3s
k3s官方主页:https://fedoramagazine.org/kubernetes-on-fedora-iot-with-k3s/
安装
安装k3s仅需运行一个简单的脚本文件,该脚本文件会自动帮你完成k8s的相关安装部署。
curl -sfL https://get.k3s.io | sh -

kubectl get node

使用
当上述命令运行结束后,我们就拥有了一个k8s集群。
下面运行一些命令来检查该集群。
kubectl create deployment my-server --image nginx
![]()
kubectl get pods
发现pod的状态一直为正在创建状态,利用
kubectl describe pod
查看pod创建的详细记录
 查看其Eevnts部分,该部分给出了pod未创建成功的原因:我们无法访问grc.io
查看其Eevnts部分,该部分给出了pod未创建成功的原因:我们无法访问grc.io
 进而还可运行
进而还可运行journalctl -f -u docker


 无法从google下载相关的镜像,看来我们需要配置国内相关的镜像服务。。。
无法从google下载相关的镜像,看来我们需要配置国内相关的镜像服务。。。
6.资源的清理工作及删除k3s
资源的清理
首先说一下我们的 创建步骤:
- service.yaml
- deployment.yaml
- 核实node以准配好:在master上创建service及deployment之前,需要先检查以下该node是否为ready状态。在大规模的生产集群中,k8s会帮你完成所有的这些检查。
kubectl get node kubectl create xxx-service.yaml
kubectl create xxx-deployment.yaml- 检查service,deployment,pod是否准备好
kubectl get service
kubectl get deploy
kubectl get endpoints
kubectl get pod
删除步骤
- 首先删除depolymet
kubectl get deploy
kubectl delete
Notes:注意不要删除pod,由于deployment创建了ReplicaSet,而ReplicaSet如同早期的ReplicationController一样,它们会控制pod的数量,使其一直保持在期望个数内,因此只有删除deployment或是RC才可以删除掉pod。 - 删除service
kubectl get svc
kubectl delete - 检查是否删除
kubectl get pod
kubectl get deploy
kubectl get svc
至此我们已经完成了k3s的初步尝试,接下来我们可以删除k3s,重新装回原来的k8s进行后续在该平台上istio的安装使用
删除k3s
 仔细观察安装过程,我们发现了uninstall script /usr/local/bin/k3s-uninstall.sh,卸载脚本文件,一般来说只要执行该文件即可完成相关软件的卸载。
仔细观察安装过程,我们发现了uninstall script /usr/local/bin/k3s-uninstall.sh,卸载脚本文件,一般来说只要执行该文件即可完成相关软件的卸载。
sudo /usr/local/bin/k3s-uninstall.sh

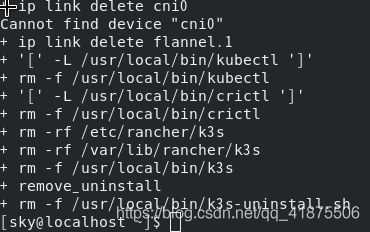
可以看出该脚本文件最后删除了自身,至此所有的卸载工作均以完成。
7.利用Vagrant Cloud现有资源实践k8s
无论是kubeadm,minikube,ansible,还是fedora提供的各种k8s总是会出现各种各样的问题,例如你需要在docker hub或是其它你可以访问的镜像站中下载了相应的镜像,然后手动修改k8s的配置文件的启动参数改为你下载好的镜像,实时跟踪docker的日志记录,查看出现问题。
下面介绍一个早就知道了的,但是一直没有尝试的方法。
https://app.vagrantup.com/flixtech/boxes/kubernetes
上面为Vagrant Cloud中提供的一个完全配置好了的一体化的k8s,该k8s的虚拟镜像为flixtech/kubernetes,其中已经安装配置好了一个单节点的k8s集群。
步骤:
-
安装Virtual Box和Vagrant,熟悉Vagrant,类似于商用的VMware Workstation,但是Vagrant是Hashicorp开源免费版的,并且只提供了命令行界面,但是它十分容易上手,建议尝试一下。
-
Don’t forget to add the appropiate route: sudo ip route add 10.0.0.0/24 via 10.10.0.2
以管理员运行命令:sudo ip route add 10.0.0.0/24 via 10.10.0.2 -
熟悉了Vagrant之后,执行以下命令就可以启动一个一体化的配置好了的k8s
mkdir VM/k8s cd VM/k8s vagrant init fliextech/kubernetes vagrant up vagrant ssh kubectl get node | kubectl cluster-info | ....
此处需要注意的是:当虚拟机使用完毕后,使用命令vagrant suspend暂停虚拟机或是vagrant halt关闭虚拟机,避免使用VirtualBox的管理界面直接操作虚拟机实例。
以上为陈耿作者给出的建议,再次推书《深入浅出Serverless—技术原理与应用实践》,作者为陈耿大大,大大还写过另外一本书《开源容器云OpenShift》都是让你眼前一亮的作品。当时我正好学完了《aws云计算实战》,正惊叹于云计算产品的伟大之处,感觉到了以后必定会是云计算的时代,同样也对aws云计算平台的架构十分好奇,当时也掌握了docker,k8s等技术,但是对于如何构建一个如同aws一样的平台简直是一头雾水,后来偶然买了《开源容器云OpenShift》,它正好就是利用了docker引擎,k8s容器编排技术,一些中间件组件,最后利用openshift的控制平面封装了一下,给用户提供了一个云计算平台的UI界面,并且他是开源的,在GitHub上就可找到,据说IBM大手笔收购REHEL就离不开Open Shift云计算平台。
后来又接触到了Serverless技术,买了相关的书后,一对比发现竟然又是大佬的书,总之此处裂墙推书,你值得拥有的两本书,绝对拓宽你的视野,就是当你苦于架构实现之不易时,一头雾水时,一窍不通时,人家就告诉你了:有开源的实现了,你可以参照了,代码在GitHub上发布了,你可以研究阅读了:)
二.k8s Notes
1.kubernetes配置文件
配置master和node的服务
在master和node上进行配置是告诉他们如何进行通信,配置文件为:
/etc/etcd/etcd.conf
/etc/kubernetes/
 简化单个pod启动的修改:编辑/etc/kubernetes/apiserver文件,将ACL中的AccountService一项去掉。(只是最初测试相关特性时可以这么做)
简化单个pod启动的修改:编辑/etc/kubernetes/apiserver文件,将ACL中的AccountService一项去掉。(只是最初测试相关特性时可以这么做)
2.k8s相关问题修复
2.1etcd connection refuse问题修复
相似问题见此:https://www.cnblogs.com/lkun/p/9486156.html
首先利用kubectl get componentstatuses查看集群的组件状态:发现其中的一个etcd出现了如下错误:
etcd-1 Unhealthy Get http://127.0.0.1:4001/health: dial tcp 127.0.0.1:4001: connect: connection refused
 这就需要修改etcd的配置文件:
这就需要修改etcd的配置文件:
/etc/etcd/etcd.conf
sudo gedit /etc/etcd/etcd.conf
根据出现的相关错误进行如下修改:

修改完成后重启etcd服务,使之前的改动生效:
sudo systemctl restart etcd
重启完成后,再次利用:
kubectl get componentstatuses
查看组件状态,发现etcd都已经处于健康状态。

2.2node:no resource found问题修复
安装完一体化的k8s集群后,发现该集群存在许多问题:例如pod长时间不能部署到node上,产看pod的event信息发现:是没有node资源。
当用kubectl get node时,同样可以看到node资源不存在。
![]()
此时就需要利用journalctl工具查看具体的问题到底出现在了哪里。
此时我们可以打开一个新的窗口,开启6个标签页,在每个标签页中分别查看各个服务组件的日志记录。
journalctl -f -u kube-apiserver
5月 02 11:52:05 localhost.localdomain kube-apiserver[1403]: W0502 11:52:05.376790 1403 cacher.go:125] Terminating all watchers from cacher *core.LimitRange
5月 02 11:52:05 localhost.localdomain kube-apiserver[1403]: W0502 11:52:05.400059 1403 reflector.go:270] k8s.io/client-go/informers/factory.go:131: watch of *v1.ServiceAccount ended with: too old resource version: 79057 (107461)
5月 02 11:52:05 localhost.localdomain kube-apiserver[1403]: W0502 11:52:05.411525 1403 reflector.go:270] k8s.io/apiextensions-apiserver/pkg/client/informers/internalversion/factory.go:117: watch of *apiextensions.CustomResourceDefinition ended with: too old resource version: 79057 (107461)
5月 02 11:52:05 localhost.localdomain kube-apiserver[1403]: W0502 11:52:05.413099 1403 reflector.go:270] k8s.io/kubernetes/pkg/client/informers/informers_generated/internalversion/factory.go:130: watch of *core.LimitRange ended with: too old resource version: 79057 (107461)
journalctl -f -u kube-controller-manager
5月 02 14:25:08 localhost.localdomain kube-controller-manager[884]: W0502 14:25:08.511090 884 reflector.go:270] k8s.io/client-go/informers/factory.go:131: watch of *v1beta1.Event ended with: very short watch: k8s.io/client-go/informers/factory.go:131: Unexpected watch close - watch lasted less than a second and no items received
journalctl -f -u kube-scheduler
5月 02 16:25:28 localhost.localdomain kubelet[1534]: I0502 16:25:28.433124 1534 kubelet_node_status.go:276] Setting node annotation to enable volume controller attach/detach
journalctl -f -u kubelet
5月 02 16:17:46 localhost.localdomain kubelet[1534]: I0502 16:17:46.492588 1534 kubelet_node_status.go:276] Setting node annotation to enable volume controller attach/detach
journalctl -f -u kube-proxy
5月 01 14:10:01 localhost.localdomain kube-proxy[977]: E0501 14:10:01.953443 977 reflector.go:134] k8s.io/client-go/informers/factory.go:131: Failed to list *v1.Endpoints: Get http://127.0.0.1:8080/api/v1/endpoints?limit=500&resourceVersion=0: dial tcp 127.0.0.1:8080: connect: connection refused
journalctl -fu docker
5月 02 18:04:02 localhost.localdomain dockerd-current[1259]: time=“2019-05-02T18:04:02.926446919+08:00” level=error msg=“Handler for GET /v1.26/images/k8s.gcr.io/pause:3.1/json returned error: No such image: k8s.gcr.io/pause:3.1”
![]()
 根据具体的出错信息,修改相关的配置文件,配置文件位于两个部分:
根据具体的出错信息,修改相关的配置文件,配置文件位于两个部分:
- etcd服务的配置文件位于:/etc/etcd/etcd.conf
- k8s各个组件的配置文件位于:/etc/kubernetes/目录下
注意:通过journalctl工具,我发现无法获取node资源的一个最最重要的问题就是通过最后对docker服务的检查发现其中的每个pod的pause container为从gcr.io上下载的,而由于屏蔽了中国的访问,故需要我们手动下载缺少的镜像,缺少的pause镜像为3.1版本的在docker hub上进行搜索,我最终找到了一个3.1版本的pause(docker.io/kubernetes/pause 为3.0版本的,故我没有选择该image)
拉取该镜像:
docker pull rancher/pause-amd64:3.1
![]()
修改kubelet的启动参数,使其使用刚刚拉取的镜像,而不是主动从gcr.io拉取。编辑/etc/kubernetes/config文件,增加如下内容
–pod_infra_container_image=docker.io/rancher/pause-amd64:3.1
 修改完上述所有配置后,重启docker及各项服务组件。
修改完上述所有配置后,重启docker及各项服务组件。
解决了pause镜像的问题。
相似问题见此:
https://linuxacademy.com/community/posts/show/topic/19040-kubectl-get-nodes-returns-no-resources-found