linux内核那些事之物理内存模型之FLATMEM(1)
linux内核中物理内存管理是其中比较重要的一块,随着内核从32位到64位发展,物理内存管理也不断进行技术更新,按照历史演进共有FLATMEM、DISCONTIGMEM以及SPRARSEMEM模型。(关于三个物理内存模型社区文档有总体说明介绍:(
https://www.kernel.org/doc/html/v5.3/vm/memory-model.html)
linux 物理内存模型是内核源码中为数不多的能够保存三个模型源码代码的模块,在使用过程中用户可以根据需要配置内核选择相应的模型,目前SPRARSEMEM使用较多。
在理解内存管理模型中,需要理解一些基本内存概念会在讲解过程中进行穿插讲解。
FLATMEM模型
flat中文意思就是水平、平坦的,按照字面意思理解该模型即位平坦模型,它是linux最早的模型管理,一直在早期支撑了linux发展,其他两种内存管理模型也是在该模型基础上进化,所以要理解linux 内存管理,必须要了解此模型,包括很多概念比如pfn,页等都是在该模型概念基础上进行提出的。
flat物理模型其实质就是将整块物理内存划分到一个数组中进行管理,整个物理内存划分到一个数组mem_map数组中实现一个平滑管理。
划分mem_map数组过程中,基于空间和效率来讲,内核整个物理内存划分成一页即page为单位进行管理,mem_map数组单位为struct page,物理内存管理的最小颗粒度即为页,如下图所示:
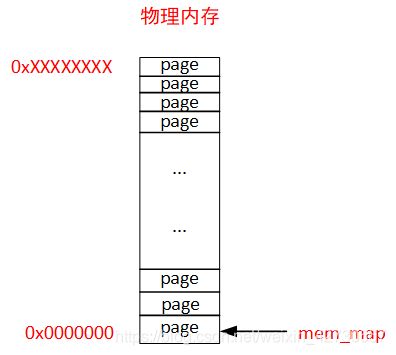
上图中有一块物理内存,物理地址空间为0x00000000~0xxxxxxxxx,内核按照页将整个物理内存进行划分,mem_map为以struct page为单位的数组,首地址指向物理内存的第一页地址。
物理内存:即为CPU通过总线写入到物理内存的总线地址,操作系统和程序员的视角是无法看到物理地址,和我们通常malloc申请到的内存不一样,malloc内存申请的为一个虚拟地址即程序员和操作系统看到的地址 。
由于物理内存管理是从32位系统开始的,首先以32位系统讲解开始,64位内存管理思路和32位差不多,只是空间划分有区别
flat模型在大多数版本中都存在,为了方便分析该模型排除其他模型干扰,选取了2.4.22内核源码为标准,主要是《understanding the linux virtual memory manager》这本书以该版本为主,后续可以方便进行持续深入。
page(页)
整个物理内存管理以page为基础,一个page大小被定义成4K,在内核中使用PAGE_SIZE定义了page大小,以i386为例,在include\asm-i386\page.h 定义了PAGE_SIZE:
/* PAGE_SHIFT determines the page size */
#define PAGE_SHIFT 12
#define PAGE_SIZE (1UL << PAGE_SHIFT)
#define PAGE_MASK (~(PAGE_SIZE-1))由此可以得到在物理内存的第一个page 的物理地址范围为0x0~0x3FF, 第二个页的物理地址范围为0x400~0x7FF,...以此类推。
内核代码中有专有的struct page数据结构对页进行描述,2.4内核版本中对该数据结构定义在linux/mm.h文件中,其详细定义如下:
typedef struct page {
struct list_head list; /* ->mapping has some page lists.
该页面所属的列表,为了节省空间,该字段会进行复用,例如在slab中该字段代表指向管理页面slab以及高速缓存结构*/
struct address_space *mapping; /* The inode (or ...) we belong to.
如果文件或设备已经映射到内存,它们的索引节点会有一个相关联 的address_space.如果这个页面属于这个文件,则该字段会指向这个address_space.如果页面是匿名的,且设置了mapping,则address_space就是交换地址空间的swapper_space */
unsigned long index; /* Our offset within mapping.
该字段有两个用途,与该页面状态有关。如果页面是文件映射的一部分,它就是页面在文件中的偏移。如果页面是交换高速缓存的一部分,它就是在交换地址空间address_space的偏移量。此外,如果包含页面的块被释放以提供给一个特色的进程,那么被释放的块的顺序存放在index中*/
struct page *next_hash; /* Next page sharing our hash bucket in
the pagecache hash table.
属于一个文件映射并被散列到索引节点及偏移中的页面。该字段将被共享相同的哈希桶的页面链接在一起*/
atomic_t count; /* Usage count, see below. 页面被引用的数目。如果count减到0,它就会被释放。当页面被多个进程使用到,或者被内核用到的时候,count就会增大*/
unsigned long flags; /* atomic flags, some possibly
updated asynchronously 页面的状态*/
struct list_head lru; /* Pageout list, eg. active_list;
protected by pagemap_lru_lock !! 页面替换策略*/
struct page **pprev_hash; /* Complement to *next_hash. */
struct buffer_head * buffers; /* Buffer maps us to a disk block. 如何一个页面有相关的块设备缓冲区*/
/*
* On machines where all RAM is mapped into kernel address space,
* we can simply calculate the virtual address. On machines with
* highmem some memory is mapped into kernel virtual memory
* dynamically, so we need a place to store that address.
* Note that this field could be 16 bits on x86 ... ;)
*
* Architectures with slow multiplication can define
* WANT_PAGE_VIRTUAL in asm/page.h
*/
#if defined(CONFIG_HIGHMEM) || defined(WANT_PAGE_VIRTUAL)
void *virtual; /* Kernel virtual address (NULL if
not kmapped, ie. highmem) */
#endif /* CONFIG_HIGMEM || WANT_PAGE_VIRTUAL */
} mem_map_t;
上述各个字段的意义与其内部实现有很大关系,可以先不必关注细节,后面再进行详细了解。
pfn(页帧号)
在内核源码会经常见到一个pfn概念,pfn即为页帧号,意思表示为第几页,即mem_map的数组的索引。在内核处理内存单元为page,经常使用页帧号来表明处理的为第几页。
正如上述例子中第一页的物理地址范围为0x0~0x3FF, 第二页物理地址范围为0x400~0x7FF。
物理地址与pfn转换
在内核源码处理中经常用到将物理地址与pfn之间转换(注意非虚拟地址,后面再讲解虚拟地址转换),其实 常简单
将一个物理地址转换成pfn只需要进行位移即可,可以参考phys_to_pfn:
#define phys_to_pfn(phys) ((phys) >> PAGE_SHIFT)同样将pfn转换成物理地址只需要左移即可,2.4.22内核中暂时没用相关宏,可以参考如下代码
将max_low_pfn转换成物理地址:
pfn与page转换
pfn与page之间转换比较简单,需要使用 mem_map数组
pfn与page之间转换可以参考下述两个宏pfn_to_page和page_to_pfn:
#define pfn_to_page(pfn) (mem_map + (pfn))
#define page_to_pfn(page) ((page) - mem_map)
mem_map数组
mem_mep为物理内存实际管理数据,以page为单位,其数组大小与实际内存有很大关系,内核中有max_pfn全局变量来表示实际的物理内存最大的页帧号,其值在系统启动过程中由实际物理内存计算得知,不同的芯片体系结构计算方法不一样,
以i386为用例,其计算最大max_pfn函数为find_max_pfn(),位于arch\i386\kernel\setup.c文件中,具体实现如下:

会遍历所有RAM页面,从而得到最大max_pfn 。
2.4内核源码中mem_map定义位于mm\memory.c文件中;
mem_map_t * mem_map;
ZONE划分
页(page)是linux物理内存管理的基本单位,将实际物理内存按照页单位进行一片片切片如同切牛肉一样,其物理地址从0x00000000开始,但是由于早期历史硬件缺陷原因(早期DMA历史硬件缺陷只能映射到物理地址(0x0000000~16M)地址范围,无法映射到整个物理地址范围,故物理地址前16M或者32M需要预留给DMA使用。
在一个32位linux系统中,一般将物理内存按照ZONE将其划分三个大的区域ZONE_DMA、ZONE_NORMAL、NOZE_ZONE_HIGHMEM三个区域,如下图:
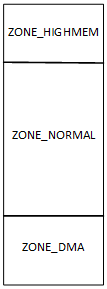
ZONE_DMA大小与具体芯片有关系,如果使用的DMA地址范围是能在32M范围,则可以将ZONE_DMA大小设置为32M。当然如果在某个开发板中使用的芯片DMA硬件没有缺陷,可以映射到全部物理地址范围之内,则完全可以将DMA取消掉,这意味着ZONE_DMA划分不是固定的,根据具体所使用的芯片有关。
ZONE_HIGHMEM划分是由于32位系统的限制(后面可以再进行介绍),也不是必须的,如果实际物理内向小于896M则不必划分ZONE_HIGHMEM。
mem_map数组初始化(鸡和蛋问题)
FLATMEM内存模型中,mem_map数组初始化位于mm\page_alloc文件中,
void __init free_area_init(unsigned long *zones_size)
{
free_area_init_core(0, &contig_page_data, &mem_map, zones_size, 0, 0, 0);
}unsigned long *zones_size:表示为各个ZONE具体的实际大小,以页为单位。
在free_area_init_core()函数中,会首先根据zones_size大小计算共有多少个实际物理页,然后从bootmem(系统引导区)申请 (totalpages + 1)*sizeof(struct page)实际物理空间,管理整个物理内存。在mem_map数组建立起来之前,整个系统内存管理是有bootmem(系统引导区)进行管理,申请内存页是从系统引导区中申请。mem_map数组建立之后,kernel会把物理内存管理权由bootmem转入到mem_map进行管理。
free_area_init_core():函数为真正的mem_map物理内存初始化函数实施函数 ,是比较关键函数,整体代码如下:
/*
* Set up the zone data structures:
* - mark all pages reserved
* - mark all memory queues empty
* - clear the memory bitmaps
*/
void __init free_area_init_core(int nid, pg_data_t *pgdat, struct page **gmap,
unsigned long *zones_size, unsigned long zone_start_paddr,
unsigned long *zholes_size, struct page *lmem_map)
{
unsigned long i, j;
unsigned long map_size;
unsigned long totalpages, offset, realtotalpages;
const unsigned long zone_required_alignment = 1UL << (MAX_ORDER-1);
if (zone_start_paddr & ~PAGE_MASK)
BUG();
totalpages = 0;
for (i = 0; i < MAX_NR_ZONES; i++) {
unsigned long size = zones_size[i];
totalpages += size;
}
realtotalpages = totalpages;
if (zholes_size)
for (i = 0; i < MAX_NR_ZONES; i++)
realtotalpages -= zholes_size[i];
printk("On node %d totalpages: %lu\n", nid, realtotalpages);
/*
* Some architectures (with lots of mem and discontinous memory
* maps) have to search for a good mem_map area:
* For discontigmem, the conceptual mem map array starts from
* PAGE_OFFSET, we need to align the actual array onto a mem map
* boundary, so that MAP_NR works.
*/
map_size = (totalpages + 1)*sizeof(struct page);
if (lmem_map == (struct page *)0) {
lmem_map = (struct page *) alloc_bootmem_node(pgdat, map_size);
lmem_map = (struct page *)(PAGE_OFFSET +
MAP_ALIGN((unsigned long)lmem_map - PAGE_OFFSET));
}
*gmap = pgdat->node_mem_map = lmem_map;
pgdat->node_size = totalpages;
pgdat->node_start_paddr = zone_start_paddr;
pgdat->node_start_mapnr = (lmem_map - mem_map);
pgdat->nr_zones = 0;
offset = lmem_map - mem_map;
for (j = 0; j < MAX_NR_ZONES; j++) {
zone_t *zone = pgdat->node_zones + j;
unsigned long mask;
unsigned long size, realsize;
zone_table[nid * MAX_NR_ZONES + j] = zone;
realsize = size = zones_size[j];
if (zholes_size)
realsize -= zholes_size[j];
printk("zone(%lu): %lu pages.\n", j, size);
zone->size = size;
zone->name = zone_names[j];
zone->lock = SPIN_LOCK_UNLOCKED;
zone->zone_pgdat = pgdat;
zone->free_pages = 0;
zone->need_balance = 0;
if (!size)
continue;
/*
* The per-page waitqueue mechanism uses hashed waitqueues
* per zone.
*/
zone->wait_table_size = wait_table_size(size);
zone->wait_table_shift =
BITS_PER_LONG - wait_table_bits(zone->wait_table_size);
zone->wait_table = (wait_queue_head_t *)
alloc_bootmem_node(pgdat, zone->wait_table_size
* sizeof(wait_queue_head_t));
for(i = 0; i < zone->wait_table_size; ++i)
init_waitqueue_head(zone->wait_table + i);
pgdat->nr_zones = j+1;
mask = (realsize / zone_balance_ratio[j]);
if (mask < zone_balance_min[j])
mask = zone_balance_min[j];
else if (mask > zone_balance_max[j])
mask = zone_balance_max[j];
zone->pages_min = mask;
zone->pages_low = mask*2;
zone->pages_high = mask*3;
zone->zone_mem_map = mem_map + offset;
zone->zone_start_mapnr = offset;
zone->zone_start_paddr = zone_start_paddr;
if ((zone_start_paddr >> PAGE_SHIFT) & (zone_required_alignment-1))
printk("BUG: wrong zone alignment, it will crash\n");
/*
* Initially all pages are reserved - free ones are freed
* up by free_all_bootmem() once the early boot process is
* done. Non-atomic initialization, single-pass.
*/
for (i = 0; i < size; i++) {
struct page *page = mem_map + offset + i;
set_page_zone(page, nid * MAX_NR_ZONES + j);
set_page_count(page, 0);
SetPageReserved(page);
INIT_LIST_HEAD(&page->list);
if (j != ZONE_HIGHMEM)
set_page_address(page, __va(zone_start_paddr));
zone_start_paddr += PAGE_SIZE;
}
offset += size;
for (i = 0; ; i++) {
unsigned long bitmap_size;
INIT_LIST_HEAD(&zone->free_area[i].free_list);
if (i == MAX_ORDER-1) {
zone->free_area[i].map = NULL;
break;
}
/*
* Page buddy system uses "index >> (i+1)",
* where "index" is at most "size-1".
*
* The extra "+3" is to round down to byte
* size (8 bits per byte assumption). Thus
* we get "(size-1) >> (i+4)" as the last byte
* we can access.
*
* The "+1" is because we want to round the
* byte allocation up rather than down. So
* we should have had a "+7" before we shifted
* down by three. Also, we have to add one as
* we actually _use_ the last bit (it's [0,n]
* inclusive, not [0,n[).
*
* So we actually had +7+1 before we shift
* down by 3. But (n+8) >> 3 == (n >> 3) + 1
* (modulo overflows, which we do not have).
*
* Finally, we LONG_ALIGN because all bitmap
* operations are on longs.
*/
bitmap_size = (size-1) >> (i+4);
bitmap_size = LONG_ALIGN(bitmap_size+1);
zone->free_area[i].map =
(unsigned long *) alloc_bootmem_node(pgdat, bitmap_size);
}
}
build_zonelists(pgdat);
}
该函数主要处理流程解释如下:
1:zone_start_paddr对 页管理开始物理地址进行检查,由于物理内存被划分成页管理,所以开始的物理地址一定是从页对其地址开始,故要进行地址页对齐检查
if (zone_start_paddr & ~PAGE_MASK)
BUG();2:根据传入的zones_size数组计算出总共占有的页数totalpages:
totalpages = 0;
for (i = 0; i < MAX_NR_ZONES; i++) {
unsigned long size = zones_size[i];
totalpages += size;
}3:由于zones_size中包含内存空洞数目,需要计算减去各个ZONE空洞数目zholes_size。由于在flatmem模式中传入的zholes_size为空,故不计算空洞数目:
realtotalpages = totalpages;
if (zholes_size)
for (i = 0; i < MAX_NR_ZONES; i++)
realtotalpages -= zholes_size[i];
printk("On node %d totalpages: %lu\n", nid, realtotalpages);4:按照 totalpages数目,计算出为了管理该内存占有的空间大小(totalpages + 1)*sizeof(struct page),注意此时内存管理权是bootmem负责管理,调用alloc_bootmem_node()接口申请内存,并初始化pgdat数据结构,此时*gmap=lmem_map,即mem_map的地址为lmem_map,真正为mem_map申请内存:
map_size = (totalpages + 1)*sizeof(struct page);
if (lmem_map == (struct page *)0) {
lmem_map = (struct page *) alloc_bootmem_node(pgdat, map_size);
lmem_map = (struct page *)(PAGE_OFFSET +
MAP_ALIGN((unsigned long)lmem_map - PAGE_OFFSET));
}
*gmap = pgdat->node_mem_map = lmem_map;
pgdat->node_size = totalpages;
pgdat->node_start_paddr = zone_start_paddr;
pgdat->node_start_mapnr = (lmem_map - mem_map);
pgdat->nr_zones = 0;5:接下循环来初始化各个zone 区域, zone数据结构较为复杂,后面再详细介绍,只要记得zone初始化地方即可:
offset = lmem_map - mem_map;
for (j = 0; j < MAX_NR_ZONES; j++) {
zone_t *zone = pgdat->node_zones + j;
unsigned long mask;
unsigned long size, realsize;
...
...
}
参考资料
https://www.kernel.org/doc/html/v5.3/vm/memory-model.html
《understanding the linux virtual memory manager》