利用Tensorflow使用BERT模型+输出句向量和字符向量
文章目录
- 1.前言
- 2.BERT模型
-
- 2.1 下载预训练好的模型
- 2.2 导入BERT模型
- 2.3 数据下载和预处理
- 2.4 模型训练
- 2.5 直接输出BERT模型的句向量或者是字符向量
1.前言
最近想着如何利用tensorflow调用BERT模型,发现其源码已经有比较详细的调用代码,具体的链接如下:https://github.com/google-research/bert/blob/master/predicting_movie_reviews_with_bert_on_tf_hub.ipynb
因此结合上面的例子,主要来构造调用BERT模型。
2.BERT模型
2.1 下载预训练好的模型
我们可以在BERT的github源码中找到已经训练好的模型,其链接如下:https://github.com/google-research/bert。
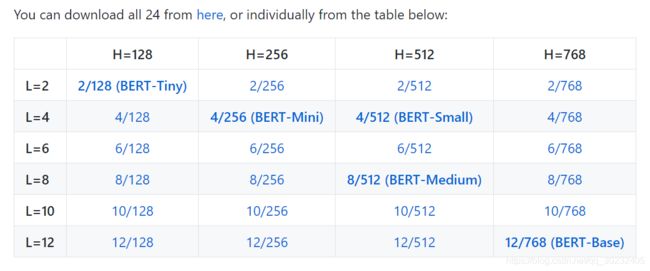
可以看到上面有许多已经训练好的模型,可以根据自己的需求找到适合自己的进行下载。下载下来的文件是一个压缩包,解压之后可以看到几个具体文件:

- bert_config.json:保存的是BERT模型的一些主要参数设置
- bert_model.ckpt.xxxx:这里有两个文件,但导入模型只需要bert_model.ckpt这个前缀就可以了
- vocab.txt:用来预训练时的词典
这时候就可以利用这三个文件来导入BERT模型。这三个文件地址可以表示为:
BERT_INIT_CHKPNT="./bert_pretrain_model/bert_model.ckpt"
BERT_VOCAB="./bert_pretrain_model/vocab.txt"
BERT_CONFIG="./bert_pretrain_model/bert_config.json"
2.2 导入BERT模型
首先需要安装好bert-tensorflow和tensorflow-hub,安装bert-tensorflow的命令为:
pip install bert-tensorflow
接着利用bert-tensorflow中的modeling模块导入参数设置和文件:
from bert import modeling
bert_config = modeling.BertConfig.from_json_file(hp.BERT_CONFIG)
model = modeling.BertModel(
config=bert_config,
is_training=is_training,
input_ids=input_ids,
input_mask=input_mask,
token_type_ids=segment_ids,
use_one_hot_embeddings=use_one_hot_embeddings)
2.3 数据下载和预处理
这次的训练数据集是电影评论情感分类,其具有两个类别标签:0(positive)和1(negative)。
具体代码:
import pandas as pd
import tensorflow as tf
import os
import re
# Load all files from a directory in a DataFrame.
def load_directory_data(directory):
data = {
}
data["sentence"] = []
data["sentiment"] = []
for file_path in os.listdir(directory):
with tf.gfile.GFile(os.path.join(directory, file_path), "r") as f:
data["sentence"].append(f.read())
data["sentiment"].append(re.match("\d+_(\d+)\.txt", file_path).group(1))
return pd.DataFrame.from_dict(data)
# Merge positive and negative examples, add a polarity column and shuffle.
def load_dataset(directory):
pos_df = load_directory_data(os.path.join(directory, "pos"))
neg_df = load_directory_data(os.path.join(directory, "neg"))
pos_df["polarity"] = 1
neg_df["polarity"] = 0
return pd.concat([pos_df, neg_df]).sample(frac=1).reset_index(drop=True)
# Download and process the dataset files.
def download_and_load_datasets(force_download=False):
dataset = tf.keras.utils.get_file(
fname="aclImdb.tar.gz",
origin="http://ai.stanford.edu/~amaas/data/sentiment/aclImdb_v1.tar.gz",
extract=True)
train_df = load_dataset(os.path.join(os.path.dirname(dataset), "aclImdb", "train"))
test_df = load_dataset(os.path.join(os.path.dirname(dataset), "aclImdb", "test"))
return train_df, test_df
if __name__ == "__main__":
train, test = download_and_load_datasets()
接下来对特征进行标记化,转换成BERT模型能够识别的特征:
# Convert our train and test features to InputFeatures that BERT understands.
label_list = [int(i) for i in hp.label_list.split(",")]
train_features = run_classifier.convert_examples_to_features(train_InputExamples, label_list, hp.MAX_SEQ_LENGTH,
tokenizer)
test_features = run_classifier.convert_examples_to_features(test_InputExamples, label_list, hp.MAX_SEQ_LENGTH,
tokenizer)
比如它能够将句子:“This here’s an example of using the BERT tokenizer”转换为:

2.4 模型训练
(1)可以利用tf.estimator训练:https://github.com/llq20133100095/bert_use/blob/master/model_estimator.py
(2)利用传统的sess和tf.data进行训练:
https://github.com/llq20133100095/bert_use/blob/master/train.py
2.5 直接输出BERT模型的句向量或者是字符向量
在BERT源码中,只要设置model.get_pooled_output和model.get_sequence_output就能得到句向量和字符向量:
def create_model(bert_config, is_training, input_ids, input_mask, segment_ids, use_one_hot_embeddings, use_sentence):
"""Creates a classification model."""
model = modeling.BertModel(
config=bert_config,
is_training=is_training,
input_ids=input_ids,
input_mask=input_mask,
token_type_ids=segment_ids,
use_one_hot_embeddings=use_one_hot_embeddings)
# Use "pooled_output" for classification tasks on an entire sentence.
# Use "sequence_outputs" for token-level output.
if use_sentence:
output_layer = model.get_pooled_output()
else:
output_layer = model.get_sequence_output()
return output_layer
具体代码可以参考:https://github.com/llq20133100095/bert_use/blob/master/get_embedding.py