MADlib——基于SQL的数据挖掘解决方案(23)——分类之SVM
一、SVM简介
SVM法即支持向量机(Support Vector Machine,SVM)法,由Vapnik等人于1995年提出,具有相对优良的性能指标。该方法是建立在统计学理论基础上的机器学习方法。通过学习算法,SVM可以自动寻找那些对分类有较好区分能力的支持向量,由此构造出的分类器可以最大化类与类的间隔,因而有较好的适应能力和较高的分准率。该方法只需要由各类域的边界样本的类别来决定最后的分类结果。
SVM属于有监督学习方法,即已知训练点的类别,求训练点和类别之间的对应关系,以便将训练集按照类别分开,或者是预测新的训练点所对应的类别。由于SVM在实例的学习中能够提供清晰直观的解释,所以其在文本分类、文字识别、图像分类、升序序列分类等方面的实际应用中,都呈现了非常好的性能。
1. 支持向量机的基本思想
SVM构建了一个分割两类的超平面(也可以扩展到多类问题)。在构建的过程中,SVM算法试图使两类之间的分割达到最大化,如图1所示。

图1 SVM划分算法示意图
以一个很大的边缘分隔两个类可以使期望泛化误差最小化。“最小化泛化误差”的含义是:当对新的样本(数值未知的数据点)进行分类时,基于学习所得的分类器(超平面),使得我们对其所属分类预测错误的概率被最小化。直觉上,这样的一个分类器实现了两个分类之间分离边缘最大化。图1解释了“最大化边缘”的概念。和分类器平面平行,分别穿过数据集中的一个或多个点的两个平面称为边界平面(Bounding Plane),这些边界平面的距离称为边缘(Margin),而“通过SVM学习”的含义是找到最大化这个边缘的超平面。落在边界平面上的数据集中的点称为支持向量(Support Vector)。这些点在这一理论中的作用至关重要,故称为“支持向量机”。支持向量机的基本思想简单总结起来,就是与分类器平行的两个平面,此两个平面能很好地分开两类不同的数据,且穿越两类数据区域集中的点,现在欲寻找最佳超几何分隔平面使之与两个平面的距离最大,如此便能实现分类总误差最小。
2. 支持向量机的理论基础
支持向量机最初是在研究线性可分问题的过程中提出的,所以这里先来介绍线性SVM的基本原理。不失一般性,假设容量为n的训练样本集 ![]() 由两个类别组成,若
由两个类别组成,若 ![]() 属于第一类,则记为
属于第一类,则记为 ![]() ;若
;若 ![]() 属于第二类,则记为
属于第二类,则记为 ![]() 。
。
若存在分类超平面:
![]()
能够将样本正确地划分成两类,即相同类别的样本都落在分类超平面的同一侧,则称该样本是线性可分的,即满足:
 (SVM-a)
(SVM-a)
此处,可知平面 ![]() 和
和 ![]() 即为该分类问题中的边界超平面,这个问题可以回归到线性规划问题。边界超平面
即为该分类问题中的边界超平面,这个问题可以回归到线性规划问题。边界超平面 ![]() 到原点的距离为
到原点的距离为 ![]() ;而边界超平面
;而边界超平面 ![]() 到原点的距离为
到原点的距离为 ![]() 。所以这两个边界超平面的距离是
。所以这两个边界超平面的距离是 ![]() 。同时注意,这两个边界超平面是平行的。而根据SVM的基本思想,最佳超平面应该使两个边界平面的距离最大化,即最大化
。同时注意,这两个边界超平面是平行的。而根据SVM的基本思想,最佳超平面应该使两个边界平面的距离最大化,即最大化 ![]() ,也就是最小化其倒数,即:
,也就是最小化其倒数,即:
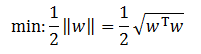
为了求解这个超平面的参数,可以以最小化上式为目标,其要求满足式SVM-a的表达式,而该式中的两个表达式,可以综合表达为:
![]()
为此可以得到如下目标规划问题:

到这个形式以后,就可以很明显地看出来,它是一个凸优化问题,或者更具体地说,它是一个二次优化问题——目标函数是二次的,约束条件是线性的。这个问题可以用现成的QP(Quadratic Programming)的优化包进行求解。虽然这个问题确实是一个标准QP问题,但是它也有它的特殊结构,通过拉格朗日变换到对偶变量(Dual Variable)的优化问题之后,可以找到一种更加有效的方法来进行求解,而且通常情况下这种方法比直接使用通用的QP优化包进行优化高效得多,而且便于推广。拉格朗日变换的作用,简单地说,就是通过给每一个约束条件加上一个拉格朗日乘子(Lagrange multiplier)ɑ,就可以将约束条件融合到目标函数里去。也就是说把条件融合到一个函数里,现在只用一个函数表达式便能清楚地表达出我们的问题。该问题的拉格朗日表达式为:

其中, ![]() ,为Lagrange系数。然后依据拉格朗日对偶理论将其转化为对偶问题,即:
,为Lagrange系数。然后依据拉格朗日对偶理论将其转化为对偶问题,即:

这个问题可以用二次规划方法求解。设求解所得的最优解为 ![]() ,则可以得到最优的
,则可以得到最优的 ![]() 和
和 ![]() 为:
为:

其中, ![]() 和
和 ![]() 为两个类别中任意的一对支持向量。最终得到的最优分类函数为:
为两个类别中任意的一对支持向量。最终得到的最优分类函数为:

在输入空间中,如果数据不是线性可分的,支持向量机通过非线性映射 ![]() 将数据映射到某个其它点积空间(称为特征空间)F,然后在F 中执行上述线性算法。这只需计算点积
将数据映射到某个其它点积空间(称为特征空间)F,然后在F 中执行上述线性算法。这只需计算点积 ![]() 即可完成映射。在文献中,这一函数称为核函数(Kernel),用
即可完成映射。在文献中,这一函数称为核函数(Kernel),用 ![]() 表示。
表示。
支持向量机的理论有三个要点,即:
- 最大化间距;
- 核函数;
- 对偶理论。
对于线性SVM,还有一种更便于理解的求解方法,即引入松弛变量,转化为纯线性规划问题。同时引入松弛变量后,SVM更符合大部分样本,因为对于大部分的情况,很难将所有的样本明显地分成两类,总有少数样本导致寻找不到最佳超平面的情况。
一个典型的线性SVM模型可以表示为:

Mangasarian证明该模型与下面模型的解几乎完全相同:

这样,对于二分类的SVM问题就可以转化为非常便于求解的线性规划问题了。
3. 支持向量机的特点
SVM具有许多很好的性质,因此它已经成为广泛使用的分类算法之一。下面简要总结一下SVM的一般特征。
- SVM学习问题可以表示为凸优化问题,因此可以利用已知的有效算法发现目标函数的全局最小值。而其它的分类方法(如基于规则的分类器和人工神经网络)都采用一种基于贪心学习的策略来搜索假设空间,这种方法一般只能获得局部最优解。
- SVM通过最大化决策边界的边缘来控制模型的能力。尽管如此,用户必须提供其它参数,如使用的核函数类型,为了引入松弛变量所需的代价函数C等,当然一些SVM工具都会默认设置,一般选择默认的设置即可。
- 通过对数据中每个分类属性值引入一个亚变量,SVM可以应用于分类数据。例如,如果婚姻状况有三个值(单身、已婚、离异),可以对每一个属性值引入一个二元变量。
二、MADlib中SVM相关函数
1. 分类训练函数
(1)语法
SVM分类训练函数具有以下格式:
svm_classification(
source_table,
model_table,
dependent_varname,
independent_varname,
kernel_func,
kernel_params,
grouping_col,
params,
verbose
)(2)参数
参数名称 |
数据类型 |
描述 |
source_table |
TEXT |
包含训练数据的表的名称。 |
model_table |
TEXT |
包含模型的输出表名称,输出表列如表2所示。 |
dependent_varname |
TEXT |
因变量列的名称。对于分类,此列可以包含任何类型的值,但必须假定两个不同的值。否则,将会抛出错误。 |
independent_varname |
TEXT |
自变量表达式列表。截取变量不应该包含在这个表达式中。有关截取信息,参阅内核参数中的‘fit_intercept’。注意表达式应该能够转换为DOUBLE PRECISION[]类型。 |
kernel_func(可选) |
TEXT |
核函数类型,缺省值为‘linear’。当前支持三种核类型,‘linear’、‘gaussian’和‘polynomial’。文本可以是三个字符串的任何子集,例如,kernel_func ='ga'将创建一个高斯核函数。 |
kernel_params(可选) |
TEXT |
缺省值为NULL。用逗号分隔的键值对中的非线性内核的参数。实际参数根据kernel_func的值而有所不同。详见后面的描述。 |
grouping_col(可选) |
TEXT |
缺省值为NULL。与SQL中的“GROUP BY”类似,是一个表达式列表,用于将输入数据集分组为离散组,每个组训练一个模型。注意,如果使用分组,则不支持交叉验证。 |
params(可选) |
TEXT |
缺省值为NULL。用逗号分隔的键值对中的优化和正则化参数。如果提供了值列表,则将执行交叉验证以从列表中选择最佳值。详见后面的描述。 |
verbose(可选) |
BOOLEAN |
缺省值为FALSE。是否详细输出训练结果。 |
表1 svm_classification函数参数说明
SVM生成的模型表包含以下列:
列名 |
数据类型 |
描述 |
coef |
FLOAT8 |
系数向量。 |
grouping_key |
TEXT |
标识数据所属的组。 |
num_rows_processed |
BIGINT |
处理的行数。 |
num_rows_skipped |
BIGINT |
由于缺失值或失败而跳过的行数。 |
num_iterations |
INTEGER |
随机梯度下降算法完成的迭代次数。该算法要么收敛在这个迭代次数中,要么达到优化参数中指定的最大数。 |
loss |
FLOAT8 |
SVM的目标函数值。 |
norm_of_gradient |
FLOAT8 |
目标函数(子)梯度的L2范数的值。 |
dep_var_mapping |
TEXT[] |
因变量标签的向量。第一项对应于-1,第二项对应+1。仅限内部使用。 |
表2 svm_classification函数输出表列说明
如果核函数不是线性的,则会创建一个名为
训练函数在产生输出表的同时,还会创建一个名为
列名 |
数据类型 |
描述 |
method |
TEXT |
‘svm’ |
version_number |
TEXT |
用于生成模型的MADlib版本。 |
source_table |
TEXT |
源数据表名。 |
model_table |
TEXT |
模型表名。 |
dependent_varname |
TEXT |
因变量。 |
independent_varname |
TEXT |
自变量。 |
kernel_func |
TEXT |
核函数。 |
kernel_parameters |
TEXT |
核参数以及随机特征映射数据。 |
grouping_col |
TEXT |
分组列。 |
optim_params |
TEXT |
优化参数字符串。 |
reg_params |
TEXT |
正则化参数字符串。 |
num_all_groups |
INTEGER |
SVM训练的组数。 |
num_failed_groups |
INTEGER |
SVM训练失败的组数。 |
total_rows_processed |
BIGINT |
所有组处理的总行数。 |
total_rows_skipped |
BIGINT |
由于缺少值或失败,所有组跳过的总行数。 |
表3 svm_classification函数概要输出表列说明
2. 回归训练函数
SVM回归训练函数具有以下格式:
svm_regression(source_table,
model_table,
dependent_varname,
independent_varname,
kernel_func,
kernel_params,
grouping_col,
params,
verbose
)回归函数格式与分类基本相同,但在其输出的模型表中,没有因变量映射。以下参数的格式与svm_classification不同:
- dependent_varname:TEXT类型,因变量列的名称。对于回归,该列只能包含可以转换为DOUBLEPRECISION的值或表达式,否则将会抛出错误。
- params(可选):TEXT,缺省值为NULL。参数epsilon和eps_table仅对回归有意义。详见后面的说明。
3. 新颖性检测训练函数
新颖性检测函数是一类SVM分类器,具有以下格式:
svm_one_class(
source_table,
model_table,
independent_varname,
kernel_func,
kernel_params,
grouping_col,
params,
verbose
)新颖性检测函数的格式与分类函数基本相同,但未指定因变量名称。生成的模型表格式与分类函数相同。
4. 核参数
核参数以包含逗号分隔的名-值对列表的字符串形式提供。所有这些命名参数都是可选的,它们的顺序无关紧要。必须使用格式“<参数名> = <值>”来指定参数的值,否则该参数将被忽略。
(1)通用核参数
- fit_intercept:缺省值为TRUE。参数fit_intercept是一个将截取值添加到independent_varname数组表达式的指示符。截距被添加到特征列表的末尾,因此系数列表的最后一个元素是截距。
- n_components:缺省值为2*num_features,变换后的特征空间的维度。较大的值会降低核函数估计的方差,但需要更多内存并需要较长时间进行训练。
- random_state:缺省值为1,由随机数生成器使用的种子。
- gamma:缺省值为1/num_features。Radius Basis Function内核中的参数 γ ,例如
 。为γ提供适当的值对于核函数的性能至关重要,大的gamma会导致过度拟合,小的gamma会使模型过于粗糙,无法捕捉到数据的复杂性。
。为γ提供适当的值对于核函数的性能至关重要,大的gamma会导致过度拟合,小的gamma会使模型过于粗糙,无法捕捉到数据的复杂性。
- coef0:缺省值为1.0,
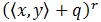 中的自变量q。必须大于或等于0。当它为0时,多项式核是齐次形式。
中的自变量q。必须大于或等于0。当它为0时,多项式核是齐次形式。 - degree:缺省值为3,
 中的r。
中的r。
5. 其它参数
本小节中的参数在params参数中作为字符串提供,其中包含逗号分隔的名-值对列表。所有这些命名参数都是可选的,它们的顺序无关紧要。必须使用“<参数名> = <值>” 格式指定参数的值,否则该参数将被忽略。
可以使用内置的交叉验证机制来执行超参数优化,该机制通过为params中的参数n_folds分配一个大于1的值来激活。注意,如果使用分组,则不支持交叉验证。
应该在列表中提供交叉验证参数的值。例如,如果想用L1范数正则化并使用集合{0.3,0.4,0.5}中的λ值,可在params中输入'lambda = {0.3,0.4,0.5},norm = L1,n_folds = 10'。使用'{}'和'[]'在这里都有效。
下面的参数并非都可以进行交叉验证。对于允许交叉验证的参数,其默认值以列表格式显示,例如[0.01]。
'init_stepsize = ,
decay_factor = ,
max_iter = ,
tolerance = ,
lambda = ,
norm = ,
epsilon = ,
eps_table = ,
validation_result = ,
n_folds = ,
class_weight = ' - init_stepsize:缺省值为[0.01],初始学习率。通常需要一个小值来确保收敛,而较大的值在训练期间提供了更多的进展空间。由于最佳值取决于数据的条件数量,因此实践中通常使用内置的交叉验证在指数范围中进行搜索,例如,"init_stepsize = [1, 0.1, 0.001]"。为了减少训练时间,通常在二次采样数据集上运行交叉验证,因为这通常提供整个数据集的条件数的良好估计。然后可以在整个数据集上运行生成的init_stepsize。
- decay_factor:缺省值为[0.9]。控制学习率变化:0表示恒定速率; <-1表示反比例缩放,即stepsize = init_stepsize /iteration; > 0意味着指数衰减,即stepsize = init_stepsize *decay_factor^iteration。
- max_iter:缺省值为[100],允许的最大迭代数。
- tolerance:缺省值为1e-10,结束迭代的条件。当连续两次迭代的训练模型之间的差值小于tolerance或者迭代次数大于max_iter时,停止训练。
- lambda:缺省值为[0.01],正则化参数,必须非负。
- norm:缺省值为‘L2’,正规化的名称,可为‘L2’或‘L1’。
- epsilon:缺省值为[0.01],决定ε-递归的ε值,分类时忽略。在训练模型时,估计标签和实际标签之间的差异小于ε将被忽略。较大的ε将产生具有较少支持向量的模型。一般来说,建议ε应随噪声数据增加而增加,并随样品数量减少。
- eps_table:缺省值为NULL,包含不同组的epsilon值的输入表名称,grouping_col为NULL时忽略。当需要不同组别的ε值不同时,定义此输入表。该表由一个名为epsilon的列组成,该列指定epsilon值,以及一个或多个grouping_col列。额外的组将被忽略,并且此表中不存在的组将使用参数epsilon中指定的epsilon值。
- validation_result:缺省值为NULL,存储交叉验证结果的表的名称,包括参数值及其平均错误值。目前0-1用于分类,平均方差用于回归。该表只在名称不是NULL的情况下创建。
- n_folds:缺省值为0,交叉验证的折数。必须至少有2折才能激活交叉验证。如果指定k>2的值,则每次折叠都用作验证集一次,而另一个k-1折叠形成训练集。
- class_weight:分类的缺省值为1,一类新颖性检测的缺省值为“balanced”,回归的缺省值为n/a。设置正类或负类的权重。如果没有给出,所有类都被设置为相同权重。如果class_weight= balanced,则y的值自动调整为与输入数据中的类频率成反比,即权重被设置为n_samples / (n_classes * bincount(y))。class_weight也可以是一个映射,为每个类赋予权重。例如。对于因变量值'a'和'b',class_weight可以是{a:2,b:3}。这将导致每个'a'元组的y值乘以2,并且每个'b'元组的y值将乘以3。对于回归,类的权重总是同一个。
6. 预测函数
(1)语法
预测函数用于估计给定新预测变量的条件均值。相同的语法用于分类,回归和新颖性检测:
svm_predict(model_table,
new_data_table,
id_col_name,
output_table)(2)参数
参数名称 |
数据类型 |
描述 |
model_table |
TEXT |
由训练函数产生的模型表。 |
new_data_table |
TEXT |
包含预测数据的表的名称。应该包含与训练期间使用的相同的特征。该表还应包含用于标识每一行的id_col_name列。 |
id_col_name |
TEXT |
输入表中id列的名称。 |
output_table |
TEXT |
输出预测写入的表的名称。如果该表名已被使用,则返回错误。 |
表4 svm_predict函数参数说明
预测函数输出表包含以下三列:
- id:每个预测的“id”,对应于new_data_table中的一行。
- prediction:为new_data_table中的每一行提供预测。对于回归,这将与decision_function相同。对于分类,这将是因变量值之一。
- decision_function:提供每个点与超平面之间的距离。
三、示例
我们将利用MADlib的SVM相关函数解决根据天气情况预测是否打高尔夫球的问题。问题描述及其已知数据参见“MADlib——基于SQL的数据挖掘解决方案(21)——分类之KNN”。
1. 准备训练数据
drop table if exists dt_golf;
create table dt_golf
( id integer not null,
"outlook" int,
temperature double precision,
humidity double precision,
windy int,
class int );
insert into dt_golf values
(1, 1,85,85,0, 0), (2, 1,80,90,1, 0), (3, 2,83,78,0, 1),
(4, 3,70,96,0, 1), (5, 3,68,80,0, 1), (6, 3,65,70,1, 0),
(7, 2,64,65,1, 1), (8, 1,72,95,0, 0), (9, 1,69,70,0, 1),
(10,3,75,80,0, 1), (11,1,75,70,1, 1), (12,2,72,90,1, 1),
(13,2,81,75,0, 1), (14,3,71,80,1, 0); 2. 使用线性模型训练分类器
drop table if exists dt_golf_svm, dt_golf_svm_summary;
select madlib.svm_classification
( 'dt_golf',
'dt_golf_svm',
'class',
'array[1, "outlook", temperature, humidity, windy]' );3. 查看线性分类模型结果
\x on
select * from dt_golf_svm;结果:
-[ RECORD 1 ]------+------------------------------------------------------------------------------------
coef | {-0.00432713875183,-0.0200483862661,0.463932931975,-0.421325305231,-0.170382962628}
loss | 24.0201945919
norm_of_gradient | 108.477372773758
num_iterations | 100
num_rows_processed | 14
num_rows_skipped | 0
dep_var_mapping | {0,1}4. 用线性模型进行预测
drop table if exists dt_golf_pred;
select madlib.svm_predict('dt_golf_svm', 'dt_golf', 'id', 'dt_golf_pred');
select t1.id, t1.class, t2.prediction, t2.decision_function,
case when class = t2.prediction then 'T' else 'F' end
from dt_golf t1 join dt_golf_pred t2 using (id) order by id;结果:
id | class | prediction | decision_function | case
----+-------+------------+--------------------+------
1 | 0 | 1 | 3.59727274822207 | F
2 | 0 | 0 | -0.999401400435932 | T
3 | 1 | 1 | 5.59863563462298 | T
4 | 1 | 0 | -8.03639636147613 | F
5 | 1 | 0 | -2.22305734173013 | F
6 | 0 | 1 | 0.428013952026874 | F
7 | 1 | 1 | 2.09075593247297 | T
8 | 0 | 0 | -6.64710841976293 | T
9 | 1 | 1 | 2.49422541508707 | T
10 | 1 | 1 | 1.02447318209487 | T
11 | 1 | 1 | 5.10744004430908 | T
12 | 1 | 0 | -4.73091324250203 | F
13 | 1 | 1 | 5.93474568636598 | T
14 | 0 | 0 | -1.00164150843313 | T
(14 rows)为了观察模型的正确性,这里就训练数据集进行预测。可以看到,使用线性模型14条记录预测错了5个。
5. 使用高斯核函数训练非线性分类器
drop table if exists
dt_golf_svm_gaussian,
dt_golf_svm_gaussian_summary,
dt_golf_svm_gaussian_random;
select madlib.svm_classification
( 'dt_golf',
'dt_golf_svm_gaussian',
'class',
'array[1, "outlook", temperature, humidity, windy]',
'gaussian',
'n_components=10',
'',
'init_stepsize=1, max_iter=200'
);这次使用高斯核函数生成非线性模型。我们指定要运行的初始步长和最大迭代次数,并选择10作为训练SVM的空间维度。n_components参数值越大,产生的模型拟合度越高,但会产生过拟合风险。该模型将是一个10维向量,而不是像线性模型那样的5个向量。
6. 查看高斯核函数分类模型结果
\x on
select * from dt_golf_svm_gaussian;结果:
-[ RECORD 1 ]------+------------------------------------------------------------------------------------------------------------------------------------------------------
coef | {-2.31367614318,2.78056086932,0.487193906431,2.44449162608,-1.83489385489,0.291183458912,4.44955544212,0.807401127481,-0.602291386893,-2.26545918234}
loss | 0.243473184802
norm_of_gradient | 0.0697815426601548
num_iterations | 184
num_rows_processed | 14
num_rows_skipped | 0
dep_var_mapping | {0,1} 7. 用高斯非线性模型进行预测
drop table if exists dt_golf_pred_gaussian;
select madlib.svm_predict
('dt_golf_svm_gaussian', 'dt_golf', 'id', 'dt_golf_pred_gaussian');
select t1.id, t1.class, t2.prediction, t2.decision_function,
case when class = t2.prediction then 'T' else 'F' end
from dt_golf t1 join dt_golf_pred_gaussian t2 using (id) order by id;结果:
id | class | prediction | decision_function | case
----+-------+------------+-------------------+------
1 | 0 | 0 | -1.75387189946328 | T
2 | 0 | 0 | -1.00586122649354 | T
3 | 1 | 1 | 1.46533752838822 | T
4 | 1 | 1 | 1.00087996595449 | T
5 | 1 | 1 | 1.18064534149082 | T
6 | 0 | 0 | -1.10258771667805 | T
7 | 1 | 1 | 1.02774696458501 | T
8 | 0 | 0 | -2.18628420555613 | T
9 | 1 | 1 | 1.18644089897747 | T
10 | 1 | 1 | 1.16863507721741 | T
11 | 1 | 1 | 4.65860062300603 | T
12 | 1 | 1 | 1.02528665961242 | T
13 | 1 | 1 | 2.73963443726011 | T
14 | 0 | 0 | -1.61538323627932 | T
(14 rows)使用高斯非线性模型的预测全部正确。
8. 使用‘balanced’参数为不平衡数据集训练模型
drop table if exists
dt_golf_svm_gaussian,
dt_golf_svm_gaussian_summary,
dt_golf_svm_gaussian_random;
select madlib.svm_classification
( 'dt_golf',
'dt_golf_svm_gaussian',
'class',
'array[1, "outlook", temperature, humidity, windy]',
'gaussian',
'n_components=10',
'',
'init_stepsize=1, max_iter=200, class_weight=balanced'
);
select * from dt_golf_svm_gaussian;结果:
-[ RECORD 1 ]------+------------------------------------------------------------------------------------------------------------------------------------------------------
coef | {-2.18145534331,3.31062345245,0.141540860754,2.36708359752,-1.82865677305,-0.275270727707,4.54041087912,0.966886454987,0.315504405212,-1.87737006094}
loss | 0.249680574733
norm_of_gradient | 0.0706654901253297
num_iterations | 184
num_rows_processed | 14
num_rows_skipped | 0
dep_var_mapping | {0,1}9. 用不平衡模型预测
drop table if exists dt_golf_pred_gaussian;
select madlib.svm_predict
('dt_golf_svm_gaussian', 'dt_golf', 'id', 'dt_golf_pred_gaussian');
select t1.id, t1.class, t2.prediction, t2.decision_function,
case when class = t2.prediction then 'T' else 'F' end
from dt_golf t1 join dt_golf_pred_gaussian t2 using (id) order by id;结果:
id | class | prediction | decision_function | case
----+-------+------------+-------------------+------
1 | 0 | 0 | -2.34442488642669 | T
2 | 0 | 0 | -1.00369614179274 | T
3 | 1 | 1 | 1.26282962942157 | T
4 | 1 | 1 | 1.00044107011296 | T
5 | 1 | 1 | 1.2460139165158 | T
6 | 0 | 0 | -1.24176161354924 | T
7 | 1 | 1 | 1.00012511351823 | T
8 | 0 | 0 | -1.88185540622382 | T
9 | 1 | 1 | 1.22073804684154 | T
10 | 1 | 1 | 1.47846097886927 | T
11 | 1 | 1 | 4.04252542659997 | T
12 | 1 | 1 | 1.00208058062533 | T
13 | 1 | 1 | 2.63821631706999 | T
14 | 0 | 0 | -1.78130113014144 | T
(14 rows)