Hadoop+ZooKeeper+HBase集群配置
转载自来源:Linux社区 作者:jpiverson
因为需要使用Hadoop环境进行测试,收集安装教程,学习一下
通常,集群里的一台机器被指定为 NameNode,另一台不同的机器被指定为JobTracker,这些机器是masters。余下的机器即作为DataNode也作为TaskTracker,这些机器是slaves。
先决条件
确保在你集群中的每个节点上都安装了所有必需软件:JDK,ssh。ssh 必须安装并且保证 sshd一直运行,并使用无密码链接的形式,以便用Hadoop 脚本管理端Hadoop守护进程。
实验环境搭建
准备工作
操作系统:Ubuntu13.04
部署:VirtualBox
在VirtualBox安装好一台Ubuntu虚拟机后,可以导出或者克隆出另外两台虚拟机。
说明:保证虚拟机的ip和主机的ip在同一个ip段,这样几个虚拟机和主机之间可以相互通信。
为了保证虚拟机的ip和主机的ip在同一个ip段,虚拟机连接设置为桥接。
准备机器:一台master,两台slave,配置每台机器的/etc/hosts保证各台机器之间通过机器名可以互访,例如:
192.168.10.203 node1
192.168.10.204 node2
192.168.10.205 node3
主机信息以在集群中的角色:
| 机器名 | IP地址 | 集群中的角色 |
|---|---|---|
| node1 | 192.168.10.203 | NameNode、JobTracker master |
| node2 | 192.168.10.204 | DataNode、TaskTracker slave |
| node3 | 192.168.10.205 | DataNode、TaskTracker slave |
创建组和用户
$ useradd hadoop
$ groupadd -G hadoop hadoop
在所有的机器上都建立相同的组(hadoop)和用户(hadoop)。(最好不要使用root安装,因为不推荐各个机器之间使用root访问 )
安装JDK
在官网下载 jdk-6u45-linux-i586.bin ,下载到/home/hadoop/目录下。将jdk安装到/usr/local,先把安装文件移动到该目录下,执行后会生成jdk1.6.0_45切换到root用户执行命令:
hadoop@node1:~$ su
密码:
root@node1:/home/hadoop#
root@node1:/home/hadoop# cd /usr/local/
root@node1:/usr/local# mkdir Java
root@node1:/usr/local# cd java
root@node1:/usr/local/java# mv /home/hadoop/jdk-6u45-linux-i586.bin .
root@node1:/usr/local/java# ./jdk-6u45-linux-i586.bin
安装完成后修改名称和权限
root@node1:/usr/local/java# cd ..
root@node1:/usr/local# chown -R hadoop:hadoop java
然后配置JDK环境
root@node1:/usr/local# su hadoop
root@node1:/usr/local# cd
hadoop@node1:~$ vim .bashrc
添加下面的内容
export JAVA_HOME=/usr/local/java/jdk1.6.0_45
export JRE_HOME=/usr/local/java/jdk1.6.0_45/jre
export CLASSPATH=.:$JAVA_HOME/lib:$JRE_HOME/lib:$CLASSPATH
export PATH=$JAVA_HOME/bin:$JRE_HOME/bin:$JAVA_HOME:$PATH
保存后退出,并使修改生效hadoop@node1:~$ source .bashrc
JDK安装完毕,执行java -verison验证是否成功
hadoop@node1:~$ java -version
java version "1.6.0_45"
Java(TM) SE Runtime Environment (build 1.6.0_45-b06)
Java HotSpot(TM) Client VM (build 20.45-b01, mixed mode, sharing)
安装ssh和配置
安装:sudo apt-get install ssh
这个安装完后,可以直接使用ssh命令 了。
执行$ netstat -nat 查看22端口是否开启了。
测试:ssh localhost。
输入当前用户的密码,回车就ok了。说明安装成功,同时ssh登录需要密码。(这种默认安装方式完后,默认配置文件是在/etc/ssh/目录下。sshd配置文件是:/etc/ssh/sshd_config)。注意:在所有机子都需要安装ssh。
配置:在Hadoop启动以后,Namenode是通过SSH(Secure Shell)来启动和停止各个datanode上的各种守护进程的,这就须要在节点之间执行指令的时候是不须要输入密码的形式,故我们须要配置SSH运用无密码公钥认证的形式。
以本文中的三台机器为例,现在node1是主节点,他须要连接node2和node3。须要确定每台机器上都安装ssh,并且datanode机器上sshd服务已经启动。
在node1上执行命令 hadoop@node1~]$ssh-keygen -t rsa -P ""
这个命令将为node1上的用户hadoop生成其空密码的密钥对,询问其保存路径时直接回车采用默认路径,直接回车。生成的密钥对id_rsa,id_rsa.pub,默认存储在/home/hadoop/.ssh目录下。然后执行命令cat id_rsa.pub >> authorized.keys。将生成的authorized_keys文件复制到每台机器的相同位置:/home/hadoop/.ssh/。最后将每天机器上的authorized_keys修改权限如下:[hadoop@node1 .ssh]$chmod 644 authorized_keys
首先设置namenode的ssh为无需密码的、自动登录
切换到hadoop用户( 保证用户hadoop可以无需密码登录,因为我们后面安装的hadoop属主是hadoop用户。)
第一次ssh会有提示信息:
The authenticity of host ‘node1 (192.168.10.203)’ can’t be established.
RSA key fingerprint is 03:e0:30:cb:6e:13:a8:70:c9:7e:cf:ff:33:2a:67:30.
Are you sure you want to continue connecting (yes/no)?
输入 yes 来继续。这会把该服务器添加到你的已知主机的列表中,下次就可以直接链接了。SSH安装和配置完成!
安装Hadoop
在官网下载hadoop-1.2.0.tar.gz,下载到/home/hadoop/目录下。
#切换为root用户,执行如下命令
root@node1:/home/hadoop# mv hadoop-1.2.0.tar.gz /usr/local
root@node1:/home/hadoop# cd /usr/local
root@node1:/usr/local# tar -zxvf hadoop-1.2.0.tar.gz
root@node1:/usr/local# mv hadoop-1.2.0 hadoop
root@node1:/usr/local# chown -R hadoop:hadoop hadopp
1 ) 安装Hadoop集群通常要将安装软件解压到集群内的所有机器上。并且安装路径要一致,如果我们用HADOOP_HOME指代安装的根路径,通常,集群里的所有机器的HADOOP_HOME路径相同。
2 ) 如果集群内机器的环境完全一样,可以在一台机器上配置好,然后把配置好的软件即hadoop整个文件夹拷贝到其他机器的相同位置即可。
3 ) 可以将Master上的Hadoop通过scp拷贝到每一个Slave相同的目录下,同时根据每一个Slave的Java_HOME 的不同修改其hadoop-env.sh 。
4) 为了方便,使用hadoop命令或者start-all.sh等命令,修改Master上/home/hadoop/.bashrc 新增以下内容:
export HADOOP_HOME=/usr/local/hadoop
export PATH=$PATH:$HADOOP_HOME/bin
- 修改完毕后,执行source .bashrc 来使其生效。
6)配置conf/hadoop-env.sh文件
#添加
export JAVA_HOME=/usr/local/java/jdk1.6.0_45 # 这里修改为你的jdk的安装位置
集群配置(所有节点相同)
配置文件:conf/core-site.xml
<configuration>
<property>
<name>fs.default.namename>
<value>hdfs://node1:49000value>
property>
<property>
<name>Hadoop.tmp.dirname>
<value>/home/hadoop/hadoop_home/varvalue>
property>
configuration>
1)fs.default.name是NameNode的URI。hdfs://主机名:端口/
2)hadoop.tmp.dir :Hadoop的默认临时路径,这个最好配置,如果在新增节点或者其他情况下莫名其妙的DataNode启动不了,就删除此文件中的tmp目录即可。不过如果删除了NameNode机器的此目录,那么就需要重新执行NameNode格式化的命令。
配置文件:conf/mapred-site.xml
<configuration>
<property>
<name>mapred.job.trackername>
<value>node1:49001value>
property>
<property>
<name>mapred.local.dirname>
<value>/home/hadoop/hadoop_home/varvalue>
property>
configuration>
1)mapred.job.tracker是JobTracker的主机(或者IP)和端口。主机:端口。
配置文件:conf/hdfs-site.xml
<configuration>
<property>
<name>dfs.name.dirname>
<value>/home/hadoop/name1, /home/hadoop/name2value> #hadoop的name目录路径
<description> description>
property>
<property>
<name>dfs.data.dirname>
<value>/home/hadoop/data1, /home/hadoop/data2value>
<description> description>
property>
<property>
<name>dfs.replicationname>
<value>2vaue>
property>
configuration>
1) dfs.name.dir是NameNode持久存储名字空间及事务日志的本地文件系统路径。 当这个值是一个逗号分割的目录列表时,nametable数据将会被复制到所有目录中做冗余备份。
2) dfs.data.dir是DataNode存放块数据的本地文件系统路径,逗号分割的列表。 当这个值是逗号分割的目录列表时,数据将被存储在所有目录下,通常分布在不同设备上。
3)dfs.replication是数据需要备份的数量,默认是3,如果此数大于集群的机器数会出错。
注意:此处的name1、name2、data1、data2目录不能预先创建,hadoop格式化时会自动创建,如果预先创建反而会有问题。
配置masters和slaves主从结点
配置conf/masters和conf/slaves来设置主从结点,注意最好使用主机名,并且保证机器之间通过主机名可以互相访问,每个主机名一行。
vi masters:
输入:
node1
vi slaves:
输入:
node2
node3
配置结束,把配置好的hadoop文件夹拷贝到其他集群的机器中,并且保证上面的配置对于其他机器而言正确,例如:如果其他机器的Java安装路径不一样,要修改conf/hadoop-env.sh
$ scp -r /home/hadoop/hadoop-0.20.203 root@node2: /home/hadoop/
hadoop启动
格式化一个新的分布式文件系统
先格式化一个新的分布式文件系统
$ cd hadoop-0.20.203
$ bin/hadoop namenode -format
成功情况下系统输出:
12/02/06 00:46:50 INFO namenode.NameNode:STARTUP_MSG:
/************************************************************
STARTUP_MSG: Starting NameNode
STARTUP_MSG: host = Ubuntu/127.0.1.1
STARTUP_MSG: args = [-format]
STARTUP_MSG: version = 0.20.203.0
STARTUP_MSG: build =http://svn.apache.org/repos/asf/hadoop/common/branches/branch-0.20-security-203-r 1099333; compiled by 'oom' on Wed May 4 07:57:50 PDT 2011
************************************************************/
12/02/0600:46:50 INFO namenode.FSNamesystem: fsOwner=root,root
12/02/06 00:46:50 INFO namenode.FSNamesystem:supergroup=supergroup
12/02/06 00:46:50 INFO namenode.FSNamesystem:isPermissionEnabled=true
12/02/06 00:46:50 INFO common.Storage: Imagefile of size 94 saved in 0 seconds.
12/02/06 00:46:50 INFO common.Storage: Storagedirectory /opt/hadoop/hadoopfs/name1 has been successfully formatted.
12/02/06 00:46:50 INFO common.Storage: Imagefile of size 94 saved in 0 seconds.
12/02/06 00:46:50 INFO common.Storage: Storagedirectory /opt/hadoop/hadoopfs/name2 has been successfully formatted.
12/02/06 00:46:50 INFO namenode.NameNode:SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode atv-jiwan-ubuntu-0/127.0.0.1
************************************************************/
查看输出保证分布式文件系统格式化成功
执行完后可以到master机器上看到/home/hadoop//name1和/home/hadoop/name2两个目录。在主节点master上面启动hadoop,主节点会启动所有从节点的hadoop。
启动所有节点
启动方式1:$ bin/start-all.sh (同时启动HDFS和Map/Reduce)
系统输出:
starting namenode, logging to /usr/local/hadoop/logs/hadoop-hadoop-namenode-ubuntu.out
node2: starting datanode, loggingto /usr/local/hadoop/logs/hadoop-hadoop-datanode-ubuntu.out
node3: starting datanode, loggingto /usr/local/hadoop/logs/hadoop-hadoop-datanode-ubuntu.out
node1: starting secondarynamenode,logging to /usr/local/hadoop/logs/hadoop-hadoop-secondarynamenode-ubuntu.out
starting jobtracker, logging to/usr/local/hadoop/logs/hadoop-hadoop-jobtracker-ubuntu.out
node2: starting tasktracker,logging to /usr/local/hadoop/logs/hadoop-hadoop-tasktracker-ubuntu.out
node3: starting tasktracker,logging to /usr/local/hadoop/logs/hadoop-hadoop-tasktracker-ubuntu.out
As you can see in slave's output above, it will automatically format it's storage directory(specified by dfs.data.dir) if it is not formattedalready. It will also create the directory if it does not exist yet.
执行完后可以到master(node1)和slave(node1,node2)机器上看到/home/hadoop/hadoopfs/data1和/home/hadoop/data2两个目录。
启动方式2:启动Hadoop集群需要启动HDFS集群和Map/Reduce集群。
在分配的NameNode上,运行下面的命令启动HDFS:$ bin/start-dfs.sh(单独启动HDFS集群)
bin/start-dfs.sh脚本会参照NameNode上 H A D O O P C O N F D I R / s l a v e s 文 件 的 内 容 , 在 所 有 列 出 的 s l a v e 上 启 动 D a t a N o d e 守 护 进 程 。 在 分 配 的 J o b T r a c k e r 上 , 运 行 下 面 的 命 令 启 动 M a p / R e d u c e : ‘ {HADOOP_CONF_DIR}/slaves文件的内容,在所有列出的slave上启动DataNode守护进程。在分配的JobTracker上,运行下面的命令启动Map/Reduce:` HADOOPCONFDIR/slaves文件的内容,在所有列出的slave上启动DataNode守护进程。在分配的JobTracker上,运行下面的命令启动Map/Reduce:‘bin/start-mapred.sh (单独启动Map/Reduce)`
bin/start-mapred.sh脚本会参照JobTracker上${HADOOP_CONF_DIR}/slaves文件的内容,在所有列出的slave上启动TaskTracker守护进程。
关闭所有节点
从主节点master关闭hadoop,主节点会关闭所有从节点的hadoop。
$ bin/stop-all.sh
Hadoop守护进程的日志写入到 ${HADOOP_LOG_DIR} 目录 (默认是 ${HADOOP_HOME}/logs). ${HADOOP_HOME}就是安装路径
测试
1)浏览NameNode和JobTracker的网络接口,它们的地址默认为:
NameNode - http://node1:50070/
JobTracker - http://node2:50030/
3) 使用netstat –nat查看端口49000和49001是否正在使用。
4) 使用jps查看进程
要想检查守护进程是否正在运行,可以使用 jps 命令(这是用于 JVM 进程的ps 实用程序)。这个命令列出 5 个守护进程及其进程标识符。
HDFS常用操作
Hadoopdfs -ls 列出HDFS下的文件
hadoop dfs -ls in 列出HDFS下某个文档中的文件
hadoop dfs -put test1.txt test 上传文件到指定目录并且重新命名,只有所有的DataNode都接收完数据才算成功
hadoop dfs -get in getin 从HDFS获取文件并且重新命名为getin,同put一样可操作文件也可操作目录
hadoop dfs -rmr out 删除指定文件从HDFS上
hadoop dfs -cat in/* 查看HDFS上in目录的内容
hadoop dfsadmin -report 查看HDFS的基本统计信息,结果如下
hadoop dfsadmin -safemode leave 退出安全模式
hadoop dfsadmin -safemode enter 进入安全模式
添加节点
可扩展性是HDFS的一个重要特性,首先在新加的节点上安装hadoop,然后修改$HADOOP_HOME/conf/master文件,加入 NameNode主机名,然后在NameNode节点上修改$HADOOP_HOME/conf/slaves文件,加入新加节点主机名,再建立到新加节点无密码的SSH连接
运行启动命令:start-all.sh
然后可以通过http://(Masternode的主机名):50070查看新添加的DataNode
负载均衡
start-balancer.sh,可以使DataNode节点上选择策略重新平衡DataNode上的数据块的分布
结束语:遇到问题时,先查看logs,很有帮助。
HBase
快速单机安装:
在单机安装Hbase的方法。会引导你通过shell创建一个表,插入一行,然后删除它,最后停止Hbase。只要10分钟就可以完成以下的操作。
下载解压最新版本
选择一个 Apache 下载镜像:http://www.apache.org/dyn/closer.cgi/hbase/,下载一个releases版本的,目前是0.94.8.然后下载后缀为 .tar.gz 的文件; 例如 hbase-0.94.8.tar.gz
$ tar xfz hbase-0.94.8.tar.gz
$ cd hbase-0.94.8
现在你已经可以启动Hbase了。但是你可能需要先编辑 conf/hbase-site.xml 去配置hbase.rootdir,来选择Hbase将数据写到哪个目录
<configuration>
<property>
<name>hbase.rootdirname>
<value>file:///DIRECTORY/hbasevalue>
property>
configuration>
将 DIRECTORY 替换成你期望写文件的目录. 默认 hbase.rootdir 是指向 /tmp/hbase-${user.name} ,也就说你会在重启后丢失数据(重启的时候操作系统会清理/tmp目录)
启动 HBase
现在启动Hbase: $ ./bin/start-hbase.sh
starting Master, logging to logs/hbase-user-master-example.org.out
现在你运行的是单机模式的Hbaes。所以的服务都运行在一个JVM上,包括Hbase和Zookeeper。Hbase的日志放在logs目录,当你启动出问题的时候,可以检查这个日志。
Hbase Shell 练习
用shell连接你的Hbase
$ ./bin/hbase shell
HBase Shell; enter 'help' for list of supported commands.
Type "exit" to leave the HBase Shell
Version: 0.90.0, r1001068, Fri Sep 24 13:55:42 PDT 2010
hbase(main):001:0>
输入 help 然后 可以看到一列shell命令。这里的帮助很详细,要注意的是表名,行和列需要加引号。
创建一个名为 test 的表,这个表只有一个column family 为 cf。可以列出所有的表来检查创建情况,然后插入些值。
hbase(main):003:0> create 'test', 'cf'
0 row(s) in 1.2200 seconds
hbase(main):003:0> list 'table'
test
1 row(s) in 0.0550 seconds
hbase(main):004:0> put 'test', 'row1', 'cf:a', 'value1'
0 row(s) in 0.0560 seconds
hbase(main):005:0> put 'test', 'row2', 'cf:b', 'value2'
0 row(s) in 0.0370 seconds
hbase(main):006:0> put 'test', 'row3', 'cf:c', 'value3'
0 row(s) in 0.0450 seconds
以上我们分别插入了3行。第一个行key为row1, 列为 cf:a, 值是 value1。Hbase中的列是由 column family前缀和列的名字组成的,以冒号间隔。例如这一行的列名就是a.
检查插入情况.
Scan这个表,操作如下
hbase(main):007:0> scan 'test'
ROW COLUMN+CELL
row1 column=cf:a, timestamp=1288380727188, value=value1
row2 column=cf:b, timestamp=1288380738440, value=value2
row3 column=cf:c, timestamp=1288380747365, value=value3
3 row(s) in 0.0590 seconds
Get一行,操作如下
hbase(main):008:0> get 'test', 'row1'
COLUMN CELL
cf:a timestamp=1288380727188, value=value1
1 row(s) in 0.0400 seconds
disable 再 drop 这张表,可以清除你刚刚的操作
hbase(main):012:0> disable 'test'
0 row(s) in 1.0930 seconds
hbase(main):013:0> drop 'test'
0 row(s) in 0.0770 seconds
关闭shell hbase(main):014:0> exit
停止 HBase
运行停止脚本来停止HBase $ ./bin/stop-hbase.sh
Hbase集群安装前注意
1) Java:(Hadoop已经安装了)
2) Hadoop1.2.0 已经正确安装,并且可以启动 HDFS 系统, 可参考的Hadoop安装文档:hadoop+zookeeper+hbase集群配置(一)http://www.linuxidc.com/Linux/2013-06/86347.htm
3) NTP:集群的时钟要保证基本的一致。稍有不一致是可以容忍的,但是很大的不一致会 造成奇怪的行为。 运行 NTP 或者其他什么东西来同步你的时间.
如果你查询的时候或者是遇到奇怪的故障,可以检查一下系统时间是否正确!
设置集群各个节点时钟:date -s “2012-02-13 14:00:00”
4) ulimit 和 nproc:
Base是数据库,会在同一时间使用很多的文件句柄。大多数linux系统使用的默认值1024是不能满足的,会导致FAQ: Why do I see “java.io.IOException…(Too manyopen files)” in my logs?异常。还可能会发生这样的异常
2010-04-06 03:04:37,542 INFO org.apache.hadoop.hdfs.DFSClient: ExceptionincreateBlockOutputStream java.io.EOFException
2010-04-06 03:04:37,542 INFO org.apache.hadoop.hdfs.DFSClient:Abandoning block blk_-6935524980745310745_1391901
所以你需要修改你的最大文件句柄限制。可以设置到10k. 你还需要修改 hbase 用户的nproc,如果过低会造成 OutOfMemoryError异常。
需要澄清的,这两个设置是针对操作系统的,不是Hbase本身的。有一个常见的错误是Hbase运行的用户,和设置最大值的用户不是一个用户。在Hbase启动的时候,第一行日志会现在ulimit信息,所以你最好检查一下。
设置ulimit:
如果你使用的是Ubuntu,你可以这样设置:
在文件 /etc/security/limits.conf 添加一行,如 hadoop - nofile 32768
可以把 hadoop 替换成你运行Hbase和Hadoop的用户。如果你用两个用户,你就需要配两个。还有配nproc hard 和 softlimits. 如 hadoop soft/hard nproc 32000
在 /etc/pam.d/common-session 加上这一行: session required pam_limits.so
否则在 /etc/security/limits.conf上的配置不会生效.
还有注销再登录,这些配置才能生效!
7 )修改Hadoop HDFS Datanode同时处理文件的上限:dfs.datanode.max.xcievers
一个 Hadoop HDFS Datanode 有一个同时处理文件的上限. 这个参数叫 xcievers (Hadoop的作者把这个单词拼错了). 在你加载之前,先确认下你有没有配置这个文件conf/hdfs-site.xml里面的xceivers参数,至少要有4096:
<property>
<name>dfs.datanode.max.xcieversname>
<value>4096value>
property>
对于HDFS修改配置要记得重启。如果没有这一项配置,你可能会遇到奇怪的失败。你会在Datanode的日志中看到xcievers exceeded,但是运行起来会报 missing blocks错误。例如: 02/12/1220:10:31 INFO hdfs.DFSClient: Could not obtain blockblk_XXXXXXXXXXXXXXXXXXXXXX_YYYYYYYY from any node: java.io.IOException: No livenodes contain current block. Will get new block locations from namenode andretry…
8)继承hadoop安装的说明:
每个机子/etc/hosts
192.168.10.203 node1 (master)
192.168.10.204 node2 (slave)
192.168.10.205 node3 (slave)
- 继续使用hadoop用户安装
Chown –R hadoop /usr/local/hbase
分布式模式配置
配置conf/hbase-env.sh
export JAVA_HOME=/usr/local/java/jdk1.6.0_45/
export HBASE_MANAGES_ZK=true
不管是什么模式,你都需要编辑 conf/hbase-env.sh来告知Hbase java的安装路径.在这个文件里你还可以设置Hbase的运行环境,诸如 heapsize和其他 JVM有关的选项, 还有Log文件地址,等等. 设置 JAVA_HOME指向 java安装的路径.
一个分布式运行的Hbase依赖一个zookeeper集群。所有的节点和客户端都必须能够访问zookeeper。默认的情况下Hbase会管理一个zookeep集群。这个集群会随着Hbase的启动而启动。当然,你也可以自己管理一个zookeeper集群,但需要配置Hbase。你需要修改conf/hbase-env.sh里面的HBASE_MANAGES_ZK 来切换。这个值默认是true的,作用是让Hbase启动的时候同时也启动zookeeper.
让Hbase使用一个现有的不被Hbase托管的Zookeep集群,需要设置 conf/hbase-env.sh文件中的HBASE_MANAGES_ZK 属性为 false
Tell HBase whether it should manage it’s own instanceof Zookeeper or not.
exportHBASE_MANAGES_ZK=false
配置conf/hbase-site.xml
<configuration>
<property>
<name>hbase.rootdirname>
<value>hdfs://node1:49002/hbasevalue>
<description>The directory shared byRegionServers.
description>
property>
<property>
<name>hbase.cluster.distributedname>
<value>truevalue>
<description>The mode the clusterwill be in. Possible values are
false: standalone and pseudo-distributedsetups with managed Zookeeper
true: fully-distributed with unmanagedZookeeper Quorum (see hbase-env.sh)
description>
property>
<property>
<name>hbase.zookeeper.property.clientPortname>
<value>2181value>
<description>Property fromZooKeeper's config zoo.cfg.
The port at which the clients willconnect.
description>
property>
<property>
<name>hbase.zookeeper.quorumname>
<value>node1,node2,node3value>
<description>Comma separated listof servers in the ZooKeeper Quorum.
For example,"host1.mydomain.com,host2.mydomain.com,host3.mydomain.com".
By default this is set to localhost forlocal and pseudo-distributed modes
of operation. For a fully-distributedsetup, this should be set to a full
list of ZooKeeper quorum servers. IfHBASE_MANAGES_ZK is set in hbase-env.sh
this is the list of servers which we willstart/stop ZooKeeper on.
description>
property>
<property>
<name>hbase.zookeeper.property.dataDirname>
<value>/home/hadoop/zookeepervalue>
<description>Property fromZooKeeper's config zoo.cfg.
The directory where the snapshot isstored.
description>
property>
configuration>
要想运行完全分布式模式,加一个属性 hbase.cluster.distributed 设置为 true 然后把 hbase.rootdir 设置为HDFS的NameNode的位置。 例如,你的namenode运行在node1,端口是49002 你期望的目录是 /hbase,使用如下的配置:hdfs://node1:49002/hbase
hbase.rootdir:这个目录是region server的共享目录,用来持久化Hbase。URL需要是’完全正确’的,还要包含文件系统的scheme。例如,要表示hdfs中的’/hbase’目录,namenode 运行在node1的9090端口。则需要设置为hdfs://node1:49002/hbase。默认情况下Hbase是写到/tmp的。不改这个配置,数据会在重启的时候丢失。默认: file:///tmp/hbase-${user.name}/hbase
hbase.cluster.distributed :Hbase的运行模式。false是单机模式,true是分布式模式。若为false,Hbase和Zookeeper会运行在同一个JVM里面。默认: false
在hbase-site.xml配置zookeeper:当Hbase管理zookeeper的时候,你可以通过修改zoo.cfg来配置zookeeper,一个更加简单的方法是在 conf/hbase-site.xml里面修改zookeeper的配置。Zookeeer的配置是作为property写在 hbase-site.xml里面的。对于zookeepr的配置,你至少要在 hbase-site.xml中列出zookeepr的ensemble servers,具体的字段是 hbase.zookeeper.quorum. 该这个字段的默认值是 localhost,这个值对于分布式应用显然是不可以的. (远程连接无法使用)。
hbase.zookeeper.property.clientPort:ZooKeeper的zoo.conf中的配置。 客户端连接的端口。
hbase.zookeeper.quorum:Zookeeper集群的地址列表,用逗号分割。如:“host1.mydomain.com,host2.mydomain.com,host3.mydomain.com”.默认是localhost,是给伪分布式用的。要修改才能在完全分布式的情况下使用。如果在hbase-env.sh设置了HBASE_MANAGES_ZK,这些ZooKeeper节点就会和Hbase一起启动。默认: localhost
运行一个zookeeper也是可以的,但是在生产环境中,你最好部署3,5,7个节点。部署的越多,可靠性就越高,当然只能部署奇数个,偶数个是不可以的。你需要给每个zookeeper 1G左右的内存,如果可能的话,最好有独立的磁盘。 (独立磁盘可以确保zookeeper是高性能的。).如果你的集群负载很重,不要把Zookeeper和RegionServer运行在同一台机器上面。就像DataNodes 和 TaskTrackers一样
hbase.zookeeper.property.dataDir:ZooKeeper的zoo.conf中的配置。 快照的存储位置
把ZooKeeper保存数据的目录地址改掉。默认值是 /tmp ,这里在重启的时候会被操作系统删掉,可以把它修改到 /home/hadoop/zookeeper (这个路径hadoop用户拥有操作权限)
对于独立的Zookeeper,要指明Zookeeper的host和端口。可以在 hbase-site.xml中设置, 也可以在Hbase的CLASSPATH下面加一个zoo.cfg配置文件。 HBase 会优先加载 zoo.cfg 里面的配置,把hbase-site.xml里面的覆盖掉.
参见 http://www.yankay.com/wp-content/hbase/book.html#hbase_default_configurations可以查找hbase.zookeeper.property 前缀,找到关于zookeeper的配置。
配置conf/regionservers
Node1
Node2
完全分布式模式的还需要修改conf/regionservers. 在这里列出了你希望运行的全部 HRegionServer,一行写一个host (就像Hadoop里面的 slaves 一样). 列在这里的server会随着集群的启动而启动,集群的停止而停止.
运行和确认你的安装
当Hbase托管ZooKeeper的时候
当Hbase托管ZooKeeper的时候Zookeeper集群的启动是Hbase启动脚本的一部分。首先确认你的HDFS是运行着的。你可以运行Hadoop_HOME中的 bin/start-hdfs.sh 来启动HDFS。你可以通过put命令来测试放一个文件,然后有get命令来读这个文件。通常情况下Hbase是不会运行mapreduce的。所以比不需要检查这些。
用如下命令启动Hbase:bin/start-hbase.sh 这个脚本在HBASE_HOME目录里面。
你现在已经启动Hbase了。Hbase把log记在 logs 子目录里面. 当Hbase启动出问题的时候,可以看看Log.
Hbase也有一个界面,上面会列出重要的属性。默认是在Master的60010端口上H (HBase RegionServers 会默认绑定 60020端口,在端口60030上有一个展示信息的界面 ).如果Master运行在 node1,端口是默认的话,你可以用浏览器在 http://node:60010看到主界面. .
一旦Hbase启动,可以看到如何建表,插入数据,scan你的表,还有disable这个表,最后把它删掉。
可以在Hbase Shell停止Hbase $./bin/stop-hbase.sh
停止操作需要一些时间,你的集群越大,停的时间可能会越长。如果你正在运行一个分布式的操作,要确认在Hbase彻底停止之前,Hadoop不能停.
独立的zookeeper启动
除了启动habse,执行:bin/start-hbase.sh 启动habse
你需要自己去运行zookeeper:${HBASE_HOME}/bin/hbase-daemons.sh {start,stop} zookeeper
你可以用这条命令启动ZooKeeper而不启动Hbase. HBASE_MANAGES_ZK 的值是 false, 如果你想在Hbase重启的时候不重启ZooKeeper,你可以这样。
测试
可以使用jps查看进程:在master上:
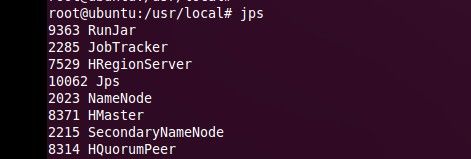
在node2,node3(slave节点)上

通过浏览器查看60010端口:

在安装中出现的问题
1 )用./start-hbase.sh启动HBase后,执行hbase shell
# bin/hbase shell
HBase Shell; enter 'help' for list of supported commands.
Version: 0.20.6, rUnknown, Thu Oct 28 19:02:04 CST 2010
接着创建表时候出现如下情况:hbase(main):001:0> create ‘test’,’'c
NativeException: org.apache.Hadoop.hbase.MasterNotRunningException: null
jps下,发现主节点上HMaster没有启动,查理HBase log(logs/hbase-hadoop-master-Ubuntu.log)里有下面异常:
FATAL org.apache.hadoop.hbase.master.HMaster: Unhandled exception. Starting shutdown.
Java.io.IOException: Call to node1/10.64.56.76:49002 failed on local exception: java.io.EOFException
解决:
从hadoop_home/下面cp一个hadoop/hadoop-core-1.2.0.jar到hbase_home/lib下。
因为Hbase建立在Hadoop之上,所以他用到了hadoop.jar,这个Jar在 lib 里面。这个jar是hbase自己打了branch-0.20-append 补丁的hadoop.jar. Hadoop使用的hadoop.jar和Hbase使用的 必须 一致。所以你需要将 Hbaselib 目录下的hadoop.jar替换成Hadoop里面的那个,防止版本冲突。比方说CDH的版本没有HDFS-724而branch-0.20-append里面有,这个HDFS-724补丁修改了RPC协议。如果不替换,就会有版本冲突,继而造成严重的出错,Hadoop会看起来挂了。
再用./start-hbase.sh启动HBase后,jps下,发现主节点上HMaster还是没有启动,在HBase log里有下面异常:
FATAL org.apache.hadoop.hbase.master.HMaster: Unhandled exception. Starting shutdown.
java.lang.NoClassDefFoundError: org/apache/commons/configuration/Configuration
解决:
在NoClassDefFoundError,缺少 org/apache/commons/configuration/Configuration
果断给他加一个commons-configuration包,
从hadoop_home/lib下面cp一个hadoop/lib/commons-configuration-1.6.jar到hbase_home/lib下。
(集群上所有机子的hbase配置都需要一样)
2 ) 注意事项:
1、先启动hadoop后,再开启hbase
2、去掉hadoop的安全模式:hadoop dfsadmin -safemode leave
3、把/etc/hosts里的ubuntu的IP改为服务器当前的IP
4、确认hbase的hbase-site.xml中
<name>hbase.rootdirname>
<value>hdfs://node:49002/hbasevalue>
与hadoop的core-site.xml中
<name>fs.default.namename>
<value>hdfs://node:49002/hbasevalue>
红字部分保持一致
6、重新执行./start-hbase.sh之前,先kill掉当前的hbase和zookeeper进程
PS:遇到问题时,先查看logs,很有帮助。
HBase 官方文档,全面介绍hbase安装配置:
http://www.yankay.com/wp-content/hbase/book.html#hbase_default_configurations