editplus json文本格式化
json格式化脚本下载:https://download.csdn.net/download/sanzhongguren/10367602
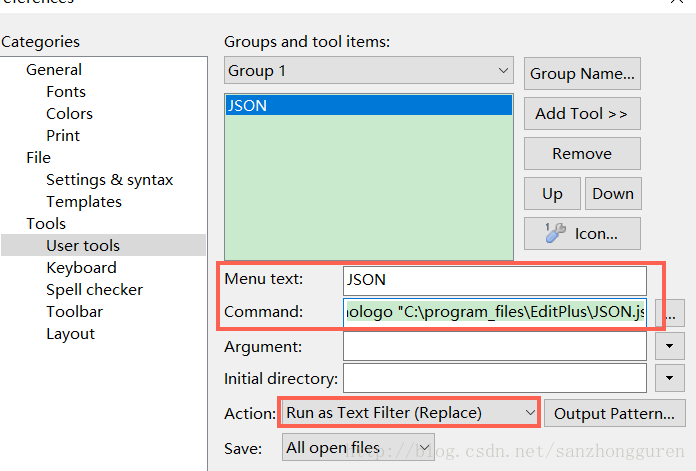
Tools->Configure User Tools->User tools->Add Tool->Program

Menu text:名称随意
Command:Cscript.exe /nologo C:\program_files\EditPlus\jsFormatter.js
如果提示找不到文件可以尝试用英文引号将路径引起来
格式化之前

CTRL+1 格式化之后

没有下载积分的可以复制以下脚本代码
//初始化选项
var indent_size = 1;//缩进空格数, 为1时使用制表符缩进
var indent_char = ' ';//缩进字符
var preserve_newlines = false;//是否保留空行, 默认不保留
//程序开始
var input = "";
while(!WScript.StdIn.AtEndOfStream)
{
input += WScript.StdIn.ReadAll();
}
if (indent_size == 1) {
indent_char = '\t';
}
var js_source = input.replace(/^\s+/, '');
var formated_code='';
if (js_source && js_source[0] !== '<') {
formated_code =js_beautify(js_source, {indent_size: indent_size, indent_char: indent_char, preserve_newlines:preserve_newlines});
}
if(!formated_code.length==0)
WScript.Echo(formated_code);
else
WScript.Echo('Are you sure your input is javascript source file?');
/*
JS Beautifier
---------------
$Date$
$Revision$
Written by Einars Lielmanis,
http://elfz.laacz.lv/beautify/
Originally converted to javascript by Vital,
http://my.opera.com/Vital/blog/2007/11/21/javascript-beautify-on-javascript-translated
You are free to use this in any way you want, in case you find this useful or working for you.
Usage:
js_beautify(js_source_text);
js_beautify(js_source_text, options);
The options are:
indent_size (default 4) — indentation size,
indent_char (default space) — character to indent with,
preserve_newlines (default true) — whether existing line breaks should be preserved,
indent_level (default 0) — initial indentation level, you probably won't need this ever,
e.g
js_beautify(js_source_text, {indent_size: 1, indent_char: '\t'});
*/
function js_beautify(js_source_text, options)
{
var input, output, token_text, last_type, last_text, last_word, current_mode, modes, indent_string;
var whitespace, wordchar, punct, parser_pos, line_starters, in_case;
var prefix, token_type, do_block_just_closed, var_line, var_line_tainted, if_line_flag;
var indent_level;
var options = options || {};
var opt_indent_size = options['indent_size'] || 4;
var opt_indent_char = options['indent_char'] || ' ';
var opt_preserve_newlines =
typeof options['preserve_newlines'] === 'undefined' ? true : options['preserve_newlines'];
var opt_indent_level = options['indent_level'] || 0; // starting indentation
function trim_output()
{
while (output.length && (output[output.length - 1] === ' ' || output[output.length - 1] === indent_string)) {
output.pop();
}
}
function print_newline(ignore_repeated)
{
ignore_repeated = typeof ignore_repeated === 'undefined' ? true: ignore_repeated;
if_line_flag = false;
trim_output();
if (!output.length) {
return; // no newline on start of file
}
if (output[output.length - 1] !== "\n" || !ignore_repeated) {
output.push("\n");
}
for (var i = 0; i < indent_level; i++) {
output.push(indent_string);
}
}
function print_space()
{
var last_output = output.length ? output[output.length - 1] : ' ';
if (last_output !== ' ' && last_output !== '\n' && last_output !== indent_string) { // prevent occassional duplicate space
output.push(' ');
}
}
function print_token()
{
output.push(token_text);
}
function indent()
{
indent_level++;
}
function unindent()
{
if (indent_level) {
indent_level--;
}
}
function remove_indent()
{
if (output.length && output[output.length - 1] === indent_string) {
output.pop();
}
}
function set_mode(mode)
{
modes.push(current_mode);
current_mode = mode;
}
function restore_mode()
{
do_block_just_closed = current_mode === 'DO_BLOCK';
current_mode = modes.pop();
}
function in_array(what, arr)
{
for (var i = 0; i < arr.length; i++)
{
if (arr[i] === what) {
return true;
}
}
return false;
}
function get_next_token()
{
var n_newlines = 0;
var c = '';
do {
if (parser_pos >= input.length) {
return ['', 'TK_EOF'];
}
c = input.charAt(parser_pos);
parser_pos += 1;
if (c === "\n") {
n_newlines += 1;
}
}
while (in_array(c, whitespace));
var wanted_newline = false;
if (opt_preserve_newlines) {
if (n_newlines > 1) {
for (var i = 0; i < 2; i++) {
print_newline(i === 0);
}
}
wanted_newline = (n_newlines === 1);
}
if (in_array(c, wordchar)) {
if (parser_pos < input.length) {
while (in_array(input.charAt(parser_pos), wordchar)) {
c += input.charAt(parser_pos);
parser_pos += 1;
if (parser_pos === input.length) {
break;
}
}
}
// small and surprisingly unugly hack for 1E-10 representation
if (parser_pos !== input.length && c.match(/^[0-9]+[Ee]$/) && input.charAt(parser_pos) === '-') {
parser_pos += 1;
var t = get_next_token(parser_pos);
c += '-' + t[0];
return [c, 'TK_WORD'];
}
if (c === 'in') { // hack for 'in' operator
return [c, 'TK_OPERATOR'];
}
if (wanted_newline && last_type !== 'TK_OPERATOR' && !if_line_flag) {
print_newline();
}
return [c, 'TK_WORD'];
}
if (c === '(' || c === '[') {
return [c, 'TK_START_EXPR'];
}
if (c === ')' || c === ']') {
return [c, 'TK_END_EXPR'];
}
if (c === '{') {
return [c, 'TK_START_BLOCK'];
}
if (c === '}') {
return [c, 'TK_END_BLOCK'];
}
if (c === ';') {
return [c, 'TK_SEMICOLON'];
}
if (c === '/') {
var comment = '';
// peek for comment /* ... */
if (input.charAt(parser_pos) === '*') {
parser_pos += 1;
if (parser_pos < input.length) {
while (! (input.charAt(parser_pos) === '*' && input.charAt(parser_pos + 1) && input.charAt(parser_pos + 1) === '/') && parser_pos < input.length) {
comment += input.charAt(parser_pos);
parser_pos += 1;
if (parser_pos >= input.length) {
break;
}
}
}
parser_pos += 2;
return ['/*' + comment + '*/', 'TK_BLOCK_COMMENT'];
}
// peek for comment // ...
if (input.charAt(parser_pos) === '/') {
comment = c;
while (input.charAt(parser_pos) !== "\x0d" && input.charAt(parser_pos) !== "\x0a") {
comment += input.charAt(parser_pos);
parser_pos += 1;
if (parser_pos >= input.length) {
break;
}
}
parser_pos += 1;
if (wanted_newline) {
print_newline();
}
return [comment, 'TK_COMMENT'];
}
}
if (c === "'" || // string
c === '"' || // string
(c === '/' &&
((last_type === 'TK_WORD' && last_text === 'return') || (last_type === 'TK_START_EXPR' || last_type === 'TK_END_BLOCK' || last_type === 'TK_OPERATOR' || last_type === 'TK_EOF' || last_type === 'TK_SEMICOLON')))) { // regexp
var sep = c;
var esc = false;
var resulting_string = '';
if (parser_pos < input.length) {
while (esc || input.charAt(parser_pos) !== sep) {
resulting_string += input.charAt(parser_pos);
if (!esc) {
esc = input.charAt(parser_pos) === '\\';
} else {
esc = false;
}
parser_pos += 1;
if (parser_pos >= input.length) {
break;
}
}
}
parser_pos += 1;
resulting_string = sep + resulting_string + sep;
if (sep == '/') {
// regexps may have modifiers /regexp/MOD , so fetch those, too
while (parser_pos < input.length && in_array(input.charAt(parser_pos), wordchar)) {
resulting_string += input.charAt(parser_pos);
parser_pos += 1;
}
}
return [resulting_string, 'TK_STRING'];
}
if (in_array(c, punct)) {
while (parser_pos < input.length && in_array(c + input.charAt(parser_pos), punct)) {
c += input.charAt(parser_pos);
parser_pos += 1;
if (parser_pos >= input.length) {
break;
}
}
return [c, 'TK_OPERATOR'];
}
return [c, 'TK_UNKNOWN'];
}
//----------------------------------
indent_string = '';
while (opt_indent_size--) {
indent_string += opt_indent_char;
}
indent_level = opt_indent_level;
input = js_source_text;
last_word = ''; // last 'TK_WORD' passed
last_type = 'TK_START_EXPR'; // last token type
last_text = ''; // last token text
output = [];
do_block_just_closed = false;
var_line = false; // currently drawing var .... ;
var_line_tainted = false; // false: var a = 5; true: var a = 5, b = 6
whitespace = "\n\r\t ".split('');
wordchar = 'abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789_$'.split('');
punct = '+ - * / % & ++ -- = += -= *= /= %= == === != !== > < >= <= >> << >>> >>>= >>= <<= && &= | || ! !! , : ? ^ ^= |= ::'.split(' ');
// words which should always start on new line.
line_starters = 'continue,try,throw,return,var,if,switch,case,default,for,while,break,function'.split(',');
// states showing if we are currently in expression (i.e. "if" case) - 'EXPRESSION', or in usual block (like, procedure), 'BLOCK'.
// some formatting depends on that.
current_mode = 'BLOCK';
modes = [current_mode];
parser_pos = 0;
in_case = false; // flag for parser that case/default has been processed, and next colon needs special attention
while (true) {
var t = get_next_token(parser_pos);
token_text = t[0];
token_type = t[1];
if (token_type === 'TK_EOF') {
break;
}
switch (token_type) {
case 'TK_START_EXPR':
var_line = false;
set_mode('EXPRESSION');
if (last_type === 'TK_END_EXPR' || last_type === 'TK_START_EXPR') {
// do nothing on (( and )( and ][ and ]( ..
} else if (last_type !== 'TK_WORD' && last_type !== 'TK_OPERATOR') {
print_space();
} else if (in_array(last_word, line_starters) && last_word !== 'function') {
print_space();
}
print_token();
break;
case 'TK_END_EXPR':
print_token();
restore_mode();
break;
case 'TK_START_BLOCK':
if (last_word === 'do') {
set_mode('DO_BLOCK');
} else {
set_mode('BLOCK');
}
if (last_type !== 'TK_OPERATOR' && last_type !== 'TK_START_EXPR') {
if (last_type === 'TK_START_BLOCK') {
print_newline();
} else {
print_space();
}
}
print_token();
indent();
break;
case 'TK_END_BLOCK':
if (last_type === 'TK_START_BLOCK') {
// nothing
trim_output();
unindent();
} else {
unindent();
print_newline();
}
print_token();
restore_mode();
break;
case 'TK_WORD':
if (do_block_just_closed) {
print_space();
print_token();
print_space();
break;
}
if (token_text === 'case' || token_text === 'default') {
if (last_text === ':') {
// switch cases following one another
remove_indent();
} else {
// case statement starts in the same line where switch
unindent();
print_newline();
indent();
}
print_token();
in_case = true;
break;
}
prefix = 'NONE';
if (last_type === 'TK_END_BLOCK') {
if (!in_array(token_text.toLowerCase(), ['else', 'catch', 'finally'])) {
prefix = 'NEWLINE';
} else {
prefix = 'SPACE';
print_space();
}
} else if (last_type === 'TK_SEMICOLON' && (current_mode === 'BLOCK' || current_mode === 'DO_BLOCK')) {
prefix = 'NEWLINE';
} else if (last_type === 'TK_SEMICOLON' && current_mode === 'EXPRESSION') {
prefix = 'SPACE';
} else if (last_type === 'TK_STRING') {
prefix = 'NEWLINE';
} else if (last_type === 'TK_WORD') {
prefix = 'SPACE';
} else if (last_type === 'TK_START_BLOCK') {
prefix = 'NEWLINE';
} else if (last_type === 'TK_END_EXPR') {
print_space();
prefix = 'NEWLINE';
}
if (last_type !== 'TK_END_BLOCK' && in_array(token_text.toLowerCase(), ['else', 'catch', 'finally'])) {
print_newline();
} else if (in_array(token_text, line_starters) || prefix === 'NEWLINE') {
if (last_text === 'else') {
// no need to force newline on else break
print_space();
} else if ((last_type === 'TK_START_EXPR' || last_text === '=') && token_text === 'function') {
// no need to force newline on 'function': (function
// DONOTHING
} else if (last_type === 'TK_WORD' && (last_text === 'return' || last_text === 'throw')) {
// no newline between 'return nnn'
print_space();
} else if (last_type !== 'TK_END_EXPR') {
if ((last_type !== 'TK_START_EXPR' || token_text !== 'var') && last_text !== ':') {
// no need to force newline on 'var': for (var x = 0...)
if (token_text === 'if' && last_type === 'TK_WORD' && last_word === 'else') {
// no newline for } else if {
print_space();
} else {
print_newline();
}
}
} else {
if (in_array(token_text, line_starters) && last_text !== ')') {
print_newline();
}
}
} else if (prefix === 'SPACE') {
print_space();
}
print_token();
last_word = token_text;
if (token_text === 'var') {
var_line = true;
var_line_tainted = false;
}
if (token_text === 'if' || token_text === 'else') {
if_line_flag = true;
}
break;
case 'TK_SEMICOLON':
print_token();
var_line = false;
break;
case 'TK_STRING':
if (last_type === 'TK_START_BLOCK' || last_type === 'TK_END_BLOCK' || last_type == 'TK_SEMICOLON') {
print_newline();
} else if (last_type === 'TK_WORD') {
print_space();
}
print_token();
break;
case 'TK_OPERATOR':
var start_delim = true;
var end_delim = true;
if (var_line && token_text !== ',') {
var_line_tainted = true;
if (token_text === ':') {
var_line = false;
}
}
if (token_text === ':' && in_case) {
print_token(); // colon really asks for separate treatment
print_newline();
break;
}
if (token_text === '::') {
// no spaces around exotic namespacing syntax operator
print_token();
break;
}
in_case = false;
if (token_text === ',') {
if (var_line) {
if (var_line_tainted) {
print_token();
print_newline();
var_line_tainted = false;
} else {
print_token();
print_space();
}
} else if (last_type === 'TK_END_BLOCK') {
print_token();
print_newline();
} else {
if (current_mode === 'BLOCK') {
print_token();
print_newline();
} else {
// EXPR od DO_BLOCK
print_token();
print_space();
}
}
break;
} else if (token_text === '--' || token_text === '++') { // unary operators special case
if (last_text === ';') {
// space for (;; ++i)
start_delim = true;
end_delim = false;
} else {
start_delim = false;
end_delim = false;
}
} else if (token_text === '!' && last_type === 'TK_START_EXPR') {
// special case handling: if (!a)
start_delim = false;
end_delim = false;
} else if (last_type === 'TK_OPERATOR') {
start_delim = false;
end_delim = false;
} else if (last_type === 'TK_END_EXPR') {
start_delim = true;
end_delim = true;
} else if (token_text === '.') {
// decimal digits or object.property
start_delim = false;
end_delim = false;
} else if (token_text === ':') {
// zz: xx
// can't differentiate ternary op, so for now it's a ? b: c; without space before colon
if (last_text.match(/^\d+$/)) {
// a little help for ternary a ? 1 : 0;
start_delim = true;
} else {
start_delim = false;
}
}
if (start_delim) {
print_space();
}
print_token();
if (end_delim) {
print_space();
}
break;
case 'TK_BLOCK_COMMENT':
print_newline();
print_token();
print_newline();
break;
case 'TK_COMMENT':
// print_newline();
print_space();
print_token();
print_newline();
break;
case 'TK_UNKNOWN':
print_token();
break;
}
last_type = token_type;
last_text = token_text;
}
return output.join('');
}
//+++++++++++++++++++++++++++test+++++++++++++++++=
function lazy_escape(str)
{
return str.replace(//g, '>').replace(/\n/g, '
');
}
function bt(input, expected)
{
expected = expected || input;
result = js_beautify(input, {indent_size:indent_size, indent_char:indent_char, preserve_newlines:preserve_newlines});
if (result != expected) {
test_result +=
'\n---- input --------\n' + lazy_escape(input) +
'\n---- expected -----\n' + lazy_escape(expected) +
'\n---- received -----\n' + lazy_escape(result) +
'\n-------------------';
tests_failed += 1;
} else {
tests_passed += 1;
}
}
function results()
{
if (tests_failed == 0) {
test_result += 'All ' + tests_passed + ' tests passed.';
} else {
test_result += '\n' + tests_failed + ' tests failed.';
}
return test_result;
}
function test_js_beautify()
{
bt('');
bt('a = 1', 'a = 1');
bt('a=1', 'a = 1');
bt("a();\n\nb();", "a();\n\nb();");
bt('var a = 1 var b = 2', "var a = 1\nvar b = 2");
bt('a = " 12345 "');
bt("a = ' 12345 '");
bt('if (a == 1) b = 2', "if (a == 1) b = 2");
bt('if(1){2}else{3}', "if (1) {\n 2\n} else {\n 3\n}");
bt('if(1||2)', 'if (1 || 2)');
bt('(a==1)||(b==2)', '(a == 1) || (b == 2)');
bt('var a = 1 if (2) 3', "var a = 1\nif (2) 3");
bt('a = a + 1');
bt('a = a == 1');
bt('/12345[^678]*9+/.match(a)');
bt('a /= 5');
bt('a = 0.5 * 3');
bt('a *= 10.55');
bt('a < .5');
bt('a <= .5');
bt('a<.5', 'a < .5');
bt('a<=.5', 'a <= .5');
bt('a = 0xff;');
bt('a=0xff+4', 'a = 0xff + 4');
bt('a = [1, 2, 3, 4]');
bt('F*(g/=f)*g+b', 'F * (g /= f) * g + b');
bt('a.b({c:d})', "a.b({\n c: d\n})");
bt('a.b\n(\n{\nc:\nd\n}\n)', "a.b({\n c: d\n})");
bt('a=!b', 'a = !b');
bt('a?b:c', 'a ? b: c'); // 'a ? b : c' would need too make parser more complex to differentiate between ternary op and object assignment
bt('a?1:2', 'a ? 1 : 2'); // 'a ? b : c' would need too make parser more complex to differentiate between ternary op and object assignment
bt('a?(b):c', 'a ? (b) : c'); // this works, though
bt('function void(void) {}');
bt('if(!a)', 'if (!a)');
bt('a=~a', 'a = ~a');
bt('a;/*comment*/b;', "a;\n/*comment*/\nb;");
bt('if(a)break', "if (a) break");
bt('if(a){break}', "if (a) {\n break\n}");
bt('if((a))', 'if ((a))');
bt('for(var i=0;;)', 'for (var i = 0;;)');
bt('a++;', 'a++;');
bt('for(;;i++)', 'for (;; i++)');
bt('for(;;++i)', 'for (;; ++i)');
bt('return(1)', 'return (1)');
bt('try{a();}catch(b){c();}finally{d();}', "try {\n a();\n} catch(b) {\n c();\n} finally {\n d();\n}");
bt('(xx)()'); // magic function call
bt('a[1]()'); // another magic function call
bt('if(a){b();}else if(', "if (a) {\n b();\n} else if (");
bt('switch(x) {case 0: case 1: a(); break; default: break}', "switch (x) {\ncase 0:\ncase 1:\n a();\n break;\ndefault:\n break\n}");
bt('a !== b');
bt('if (a) b(); else c();', "if (a) b();\nelse c();");
bt("// comment\n(function()"); // typical greasemonkey start
bt("// comment\n(function something()"); // typical greasemonkey start
bt("{\n\n x();\n\n}"); // was: duplicating newlines
bt('if (a in b)');
//bt('var a, b');
bt('{a:1, b:2}', "{\n a: 1,\n b: 2\n}");
bt('var l = {\'a\':\'1\', \'b\':\'2\'}', "var l = {\n 'a': '1',\n 'b': '2'\n}");
bt('if (template.user[n] in bk)');
bt('{{}/z/}', "{\n {}\n /z/\n}");
bt('return 45', "return 45");
bt('If[1]', "If[1]");
bt('Then[1]', "Then[1]");
bt('a = 1e10', "a = 1e10");
bt('a = 1.3e10', "a = 1.3e10");
bt('a = 1.3e-10', "a = 1.3e-10");
bt('a = -1.3e-10', "a = -1.3e-10");
bt('a = 1e-10', "a = 1e-10");
bt('a = e - 10', "a = e - 10");
bt('a = 11-10', "a = 11 - 10");
bt("a = 1;// comment\n", "a = 1; // comment\n");
bt("a = 1; // comment\n", "a = 1; // comment\n");
bt("a = 1;\n // comment\n", "a = 1;\n// comment\n");
bt("if (a) {\n do();\n}"); // was: extra space appended
bt("if\n(a)\nb()", "if (a) b()"); // test for proper newline removal
bt("if (a) {\n// comment\n}else{\n// comment\n}", "if (a) {\n // comment\n} else {\n // comment\n}"); // if/else statement with empty body
bt("if (a) {\n// comment\n// comment\n}", "if (a) {\n // comment\n // comment\n}"); // multiple comments indentation
bt("if (a) b() else c()", "if (a) b()\nelse c()");
bt("if (a) b() else if c() d()", "if (a) b()\nelse if c() d()");
bt("{}");
bt("{\n\n}");
bt("do { a(); } while ( 1 );", "do {\n a();\n} while ( 1 );");
bt("do {} while ( 1 );");
bt("do {\n} while ( 1 );", "do {} while ( 1 );");
bt("do {\n\n} while ( 1 );");
bt("var a, b, c, d = 0, c = function() {}, d = '';", "var a, b, c, d = 0,\nc = function() {},\nd = '';");
bt("var a = x(a, b, c)");
bt("delete x if (a) b();", "delete x\nif (a) b();");
bt("delete x[x] if (a) b();", "delete x[x]\nif (a) b();");
bt("a = 'a'\nb = 'b'");
bt("a = /reg/exp");
bt("a = /reg/");
bt("x(); /reg/exp.match(something)", "x();\n/reg/exp.match(something)");
bt("function namespace::something()");
indent_size = 1;
indent_char = ' ';
bt('{ one_char() }', "{\n one_char()\n}");
indent_size = 4;
indent_char = ' ';
bt('{ one_char() }', "{\n one_char()\n}");
indent_size = 1;
indent_char = "\t";
bt('{ one_char() }', "{\n\tone_char()\n}");
preserve_newlines = false;
bt('var\na=dont_preserve_newlines', 'var a = dont_preserve_newlines');
preserve_newlines = true;
bt('var\na=do_preserve_newlines', 'var\na = do_preserve_newlines');
return results();
}
//+++++++++++++++++++++++++++++
/*
Style HTML
---------------
Written by Nochum Sossonko, ([email protected])
$Date$
$Revision$
Based on code initially developed by: Einars "elfz" Lielmanis,
http://elfz.laacz.lv/beautify/
You are free to use this in any way you want, in case you find this useful or working for you.
Usage:
style_html(html_source);
*/
function style_html(html_source, indent_size, indent_character, max_char) {
//Wrapper function to invoke all the necessary constructors and deal with the output.
var Parser, multi_parser;
function Parser() {
this.pos = 0; //Parser position
this.token = '';
this.current_mode = 'CONTENT'; //reflects the current Parser mode: TAG/CONTENT
this.tags = { //An object to hold tags, their position, and their parent-tags, initiated with default values
parent: 'parent1',
parentcount: 1,
parent1: ''
};
this.tag_type = '';
this.token_text = this.last_token = this.last_text = this.token_type = '';
this.Utils = { //Uilities made available to the various functions
whitespace: "\n\r\t ".split(''),
single_token: 'br,input,link,meta,!doctype,basefont,base,area,hr,wbr,param,img,isindex,?xml,embed'.split(','), //all the single tags for HTML
extra_liners: 'head,body,/html'.split(','), //for tags that need a line of whitespace before them
in_array: function (what, arr) {
for (var i=0; i= this.input.length) {
return content.length?content.join(''):['', 'TK_EOF'];
}
char = this.input.charAt(this.pos);
this.pos++;
this.line_char_count++;
if (this.Utils.in_array(char, this.Utils.whitespace)) {
if (content.length) {
space = true;
}
this.line_char_count--;
continue; //don't want to insert unnecessary space
}
else if (space) {
if (this.line_char_count >= this.max_char) { //insert a line when the max_char is reached
content.push('\n');
for (var i=0; i', 'igm');
reg_match.lastIndex = this.pos;
var reg_array = reg_match.exec(this.input);
var end_script = reg_array?reg_array.index:this.input.length; //absolute end of script
while(this.pos < end_script) { //get everything in between the script tags
if (this.pos >= this.input.length) {
return content.length?content.join(''):['', 'TK_EOF'];
}
char = this.input.charAt(this.pos);
this.pos++;
content.push(char);
}
return content.length?content.join(''):''; //we might not have any content at all
}
this.record_tag = function (tag){ //function to record a tag and its parent in this.tags Object
if (this.tags[tag + 'count']) { //check for the existence of this tag type
this.tags[tag + 'count']++;
this.tags[tag + this.tags[tag + 'count']] = this.indent_level; //and record the present indent level
}
else { //otherwise initialize this tag type
this.tags[tag + 'count'] = 1;
this.tags[tag + this.tags[tag + 'count']] = this.indent_level; //and record the present indent level
}
this.tags[tag + this.tags[tag + 'count'] + 'parent'] = this.tags.parent; //set the parent (i.e. in the case of a div this.tags.div1parent)
this.tags.parent = tag + this.tags[tag + 'count']; //and make this the current parent (i.e. in the case of a div 'div1')
}
this.retrieve_tag = function (tag) { //function to retrieve the opening tag to the corresponding closer
if (this.tags[tag + 'count']) { //if the openener is not in the Object we ignore it
var temp_parent = this.tags.parent; //check to see if it's a closable tag.
while (temp_parent) { //till we reach '' (the initial value);
if (tag + this.tags[tag + 'count'] === temp_parent) { //if this is it use it
break;
}
temp_parent = this.tags[temp_parent + 'parent']; //otherwise keep on climbing up the DOM Tree
}
if (temp_parent) { //if we caught something
this.indent_level = this.tags[tag + this.tags[tag + 'count']]; //set the indent_level accordingly
this.tags.parent = this.tags[temp_parent + 'parent']; //and set the current parent
}
delete this.tags[tag + this.tags[tag + 'count'] + 'parent']; //delete the closed tags parent reference...
delete this.tags[tag + this.tags[tag + 'count']]; //...and the tag itself
if (this.tags[tag + 'count'] == 1) {
delete this.tags[tag + 'count'];
}
else {
this.tags[tag + 'count']--;
}
}
}
this.get_tag = function () { //function to get a full tag and parse its type
var char = '';
var content = [];
var space = false;
do {
if (this.pos >= this.input.length) {
return content.length?content.join(''):['', 'TK_EOF'];
}
char = this.input.charAt(this.pos);
this.pos++;
this.line_char_count++;
if (this.Utils.in_array(char, this.Utils.whitespace)) { //don't want to insert unnecessary space
space = true;
this.line_char_count--;
continue;
}
if (char === "'" || char === '"') {
if (!content[1] || content[1] !== '!') { //if we're in a comment strings don't get treated specially
char += this.get_unformatted(char);
space = true;
}
}
if (char === '=') { //no space before =
space = false;
}
if (content.length && content[content.length-1] !== '=' && char !== '>'
&& space) { //no space after = or before >
if (this.line_char_count >= this.max_char) {
this.print_newline(false, content);
this.line_char_count = 0;
}
else {
content.push(' ');
this.line_char_count++;
}
space = false;
}
content.push(char); //inserts character at-a-time (or string)
} while (char !== '>');
var tag_complete = content.join('');
var tag_index;
if (tag_complete.indexOf(' ') != -1) { //if there's whitespace, thats where the tag name ends
tag_index = tag_complete.indexOf(' ');
}
else { //otherwise go with the tag ending
tag_index = tag_complete.indexOf('>');
}
var tag_check = tag_complete.substring(1, tag_index).toLowerCase();
if (tag_complete.charAt(tag_complete.length-2) === '/' ||
this.Utils.in_array(tag_check, this.Utils.single_token)) { //if this tag name is a single tag type (either in the list or has a closing /)
this.tag_type = 'SINGLE';
}
else if (tag_check === 'script') { //for later script handling
this.record_tag(tag_check);
this.tag_type = 'SCRIPT';
}
else if (tag_check === 'style') { //for future style handling (for now it justs uses get_content)
this.record_tag(tag_check);
this.tag_type = 'STYLE';
}
else if (tag_check.charAt(0) === '!') { //peek for so...
var comment = this.get_unformatted('-->', tag_complete); //...delegate to get_unformatted
content.push(comment);
}
this.tag_type = 'START';
}
else if (tag_check.indexOf('[endif') != -1) {//peek for ', tag_complete);
content.push(comment);
this.tag_type = 'SINGLE';
}
}
else {
if (tag_check.charAt(0) === '/') { //this tag is a double tag so check for tag-ending
this.retrieve_tag(tag_check.substring(1)); //remove it and all ancestors
this.tag_type = 'END';
}
else { //otherwise it's a start-tag
this.record_tag(tag_check); //push it on the tag stack
this.tag_type = 'START';
}
if (this.Utils.in_array(tag_check, this.Utils.extra_liners)) { //check if this double needs an extra line
this.print_newline(true, this.output);
}
}
return content.join(''); //returns fully formatted tag
}
this.get_unformatted = function (delimiter, orig_tag) { //function to return unformatted content in its entirety
if (orig_tag && orig_tag.indexOf(delimiter) != -1) {
return '';
}
var char = '';
var content = '';
var space = true;
do {
char = this.input.charAt(this.pos);
this.pos++
if (this.Utils.in_array(char, this.Utils.whitespace)) {
if (!space) {
this.line_char_count--;
continue;
}
if (char === '\n' || char === '\r') {
content += '\n';
for (var i=0; i 0) {
this.indent_level--;
}
}
}
return this;
}
/*_____________________--------------------_____________________*/
multi_parser = new Parser(); //wrapping functions Parser
multi_parser.printer(html_source, indent_character, indent_size); //initialize starting values
while (true) {
var t = multi_parser.get_token();
multi_parser.token_text = t[0];
multi_parser.token_type = t[1];
if (multi_parser.token_type === 'TK_EOF') {
break;
}
switch (multi_parser.token_type) {
case 'TK_TAG_START': case 'TK_TAG_SCRIPT': case 'TK_TAG_STYLE':
multi_parser.print_newline(false, multi_parser.output);
multi_parser.print_token(multi_parser.token_text);
multi_parser.indent();
multi_parser.current_mode = 'CONTENT';
break;
case 'TK_TAG_END':
multi_parser.print_newline(true, multi_parser.output);
multi_parser.print_token(multi_parser.token_text);
multi_parser.current_mode = 'CONTENT';
break;
case 'TK_TAG_SINGLE':
multi_parser.print_newline(false, multi_parser.output);
multi_parser.print_token(multi_parser.token_text);
multi_parser.current_mode = 'CONTENT';
break;
case 'TK_CONTENT':
if (multi_parser.token_text !== '') {
multi_parser.print_newline(false, multi_parser.output);
multi_parser.print_token(multi_parser.token_text);
}
multi_parser.current_mode = 'TAG';
break;
}
multi_parser.last_token = multi_parser.token_type;
multi_parser.last_text = multi_parser.token_text;
}
return multi_parser.output.join('');
}