MADlib——基于SQL的数据挖掘解决方案(26)——聚类之k-means方法
“物以类聚,人以群分”,其核心思想就是聚类。所谓聚类,就是将相似的事物聚集在一起,而将不相似的事物划分到不同的类别的过程,是数据分析中十分重要的一种手段。比如古典生物学中,人们通过物种的形貌特征将其分门别类,可以说就是一种朴素的人工聚类。如此,我们就可以将世界上纷繁复杂的信息,简化为少数方便人们理解的类别,因此聚类可以说是人类认知这个世界的最基本方式之一。通过聚类,人们能意识到密集和稀疏的区域,发现全局的分布模式,以及数据属性之间有趣的相互关系。
聚类起源于分类学,在古老的分类学中,人们主要依靠经验和专业知识来实现分类,很少利用数学工具定量分类。随着科学技术的发展,对分类的要求越来越高,以至有时仅凭经验难以确切地分类,于是人们逐渐把数学工具引用到了分类学中,形成了数值分析学,之后又将多元分析技术引入进数值分类学,从而形成了聚类。在实践中,聚类往往为分类服务,即先通过聚类来判断事物的合适类别,然后在利用分类技术对新的样本进行分类。
聚类算法大都是几种最基本的方法,如k-means、层次聚类、SOM等,以及它们的许多改进变种。MADlib提供了一种k-means算法的实现。本篇主要介绍MADlib的k-means算法相关函数和应用案例。
一、聚类方法简介
1. 聚类的概念
将物理或抽象对象的集合分成由类似的对象组成的多个类或簇(Cluster)的过程被称为聚类(Clustering)。由聚类所生成的簇是一组数据对象的集合,这些对象与同一个簇中的对象相似度较高,与其它簇中的对象相似度较低。相似度是根据描述对象的属性值来度量的,距离是经常采用的度量方式。分析事物聚类的过程称为聚类分析或群分析,是研究样品或指标分类问题的一种统计分析方法。
在数据分析的术语中,聚类和分类是两种技术。分类是指已经知道了事物的类别,需要从样品中学习分类规则,对新的、无标记的对象赋予类别,是一种有监督学习。而聚类则没有事先预定的类别,而是依据人为给定的规则进行训练,类别在聚类过程中自动生成,从而得到分类,是一种无监督学习。作为一个数据挖掘的功能,聚类可当做独立的工具来获得数据分布情况,观察每个簇的特点,集中对特定簇做进一步的分析。此外,聚类分析还可以作为其它算法的预处理步骤,简少计算量,提高分析效率。
2. 类的度量方法
虽然类的形式各有不同,但总的来说,一般用距离作为类的度量方法。设x、y是两个向量 ![]() 和
和 ![]() ,聚类分析中常用的距离有以下几种:
,聚类分析中常用的距离有以下几种:
(1) 曼哈顿距离
x、y的曼哈顿距离定义为:![]()
(2) 欧氏距离
x、y的欧氏距离定义为:![]()
(3) 欧氏平方距离
x、y的欧氏平方距离定义为:![]()
(4) 角距离
x、y的角距离定义为:![]() ,分母是x、y两个向量的2范数乘积。
,分母是x、y两个向量的2范数乘积。
(5) 谷本距离
x、y的谷本距离定义为:![]()
二、k-means方法
在数据挖掘中,k-means算法是一种广泛使用的聚类分析算法,也是MADlib 1.10.0官方文档中唯一提及的聚类算法。
1. 基本思想
k-means聚类划分方法的基本思想是:将一个给定的有N个数据记录的集合,划分到K个分组中,每一个分组就代表一个簇,K 算法首先给出一个初始的分组,以后通过反复迭代的方法改变分组,使得每一次改进之后的分组方案都较前一次好,而所谓好的标准就是:同一分组中对象的距离越近越好(已经收敛,反复迭代至组内数据几乎无差异),而不同分组中对象的距离越远越好。 k-means算法的工作原理是:首先随机从数据集中选取K个点,每个点初始地代表每个簇的中心,然后计算剩余各个样本到中心点的距离,将它赋给最近的簇,接着重新计算每一簇的平均值作为新的中心点,整个过程不断重复,如果相邻两次调整没有明显变化,说明数据聚类形成的簇已经收敛。本算法的一个特点是在每次迭代中都要考察每个样本的分类是否正确。若不正确,就要调整,在全部样本调整完后,再修改中心点,进入下一次迭代。这个过程将不断重复直到满足某个终止条件,终止条件可以是以下任何一个: k-means算法是很典型的基于距离的聚类算法,采用距离作为相似性的评价指标,即认为两个对象的距离越近,其相似度就越大。该算法认为簇是由距离靠近的对象组成,因此把得到紧凑且独立的簇作为最终目标。 k-means算法的输入是聚类个数k,以及n个数据对象,输出是满足误差最小标准的k个聚簇。其处理流程为: k-means算法接受输入量k,然后将n个数据对象划分为k个簇以便使得所获得的簇满足:同一簇中的对象相似度较高,而不同簇中的对象相似度较低。簇相似度是利用各簇中对象的均值所获得的中心对象来进行计算的。为了便于理解k-means算法,可以参考图1所示的二维向量的例子。 图1 k-means聚类算法 从图中我们可以看到A、B、C、D、E五个点。而灰色的点是初始中心点,也就是用来找簇的点。有两个中心点,所以K=2。 k-means的算法如下: 二维坐标中两点之间距离公式如下: 公式中(x1,y1),(x2,y2)分别为A、B两个点的坐标。求聚类中心点的算法可以简单使用各个点的X/Y坐标的平均值。 k-means主要有两个重大缺陷,并且都和初始值有关: k-means++算法步骤: 形式上,我们希望最小化以下目标函数: 其中 (1)语法 MADlib提供了以下四个k-means算法训练函数。使用随机中心点方法,语法如下: 使用kmeans++中心点方法,语法如下: 由rel_initial_centroids参数提供一个包含初始中心点的表名,语法如下: 由initial_centroids参数提供的数组表达式,指定一个初始中心点集合,语法如下: (2)参数 参数名称 数据类型 描述 rel_source TEXT 含有输入数据对象的表名。数据对象和预定义中心点(如果使用的话)应该使用一个数组类型的列存储,如FLOAT[]或INTEGER[]。调用任何以上四种函数进行数据分析时,都会跳过具有non-finite值的数据对象,non-finite值包括NULL、NaN、infinity等。 expr_point TEXT 包含数据对象的列名。 k INTEGER 指定要计算的中心点的个数。 fn_dist(可选) TEXT 缺省值为‘squared_dist_norm2’,指定计算数据对象与中心点距离的函数名称。可以使用以下距离函数,括号内为均值计算方法: agg_centroid(可选) TEXT 缺省值为‘avg’。确定中心点使用的聚合函数名,可以使用以下聚合函数: max_num_iterations(可选) INTEGER 缺省值为20,指定执行的最大迭代次数。 min_frac_reassigned(可选) DOUBLE PRECISION 缺省值为0.001。相邻两次迭代所有中心点相差小于该值时计算完成。 seeding_sample_ratio(可选) DOUBLE PRECISION 缺省值为1.0。kmeans++将扫描数据‘k’次,对大数据集会很慢。此参数指定用于确定初始中心点所使用的原始数据集样本比例。当此参数大于0时(最大值为1.0),初始中心点在数据均匀分布的随机样本上。注意,k-means算法最终会在全部数据集上执行。此参数只是为确定初始中心点建立一个子样本,并且只对kmeans++有效。 rel_initial_centroids TEXT 包含初始中心点的表名。 expr_centroid TEXT rel_initial_centroids指定的表中包含中心点的列名。 initial_centroids TEXT 包含初始中心点的DOUBLE PRECISION数组表达式的字符串。 表1 kmeans相关函数参数说明 (3)输出格式 k-means模型的输出具有表2所示列的复合数据类型。 列名 数据类型 描述 centroids DOUBLE PRECISION[][] 最终的中心点。 cluster_variance DOUBLE PRECISION[] 每个簇的方差。 objective_fn DOUBLE PRECISION 方差合计。 frac_reassigned DOUBLE PRECISION 最后一次迭代的误差。 num_iterations INTEGER 迭代执行的次数。 表2 k-means模型输出列说明 (1)语法 得到中心点后,可以调用以下函数为每个数据对象进行簇分配: (2)参数 m:DOUBLEPRECISION[][]类型,训练函数返回的中心点。 x:DOUBLEPRECISION[]类型,输入数据。 (3)输出格式 column_id:INTEGER类型,簇ID,从0开始。 distance:DOUBLEPRECISION类型,数据对象与簇中心点的距离。 轮廓系数(Silhouette Coefficient),是聚类效果好坏的一种评价方法。作为 k-means模型的一部分,MADlib提供了一个轮廓系数方法的简化版本函数,该函数结果值处于-1~1之间,值越大,表示聚类效果越好。注意,对于大数据集,该函数的计算代价很高。 (1)语法 (2)参数 参数名称 数据类型 描述 rel_source TEXT 含有输入数据对象的表名。 expr_point TEXT 数据对象列名。 centroids TEXT 中心点表达式。 fn_dist(可选) TEXT 计算数据点到中心点距离的函数名,缺省值为‘dist_norm2’。 表3 simple_silhouette函数参数说明 RFM模型是在做用户价值细分时常用的方法,主要涵盖的指标有最近一次消费时间R(Recency)、消费频率(Frequency),消费金额(Monetary)。我们用R、F、M三个指标作为数据对象属性,应用MADlib的k-means模型相关函数对用户进行聚类分析,并得出具有实用性和解释性的结论。 (1)将最近一次访问日期处理成最近一次访问日期到当前日期的间隔天数,代表该用户是否最近有购买记录(即目前是否活跃)。 (2)因为k-means受异常值影响很大,并且金额变异比较大,所以去除该维度的异常值。 (3)使用PCA方法消除维度之间的相关性。 (4)0-1归一化处理。 查询结果为: 可以看到,因为cust_id=666用户的金额不在99%的范围内,所以t_source_change表中去掉了该条记录。在此去除异常并非这个用户异常,而是为了改善聚类结果。最后需要给这些“异常用户”做业务解释。 查询结果为: (1)调用kmeanspp函数执行聚类 查询结果如下: (2)调用simple_silhouette函数评价聚类质量 结果如下: (3)调用closest_column函数执行簇分配 查询结果为: 表4对聚类结果分成的三类用户进行了说明。 类别 占比 描述 第一类:高价值用户 32.3% 购买频率高(平均4次);消费金额较高(平均5586元);最近一周有过购买行为,这部分用户需要大力发展。 第二类:中价值用户 48.5% 购买频率中等(平均2.4次);消费金额不高(平均3447);最近一个月有个购买行为,这部分用户可以适当诱导购买。 第三类:高价值挽留用户 19.2 购买频率一般(平均2次);消费金额较高(平均5439元);较长时间没有购买行为,这部分客户需要尽量挽留。 表4 聚类形成的三类用户 聚类方法是根据给定的规则进行训练,自动生成类别的数据挖掘方法,属于无监督学习范畴。聚类已经被应用在模式识别、数据分析、图像处理、市场研究等多个领域。虽然类的形式各不相同,但一般都用距离作为类的度量方法。聚类算法有很多种,其中k-means是应用最广泛、适应性最强的聚类算法,也是MADlib唯一支持的聚类算法。MADlib提供了4个k-means训练函数、一个簇分配函数、一个轮廓系数函数。我们利用MADlib提供的这些函数,实现了一个按照RFM模型对用户进行细分的示例需求。
2. 原理与步骤
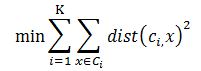
3. k-means算法

![]()
三、MADlib的k-means相关函数

![]() 是n个数据对象,
是n个数据对象,![]() 是k个中心点,常见的情况下,距离使用欧氏平方距离。这个问题在计算上很困难(NP-hard问题),但由于局部启发式搜索算法在实践中表现的相当好,如今被普遍采用,其中之一就是前面讨论的k-means算法。MADlib提供了三组k-means算法相关函数,分别是训练函数、簇分配函数和轮廓系数函数。
是k个中心点,常见的情况下,距离使用欧氏平方距离。这个问题在计算上很困难(NP-hard问题),但由于局部启发式搜索算法在实践中表现的相当好,如今被普遍采用,其中之一就是前面讨论的k-means算法。MADlib提供了三组k-means算法相关函数,分别是训练函数、簇分配函数和轮廓系数函数。1. 训练函数
kmeans_random (rel_source,
expr_point,
k,
fn_dist,
agg_centroid,
max_num_iterations,
min_frac_reassigned
)kmeanspp( rel_source,
expr_point,
k,
fn_dist,
agg_centroid,
max_num_iterations,
min_frac_reassigned,
seeding_sample_ratio
) kmeans( rel_source,
expr_point,
rel_initial_centroids,
expr_centroid,
fn_dist,
agg_centroid,
max_num_iterations,
min_frac_reassigned
)kmeans( rel_source,
expr_point,
initial_centroids,
fn_dist,
agg_centroid,
max_num_iterations,
min_frac_reassigned
)
2. 簇分配函数
closest_column( m, x )3. 轮廓系数函数
simple_silhouette( rel_source,
expr_point,
centroids,
fn_dist
)
四、k-means应用示例
1. 问题提出
2. 建立测试数据表并装载原始数据
-- 创建原始数据表
drop table if exists t_source;
create table t_source
(cust_id int,
amount decimal(10 , 2 ),
quantity int,
dt date);
-- 添加100条数据
insert into t_source (cust_id,amount,quantity,dt) values
(567,1100.51,2,'2017-07-20'),(568,2003.47,2,'2017-07-20'),
(569,297.91,2,'2017-07-14'),(570,300.02,2,'2017-07-12'),
…
(663,954.77,2,'2017-06-27'),(664,6006.78,3,'2017-06-22'),
(665,25755.7,2,'2017-06-06'),(666,60201.48,2,'2017-07-11'); 3. 数据预处理
-- 去掉异常值
drop table if exists t_source_change;
create table t_source_change
(row_id serial,
cust_id int,
amount decimal(10 , 2 ),
quantity int,
dt int);
insert into t_source_change (cust_id,amount,quantity,dt)
select cust_id,
amount,
quantity,
current_date-dt dt
from t_source
where amount < (select percentile_cont (0.99) within group (order by amount)
from t_source);
select * from t_source_change order by cust_id; …
94 | 660 | 11594.24 | 10 | 2
95 | 661 | 12039.49 | 2 | 30
96 | 662 | 1494.97 | 2 | 39
97 | 663 | 954.77 | 2 | 25
98 | 664 | 6006.78 | 3 | 30
99 | 665 | 25755.70 | 2 | 46
(99 rows) -- PCA去掉相关性
drop table if exists mat;
create table mat (id integer,
row_vec double precision[] );
insert into mat
select row_id,
string_to_array(amount||','||quantity||','||dt,',')::double precision[] row_vec
from t_source_change;
-- PCA培训
drop table if exists result_table, result_table_mean;
select madlib.pca_train('mat', -- source table
'result_table', -- output table
'id', -- row id of source table
3 -- number of principal components
);
-- PCA投影
drop table if exists residual_table, result_summary_table, out_table;
select madlib.pca_project( 'mat',
'result_table',
'out_table',
'id',
'residual_table',
'result_summary_table'
);
-- 0-1归一化
drop table if exists t_source_change_nor;
create table t_source_change_nor
as
select row_id,
string_to_array(amount_nor||','||quantity_nor||','||dt_nor,',')::double precision[] row_vec
from
(
select row_id,
(row_vec[1] - min_amount)/(max_amount - min_amount) amount_nor,
(row_vec[2] - min_quantity)/(max_quantity - min_quantity) quantity_nor,
(max_dt - row_vec[3])/(max_dt - min_dt) dt_nor
from out_table,
(select max(row_vec[1]) max_amount,
min(row_vec[1]) min_amount,
max(row_vec[2]) max_quantity,
min(row_vec[2]) min_quantity,
max(row_vec[3]) max_dt,
min(row_vec[3]) min_dt
from out_table) t) t;
select * from t_source_change_nor order by row_id; …
94 | {0.558470357737996,0.954872666162949,0.296935710714377}
95 | {0.54122257689463,0.482977156688704,0.81244230552888}
96 | {0.949697477408967,0.385844448834949,0.65901807391295}
97 | {0.970623648952883,0.62014760223173,0.704941708880569}
98 | {0.774918367989914,0.513405499602443,0.666993533505089}
99 | {0.00988267286683593,0.150872332720288,0.908966781310526}
(99 rows)4. k-means聚类
drop table if exists km_result;
create table km_result as
select * from madlib.kmeanspp
( 't_source_change_nor', -- 源数据表名
'row_vec', -- 包含数据点的列名
3, -- 中心点个数
'madlib.squared_dist_norm2', -- 距离函数
'madlib.avg', -- 聚合函数
20, -- 迭代次数
0.001 -- 停止迭代条件 );
\x on;
select centroids[1][1]||', '||centroids[1][2]||', '||centroids[1][3] cent1,
centroids[2][1]||', '||centroids[2][2]||', '||centroids[2][3] cent2,
centroids[3][1]||', '||centroids[3][2]||', '||centroids[3][3] cent3,
cluster_variance,
objective_fn,
frac_reassigned,
num_iterations
from km_result;-[ RECORD 1 ]----+------------------------------------------------
cent1 | 0.872433445942, 0.0724942318135, 0.318094096598
cent2 | 0.890144445443, 0.546835465582, 0.333554735766
cent3 | 0.238390106949, 0.449997152636, 0.267439867941
cluster_variance | {1.33448519773,2.05461238207,1.83212942768}
objective_fn | 5.22122700748
frac_reassigned | 0
num_iterations | 8select * from madlib.simple_silhouette
( 't_source_change_nor',
'row_vec',
(select centroids
from madlib.kmeanspp('t_source_change_nor',
'row_vec',
3,
'madlib.squared_dist_norm2',
'madlib.avg',
20,
0.001)),
'madlib.dist_norm2' );-[ RECORD 1 ]-----+------------------
simple_silhouette | 0.640471849127657 \x off;
select cluster_id,
round(count(cust_id)/99.0,4) pct,
round(avg(amount),4) avg_amount,
round(avg(quantity),4) avg_quantity,
round(avg(dt),2) avg_dt
from
(
select t2.*,
(madlib.closest_column(centroids, row_vec)).column_id as cluster_id
from t_source_change_nor as t1, km_result, t_source_change t2
where t1.row_id = t2.row_id) t
group by cluster_id; cluster_id | pct | avg_amount | avg_quantity | avg_dt
------------+--------+------------+--------------+--------
2 | 0.1919 | 5439.9795 | 2.0526 | 48.79
1 | 0.4848 | 3447.5631 | 2.4375 | 29.56
0 | 0.3232 | 5586.0203 | 4.0313 | 5.56
(3 rows) 5. 解释聚类结果
五、小节