MADlib——基于SQL的数据挖掘解决方案(29)——模型评估之交叉验证
验证是评估数据挖掘模型对实际数据执行情况的过程。在将挖掘模型部署到生产环境之前,必须通过了解其质量和特征来对其进行验证,评估模型的准确性、可靠性和可用性。可以使用多种方法评估数据挖掘模型的质量和特征:
- 使用统计信息有效性的各种度量值来确定数据或模型中是否存在问题。
- 将数据划分为定型集和测试集,以测试预测的准确性。
- 请求商业专家查看数据挖掘模型的结果,以确定发现的模式在目标商业方案中是否有意义。
所有这些方法在数据挖掘方法中都非常有用,创建、测试和优化模型来解决特定问题时,可以反复使用这些方法。没有一个全面的规则可以说明什么时候模型已足够好,或者什么时候具有足够的数据。本篇介绍最常用的交叉验证方法,以及MADlib中交叉验证函数的用法。
一、交叉验证简介
数据挖掘技术在应用之前使用的“训练+检验”模式,通常被称作“交叉验证”,如图1所示。实际上在“MADlib——基于SQL的数据挖掘解决方案(24)——分类之决策树”中,我们已经接触过交叉验证,当n_folds参数大于0时,决策树函数在构造模型过程中就会进行交叉验证。
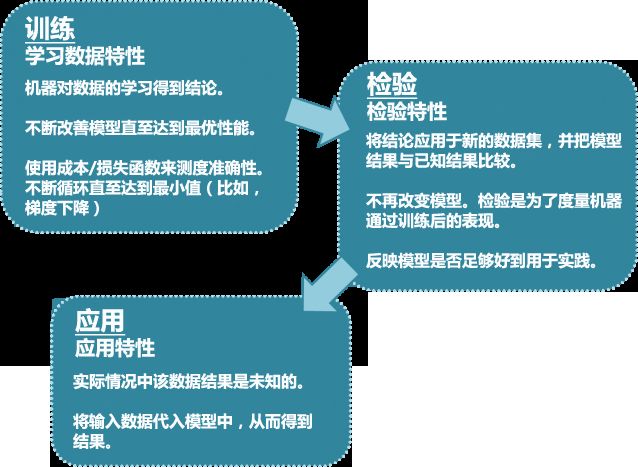
图1 交叉验证过程
1. 预测模型的稳定性
我们通过一个例子来理解模型的稳定性问题。考虑以下几幅图:
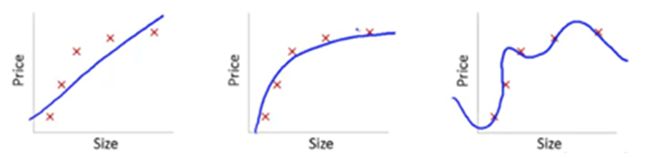
图2 尺寸与价格模型图
此处我们试图找到尺寸(size)和价格(price)的关系。三个模型各自做了如下工作:
- 第一个模型使用了线性等式。对于训练用的数据点,此模型有很大误差。这是“拟合不足”(“Under fitting”)的一个例子。此模型不足以发掘数据背后的趋势。
- 第二个模型发现了价格和尺寸的正确关系,此模型误差低,概括程度高。
- 第三个模型对于训练数据几乎是零误差。这是因为此关系模型把每个数据点的偏差(包括噪声)都纳入了考虑范围,也就是说,这个模型太过敏感,甚至会捕捉到只在当前数据训练集出现的一些随机模式。这是“过度拟合”(Over fitting)的一个例子。
在应用中,常见的做法是对多个模型进行迭代,从中选择表现更好的一个。然而,最终的数据是否会有所改善依然未知,因为我们不确定这个模型是更好的发掘出潜在关系,还是过度拟合了。为解答这个难题,需要使用交叉验证(cross validation)技术,它能帮我们得到更有概括性的数据模型。实际上,数据挖掘关注的是通过训练集训练后的模型对测试样本的学习效果,我们称之为泛化能力。左右两图的泛化能力就表现不好。具体到数据挖掘中,对偏差和方差的权衡是数据挖掘理论着重解决的问题。
2. 交叉验证步骤
交叉验证意味着需要保留一个样本数据集,不用来训练模型。在最终完成模型前,用这个数据集验证模型。交叉验证包含以下步骤:
- 保留一个样本数据集,即测试集。
- 用剩余部分(训练集)训练模型。
- 用保留的数据集(测试集)验证模型。
这样做有助于了解模型的有效性。如果当前模型在此测试数据集也表现良好,说明模型的泛化能力较好,可以用来预测未知数据。
3. 交叉验证的常用方法
交叉验证有很多方法,下面介绍其中三种。
(1) “验证集”法
保留 50% 的数据集用作验证,剩下 50% 训练模型。之后用验证集测试模型表现。这个方法的主要缺陷是,由于只使用了 50% 数据训练模型,原数据中一些重要的信息可能被忽略,也就是说,会有较大偏误。
(2) 留一法交叉验证(LOOCV)
这种方法只保留一个数据点用作验证,用剩余的数据集训练模型。然后对每个数据点重复这个过程。该方法有利有弊:
- 由于使用了所有数据点,所以偏差较低。
- 验证过程重复了n次(n为数据点个数),导致执行时间很长。
- 由于只使用一个数据点验证,该方法导致模型有效性的差异更大。得到的估计结果深受此点的影响。如果这是个离群点,会引起较大偏差。
(3)K折交叉验证 (K-fold cross validation)
从以上两个验证方法中,我们知道:
- 应该使用较大比例的数据集来训练模型,否则会导致失败,最终得到偏误很大的模型。
- 验证用的数据点,其比例应该恰到好处。如果太少,会影响验证模型有效性时,得到的结果波动较大。
- 训练和验证过程应该重复多次(迭代)。训练集和验证集不能一成不变,这样有助于验证模型的有效性。
是否有一种方法可以兼顾这三个方面?答案是肯定的!这种方法就是“K折交叉验证”。该方法的简要步骤如下:
- 把整个数据集随机分成 K“层”。
- 对于每一份数据来说: 1)以该份作为测试集,其余作为训练集,也就是说用其中K-1 层训练模型,然后用第K层验证。2)在训练集上得到模型。 3)在测试集上得到生成误差。
- 重复这个过程,直到每“层”数据都作过验证集。这样对每一份数据都有一个预测结果,记录从每个预测结果获得的误差。
- 记录下的K个误差的平均值,被称为交叉验证误差(cross-validation error)。可以被用做衡量模型表现的标准。
- 取误差最小的那个模型。
此算法的缺点是计算量较大,当K=10时,K层交叉验证示意图如下:
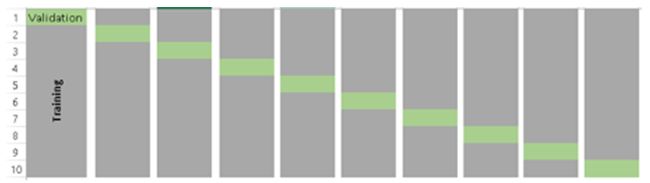
图3 10折交叉验证
一个常见的问题是:如何确定合适的K值?K值越小,偏误越大,所以越不推荐。另一方面,K值太大,所得结果会变化多端。K值小,则会变得像“验证集法”,K值大,则会变得像“留一法”(LOOCV),因此通常建议的经验值是 K=10。
4. 衡量模型的偏误/变化程度
K层交叉检验之后,我们得到K个不同的模型误差估算值(e1, e2 …..ek)。理想情况是,这些误差值相加的结果值为0。计算模型的偏误时,我们把所有这些误差值相加再取平均值,平均值越低,模型越好。模型表现变化程度的计算与之类似。取所有误差值的标准差,标准差越小说明模型随训练数据的变化越小。
应该试图在偏误和变化程度间找到一种平衡。降低变化程度、控制偏误可以达到这个目的,这样会得到更好的数据模型。进行这个取舍,通常会得出复杂程度较低的预测模型。
二、MADlib的交叉验证相关函数
决策树例子中的交叉验证,是内嵌在决策树训练函数中的。MADlib还提供了独立的交叉验证函数,可对大部分MADlib的预测模型进行交叉验证。
交叉验证可以估计一个预测模型在实际中的执行精度,还可用于设置预测目标。MADlib提供的交叉验证函数非常灵活,不但可以选择已经支持的交叉验证算法,用户还可以编写自己的验证算法。从交叉验证函数输入需要验证的训练、预测和误差估计函数规范。这些规范包括三部分:函数名称、传递给函数的参数数组、参数对应的数据类型数组。
训练函数使用给定的自变量和因变量数据集产生模型,模型存储于输出表中。预测函数使用训练函数生成的模型,并接收不同于训练数据的自变量数据集,产生基于模型的对因变量的预测,并将预测结果存储在输出表中。预测函数的输入中应该包含一个表示唯一ID的列名,便于预测结果与验证值作比较。注意,有些MADlib的预测函数不将预测结果存储在输出表中,这种函数不适用于MADlib的交叉验证函数。误差度量函数比较数据集中已知的因变量和预测结果,用特定的算法计算误差度量,并将结果存入一个表中。其它输入包括输出表名,K折交叉验证的K值等。
1. 语法
cross_validation_general( modelling_func,
modelling_params,
modelling_params_type,
param_explored,
explore_values,
predict_func,
predict_params,
predict_params_type,
metric_func,
metric_params,
metric_params_type,
data_tbl,
data_id,
id_is_random,
validation_result,
data_cols,
fold_num ) 2. 参数
参数名称 |
数据类型 |
描述 |
modelling_func |
VARCHAR |
模型训练函数名称。 |
modelling_params |
VARCHAR[] |
训练函数参数数组。 |
modelling_params_type |
VARCHAR[] |
训练函数参数对应的数据类型名称数组。 |
param_explored |
VARCHAR |
被寻找最佳值的参数名称,必须是modelling_params数组中的元素。 |
explore_values |
VARCHAR |
候选的参数值。如果为NULL,只运行一轮交叉验证。 |
predict_func |
VARCHAR |
预测函数名称。 |
predict_params |
VARCHAR[] |
提供给预测函数的参数数组。 |
predict_params_type |
VARCHAR[] |
预测函数参数对应的数据类型名称数组。 |
metric_func |
VARCHAR |
误差度量函数名称。 |
metric_params |
VARCHAR[] |
提供给误差度量函数的参数数组。 |
metric_params_type |
VARCHAR[] |
误差度量函数参数对应的数据类型名称数组。 |
data_tbl |
VARCHAR |
包含原始输入数据表名,表中数据将被分成训练集和测试集。 |
data_id |
VARCHAR |
表示每一行唯一ID的列名,可以为空。理想情况下,数据集中的每行数据都包含一个唯一ID,这样便于将数据集分成训练部分与验证部分。id_is_random参数值告诉交叉验证函数ID值是否是随机赋值。如果原始数据不是随机赋的ID值,验证函数为每行生成一个随机ID。 |
id_is_random |
BOOLEAN |
为TRUE时表示提供的ID是随机分配的。 |
validation_result |
VARCHAR |
存储交叉验证函数输出结果的表名,具有以下列:
|
data_cols |
VARCHAR |
逗号分隔的用于计算的数据列名。为NULL时,函数自动计算数据表中的所有列。只有当data_id参数为NULL时才会用到此参数,否则忽略。如果数据集没有唯一ID,交叉验证函数为每行生成一个随机ID,并将带有随机ID的数据集复制到一个临时表。设置此参数为自变量和因变量列表,通过只复制计算需要的数据,最小化复制工作量。计算完成后临时表被自动删除。 |
fold_num |
INTEGER |
K值,缺省值为10,指定验证轮数,每轮验证使用1/fold_num数据做验证。 |
表1 cross_validation_general函数参数说明
训练、预测和误差度量函数的参数数组中可以包含以下特殊关键字:
- %data%:代表训练/验证数据。
- %model%:代表训练函数的输出,即预测函数的输入。
- %id%:代表唯一ID列(用户提供的或函数生成的)。
- %prediction%:代表预测函数的输出,即误差度量函数的输入。
- %error%:代表误差度量函数的输出。
三、交叉验证示例
我们将调用交叉验证函数,量化弹性网络正则化回归模型的准确性,并找出最佳的正则化参数。关于弹性网络正则化的说明参见https://en.wikipedia.org/wiki/Elastic_net_regularization。
1. 准备输入数据
drop table if exists houses;
-- 房屋价格表
create table houses (
id serial not null, -- 自增序列
tax integer, -- 税金
bedroom real, -- 卧室数
bath real, -- 卫生间数
price integer, -- 价格
size integer, -- 使用面积
lot integer -- 占地面积
);
insert into houses(tax, bedroom, bath, price, size, lot) values
( 590, 2, 1, 50000, 770, 22100),
(1050, 3, 2, 85000, 1410, 12000),
( 20, 3, 1, 22500, 1060, 3500),
( 870, 2, 2, 90000, 1300, 17500),
(1320, 3, 2, 133000, 1500, 30000),
(1350, 2, 1, 90500, 820, 25700),
(2790, 3, 2.5, 260000, 2130, 25000),
( 680, 2, 1, 142500, 1170, 22000),
(1840, 3, 2, 160000, 1500, 19000),
(3680, 4, 2, 240000, 2790, 20000),
(1660, 3, 1, 87000, 1030, 17500),
(1620, 3, 2, 118600, 1250, 20000),
(3100, 3, 2, 140000, 1760, 38000),
(2070, 2, 3, 148000, 1550, 14000),
( 650, 3, 1.5, 65000, 1450, 12000); 2. 创建函数执行交叉验证
create or replace function check_cv()
returns void as $$
begin
execute 'drop table if exists valid_rst_houses';
perform madlib.cross_validation_general(
-- 训练函数
'madlib.elastic_net_train',
-- 训练函数参数
'{%data%, %model%, (price>100000), "array[tax, bath, size, lot]",
binomial, 1, lambda, true, null, fista,
"{eta = 2, max_stepsize = 2, use_active_set = t}",
null, 2000, 1e-6}'::varchar[],
-- 训练函数参数数据类型
'{varchar, varchar, varchar, varchar, varchar, double precision,
double precision, boolean, varchar, varchar, varchar, varchar, integer,
double precision}'::varchar[],
-- 被考察参数
'lambda',
-- 被考察参数值
'{0.04, 0.08, 0.12, 0.16, 0.20, 0.24, 0.28, 0.32, 0.36}'::varchar[],
-- 预测函数
'madlib.elastic_net_predict',
-- 预测函数参数
'{%model%, %data%, %id%, %prediction%}'::varchar[],
-- 预测函数参数数据类型
'{text, text, text, text}'::varchar[],
-- 误差度量函数
'madlib.misclassification_avg',
-- 误差度量函数参数
'{%prediction%, %data%, %id%, (price>100000), %error%}'::varchar[],
-- 误差度量函数参数数据类型
'{varchar, varchar, varchar, varchar, varchar}'::varchar[],
-- 数据表
'houses',
-- ID列
'id',
-- id是否随机
false,
-- 验证结果表
'valid_rst_houses',
-- 数据列
'{tax,bath,size,lot, price}'::varchar[],
-- 折数
3
);
end;
$$ language plpgsql volatile;3. 执行函数并查询结果
select check_cv();
select * from valid_rst_houses order by lambda;结果:
lambda | error_rate_avg | error_rate_stddev
--------+------------------------+--------------------------------------------
0.04 | 0.26666666666666666667 | 0.1154700538379251529018297561003914911294
0.08 | 0.33333333333333333333 | 0.1154700538379251529018297561003914911294
0.12 | 0.33333333333333333333 | 0.1154700538379251529018297561003914911294
0.16 | 0.53333333333333333333 | 0.2309401076758503058036595122007829822590
0.2 | 0.60000000000000000000 | 0.2000000000000000000000000000000000000000
0.24 | 0.60000000000000000000 | 0.2000000000000000000000000000000000000000
0.28 | 0.66666666666666666667 | 0.2309401076758503058036595122007829822590
0.32 | 0.66666666666666666667 | 0.2309401076758503058036595122007829822590
0.36 | 0.73333333333333333333 | 0.1154700538379251529018297561003914911294
(9 rows) 上面的查询结果表示,随着正则化参数不断加大,平均误差也会增加,而且当正则化参数较小时标准差也较小。因此得出结论,用0.04作为正则化参数,将得到较好的预测模型。
四、小节
验证对由训练数据集生成的数据挖掘预测模型的准确性非常重要。在模型正式投入使用前必须经过验证过程。交叉验证是常用一类的模型验证评估方法,其中“K折交叉验证”法重复多次执行训练和验证过程,每次训练集和验证集发生变化,有助于验证模型的有效性。MADlib提供的K折交叉验证函数,可用于大部分MADlib的预测模型。